


** بسم الله والحمدلله والصلاة والسلام على رسول الله **
Bahnasy Tree
GitHub Repository: Bahnasy-Tree
Bahnasy Tree is a dynamic tree that represents a sequence of length $$$N$$$ (positions $$$1..N$$$). It is controlled by two parameters:
- $$$T$$$ ( threshold ): the maximum fanout a node is allowed to have before we consider it "too wide".
- $$$S$$$ ( split factor ): used when splitting; computed from the node size using the smallest prime factor (SPF). If $$$S \gt T$$$, we fallback to $$$S = 2$$$.
The tree supports the usual sequence operations (find by index, insert, delete) and can be extended to support range query / range update by storing aggregates (sum, min, etc.) and optionally using lazy propagation.
1) Node meaning and the main invariant
Each node represents a contiguous block of the sequence. If a node represents a block of length sz, then its children partition this block into consecutive sub-blocks whose lengths sum to sz.
The key invariant is: every node always knows the sizes of its children subtrees (how many leaves are inside each child).
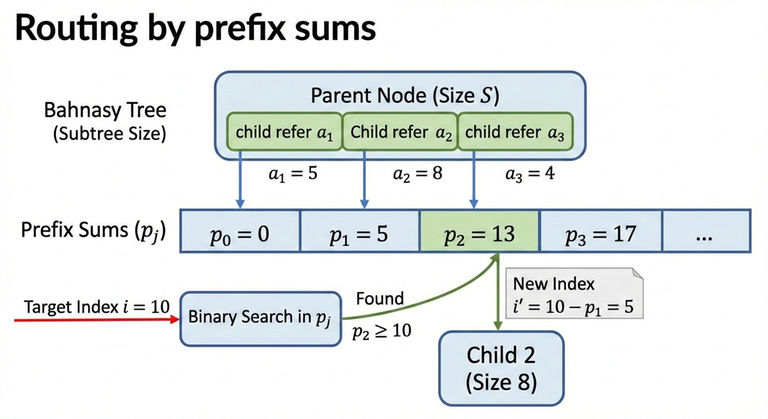
2) Prefix sizes (routing by index)
Assume a node has children with subtree sizes:
Define the prefix sums:
To route an index $$$i$$$ (1-indexed) inside this node:
- Find the smallest $$$j$$$ such that $$$p_j \ge i$$$.
- Go to that child (and convert $$$i$$$ into the child-local index by subtracting $$$p_{j-1}$$$).
Because $$$p_j$$$ is monotone, this is done using binary search ("lower bound on prefix sums").
3) Building the tree (global split using SPF)
Start with a root node representing $$$N$$$ elements.
For a node representing $$$n$$$ elements:
- If $$$n \le T$$$: stop splitting and create $$$n$$$ leaves under it.
- If $$$n \gt T$$$: split it into $$$S$$$ children:
- $$$S = \mathrm{SPF}(n)$$$
- If $$$S \gt T$$$, use $$$S = 2$$$
- Distribute the $$$n$$$ elements among those $$$S$$$ children (almost evenly), then recurse.
This guarantees that during the initial build, every internal node has at most $$$T$$$ children.
4) Find / traverse complexity
Define:
- $$$D$$$: the depth (number of levels).
- At each level, routing uses binary search on at most $$$T$$$ children, so it costs $$$O(\log_2 T)$$$.
