


We'd like to thank you all for participating in the contest, and hope you enjoyed it. Any feedback would be appreciated!
2183A — Binary Array Game
Idea & Preparation: wangmarui
If the sequence $$$a$$$ consists entirely of $$$1$$$ s, what will Alice do?
Consider discussing the values of $$$a_1$$$ and $$$a_n$$$.
First, if the entire sequence consists of $$$1$$$ s, Alice wins immediately by operating on the whole sequence.
Note that the last operation must involve at least one of $$$a_1$$$ or $$$a_n$$$. We discuss based on the values of $$$a_1$$$ and $$$a_n$$$:
If $$$a_1 = 1$$$, then Alice can directly operate on the interval $$$[2,n]$$$ to win, because $$$a_{2 \sim n}$$$ must contain at least one $$$0$$$.
If $$$a_n = 1$$$, then Alice can directly operate on the interval $$$[1,n-1]$$$ to win, because $$$a_{1 \sim n-1}$$$ must contain at least one $$$0$$$.
If $$$a_1 = 0$$$ and $$$a_n = 0$$$, then operating on the entire sequence would certainly cause Alice to lose. This implies that Alice cannot operate on both $$$a_1$$$ and $$$a_n$$$ simultaneously. Therefore, after Alice's operation, there will still be at least one $$$0$$$ in the sequence $$$a$$$. Bob can then operate on the entire sequence to win. Hence, in this case, Bob wins.
Time complexity: $$$O(\sum n)$$$.
#include<bits/stdc++.h>
using namespace std;
int _t_,n,a[100010];
void solve()
{
cin>>n;
for(int i=1;i<=n;i++)
cin>>a[i];
if(a[1]+a[n]==0)
cout<<"NO\n";
else
cout<<"YES\n";
}
int main()
{
ios::sync_with_stdio(0);
cin.tie(0),cout.tie(0);
cin>>_t_;
while(_t_--)
solve();
return 0;
}
2183B — Yet Another MEX Problem
Idea & Preparation: wangmarui
Considering that in the end only $$$k - 1$$$ numbers will remain, which numbers in an interval of length $$$k$$$ are invalid?
Consider the Pigeonhole Principle.
Since only $$$k - 1$$$ numbers will remain in the end, it is relatively easy to notice that for any interval of length $$$k$$$, numbers within this interval that are greater than or equal to $$$k-1$$$ or have duplicate values are invalid. One of these two types of numbers can be removed. Since there are only $$$k - 1$$$ numbers from $$$0$$$ to $$$k-2$$$, in any interval of length $$$k$$$, there must be at least one number that can be deleted. Therefore, the answer is $$$\min(\text{mex}(a), k-1)$$$.
Time complexity: $$$O(\sum n)$$$.
#include<bits/stdc++.h>
using namespace std;
#define re register
#define ll long long
#define forl(i,a,b) for(re ll (i)=(a);i<=(b);(i)++)
#define forr(i,a,b) for(re ll (i)=(a);i>=(b);(i)--)
#define IOS ios::sync_with_stdio(0),cin.tie(0),cout.tie(0);
#define endl '\n'
ll _t_;
ll n,m;
ll maxn;
ll a[1000010];
ll b[1000010];
void _clear(){}
void solve()
{
_clear();
cin>>n>>m;
forl(i,1,n)
cin>>a[i],a[i]=min(a[i],n+1);
forl(i,0,n+5)
b[i]=0;
ll mex=0;
forl(i,1,n)
b[a[i]]++;
while(b[mex])
mex++;
cout<<min(mex,m-1)<<endl;
}
int main()
{
IOS;
_t_=1;
cin>>_t_;
while(_t_--)
solve();
return 0;
}
2183C — War Strategy
Idea & Preparation: Network_Error
Consider a greedy algorithm.
What shape must the finally occupied bases take?
If the capital is the first city (i.e., $$$k=1$$$), how to solve it?
The finally occupied bases must form an interval containing $$$k$$$.
If the finally occupied bases do not form an interval containing $$$k$$$, then there must exist some $$$x, y$$$ such that $$$1 \le x \lt y \lt k$$$ or $$$k \lt y \lt x \le n$$$, with $$$x$$$ occupied and $$$y$$$ unoccupied. Consider a soldier at $$$y$$$ starting from $$$k$$$ and moving to $$$x$$$; it must pass through base $$$x$$$ along the way. Consider making this soldier stop exactly at $$$x$$$. Then soldier $$$y$$$ ends up at $$$x$$$. After a finite number of such adjustments, we will reach a state where no further adjustment is possible, which implies the finally occupied bases must be an interval containing $$$k$$$.
Suppose this interval contains $$$a$$$ positions to the left of $$$k$$$ and $$$b$$$ positions to the right of $$$k$$$ (excluding $$$k$$$ itself) ($$$0 \le a \le k-1$$$, $$$0 \le b \le n-k$$$). It is possible to occupy this interval if and only if $$$a + b + \max(a, b) - 1 \le m$$$.
Sufficiency:
We can imagine a simple strategy. Initially, we do nothing until the capital contains $$$a$$$ soldiers. Then we move $$$a$$$ soldiers from $$$k$$$ to $$$k-1$$$, then move $$$a-1$$$ soldiers from $$$k-1$$$ to $$$k-2$$$, and so on. Thus $$$k-1, k-2, \ldots, k-a$$$ are all filled with soldiers. Then we wait (if necessary) until the capital contains $$$b$$$ soldiers and move them in the same way to $$$k+1, \ldots, k+b$$$. It can be observed that this strategy requires exactly $$$a + b + \max(a, b) - 1$$$ days.
Necessity:
We prove that for any strategy, the required number of days $$$m$$$ is at least $$$a + b + \max(a, b) - 1$$$.
First, we need at least $$$a+b$$$ days to obtain the extra $$$a+b$$$ soldiers. Second, we cannot move new soldiers to new bases every moment. In fact, we can prove that there are at least $$$\max(a, b) - 1$$$ idle days. The proof is as follows.
Assume without loss of generality that $$$a \ge b$$$.
Define the potential function $$$h(S)$$$ of a state $$$S$$$ as the number of soldiers minus the number of occupied bases.
Suppose the first move to the left is moving $$$t$$$ soldiers to the leftmost consecutive $$$t$$$ positions $$$k-a, \ldots, k-a+t-1$$$.
(If the move is not to the leftmost positions but to some intermediate positions, we can show through adjustment that such a move is suboptimal. Therefore, an optimal solution will not contain such moves.)
Let $$$S_0$$$ be the state before the move, $$$S_1$$$ be the state when moving $$$t$$$ soldiers to $$$k-a+t$$$, $$$S_2$$$ be the state after completing the move of all $$$t$$$ soldiers, and $$$S_3$$$ be the final state.
We have $$$h(S_2) = h(S_1)$$$, $$$h(S_3) \ge h(S_2)$$$.
$$$h(S_1) - h(S_0) \ge a - t$$$ (during the intermediate $$$a-t$$$ steps, the potential increases each time).
$$$h(S_0) \ge t - 1$$$ (at least $$$t$$$ movable soldiers are needed).
Summing up, we get $$$h(S_3) \ge a - 1$$$. Therefore, the number of days needed is at least $$$2a + b - 1$$$.
In summary, at least $$$a + b + \max(a, b) - 1$$$ days are required.
We consider a greedy approach. First, if $$$k-1 \lt n-k$$$, we replace $$$k$$$ with $$$n+1-k$$$.
We define two variables $$$a$$$ and $$$b$$$, representing how many cells have been extended to the left and right, respectively. Initially, $$$a = 0$$$, $$$b = 0$$$. Then we repeatedly try to increase $$$a$$$ and $$$b$$$ by $$$1$$$ in turns. We first try to increase $$$b$$$ by $$$1$$$ (if $$$b \lt n-k$$$ and $$$a + (b+1) + \max(a, b+1) - 1 \le m$$$), then set $$$b$$$ to $$$b+1$$$. Next, we try to increase $$$a$$$ by $$$1$$$ (if $$$a \lt k-1$$$ and $$$(a+1) + b + \max(a+1, b) - 1 \le m$$$). If we cannot increase $$$a$$$, we break the loop. Finally, $$$a + b + 1$$$ (don't forget the home base) is the answer. The time complexity is $$$O(n)$$$.
#include<bits/stdc++.h>
using namespace std;
int n,k,m;
signed main(){
int T;
cin>>T;
while(T--){
cin>>n>>m>>k;
if(k-1<n-k)k=n+1-k;
int a=0,b=0;
while(1){
if(b<n-k&&a+(b+1)+max(a,b+1)-1<=m)++b;
if(a<k-1&&(a+1)+b+max(a+1,b)-1<=m)++a;
else break;
}
cout<<a+b+1<<endl;
}
}
Solve the problem in $$$O(1)$$$ or $$$O(\log n)$$$ time per test case.
2183D1 — Tree Coloring (Easy Version)
Idea & Preparation: jiazhichen844
Consider which points cannot be colored in the same operation.
Find a lower bound for the number of operations.
Suppose the number of points at depth $$$i$$$ is $$$t_i$$$. First, points at the same depth cannot be colored simultaneously, so the lower bound for the answer is $$$\max t_i$$$.
However, note that if points in layer $$$x$$$ share a common parent, they and their parent also cannot be colored simultaneously. Thus, the answer must also be compared with $$$\max(t_x + 1)$$$.
We claim this is the answer. Proof follows from the constructive proof in D2.
2183D2 — Tree Coloring (Hard Version)
Idea & Preparation: jiazhichen844
When can the minimum number of operations reach $$$\max t_i$$$? How much more than $$$\max t_i$$$ can it be at most?
We claim the maximum number of operations is $$$\max t_i + 1$$$. Consider the following constructive proof.
Let $$$S_i$$$ denote the set of points for the $$$i$$$ th operation.
Without loss of generality, let $$$T=\max t_i$$$. Find the largest $$$x$$$ such that $$$t_x=T$$$. Clearly, points with $$$d_i=x$$$ cannot be operated on simultaneously; we can place them into $$$S_1, S_2, \cdots, S_T$$$ respectively.
Then we only need to consider placing points of depth $$$\neq x$$$ into $$$S$$$. First, consider points of depth $$$ \gt x$$$. Suppose we have already placed all points of depth $$$k-1$$$. Now, when placing points of depth $$$k$$$, it is clear that each $$$S_i$$$ can contain at most one point of depth $$$k-1$$$.
Now, $$$t_{k-1}$$$ sets contain points of depth $$$k-1$$$, which impose constraints on the depth $$$k$$$ points to be placed; The remaining $$$T-t_{k-1}$$$ sets contain no points of depth $$$k-1$$$ and can freely add any point of depth $$$k$$$ (see the diagram below, where the upper red dots represent sets containing points of depth $$$k-1$$$, and the blue dots represent sets without such points).
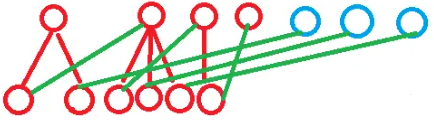
For restricted sets (where children cannot be placed), we can retain only one child and place the others into unrestricted sets. Since the number of points in the lower layer is strictly less than $$$T$$$, at least one unrestricted set will remain. At this point, we can place each retained child into the set to its right.
Next, we construct the point of depth $$$ \lt x$$$. Suppose we have already constructed the point of depth $$$k+1$$$. Now we need to place the point of depth $$$k$$$ into a set. Clearly, there are $$$t_{k+1}$$$ sets with restrictions. Assume the current number of sets is $$$a = T$$$ or $$$T + 1$$$. The number of unrestricted sets is $$$c = a - t_{k+1}$$$. We proceed with some case analysis:
- $$$a=T$$$ and $$$c=0$$$: All points at depth $$$k+1$$$ share a common parent.
This parent cannot be placed into any set. We set $$$a$$$ to $$$T+1$$$, place the parent into this new set, and assign the remaining points arbitrarily.
- Points at depth $$$k$$$ have at least two non-leaf neighbors.
We can rotate these fathers into their children's sets, placing the remaining unrestricted nodes arbitrarily.
- A node at depth $$$k$$$ has exactly one non-leaf child, and at least one set lacks any node at depth $$$k+1$$$.
Place this father into the set lacking a node at depth $$$k+1$$$, then place the remaining nodes arbitrarily.
The above process constructs a solution with either $$$T$$$ or $$$T+1$$$ sets. It yields $$$T+1$$$ sets precisely when there are $$$T$$$ points at the same depth with the same parent, making this process clearly optimal. These sets can be maintained in $$$O(n)$$$ or $$$O(n\log n)$$$ time.
Some bottom-up, directly greedy approaches are also valid, but their complexity is generally $$$O(n\log n)$$$.
This solution is from nldr.
Consider the construction scheme.
We assign each node $$$u$$$ a color $$$c_u \in {1, \dots, k}$$$ such that:
If $$$dep_u = dep_v$$$ and $$$u \neq v$$$, then $$$c_u \neq c_v$$$.
If $$$u$$$ is the parent node of $$$v$$$, then $$$c_u \neq c_v$$$.
Assign colors layer by layer based on depth. For each layer of $$$m$$$ nodes, convert it into a matching problem.
Select $$$m$$$ distinct colors from $$${1, \dots, k}$$$ to assign to these $$$m$$$ nodes, ensuring each node does not receive the color of its parent node.
Consider removing all nodes from the $d+1$th layer.
Sort them by their parent node's color. This groups child nodes constrained by the same color together.
Let the sorted nodes be $$$u_0, u_1, \dots, u_{m-1}$$$.
Let their parent node colors be $$$f_0, f_1, \dots, f_{m-1}$$$.
Define: $$$c_{u_i} = ((i + \Delta) \pmod k) + 1$$$.
Here we treat colors as a cycle $$$0 \dots k-1$$$ and attempt to assign the sorted nodes $$$m$$$ consecutive colors.
We need to find a $$$\Delta$$$ such that for all $$$i$$$, $$$(i + \Delta) \pmod k \neq f_i$$$.
That is, $$$\Delta \not\equiv (f_i - i) \pmod k$$$.
We compute all invalid $$$\Delta$$$ values (i.e., $$$(f_i - i) \pmod k$$$), yielding $$$m$$$ constraints in total.
Since there are $$$k$$$ possible values for $$$\Delta$$$ and typically $$$m \lt k$$$ or constraints overlap, by the Pigeonhole Principle, a valid $$$\Delta$$$ must exist under the lower bound definition of $$$k$$$.
In practice, because we've sorted by $$$f_i$$$, the constraints form a regular pattern—we only need $$$\Delta$$$ to avoid specific values.
We can enumerate $$$\Delta$$$ values from smallest to largest and find the first valid $$$\Delta$$$.
The complexity bottleneck lies in the sorting operation, which is $$$O(n \log n)$$$.
#include<bits/stdc++.h>
#define int long long
using namespace std;
vector<int> e[300005],v[300005],g[300005];
int n,d[300005],t[300005],id[300005],son[300005],snum[300005],fa[300005];
bool flag[300005];
void dfs(int pos,int fa)
{
::fa[pos]=fa;
d[pos]=d[fa]+1;
t[d[pos]]++;
g[d[pos]].push_back(pos);
for(int x:e[pos])
{
if(x==fa)
continue;
snum[pos]++;
dfs(x,pos);
}
}
void test()
{
cin>>n;
for(int i=1;i<=n;i++)
e[i].clear(),g[i].clear(),v[i].clear(),d[i]=t[i]=id[i]=snum[i]=0;
for(int i=1;i<n;i++)
{
int u,v;
cin>>u>>v;
e[u].push_back(v);
e[v].push_back(u);
}
dfs(1,0);
int mx=0,mt=0;
for(int i=1;i<=n;i++)
if(t[i]>=mx)
mx=t[i],mt=i;
// for(int i=1;i<=n;i++)
// cerr<<i<<" "<<fa[i]<<" "<<d[i]<<"\n";
int ans=mx;
for(int i=1;i<=mx;i++)
id[g[mt][i-1]]=i,v[i].push_back(g[mt][i-1]);
for(int i=mt+1;i<=n;i++)
{
vector<int> vfa;
for(int j:g[i-1])
{
son[j]=0;
if(snum[j])
flag[id[j]]=1;
}
int pos=1;
for(int j:g[i])
{
if(!son[fa[j]])
son[fa[j]]=j,vfa.push_back(fa[j]);
else
{
while(flag[pos])
pos++;
assert(pos<=mx);
id[j]=pos,v[pos].push_back(j),pos++;
}
}
while(flag[pos])
pos++;
assert(pos<=mx);
int lst=pos;
for(int x:vfa)
{
id[son[x]]=lst;
v[lst].push_back(son[x]);
lst=id[x];
}
for(int j:g[i-1])
flag[id[j]]=0;
}
for(int i=mt-1;i>=1;i--)
{
vector<int> vfa;
for(int j:g[i])
son[j]=0;
for(int j:g[i+1])
{
flag[id[j]]=1;
if(!son[fa[j]])
son[fa[j]]=j,vfa.push_back(fa[j]);
}
assert(!vfa.empty());
if(vfa.size()==1)
{
if(ans==t[i+1])
ans++,id[vfa[0]]=ans,v[ans].push_back(vfa[0]);
else
{
int pos=1;
while(flag[pos])
pos++;
assert(pos<=ans);
id[vfa[0]]=pos,v[pos].push_back(vfa[0]);
}
}
else
{
for(int i=0;i<vfa.size();i++)
id[vfa[i]]=id[son[vfa[(i+1)%vfa.size()]]],v[id[vfa[i]]].push_back(vfa[i]);
}
for(int j:g[i+1])
flag[id[j]]=0;
for(int x:vfa)
flag[id[x]]=1;
int pos=1;
for(int x:g[i])
if(!son[x])
{
while(flag[pos])
pos++;
assert(pos<=ans);
id[x]=pos,v[pos].push_back(x);
pos++;
}
for(int x:vfa)
flag[id[x]]=0;
}
cout<<ans<<"\n";
for(int i=1;i<=ans;i++)
{
cout<<v[i].size()<<" ";
for(int x:v[i])
cout<<x<<" ";
cout<<"\n";
}
}
signed main()
{
ios::sync_with_stdio(0);
cin.tie(0);
cout.tie(0);
int t;
cin>>t;
for(int i=1;i<=t;i++)
test();
}
2183E — LCM is Legendary Counting Master
Idea & Preparation: Gold14526
Consider the term $$$\frac{1}{\operatorname{lcm}(a_i,a_{i+1})}$$$. What properties can you derive if $$$a_i \lt a_{i+1}$$$?
Recall that $$$\frac{1}{\operatorname{lcm}(a_i,a_{i+1})} = \frac{\gcd(a_i,a_{i+1})}{a_i a_{i+1}}$$$. Notice that when $$$a_i \lt a_{i+1}$$$, the inequality $$$\gcd(a_i,a_{i+1}) \le a_{i+1}-a_i$$$ always holds.
You might have bounded the sum of the first $$$n-1$$$ terms. Try comparing the term $$$\frac{a_n-a_1}{a_1 a_n}$$$ (from the telescoping sum) with the last term $$$\frac{a_1}{a_1 a_n}$$$.
If $$$y \gt x$$$ and $$$\gcd(x,y)=y-x$$$, what does this imply about the relationship between $$$x$$$ and $$$y$$$? How many such pairs $$$(x,y)$$$ exist for $$$1\le x \lt y \le m$$$?
Note that
The equality holds if and only if $$$\gcd(a_i,a_{i+1})=a_{i+1}-a_i$$$ for all $$$1\le i \lt n$$$, and $$$a_1=1$$$. Thus, the problem is transformed into counting the number of sequences that satisfy these conditions.
The condition $$$\gcd(x,y)=y-x$$$ implies that $$$y-x$$$ is a divisor of $$$x$$$. In other words, there exists a divisor $$$d$$$ of $$$x$$$ such that $$$y=x+d$$$. Therefore, the total number of such valid pairs $$$(x,y)$$$ is only $$$\mathcal O(m \ln m)$$$. Consequently, we can easily obtain the answer using dynamic programming with a time complexity of $$$O(nm\ln m)$$$.
#include<bits/stdc++.h>
#define cint const int
#define uint unsigned int
#define cuint const unsigned int
#define ll long long
#define cll const long long
#define ull unsigned long long
#define cull const unsigned long long
using namespace std;
namespace FastIO
{
const int BUF_SIZE=1<<20;
char in_buf[BUF_SIZE],out_buf[BUF_SIZE];
char* in_ptr=in_buf+BUF_SIZE;
char* out_ptr=out_buf;
char get_char()
{
if(in_ptr==in_buf+BUF_SIZE)
{
in_ptr=in_buf;
fread(in_buf,1,BUF_SIZE,stdin);
}
return *in_ptr++;
}
void put_char(char c)
{
if(out_ptr==out_buf+BUF_SIZE)
{
fwrite(out_buf,1,BUF_SIZE,stdout);
out_ptr=out_buf;
}
*out_ptr++=c;
}
struct Flusher
{
~Flusher()
{
if(out_ptr!=out_buf)
{
fwrite(out_buf,1,out_ptr-out_buf,stdout);
}
}
} flusher;
}
#define getchar FastIO::get_char
#define putchar FastIO::put_char
inline int read()
{
int x=0;
bool zf=1;
char ch=getchar();
while(ch<'0'||ch>'9')
{
if(ch=='-')
{
zf=0;
}
ch=getchar();
}
while(ch>='0'&&ch<='9')
{
x=(x<<1)+(x<<3)+(ch^48);
ch=getchar();
}
return zf?x:-x;
}
void print(cint x)
{
if(x==0)
{
putchar('0');
return;
}
char buf[12];
int len=0,y=x;
if(y<0)
{
putchar('-');
y=-y;
}
while(y)
{
buf[len++]=(y%10)+'0';
y/=10;
}
while(len--)
{
putchar(buf[len]);
}
}
inline void princh(cint x,const char ch)
{
print(x);
putchar(ch);
}
cint N=3000,M=3000;
cint mod=998244353;
int n,m;
int a[N+1];
int dp[N+1][M+1];
vector<int>d[M+1];
int ans;
void solve()
{
n=read();
m=read();
for(int i=1;i<=n;++i)
{
a[i]=read();
}
if(a[1]>1)
{
princh(0,'\n');
return;
}
dp[1][1]=1;
for(int i=2;i<=n;++i)
{
for(int j=1;j<=m;++j)
{
dp[i][j]=0;
for(int x:d[j])
{
(dp[i][j]+=dp[i-1][j-x])>=mod?(dp[i][j]-=mod):0;
}
}
if(a[i])
{
for(int j=1;j<=m;++j)if(j!=a[i])dp[i][j]=0;
}
}
ans=0;
for(int j=1;j<=m;++j)
{
(ans+=dp[n][j])>=mod?(ans-=mod):0;
}
princh(ans,'\n');
}
int main()
{
// freopen(".in","r",stdin);
// freopen(".out","w",stdout);
for(int i=1;i<=M;++i)
{
for(int j=i;j<=M;j+=i)
{
d[j].push_back(i);
}
}
int T=read();
while(T--)solve();
return 0;
}
2183F — Jumping Man
Idea & Preparation: Neil_Qian
Calculating the sum of squares of counts is difficult.