Therefore:
In a "fully expanded" $$$T$$$-ary tree shape, depth is about:
So a direct expression is:
Now simplify using change-of-base:
Multiplying both sides by $$$\log_2 T$$$ gives:
So the final form is:
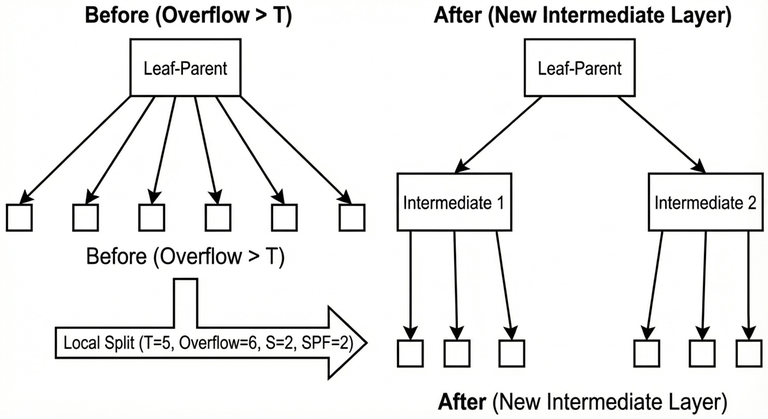
5) Insert, local overflow, and local split
Insertion happens at leaf level. After inserting a new element, the "leaf-parent" (the node whose children are leaves) increases its number of children.
As long as the leaf-parent still has at most $$$T$$$ children, nothing structural is required.
When the leaf-parent exceeds $$$T$$$ children, a local split is performed:
- A new intermediate layer is created between the leaf-parent and its leaves.
- The old leaves are grouped into $$$S$$$ buckets (where $$$S$$$ is computed by the same SPF rule capped by $$$T$$$).
This restores a bounded fanout and keeps future routing efficient.
Complexity of one local split
A local split creates about $$$\mathrm{SPF}(T+1)$$$ intermediate nodes and reconnects about $$$T+1$$$ leaves, so ignoring the SPF term, the time is:
Insert complexity
Insert cost is:
- Routing: $$$O(\log_2 N)$$$
- Plus possible local overflow handling: $$$O(T)$$$
So the worst-case insert is:
6) Delete complexity
Deletion also consists of:
- Routing to the target: $$$O(\log_2 N)$$$
- Removing it from the leaf-parent's ordered child list (bounded by the same width idea), so $$$O(T)$$$
So the worst-case delete is:
7) Why rebuild is needed
Repeated insertions concentrated in the same area can create a "deep path" because local splits keep adding intermediate layers.
Consider the worst case where local splits behave like $$$S=2$$$:
- After a local overflow, the leaves are grouped into 2 buckets of size about $$$T/2$$$.
- To overflow one bucket again and force another local split deeper, it takes about $$$T/2$$$ further insertions in that same region.
- Therefore, each new additional level costs about $$$T/2$$$ insertions.
If the current depth is $$$D$$$ and the tree is considered valid only while $$$D \le T$$$, then the number of insertions needed to reach the invalid depth threshold is approximately:
In the worst case (starting from $$$D = 0$$$):
When the tree becomes invalid, it is rebuilt.
8) Rebuild time
A rebuild does:
- Collect leaves into an array of size $$$N$$$.
- Reconstruct the tree from scratch using the global split rule.
The rebuild time is proportional to the number of nodes created.
Leaf level: $$$N$$$ nodes.
Previous levels shrink geometrically, so the maximum total node count is bounded by:
Therefore rebuild cost is:
9) Total cost of rebuilds across $$$Q$$$ operations
In the worst case, rebuild happens every $$$\Theta(T^2)$$$ insertions concentrated in one place.
So number of rebuilds is approximately:
Each rebuild costs $$$O(N)$$$, therefore total rebuild time across all operations is:
For operation costs in the same worst-style view, insertion can be treated as $$$O(T)$$$ due to local split work, so the operation part is:
Thus a total bound is:
10) Choosing a good $$$T$$$
A common practical choice is:
Because plugging $$$T = N^{1/3}$$$ into the rebuild term:
and the operations term $$$QT$$$ becomes:
so both terms become the same order:
In practice (based on testing), good values often fall in the range:
with higher values helping insertion-heavy workloads and lower values helping query-heavy workloads.
11) Worst-case tests and mitigation
Worst-case behavior happens when a test is engineered to keep inserting in exactly the same place so the tree reaches a depth close to $$$T$$$, and then many operations are issued around that hot region.