Calculating the sum of squares of counts is difficult, so we consider transforming it into the number of ways to choose two identical strings.
Try dynamic programming.
The DP transition is continuous over the DFS sequence.
Calculating the sum of squares of counts is difficult, so we consider transforming it into the number of ways to choose two identical strings.
Let $$$f_{i,j}$$$ represent the number of ways to choose two strings located at nodes $$$i$$$ and $$$j$$$, respectively, within their subtrees. Clearly, $$$f_{i,j}$$$ has a non-zero value only if $$$c_i = c_j$$$, where $$$c$$$ denotes the string sequence.
Then, $$$f_{p,q}$$$ contributes to $$$f_{i,j}$$$ if and only if $$$p$$$ is in the subtree of $$$i$$$ and $$$q$$$ is in the subtree of $$$j$$$. By performing a depth-first search (DFS) on the tree and marking timestamps, the $$$(x, y)$$$ pairs of contributing $$$f_{p,q}$$$ must form a rectangle (as in a DFS sequence, each subtree is a range). Sorting by reverse DFS order and computing $$$2$$$ — dimensional suffix sums suffices.
The time complexity is $$$O(n^2)$$$.
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
const int MAXN = 5e3 + 10;
const int mod = 998244353;
inline void cadd(int &x, int y) { x += y, x < mod || (x -= mod); }
inline int add(int x, int y) { return x += y, x < mod ? x : x - mod; }
inline int sub(int x, int y) { return x -= y, x < 0 ? x + mod : x; }
int T, n, ans[MAXN], sum[MAXN][MAXN]; char s[MAXN];
vector<int> g[MAXN]; int in[MAXN], out[MAXN], rev[MAXN], id;
void init(int u, int f = 0) {
in[u] = ++id, rev[id] = u;
for (int v : g[u]) if (v != f) init(v, u);
out[u] = id;
}
inline
int query(int al, int ar, int bl, int br) {
return sub(add(sum[al][bl], sum[ar + 1][br + 1]), add(sum[al][br + 1], sum[ar + 1][bl]));
}
int main() {
for (scanf("%d", &T); T--; ) {
scanf("%d%s", &n, s + 1), id = 0;
for (int i = 1, u, v; i < n; i++) {
scanf("%d%d", &u, &v);
g[u].emplace_back(v), g[v].emplace_back(u);
}
init(1);
for (int i = n; i; i--) {
for (int j = n; j; j--) {
if (s[rev[i]] == s[rev[j]]) {
sum[i][j] = add(query(in[rev[i]] + 1, out[rev[i]], in[rev[j]] + 1, out[rev[j]]), 1);
}
cadd(sum[i][j], sub(add(sum[i + 1][j], sum[i][j + 1]), sum[i + 1][j + 1]));
}
}
for (int i = 1; i <= n; i++) {
printf("%d ", query(in[i], out[i], in[i], out[i]));
}
puts("");
for (int i = 1; i <= n; i++) g[i].clear();
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= n; j++) sum[i][j] = 0;
}
}
}
2183G — Snake Instructions
Idea & Preparation: xvchongyv & wangmarui
Consider under what circumstances you need to return $$$-1$$$.
When there are three consecutive snakes with speeds $$$0, x, 0$$$, we cannot determine whether $$$x$$$ is $$$1$$$ or $$$2$$$, so we need to return $$$-1$$$ in this case. In all other situations, it's easy to have a scheme that uniquely determines all snakes' speeds.
Consider what information you can get by querying the string L.
The case analysis process for this problem is not complicated.
Consider querying three fixed strings to determine all snakes' speeds.
Consider querying the three strings: L, LR, and R.
It can be observed that the sizes of the sets returned from querying L and LR are the same. The specific proof states that after querying LR, the positions of the surviving snakes are exactly their initial positions. Since the relative order of the snakes remains unchanged, performing operation R after operation L will definitely not cause any two snakes to collide. Therefore, the sizes of the returned sets are the same.
By establishing a one-to-one correspondence with the initial coordinates, we can easily deduce the speeds of all snakes that survive after performing operation L.
At this point, we only lack the speeds of the snakes that died after performing operation L. A simple case analysis reveals the following scenarios (the first number on the right represents the speed of the snake that died after operation L, and _ indicates that there is no snake at that initial position):
01.02.0_2.12.
We can directly solve the problem by classifying these cases, but the implementation might be somewhat cumbersome. Therefore, let's consider a more concise approach to the case analysis.
First, try to determine some snakes with speed $$$2$$$. For the position and speed of such a snake, the following cases allow direct determination:
- The previous snake is at a distance of $$$1$$$ and has been determined to have speed $$$1$$$.
- The previous snake is at a distance of $$$1$$$ and has not been determined. Let's explain why this snake's speed is certain in this case:
- If the previous snake's speed is $$$0$$$, it will definitely not be killed in a collision, so this case is impossible.
- If the previous snake's speed is at least $$$1$$$, then this snake must have a speed of at least $$$2$$$ to catch up and collide with the previous snake. Therefore, this snake's speed is at least $$$2$$$.
- The previous snake is at a distance of $$$2$$$ and has been determined to have speed $$$0$$$.
The case analysis above naturally eliminates the 0_2 and 12 scenarios.
Now, only the 01 and 02 cases remain. It can be observed that only the patterns 010 and 020 are indistinguishable. Therefore, we can initially ignore this situation: first find one valid solution, and then check if this solution contains such an indistinguishable pattern.
Otherwise, since the snake immediately after this one must have a speed of at least $$$1$$$ (under the condition of a unique solution), the position this snake would reach if it moved ignoring obstacles is exactly the position of the first snake whose position is $$$\ge$$$ this snake's position after performing the R query. If this snake does not come into contact with any other snake while moving right, its position can also be directly determined. Therefore, we can directly deduce the speeds of all snakes using this method.
Time complexity: $$$O(\sum n)$$$ or $$$O(\sum n \log n)$$$.
/*
OI 2025 RP++!!!
author: wmrqwq[alsu]
time: 2025/7/12
contest:
Tips:
RE, MLE?
greedy, dp?
natural time?
map, umap?
giveup rating, get score.
brute force, right solution?
%mod? std/run/maker/checker?
add bruteforce?
clear?
double, long double?
O(n)? O(n^2)!
make data!
last but not least.
bruteforce -> SegTree?
Think more.
*/
//#pragma GCC optimize("Ofast")
//#pragma GCC optimize("unroll-loops")
//#pragma GCC target("sse,sse2,sse3,ssse3,sse4,popcnt,abm,mmx,avx,avx2,tune=native")
#include<bits/stdc++.h>
using namespace std;
//#define map unordered_map
#define re register
#define ll long long
#define cll const ll
#define forl(i,a,b) for(re ll (i)=(a);i<=(b);(i)++)
#define forr(i,a,b) for(re ll (i)=(a);i>=(b);(i)--)
#define forll(i,a,b,c) for(re ll (i)=(a);i<=(b);(i)+=(c))
#define forrr(i,a,b,c) for(re ll (i)=(a);i>=(b);(i)-=(c))
#define forL(i,a,b,c) for(re ll (i)=(a);((i)<=(b)) && (c);(i)++)
#define forR(i,a,b,c) for(re ll (i)=(a);((i)>=(b)) && (c);(i)--)
#define forLL(i,a,b,c,d) for(re ll (i)=(a);((i)<=(b)) && (d);(i)+=(c))
#define forRR(i,a,b,c,d) for(re ll (i)=(a);((i)>=(b)) && (d);(i)-=(c))
#define pii pair<ll,ll>
#define mid ((l+r)>>1)
#define lowbit(x) (x&-x)
#define pb push_back
#define IOS ios::sync_with_stdio(0),cin.tie(0),cout.tie(0);
// #define endl '\n'
#define QwQ return 0;
#define db long double
#define ull unsigned long long
#define lcm(x,y) (1ll*(x)/__gcd(x,y)*(y))
#define Sum(x,y) (1ll*((x)+(y))*((y)-(x)+1)/2)
#define x first
#define y second
#define aty cout<<"Yes\n";
#define atn cout<<"No\n";
#define cfy cout<<"YES\n";
#define cfn cout<<"NO\n";
#define xxy cout<<"yes\n";
#define xxn cout<<"no\n";
#define printcf(x) x?cout<<"YES\n":cout<<"NO\n";
#define printat(x) x?cout<<"Yes\n":cout<<"No\n";
#define printxx(x) x?cout<<"yes\n":cout<<"no\n";
#define maxqueue priority_queue<ll>
#define minqueue priority_queue<ll,vector<ll>,greater<ll>>
#define bug1 cout<<"bug1,AWaDa?\n";
#define bug2 cout<<"bug2,AWaDa!\n";
#define bug3 cout<<"bug3,AKTang?\n";
#define bug4 cout<<"bug4,AKTang!\n";
#define IM (ll)1e9
#define LM (ll)1e18
#define MIM (ll)-1e9
#define MLM (ll)-1e18
#define sort stable_sort
ll rd(ll&x){cin>>x;return x;}ll rd(){ll x;cin>>x;return x;}
ll pw(ll x,ll y,ll mod){if(mod==1)return 0;if(y==0)return 1;if(x==0)return 0;ll an=1,tmp=x;while(y){if(y&1)an=(an*tmp)%mod;tmp=(tmp*tmp)%mod;y>>=1;}return an;}
ll pw(ll x){return 1ll<<x;}
template<typename T1,typename T2>bool Max(T1&x,T2 y){if(y>x)return x=y,1;return 0;}template<typename T1,typename T2>bool Min(T1&x,T2 y){if(y<x)return x=y,1;return 0;}ll Ss=chrono::steady_clock::now().time_since_epoch().count();mt19937_64 Apple(Ss);ll rand_lr(ll l,ll r){return Apple()%(r-l+1)+l;}
// cll mod=1e9+7,N=300010;ll fac[N],inv[N];void init(){fac[0]=1;forl(i,1,N-5)fac[i]=i*fac[i-1],fac[i]%=mod;inv[N-5]=pw(fac[N-5],mod-2,mod);forr(i,N-5,1)inv[i-1]=inv[i]*i%mod;}ll C(ll n,ll m){if(n<m || m<0)return 0;return (fac[n]%mod)*(inv[n-m]*inv[m]%mod)%mod;}
// void add(ll&x,ll y){x=((x+y)%mod+mod)%mod;}void del(ll&x,ll y){x=(x%mod-y%mod+mod)%mod;}
ll _t_;
struct BIT{
ll maxn;
ll tree[1000010];
void clear(ll l){
forl(i,0,l)
tree[i]=0;
}
void add(ll x,ll y){
for(;x<=maxn;x+=lowbit(x))
tree[x]+=y;
}
ll query(ll x){
ll S=0;
for(;x;x-=lowbit(x))
S+=tree[x];
return S;
}
ll query(ll l,ll r){
return query(r)-query(l-1);
}
};
// ll lg[1000010];
void Init(){
// forl(i,2,1e6+5)
// lg[i]=lg[i>>1]+1;
}
//sunny
ll n;
ll a[100010];
ll ans[100010];
vector<ll>vl,vr,vlr;
//tulpa
void ask(string s,vector<ll>&v)
{
cout<<"? "<<s<<endl;
v.pb(rd());
forl(i,1,v[0])
v.pb(rd());
}
/*
012
01
02
120
*/
void _clear(){}
void solve()
{
_clear();
vl.clear(),vr.clear(),vlr.clear();
cin>>n;
forl(i,1,n)
cin>>a[i],
ans[i]=-1;
ask("L",vl),ask("R",vr),ask("LR",vlr);
ll sz=vlr[0],L=1;
forl(i,1,n)
{
while(L<=sz && vlr[L]<a[i])
L++;
if(L<=sz && vlr[L]==a[i])
ans[i]=vlr[L]-vl[L];
}
forl(i,2,n)
if(ans[i]==-1 && ((a[i]-a[i-1]==1 && abs(ans[i-1])==1) || (a[i]-a[i-1]==2 && ans[i-1]==0)))
{
// if(ans[i-1]==-1)
// ans[i-1]=1;
ans[i]=2;
}
forl(i,1,n)
if(ans[i]==-1)
ans[i]=*lower_bound(vr.begin()+2,vr.end(),a[i])-a[i];
forl(i,1,n-2)
if(a[i]+1==a[i+1] && a[i+1]+1==a[i+2] && ans[i]+ans[i+2]==0 && ans[i+1])
{
cout<<"! "<<-1<<endl;
return ;
}
cout<<"! ";
forl(i,1,n)
cout<<ans[i]<<' ';
cout<<endl;
}
int main()
{
Init();
// freopen("tst.txt","r",stdin);
// freopen("sans.txt","w",stdout);
IOS;
_t_=1;
cin>>_t_;
while(_t_--)
solve();
QwQ;
}
2183H — Minimise Cost
Idea & Preparation: Hoks_ Special Thanks: Sorasaki_Hina
Subsequences are too hard; can we find some properties? How should we approach the case where $$$k\le n\le500$$$?
The approach for $$$k\le n\le500$$$ is too naive; how can we optimize it? What if $$$k\le n\le5000$$$?
What if we are guaranteed that the count of positive numbers $$$m \le 5000$$$?
The requirement of exactly $$$k$$$ segments, combined with the previous optimizations, suggests what technique? Consider the data constraints.
We can observe the following two conclusions:
- After sorting all elements, the subsequence we partition must correspond to a substring (contiguous segment) of the new sequence.
- If the lengths of the partitioned segments are $$$l_1, l_2, \dots, l_k$$$, then it must hold that $$$l_i \ge l_{i+1}$$$ for $$$i \in [1, k)$$$.
Define the range of a sequence $$$b$$$ as $$$[\min b_i, \max b_i]$$$.Take two subsequences $$$s_i, s_j$$$ such that their value ranges intersect. Let their lengths be $$$l_i, l_j$$$.Without loss of generality, assume $$$l_i \gt l_j$$$.Consider the set of all elements in $$$s_i$$$ and $$$s_j$$$. If we take the smallest $$$l_i$$$ elements to form a new $$$s_i$$$ and the remaining to form $$$s_j$$$, the cost decreases.
Why? Consider an element $$$a_x$$$. It is multiplied by either $$$l_i$$$ or $$$l_j$$$. We only care about elements that switch coefficients. With the split point at the $$$l_i$$$-th number, the number of elements switching from coefficient $$$l_j$$$ to $$$l_i$$$ equals the number of elements switching from $$$l_i$$$ to $$$l_j$$$. Since the array is sorted, the former elements are strictly smaller than the latter. Given $$$l_i \gt l_j$$$, switching the larger coefficient to smaller numbers reduces the total sum.By repeatedly adjusting, we arrive at the conclusion.
Based on this, we can design a brute-force DP. Let $$$f_{i,j}$$$ be the minimum weight sum for partitioning the first $$$i$$$ numbers into exactly $$$j$$$ segments.
This runs in $$$O(n^2k)$$$.
We can optimize this DP. Let $$$w(l,r) = (r-l+1)\cdot(s_r-s_{l-1})$$$. If all numbers are non-negative, the cost function satisfies the Quadrangle Inequality (QI). Using Knuth Optimization, we can reduce the complexity to $$$O(nk)$$$.
Now consider the case with negative numbers.We observe:
- For positive numbers, more segments are better (smaller coefficients).
- For negative numbers, fewer segments are better (larger coefficients).
Since $$$l_1$$$ is the largest coefficient, we prioritize assigning the negative numbers to the first segment. Let $$$m$$$ be the count of non-negative numbers.If $$$k \le m$$$, the optimal strategy is to assign a prefix (containing all negative numbers and some positive numbers) to the first segment, and partition the remaining suffix of positive numbers into $$$k-1$$$ segments.
We prove that splitting negative numbers into 2 segments is not optimal.Consider a configuration: $$$a_1, \dots, a_x$$$ (negative), $$$a_{x+1}, \dots, a_n$$$ (positive).Suppose we have a partition $$$[a_1, a_l]$$$ and $$$[a_{l+1}, a_r]$$$ where $$$l \lt x \lt r$$$. We can shift the split to $$$[a_1, a_x]$$$ and $$$[a_{x+1}, a_r]$$$.Let $$$l_1=l, l_2=x-l, l_3=r-x$$$. Let $$$S_1, S_2, S_3$$$ be the sum of absolute values in the respective ranges.The change in cost is a reduction of $$$S_1 l_2 + S_3 l_2 - S_2(l_1 - l_3)$$$.Since $$$S_3 l_2 + S_2 l_3 \ge 0$$$, we only need $$$S_1 l_2 \ge S_2 l_1$$$, or $$$S_1/l_1 \ge S_2/l_2$$$.This means the average absolute value of the earlier segment is larger. Since the array is sorted (and values are negative), the absolute values are indeed decreasing, so this holds.
If $$$k \gt m$$$, we assign each positive number to its own segment, and partition the negative numbers into the remaining segments.
Finally, consider $$$n, k \le 2 \times 10^5$$$.The constraints and the "exactly $$$k$$$ segments" requirement suggest Alien's Trick. The cost function $$$w(l,r)$$$ for positive numbers satisfies QI, implying convexity.We binary search a penalty $$$\lambda$$$. The transitions become $$$dp[i] = \min (dp[j] + w(j+1, i) + \lambda)$$$.
Combining the property that negative numbers form at most 1 segment, we notice that during the DP process, negative number segments surely cannot be decision points (transition sources).Since our optimal decision won't be in the middle of these negative numbers, if we assume $$$[1, k]$$$ are all negative numbers, we can enforce that any $$$x \in (1, k]$$$ cannot be a transition point (because transitioning from there is strictly suboptimal).We still need to keep index $$$1$$$ (or $$$0$$$ in 0-indexed terms) because the preceding numbers must be included.
This property looks naive, doesn't it?Unfortunately, we notice that after removing these transition points, the Quadrangle Inequality still does not necessarily hold.
Notice that the contribution of an element $$$x$$$ if placed in the first segment is easy to calculate. If not placed there, it will be in a segment of length $$$l \ge 1$$$ later, contributing at least $$$x$$$.This implies that if adding a number $$$x$$$ to the front generates a contribution $$$w \lt x$$$, it is better to put it in the front.This might not look different, but in fact, we can find that after greedily removing these points (suppose we greedily reached position $$$k$$$), if we restrict $$$x \in (1, k]$$$ from being transition points, the Quadrangle Inequality holds.
We consider substituting directly into the Quadrangle Inequality (referencing the formula above):
Previously, when $$$\forall i\in[1,n], a_i\ge0$$$, we had $$$s_{i+1}\ge s_i, \forall i\in[1,n)$$$, and the inequality held.When $$$a \neq 1$$$ (transition index), it obviously follows the previous formula and holds.The only special case is when $$$a$$$ could be $$$1$$$ (index 0 effectively), where $$$s_a=0, s_b \le s_c \le s_d$$$.Substituting, the left side is:
We have $$$d \gt c \gt b \gt k$$$, so $$$s_d-s_c \gt (d-c)\cdot a_b$$$. Thus:
Since $$$b \gt k$$$ (outside the greedy negative prefix), we can derive $$$b\cdot s_b \gt (b-1)\cdot s_{b-1} + a_b$$$.Here we must have $$$a_b \gt 0$$$, so $$$b\cdot s_b \gt (b-1)\cdot s_{b-1}$$$. Expanding the terms:
Substituting back into the original expression:
Thus, the Quadrangle Inequality holds.
Adding a uniform $$$lim$$$ (penalty cost) to all $$$w(l,r)$$$ clearly maintains the inequality. Therefore, the inner DP of Alien's Trick satisfies decision monotonicity.
Implementation-wise, simply use Alien's Trick wrapping a classic monotonic queue optimization (1D/1D DP), taking care to exclude non-optimal transition points.
Here is how the monotonic queue works, combined with code logic.The queue maintains current and potential future optimal decision points.Each element in the queue is not just an index $$$j$$$, but effectively represents that decision $$$j$$$ is optimal for a certain future interval.
In the Implementation code:
$$$q$$$: Stores decision point indices (the queue).
$$$lim$$$: Stores the switching boundary for decision points. $$$lim_k$$$ means that when the calculated index $$$i \gt lim_k$$$, the decision point $$$q_{k+1}$$$ in the queue becomes better than $$$q_k$$$ (i.e., the decision range of $$$q_k$$$ ends).
for(;l<r&&lim[l]<=i;l++);
dp[i]=calc(i,q[l],mid);
This part pops the front of the queue to remove suboptimal decisions. After popping, $$$q_l$$$ is the current optimal decision point, so we calculate directly.
// find(i, q[r], mid) returns a position x, meaning starting from x, decision i is better than q[r]
for(;l<r&&lim[r-1]>=find(i,q[r],mid);r--);
Due to decision monotonicity, decision $$$i$$$ will definitely take over the latter part (or even the entirety) of the interval previously controlled by the tail decision $$$q_r$$$.$$$lim_{r-1}$$$ is the starting point of $$$q_r$$$'s decision range. We compare it with the starting point where $$$i$$$ becomes better than $$$q_r$$$. If $$$i$$$ dominates $$$q_r$$$ starting before $$$q_r$$$ even becomes optimal, then $$$q_r$$$ is strictly worse and is discarded.
inline __int128 find(__int128 i,__int128 j,__int128 m){
int l=i,r=n,mid,res=n+1;
while(l<=r) c2(mid=l+r>>1,i,j,m)?res=mid,r=mid-1:l=mid+1;
return res;
}
This is a naive binary search (enabled by the monotonicity of relative optimality), finding the first position $$$x$$$ such that decision $$$i$$$ is better than $$$j$$$.
Complexity-wise, each element enters and leaves the queue at most once. Only when entering do we possibly need an extra $$$O(\log n)$$$ binary search. The total complexity is $$$O(n\log n\log V)$$$.
#include <bits/stdc++.h>
using namespace std;
#define S cerr << "SYT AK IOI" << endl;
#define M cerr << "MKF AK IOI" << endl;
using ll = long long;
using pii = pair<int, int>;
using uint = unsigned int;
using ull = unsigned long long;
mt19937 rnd(0 ^ (*new int));
// #define int long long //use it if possible
#define pb(x) push_back(x)
#define F(i, a, b) for (int i = (a), i##end = (b); i <= (i##end); ++i)
#define UF(i, a, b) for (int i = (a), i##end = (b); i >= (i##end); --i)
#define gc() getchar()
#define pc putchar
#define popcount(x) __builtin_popcount(x)
inline void init();
inline void IO();
__int128 n,k,p;
__int128 a[1000100],lim[1000100],q[1000100];
array<__int128,2>dp[1000100];
ll rd()
{
ll x;
cin>>x;
return x;
}
inline array<__int128,2> calc(__int128 i,__int128 j,__int128 x){
return (array<__int128,2>){dp[j][0]+(i-j)*(a[i]-a[j])-x,dp[j][1]+1};
}
inline bool c2(__int128 x,__int128 i,__int128 j,__int128 m){
return calc(x,j,m)>=calc(x,i,m);
}
inline __int128 find(__int128 i,__int128 j,__int128 m){
int l=i,r=n,mid,res=n+1;
while(l<=r) c2(mid=l+r>>1,i,j,m)?res=mid,r=mid-1:l=mid+1;
return res;
}
inline __int128 ck(__int128 mid){
for(__int128 i=p,l=1,r=1;i<=n;i++){
for(;l<r&&lim[l]<=i;l++);dp[i]=calc(i,q[l],mid);
for(;l<r&&lim[r-1]>=find(i,q[r],mid);r--);
lim[r]=find(i,q[r],mid);q[++r]=i;
}
return dp[n][1]<=k;
}
void print(__int128 x){if(x<0) putchar('-'),x=-x;if(x>9) print(x/10);putchar(x%10+'0');}
inline void mian()
{
// cin>>n>>k;
n=rd(),k=rd();
F(i,1,n)a[i]=rd();
sort(a+1,a+1+n);
F(i,2,n)a[i]+=a[i-1];
if(k==1){print(n*a[n]);putchar('\n');return;}
__int128 ans=(n-k+1)*a[n-k+1]+a[n]-a[n-k+1];p=1;
while(p<=n and a[p]-a[p-1]<=0)p++;
while(p<=n and p*a[p]-a[p]+a[p-1]<(p-1)*a[p-1])p++;
--p,p=max(p,(__int128)1);
if(n-p<k-1){print(ans);putchar('\n');return;}
__int128 l=-n*n*(__int128)(1e9),r=-l,mid,res=l;
while(l<=r) ck(mid=l+r>>1)?res=mid,l=mid+1:r=mid-1;
ck(res);
ans=min(ans,(__int128)k*res+dp[n][0]);
print(ans);putchar('\n');
}
signed main()
{
IO();
cin.tie(nullptr)->sync_with_stdio(false);
int T = 1;
#define multitest 1
#ifdef multitest
T=rd();
#endif
init();
while (T--)
mian();
return 0;
}
inline void init()
{
}
#define NAME(x) #x
#define INNAME(x) NAME(x)
// #define FILEIO sub3_15
inline void IO()
{
#ifdef FILEIO
freopen(INNAME(FILEIO) ".in", "r", stdin), freopen(INNAME(FILEIO) ".out", "w", stdout);
#endif
}
2183I1 — Pairs Flipping (Easy Version)
Idea & Preparation: Network_Error Special Thanks: N_z__
What if $$$s=1111\ldots$$$?
Try dividing the sequence into two equal halves, eliminating both halves by assigning odd and even lengths respectively.
Try processing recursively to reduce $$$n$$$ to a smaller scale.
Try further optimizing one of the two halves.
If $$$n$$$ is even, we only consider $$$s_1s_2\ldots s_{n-1}$$$. Now assume that $$$n$$$ is odd. Let $$$m=\frac{n-1}2$$$.
Consider dividing the $$$n$$$ numbers into the first $$$m$$$ and the last $$$m+1$$$ parts. The first $$$m$$$ are eliminated using odd lengths in $$$[1,m-1]$$$, and the last $$$m+1$$$ are eliminated using even lengths in $$$[1,m]$$$. (Assume that $$$m$$$ is even; it is similar when $$$m$$$ is odd.)
Let $$$solvePartially(l,r,p)$$$ denote the process of considering that there are 1s only in the interval $$$[l,r]$$$ and at some position $$$p$$$ outside $$$[l,r]$$$, and only using lengths in $$$[1,r-l]$$$ to eliminate. If $$$s_l=s_r=0$$$ or $$$s_l=s_r=1$$$, we operate on $$$l,r$$$ and recurse to $$$solvePartially(l+1,r-1,p)$$$; otherwise, assume that $$$s_l=1,s_r=0$$$ and $$$r \lt p$$$. If $$$p-(r-l)\in [l+1,r-1]$$$, we operate on $$$p-(r-l),p$$$ and then recurse to $$$solvePartially(l+1,r-1,l)$$$. Otherwise, the $$$1$$$ at $$$p$$$ is difficult to eliminate. Note that this situation occurs at most $$$\left\lfloor\log_3\frac{n}2\right\rfloor$$$ times, so we have obtained a solution with $$$c\le 2\left\lfloor\log_3\frac{n}2\right\rfloor+2$$$, roughly $$$24$$$ in the constraints of the problem, which is not acceptable.
Proof that the above situation occurs at most $$$\left\lfloor\log_3\frac{n}2\right\rfloor$$$ times:
- Note that the occurrence of an impossible elimination necessarily comes with $$$p-(r-l)\ge r$$$. Let $$$q+p=l+r$$$; then we must have $$$3(r-l)\le p-q$$$. Since $$$1\le r-l\le \frac{n}2$$$, it can happen at most $$$\left\lfloor\log_3\frac{n}2\right\rfloor$$$ times. In other words, each time an elimination is impossible, the interval length must reduce to $$$1/3$$$ of its original length.
In the above approach, the left and right sides are almost independent. Since operations on the left side are allowed to extend to the right side, we try to eliminate the left side completely. Let $$$solveCompletely(l,r,p)$$$ denote that the interval $$$[l,r]$$$ except for some position $$$p$$$ on the left side has been completely eliminated, and that we still need to eliminate position $$$p$$$ together with parts outside $$$[l,r]$$$. If $$$s_l=s_r=1$$$ or $$$s_l=s_r=0$$$, we eliminate $$$l,r$$$ and recurse to $$$solveCompletely(l-1,r+1,p)$$$; otherwise, assume that $$$s_l=1,s_r=0$$$, we eliminate $$$p,p+r-l$$$ and then recurse to $$$solveCompletely(l-1,r+1,l)$$$. In this way, for the left half, we can reduce it to a single remaining position $$$p$$$. Finally, we have optimised to $$$c\le \left\lfloor\log_3 \frac n2\right\rfloor+2$$$, which is below $$$14$$$ under the constraints of this problem. The code is easy to implement.
#include <bits/stdc++.h>
using namespace std;
signed main() {
ios_base::sync_with_stdio(false);
cin.tie(0);
int t;
cin >> t;
while(t--) {
int n;
cin >> n;
string a;
cin >> a;
vector<int> ops(n/2+5);
auto operate = [&](int i)->void{
if(ops[i]==0) return;
else {
a[ops[i]-1]^=1;
a[ops[i]-1+i]^=1;
}
};
auto solveCompletely = [&](auto self, int l, int r, int x)->void{
if(l>r) return;
if(a[l]==a[r]) {
if(a[l]=='1') ops[r-l]=l+1, operate(r-l);
self(self, l+1, r-1, x);
return;
}
if(x!=-1 && x<l) {
if(x+r-l>=l) {
ops[r-l]=x+1, operate(r-l);
}
} else if(x!=-1 && x>r) {
if(x-r+l<=r) {
ops[r-l]=x-r+l+1, operate(r-l);
}
}
if(a[l]=='1') {
self(self, l+1, r-1, l);
} else {
self(self, l+1, r-1, r);
}
};
auto solvePartially = [&](auto self, int l, int r)->int{
if(l>r) return -1;
if(l==r) if(a[l]=='1') return l; else return -1;
int x = self(self, l+1, r-1);
if(a[l]==a[r]) {
if(a[l]=='1') ops[r-l]=l+1, operate(r-l);
return x;
} else {
if(x!=-1) {
ops[r-l]=x+1, operate(r-l);
}
if(a[l]=='1') return l;
else return r;
}
};
solvePartially(solvePartially, 0, (n-1)/2-1);
if(n%2) solveCompletely(solveCompletely, (n-1)/2, n-1, -1);
else solveCompletely(solveCompletely, (n-1)/2, n-2, -1);
for(int i=1; i<=n/2; i++) cout << ops[i] << " ";
cout << endl;
}
return 0;
}
2183I2 — Pairs Flipping (Hard Version)
Idea & Preparation: Network_Error
In the I1 approach, we can observe that the main cost arises from isolated $$$1$$$'s outside the interval that occasionally cannot be eliminated. We consider optimizing this situation.
The following diagram illustrates a scenario where such an elimination fails:
1111111111111|1??????0|1111111111110
p l r q
Here, $$$p$$$ is the previous $$$1$$$ we could not eliminate (without loss of generality, assume $$$p \lt l$$$), the current interval being processed is $$$[l,r]$$$, and $$$l-p \ge r-l$$$ (making it impossible to eliminate directly using the previous method). $$$q$$$ is the symmetric point of $$$p$$$.
At this point, the operation lengths we can use are $$$q-p-2, q-p-4, q-p-6, \ldots, r-l$$$. Note that $$$q-p$$$ is excluded because we have already used it earlier.
Let the lengths of the three segments be $$$A$$$, $$$B$$$, and $$$C$$$, where $$$A=C$$$. This scenario is denoted as $$$F(A,B,C)$$$.
Next, we will study in detail how to eliminate for $$$F(A,B,C)$$$.
If $$$A \lt B-1$$$, we have essentially solved it in I1.
For example, in a simple case where $$$r-l = l-p$$$ and $$$s_l=1, s_r=0$$$, we can apply an operation of length $$$r-l$$$ on $$$p$$$ and $$$l$$$, thereby eliminating both $$$p$$$ and $$$l$$$ simultaneously.
For other cases, we can show that there is always a method to eliminate until only one $$$1$$$ remains, and this remaining $$$1$$$ can only be at one of the positions $$$l, l-1, l-2, r, r+1, r+2$$$. This part can be resolved through case analysis.
Specifically, we only need to consider three cases: $$$A=B$$$, $$$A=B+1$$$, or $$$A=B-1$$$. If the case falls outside these three, such as $$$A',B',C'$$$, we always shift the interval inward and transform it into $$$A'-1, B'+2, C'-1$$$.
We take $$$F(B-1,B,B-1)$$$ as an example to discuss the specific method.
We further discuss based on $$$s_l$$$ and $$$s_r$$$. For convenience, we label the positions starting from $$$p$$$ as $$$0, \ldots, q-p$$$, and use a sequence to represent the positions operated on in order of decreasing length. Let the maximum available length be $$$L = q-p-2$$$. For example, the sequence $$$0,3,1$$$ means we first use an operation of length $$$L$$$ on $$$p$$$ and $$$p+L$$$, then use an operation of length $$$L-2$$$ on $$$p+3$$$ and $$$p+3+(L-2)$$$, and finally use an operation of length $$$L-4$$$ on $$$p+1$$$ and $$$p+1+(L-4)$$$.
- $$$s_l = s_r = 0$$$. We operate in order: $$$[0,1,2,\ldots,B-4], 2B-5, B-3$$$. Finally, a $$$1$$$ remains at index $$$B-2$$$.
- $$$s_l = 1, s_r = 0$$$. We operate in order: $$$0, [(3,2),(5,4),(7,6),\ldots,(B-3,B-4)], B-1, 1$$$. Finally, a $$$1$$$ remains at index $$$B-2$$$.
- $$$s_l = 0, s_r = 1$$$. We operate in order: $$$[0,1,2,\ldots,B-3], 2B-3$$$. Finally, a $$$1$$$ remains at index $$$B-2$$$.
- $$$s_l = s_r = 1$$$. We operate in order: $$$[1,2,3,\ldots,B-2], 0$$$. Finally, a $$$1$$$ remains at index $$$2B-2$$$.
Similarly, elimination methods for $$$F(B,B,B)$$$ and $$$F(B+1,B,B+1)$$$ can be obtained.
Thus, between every two adjacent $$$1$$$'s that cannot be eliminated, we can always save one elimination, leaving a $$$1$$$ within a distance of at most $$$2$$$ from $$$l$$$ or $$$r$$$. Let the interval length be $$$s$$$. Whenever a $$$1$$$ cannot be eliminated, $$$s$$$ becomes at least $$$\frac19 s + \frac{2}{3}$$$. Therefore, the number of remaining $$$1$$$'s is approximately $$$\log_9\frac{n}{2}+O(1)$$$. Note that when the interval length is small, it may consume many $$$1$$$'s. A constant optimization is that when the recursion interval length does not exceed $$$18$$$, we can use an $$$O(n^2 2^n)$$$ dynamic programming approach to easily find the optimal solution, and the optimal solution can always leave no more than $$$1$$$ remaining $$$1$$$. Additionally, there are other optimizations, such as running the algorithm forward and backward on the sequence and taking the better result. All of these can pass.
It can be proven that when $$$n \le 2 \times 10^6$$$, the total number of $$$1$$$'s does not exceed $$$7$$$.
#include<bits/stdc++.h>
using namespace std;
const int N=2e6,DB=20;
int n,a[N+1];
int ans[N+1];
int mid;
inline void op(int x,int y)
{
if(x>y)swap(x,y);
ans[y-x]=x;
a[x]^=1;
a[y]^=1;
}
inline void del(int x,int y)
{
if(x>y)swap(x,y);
if(!ans[y-x])return;
ans[y-x]=0;
a[x]^=1;
a[y]^=1;
}
#define ppc __builtin_popcount
namespace DP{
int n;
bool f[DB+1][1<<DB+1];
int g[DB+1][1<<DB+1];
void dp()
{
n=DB;
f[n][0]=1;
for(int S=1;S<(1<<n);S<<=1)f[n][S]=1;
for(int len=n;len>=2;len-=2)
{
for(int S=0;S<(1<<n);S++)
{
if(!f[len][S])continue;
f[len-2][S]=1;
g[len-2][S]=-1;
for(int i=0;i+len-1<n;i++)
{
f[len-2][S^(1<<i)^(1<<(i+len-1))]=1;
g[len-2][S^(1<<i)^(1<<(i+len-1))]=i;
}
}
}
}
vector<int>ask(int S)
{
int len=0;
vector<int>ans(n+2);
while(len<n)
{
int pos=g[len][S];
ans[len+1]=pos;
if(pos!=-1)
{
S^=1<<pos;
S^=1<<(pos+len+1);
}
len+=2;
}
return ans;
}
}
int solvec(int l,int r,int p)
{
if(!l)return p;
if(a[l]==a[r])
{
if(a[l])op(l,r);
return solvec(l-1,r+1,p);
}
if(p)op(p,p+r-l);
if(a[l])return solvec(l-1,r+1,l);
else return solvec(l-1,r+1,r);
}
void solvep(int l,int r,int p,bool flag)
{
if(l>=r)return;
if(!p)
{
if(a[l]==a[r])
{
if(a[l])op(l,r);
solvep(l+1,r-1,0,0);
return;
}
if(a[l])solvep(l+1,r-1,l,0);
else solvep(l+1,r-1,r,0);
return;
}
if(r-l+1==DB)
{
int S=0;
for(int i=l;i<=r;++i)S|=a[i]<<(i-l);
vector<int>res=DP::ask(S);
for(int len=r-l;len>=1;len-=2)
{
if(res[len]!=-1)op(res[len]+l,res[len]+len+l);
}
return;
}
int x=l+r-p,y=p;
if(x>y)swap(x,y);
int A=l-x,B=r-l+1;
int len=y-x-2;
auto f=[&](int a){int b=a+len;len-=2,a=a+x,b=b+x;if(p>l)a=l+r-a,b=l+r-b;op(a,b);};
if(!flag&&r-l+1>=10&&abs(A-B)==1)
{
for(int i=x+1;i<l;++i)del(i,l+r-i);
int type=a[l]|(a[r]<<1);
if(p>r)type=a[r]|(a[l]<<1);
if(A==B-1)
{
switch(type)
{
case 0:for(int i=0;i<=B-4;i++)f(i);f(2*B-5);f(B-3);break;
case 1:f(0);for(int i=3;i<=B-3;i+=2)f(i),f(i-1);f(B-1);f(1);break;
case 2:for(int i=0;i<=B-3;i++)f(i);f(2*B-3);break;
case 3:for(int i=1;i<=B-2;i++)f(i);f(0);break;
}
}
else if(A==B)
{
switch(type)
{
case 0:for(int i=0;i<=B-2;i++)f(i);f(2*B-1);break;
case 1:
if(B%3==2){f(1);f(0);for(int i=3;i<=B-5;i+=3)f(i+1),f(i+2),f(i);f(B-1);f(B);f(2);}
else if(B%3==0){f(1);f(0);for(int i=3;i<=B-6;i+=3)f(i+1),f(i+2),f(i);f(B-3);f(B);f(B-1);f(2);}
else{f(1);f(0);for(int i=3;i<=B-7;i+=3)f(i+1),f(i+2),f(i);f(B-3);f(B-4);f(B);f(B-1);f(2);}
break;
case 2:f(1);f(0);for(int i=3;i<=B-3;i+=2)f(i),f(i-1);f(B-1);f(2*B-2);break;
case 3:f(0);for(int i=3;i<=B-1;i+=2)f(i),f(i-1);f(1);break;
}
}
else if(A==B+1)
{
switch(type)
{
case 0:for(int i=1;i<=B;i++)f(i);f(0);break;
case 1:for(int i=1;i<B;i++)f(i);f(0);f(B);break;
case 2:for(int i=1;i<=B-1;i+=2)f(i),f(i-1);f(2*B);break;
case 3:
if(B%3==2){f(0);f(1);for(int i=3;i<=B-2;i+=3)f(i+2),f(i),f(i+1);f(2);}
else if(B%3==0){f(1);f(0);for(int i=3;i<=B-3;i+=3)f(i+1),f(i+2),f(i);f(B);f(2);}
else{f(1);f(0);for(int i=4;i<=B-3;i+=3)f(i),f(i+1),f(i-1);f(B);f(B-1);f(2);}
break;
}
}
for(int i=x;i<=l;++i)if(a[i]){solvep(l+1,r-1,i,1);return;}
for(int i=r;i<=y;++i)if(a[i]){solvep(l+1,r-1,i,1);return;}
solvep(l+1,r-1,0,1);
return;
}
if(a[l]&&a[r])
{
op(l,r);
solvep(l+1,r-1,p,flag);
return;
}
len=r-l;
auto down=[&](){
if(a[l])solvep(l+1,r-1,l,0);
else if(a[r])solvep(l+1,r-1,r,0);
else solvep(l+1,r-1,0,0);
};
if(p+len>l&&p+len<r)
{
op(p,p+len);
down();
return;
}
if(p-len>l&&p-len<r)
{
op(p,p-len);
down();
return;
}
down();
}
int rn;
void solve()
{
cin>>n;
rn=(n>>1);
for(int i=1;i<=n;++i)
{
char ch;
cin>>ch;
a[i]=ch-'0';
}
for(int i=1;i<=n;++i)ans[i]=0;
if(!(n&1))
{
op(n-(n>>1),n);
--n;
}
mid=(n+1>>1);
if(!(mid&1))--mid;
int p=solvec((mid>>1),(mid>>1)+2,(a[(mid>>1)+1]?(mid>>1)+1:0));
solvep(mid+1,n,0,0);
for(int i=1;i<=rn;++i)cout<<ans[i]<<' ';
cout<<'\n';
}
int main()
{
DP::dp();
int T;
cin>>T;
while(T--)solve();
return 0;
}






Auto comment: topic has been updated by wangmarui (previous revision, new revision, compare).
really awesome contest , this is like my favourite contest ever i really enjoyed the problems ; ; i was like stuck on b cause my dumbass wanted to speed blitz ab to try c ;; so ended up stuck in b for almost whole contest .... ;
Awesome contest , thank you
This contest was considerably harder to me, is it div.2 level or div.2+div.1? In any case, good job on the problems, they were well defined and I liked them.
really amazing of a contest i wish i could solve D1 i did get the intuition of pairwise connected components belonging to different subsets but couldnt really solve it properly. Loved the contest tho!
H: The QI condition is definitely false if we only group together the negative prefix, e.g. take A = -100 1 1. Then, cost [-100, 1, 1] + cost [1] << cost[-100, 1] + cost[1, 1]. Instead, we need to extend our prefix until the QI condition holds (equivalently, extend it to the global optimum), and then we can run the Knuth-optimization code.
sry you're right I just find a mistake in my prove that the s_b could be a huge negative number I will fix it soon
Actually I wanted to hack this.wrong code at first. To my relief,the data is still right
There's a way to make the solution work while only excluding negatives. Note that all transitions that start at positive values are Monge. Then, we can exclude the $$$a=0$$$ transitions from the monotonicity logic and run LARSCH on the later start points, and then min with the $$$a=0$$$ transition outside the LARSCH/Monge/monotonicity.
You can also run the dp backwards, so that only positive values are considered in the dp. To get the final answer, iterate through all $$$i$$$ as the break point of the segment containing negative values. Since the dp gets the answer for every prefix (or suffix in the original sense), it's easy to get the answer in $$$O(n)$$$.
Can someone please explain in B, why for k — 1, anything greater than or equal to k−1 are invalid, is it because to maximize the MEX, we need to keep the elements less than sequence length in the array?
Yes at the end we will be left with only k-1 elements so desired elements would be 0,1,2..k-2
To make MEX ≥ k, the array must contain all numbers from 0 to k−1, but the problem’s constraint limits this, so any MEX ≥ k is invalid and the maximum allowed value is k−1.
I used a different thought-process for D1, although I do believe it's more or less the same as what the editorial talks about: -
It is easy to observe that for any particular depth $$$d$$$, no two nodes can belong to the same set (as per the problem statement). Therefore, if we let $$$N_d$$$ be the count of nodes at depth $$$d$$$, we must make at least $$$N_d$$$ moves. This leads to our first lower bound being
Now consider a specific node $$$u$$$. We know that: -
This implies that $$$u$$$ and all its children form a clique where every node should be part of a unique set. This gives us our second relation
Combining these two necessary conditions, the optimal answer is simply the maximum of these two values. Hence we arrive at our final relation
I hope this helps! :)
Submission Link
how do you write those mathy terms like that inequalities and stuff in comments??
by using LaTeX, it helps in making things more elegant and easy to explain!
Love that explanation. Not that much different from the original but much clearer in my opinion. I should have thought of that :(
thanks for your kind words!
Love the idea. However, without thinking about the construction strategy in editorial, how did you prove that the minimal answer given by the two inequalities is also achievable?
Auto comment: topic has been updated by wangmarui (previous revision, new revision, compare).
Problem C can be solved faster in $$$O(t)$$$ time ($$$O(1)$$$ time per test case):
Let $$$s_1 = max(n-k, k-1)$$$ and $$$s_2 = min(n-k, k-1)$$$. You can first try to fill the same amount in both sides $$$x$$$, which takes $$$3 * x - 1$$$ days: $$$x-1$$$ days to get the soldiers for one side, $$$x$$$ days to fill this first side, and $$$x$$$ days to fill the second side. Solving for $$$x$$$ in this specific case gives us $$$\frac{m+1}{3}$$$, and we will thus fill $$$1 + 2*\frac{m+1}{3}$$$ bases in this case.
However in the case that $$$x \geq s_2$$$, you still take $$$3*s_2 - 1$$$ time to fill $$$s_2$$$ bases on both sides, but you add $$$2$$$ days for each base you want to cover on the second longer side, because you need to wait one day to get the extra soldier and you need one more day to reach one base farther at the end. The time you have at this point is $$$m - (3*s_2 - 1)$$$. Divide this by two and you get your extra reach. Thus the final formula is $$$1 + 2 * s_2 + min(s_1 - s_2, \frac{m - 3 * s_2 + 1}{2})$$$.
I'm not entirely sure if this approach is correct, but it got me an AC so I assume it is.
yeah I did this in contest but I used a while loop to check for the x (I called it lenpath) so it was actually O(n) instead of O(1) but could easily be reduced to O(1) 356828614
i normally recieve downvotes but im not even sure what i did to get them this time
Auto comment: topic has been updated by wangmarui (previous revision, new revision, compare).
I didn't find E as easy as >1200 AC
This may be because the transformation of E is relatively common in Chinese mathematics.
Alternative solution for C using Binary Search: -
Let $$$F(S)$$$ be a boolean function that returns true if it is possible to fortify $$$S$$$ forts within the given time limit $$$M$$$. It is easy to observe that if a valid configuration of $$$S$$$ forts exists, we can trivially achieve a configuration of $$$S-1$$$ forts by simply removing the soldier at the furthest fortified node. Thus, the function $$$F(S)$$$ is monotonic, allowing us to use Binary Search for the maximum $$$S$$$.
Now consider how to optimally distribute $$$S$$$ fortified forts. We know that: -
To minimize the time required, we should balance the expansion as much as possible. Let $$$L_{cap} = K-1$$$ and $$$R_{cap} = N-K$$$ be the capacities of the left and right sides. We attempt to assign $$$P = \lfloor \frac{S-1}{2} \rfloor$$$ soldiers to each side.
The actual number of forts we can fill on each side is bounded by the capacity: -
The optimal way to fortify these is to prioritize the side that requires more soldiers to maximize the utility of the spawner while traveling. Let: -
This leads to our fundamental relation for the number of days used: -
We must also account for specific edge cases: -
If $S$ is even (i.e., $$$S-1$$$ is odd), we need 1 extra soldier on one side, costing $$$2$$$ extra time units (wait + travel).
If $$$P \gt \text{capacity}$$$ for any side, we cannot extend further on that side. This forces us to send those soldiers to the other side (or wait), adding a penalty cost of $$$2 \cdot (P - \text{capacity})$$$.
Combining these conditions, we simply check if the calculated $$$\text{Moves} \le M$$$ to update our binary search boundaries.
I hope this helps! :)
Submission Link
Damn, this is exactly my solution, Niceee
Nahh, but mine was simpler tho, no specific edge cases, check my submission
true! you've implemented it in quite a simple manner, very cool!
Guys in the editorial's approach for C, a can take values in [0;k — 1] and b can take values in [0;n — k] so shouldn't we check for all k * (n — k + 1) possibilities. Whats the reason behind trying to increment a and b in turns and how does that work
Checking k*(n-k+1) possiblities is too slow as it can easily become O(n^2) (take k=n/2, then we have about n/2*n/2=n^2/4=O(n^2) possibilities to check
Yea I got that it's too slow but we do need to prove that the faster way is correct because we do have problems where exponential solution is the fastest. I was thinking of a generalization of this problem. Let's say we are trying to find the largest subarray containing a given element which satisfies some condition (that condition should be evaluated in constant time)(in this problem that element is k th position and that condition is a + b + max(a,b) — 1 <= m.) my doubt is whether there whether it's possible to solve this in O(n). If so can u please explain it with proof of correctness? Thanks
There are multiple solutions: First of all you could speed up the brute force by setting b and the binary searching for the optimal a in O(n log n), which would prob already pass.
The next improvement is our turn-based approach. The main assumption is, that you always want to keep |a-b| as small as possible. I find it hard to formalize this, but maybe this idea helps: For a given sum a+b (our "score") lets try to keep the term a+b+max(a,b)-1 as small as possible. The part a+b-1 is constant, so we have to try and minimize max(a,b), which is given exactly if |a-b| is minimal (This is kinda intuitive I hope). Now we can always try to increase the lower one of a,b if possible in each step, so |a-b| gets minimal (this is basically done in the editorial approach). You can also do it in O(1) per query by doing some casework. I hope this helps.
is it somehow possible to solve problem E with Cauchy–Schwarz inequality?
The algebra I worked out is below.
1/a + 1/b >= 1/c
c = arr[i-1]
a = lcm(arr[i],arr[i-1])
b = arr[i]
if (c * (b+a)) >= b*a: ## valid
i was super confused about D1. i couldn't see how one solves D1 without figuring out the solution for D2. and the editorial seems to suggest that D1 should be just guessed. i think this problem is promoting bad problem solving practices, and i don't understand why this problem needed to have subproblems.
Since problems A and B both rely heavily on guessing, I tried to keep using some kind of greedy approach in D as well, hoping to simulate the answer of D1 from D2. However, the acceptance rates between D1 and D2 really confuse me.
Does D1 actually have some obvious conclusion about the number of operations, but one that’s hard to turn into a concrete solution for D2? I asked myself, but the answer was no.
I feel like anyone who can solve D1 should also be able to solve D2 — maybe it’s just a matter of implementation time? But it doesn’t even seem that hard to implement.
During the contest, in order to move fast, I relied a bit too much on some unjustified guesses in problems A and B. Anyway, thanks to the problem setters for a great contest!
Although I agree with you and I used D1 just to confirm that my Hall's theorem argument was correct, that's the current cf meta.
oh. please tell me about your hall's theorem argument! because in that case indeed such a solution would not pass D2 but is enough to pass D1. i just went straight for a lower bound and a constructive upper bound.
Start the solution from knowing that (bipartite) matching solves the problem.
Construct the matching layer by layer. It's obvious that maximizing the number of things matches is optimal and we never need to unmatch shit because when going to the next layer each unmatched node is connected to all nodes on the other side.
Now to find the max match we use the min cut max flow theorem. By using middle edges with infinity capacity, a candidade for min cut can be obtained by fixing a set of nodes from the upper layer. After fixing a set of such nodes, the cut has capacity (sum of unchosen nodes from the upper layer) + (sum of nodes from the lower layer that are connected to chosen nodes). The trick in this sort of common "complement graph bipartite matching" thing is that if we take 2 different nodes the "sum of nodes from the lower layer" is the whole layer, so there are 3 types of cuts to be considered: empty set, full set, set of size 1. For the set of size 1 we take the node in the upper layer that has the most children in the tree.
After confirming that I didn't make a dumb mistake on D1 it was a matter of finding a greedy construction for the D2 solution.
Could you please explain how did you transform this problem to bipartite matching?
I've never before seen such a nice use of bipartite matching, so finding it difficult to relate.
You can reduce the problem into "find the min number of paths in a DAG to cover all vertices" and that's a very very very very well known bipartite matching problem that I might've seen 50+ times.
Actually, I think you can also use Dilworth's theorem to get the result more directly. Evidently, any antichain either contains only nodes from layer $$$i$$$, or some nodes from layers $$$i$$$ and $$$i + 1$$$. In the second case, it can only contain one node on layer $$$i$$$, and all the chosen nodes on layer $$$i + 1$$$ must be children of that node. From this, you can get the desired bound.
yeah, I think D1 is the worst problem I've seen in a Codeforces contest in at least the past few months, probably longer because this was an intentional decision... I don't understand how it was decided that this was fine. did a problem need replacing at the last minute, and they had no choice besides slotting a hard problem in D and finding some way to split it into two subtasks?
While we are on the topic of problem D, this guy is obviously cheating (check out all his submissions on it, switches languages, very diff style, etc): https://mirror.codeforces.com/contest/2183/submission/356826472
I think figuring out the solution for D2 is easier than actually implementing it. Maybe that’s why the author decided to include subproblems, so people who understand the logic but can’t implement it fully can at least solve D1.
Here, here, here, here, here
Amazing contest
Great contest i think, especially problem D2
A typo in Tutorial (zh) Page 11, Problem E,Hint4.
It should be:
If $$$y \gt x$$$ and $$$gcd(x,y)=y−x$$$
But:
If $$$x \gt y$$$ and $$$gcd(x,y)=y−x$$$
Auto comment: topic has been updated by Network_Error (previous revision, new revision, compare).
I liked H. Been practicing dp tasks. Loved it. Hoks_ !!
Auto comment: topic has been updated by Network_Error (previous revision, new revision, compare).
Auto comment: topic has been updated by Network_Error (previous revision, new revision, compare).
There is a way to avoid any case analysis for G. Every two consecutive positions which are still alive after
LRshouldn't be too far apart. So just brute force through all possible scenarios between some two consecutive elements and get the results beforehand. When answering a query, use the results given to find the actual speeds in the stuffs calculated before.how to do C in O(1)?
356791462
I misread B in virtual contest and thought the final sequence was length k rather than k-1, which makes it a lot harder. I'm curious if there is a solution to this harder variant?
Can anybody explain in E in solution how does last term (gcd(an,a1)/a1*an) becomes a1/an*a1 , shouldnt it be (an-a1)/an*a1
gcd(a1, an) <= a1
We decided to use two different inequalities. Can we get relation using only one to get same final observation
The reason for using a different inequality was so that you can cancel the 1/an and be left with 1/a1. Hence, we are able to prove it is <= 1 because a1 >= 1
because $$$\gcd(a_1,a_n)\le a_1$$$,so partial order relation remains unchanged
Amazing Problems! Thank for the great round! Really enjoyed the problems!
You will solve C quickly if you've played generals.io.
Alternative solution for problem F. It comes more from intuition than from strict math.
Notice:
Since constraints are <= 3000, try DP with N * M states. Most obvious state is a pair of current index i and current value a[i]. Because sum is max 1, just store 2 numbers for each DP state:
There are O(N * M) states, but complexity is O(N ^ 2 * M), because we have M transitions (iterating a[i + 1] possibilities for current i and a[i]). When solving small samples by hand, we noticed that with increase of a[i + 1], final sum decreases very fast. Thus, there are not many good a[i + 1] for given a[i]. Say a[i + 1] = a[i] + x, here if x is not a divisor of a[i], lcm(a[i], a[i + 1]) grow a lot and we likely never reach sum 1. So, iterate only x's which are divisors of a[i].
That's exactly what the editorial solution actually does, it just also contains a proof of this working.
Editorial contains a lot of math. I've just showed how to come to a valid solution via less math. Path to solution is different.
Implementation is also different actually. My DP produces 2 outputs:
- Max reachable sum of 1/lcm's.
- Number of ways to construct exactly the above-mentioned sum of 1/lcm's.
And I calculate the first of them just straightforward in "double" type variable. Editorial solution seems to calculate "number of ways" without calculating the max 1/lcm's sum.Editorial does math to come up to:
The equality holds if and only if gcd(ai,ai+1)=ai+1−ai for all 1≤i<n, and a1=1. Thus, the problem is transformed into counting the number of sequences that satisfy these conditions.
I don't do anything like this, but operate directly with LCM.
Problems C and D1 would be much harder without the test cases.
is there a more intuitive proof for C's necessity
Shouldn't A be Alice and Bob, not Yes and No?
For the problem
BI understand that in the end, the array will have k-1 elements so the final MEX <= k-1, if any number from 0 to k-2 isn't in the array, then it's the final mex.
But this still doesn't sound satisfactory to me. Can anyone kindly tell me an intuitive way to think about B?
The main observation is that you can end up with any $$$k-1$$$ numbers in the array, because in every step, you have an option to remove one number from $$$k$$$ numbers, and since you're only trying not to remove $$$k-1$$$ numbers, you always have an option to remove a number you don't care about. So the answer is just the maximal MEX among any $$$k-1$$$ numbers. Then, it's clearly optimal to first take a $$$0$$$, then $$$1$$$, $$$2$$$, etc., unless you either get to a number not in the starting array (in which case the answer is MEX of the starting array) or you use all $$$k-1$$$ spots (in which case the answer is $$$k-1$$$.
The "you always have an option to remove a number you don't care about" really help me to understand the solution. Thanks a lot
Auto comment: topic has been updated by jiazhichen844 (previous revision, new revision, compare).
Auto comment: topic has been updated by jiazhichen844 (previous revision, new revision, compare).
Can anyone explain problem B? I didn't understand...
See here.
Can anyone tell where I am going wrong ? My submission
I looked at your code, and you seem to have overcomplicated things a bit. The question is esentially How far can soldiers expand in m days from position k?
Also, you hardcoded your cases for small n, when a general formula of
answer = min(n, m+1, 1+min(m, k-1) + min(m, n-k)
works.
Thanks
难:)
E is such an amazing prblem! I cant help but admire the person who set this problem
I solved 3 questions but my question how could one correctly give a solution with proof during the contest as most of times I dont know if my solution is correct or not and also the proofs in the editorial look very non-trivial, pls tell what to do?
Also is there some other solution for problem E other then the one given in the editorial and also how would one think intuitively of the solution that was given in the editorial?
Auto comment: topic has been updated by Hoks_ (previous revision, new revision, compare).
can anyone tell a better or more easily comprehendable solution of F?
dp[u][v] = answer for the problem and the current "heads" of the paths are in u, v.
$$$dp[u][v] = \sum_{a \space child \space of \space u} dp[a][v] + \sum_{b \space child \space of \space v} dp[u][b] - [str[u] \neq str[v]] \sum_{a \space child \space of \space u} \sum_{b \space child \space of \space v} dp[a][b]$$$
That straightforward dp (think of that sort of count common subsequences dp on an array to understand why the — is there for managing double counting) is quadratic because for state (u, v) we do one transition per pair of edges going down u and v, so the total number of transitions is just the number of pairs of edges which is O(N^2).
Auto comment: topic has been updated by Hoks_ (previous revision, new revision, compare).
In div2C explanation, there's some confusion regarding claim 1. I think correct version should go like this:
"Consider a soldier at x starting from k and moving to x; it must pass through base y along the way. Consider making this soldier stop exactly at y . Then soldier x ends up at y .". Also for clarity, it's worth mentioning that k always ends up containing a soldier in the end.
By the way, how this remark
(If the move is not to the leftmost positions but to some intermediate positions, we can show through adjustment that such a move is suboptimal. Therefore, an optimal solution will not contain such moves.)
can be proven? Is it really suboptimal or only the swapping doesn't make the answer worse? I can't find a counterexample which would show that.
One more doubt which I have, the proof assumes it's optimal to fill leftmost contigous interval and doesn't consider the case where it might be gaps (I know it's intuitive, but still, no proof for that). And I'm not sure if h(S1)-h(S0)>=a-t is correct. Considering we start from t soldiers at k (the only occupied base), after a-t moves, we'll have 2 bases occupied (k and k-a+t, although it's not a part of our goal and could be occupied before) instead of 1 (k-th), while soldiers count will indeed grow by a-t. So I think the h delta should be >=a-t-1 (and I don't think we need > sign here, as we constantly have to move during this phase to k-a+t and each turn, the soldiers count grow by 1?).
Auto comment: topic has been updated by Hoks_ (previous revision, new revision, compare).
hope I just fixed everything
It was an awesome contest...since I am a beginner I felt overwhelmed but still managed to get one of them...but I want to know exactly how should I approach for these types of contest...kindly guide me through this journey...it would be a great help.
Great contest, I was only able to solve the A problem but I hope to get better :)
I didn’t really like the official explanation for H, so here is an alternative one.
Observations
As shown in the editorial, there exists an optimal solution where the partition consists of contiguous subarrays after sorting $$$a$$$. We work on the sorted array.
Let ($$$m$$$) be the number of non-negative elements.
Case 1: $$$(m \gt k)$$$:
We can put each non-negative element into its own group and keep all negatives in one prefix.
The optimal partition is: one group containing the first $$$(n-k+1)$$$ elements, and the remaining elements as singleton groups.
Case 2: $$$(m \le k):$$$
All negative elements should belong to a single group, so there is at most one prefix segment containing negatives (and possibly some positives).
We apply Alien’s trick. Introduce a penalty ($$$\lambda$$$) per segment and define
$$$ dp_\lambda[i] = \min_{j \lt i}\left(dp_\lambda[j] + (s[i]-s[j])\cdot(i-j) + \lambda\right), $$$ where ($$$s$$$) is the prefix sum of the sorted array.
For the transition cost
$$$ f(l,r) = dp_\lambda[l] + (s[r]-s[l])\cdot(r-l), $$$ we have the Monge property for indices $$$(l,r \ge n-m)$$$:
$$$ \forall a \le b \le c \le d:\quad f(a,c) + f(b,d) \le f(a,d) + f(b,c), $$$ since all involved values are non-negative and the $$$(dp_\lambda)$$$ terms cancel.
Negative elements are handled separately. Since they appear in at most one prefix segment, we start transitions from index (n-m+1) and additionally relax
$$$ dp_\lambda[i] \leftarrow \min(dp_\lambda[i], f(0,i) + \lambda). $$$
Thus, DP transitions satisfy the Monge property and can be optimized with standard 1D/1D optimization trick to solve in $$$O(n \log n)$$$ which you can read online.
The first 2 hints for H are kinda useless since $$$n=k$$$ is just sum. Better to go for
only negative and only positive numbers
I think the problemsetter meant to say “Consider how to solve the problem if n,k<=500” instead of n=k=500
Would make more sense to just say $$$n = 500$$$ in that case since $$$k \le n$$$. Well, if meaning is unclear, that just highlights the necessity of making hints' meaning clear instead of letting readers engage in exegesis.
ty
Auto comment: topic has been updated by Hoks_ (previous revision, new revision, compare).
i would like to respectfully express my frustration at the implementation for D2. looking at the code makes me want to look away. upsolving is hard enough when im this sleepy
I found tin_le's implementation much easier to understand: https://mirror.codeforces.com/contest/2183/submission/356818803
Auto comment: topic has been updated by Network_Error (previous revision, new revision, compare).
Brilliant problems! However, However, I still have a question regarding the proof for Problem H.
In the part of proving QI, why does the inequality $$$bs_b-(b-1)s_{b-1}\ge 0$$$ hold even when only $$$a_1$$$ is negative. If $$$a=[-100,1]$$$ and $$$b=2$$$, for instance, the condition does not seem to be satisfied.
I remember I'very changed the prove to the new right version In current version,We define k as the largest k satisfying the partition being optimal for the preceding part. So in your example -100 and -1 must be in the same part so we don't consider position 2 so that the QI holds. In fact, even if the QI in the previous version was incorrect, the dp within it can still be optimized to be less than O(n^2). But as for me,without QI just hard to prove it could use Alien's Trick
Yes, thanks.
Was upsolving and found some solutions with O(1) time in Problem C. Can someone explain how the math is working?
there is a mistake in problem E, LCM is not legendary counting master, its actually me(LegendaryCandidateMaster)
jk jk this was a great contest thank you!
Thank you wangmarui for contest and problem.
problem I. I haven’t even proved that the final score is $$$\leq 7$$$, but my solution still got accepted even with $$$\leq 3$$$. https://mirror.codeforces.com/contest/2183/submission/363500243
Is there a proof on I1?