Common mitigations:
- Randomize $$$T$$$ each rebuild within a safe exponent range (e.g. $$$N^{0.27}$$$ to $$$N^{0.39}$$$).
- Randomize the rebuild target (instead of rebuilding exactly at depth $$$T$$$, rebuild at $$$(0.5/1/2/3/4)\cdot T$$$).
12) Implementations
Minimal structure-only implementation (split / split_local / find / insert / delete):
general_structure.cpp
Full implementation (find/query/update/insert/delete + rebuild):
non_generic_version.cpp
Benchmark results
Stress-testing results comparing Bahnasy Tree implementations against Treap and Segment Tree showed full agreement (no diffs) across all test suites.
| Test suite | Bahnasy variant | Reference | Tests | Bahnasy avg time | Reference avg time |
|---|---|---|---|---|---|
| All operations | non_generic_version.cpp | treap_fast.cpp | 105 | 0.202s | 0.193s |
| Point update + query | bahnasy_point_update.cpp | segTree_point_update.cpp | 18 | 0.303s | 0.218s |
| Range update + query | bahnasy_range_update.cpp | segTree_range_update.cpp | 12 | 0.274s | 0.236s |
Full benchmark logs and automated testing scripts are available in the GitHub repository under tools/ and reports/.
Tutorials:






Auto comment: topic has been updated by THE_FOOL_ON_THE_GREY_FOG (previous revision, new revision, compare).
Great work
Thank you
كنت اعاني من تساقط الشعر و لكن بعد استخدام بهنسي تري قد تم حل جميع مشاكلي
If I'm not mistaken, isn't this a version of a B-tree?
No, it may be similar in the threshold number, but the structure of Bahnasy tree is different and the rebalance in this tree is diff as well.
What did you think the 'B' in B-tree stood for?
The B-tree I know is that version I studied when learning databases, and I know B+ tree, I do not know what 'B' stood for, but after some search I found this:
The origin of "B-tree" has never been explained by the authors. As we shall see, "balanced," "broad," or "bushy" might apply. Others suggest that the "B" stands for Boeing. Because of his contributions, however, it seems appropriate to think of B-trees as "Bayer"-trees.
https://stackoverflow.com/questions/2263858/does-anybody-know-how-b-tree-got-its-name
Amazing work
Thank you
Calling complete BS, bannable in fact. Convince me why this one is useful in a single situation against the 1e7 other BBST options. The better you polish the blog withou real content, the more you waste everyone's time.
You can't just mention segment tree and treap and pretend you have proposed a better option.
Sorry if I wasted your time, but actually I mentioned treaps and segment tree to compare my tree with them as they are one of the fastest trees I know in these tasks. I did not mentioned it to say I made a better DS, but just for comparison to be fair. And it is abvious they are better or the same in avarege cases, I just published it as a new structure and the idea for just the idea. So you may use it or not, it is just for educative purpose.
It doesn't work like that. If your DS is not better in any single way, why should anyone know about it?
If you think the ideas about the DS is cool and what not, you should clearly say why, and what it is different. Make it clear, unquestionably clear that it is the focus of the blog. You cannot just write down the definitions and expect readers to help you discover why it is useful.
Besides the fact that you invented it, why should the readers not know about any of the following trees first? Red black tree, treap, implicit segment trees (mergable), scrapegoat tree, general B-tree, 64-nary or similar tree, splay, AVL tree, or leftish redblack tree or aa tree(Reasons: all rounded good tree, short and simple mergable, saves 1 log when doing small-to-large like merges, shortest BBST in code, theoretical slight generalisation of red black tree, best way to make use of AVX, good amortizations when accesing the same node, best if large number of reads due to near constnat depth, nearly identical with red-black tree but shorter and less cases)
Where is the educational part besides that I know you write a new BBST?
Edit: To be clear, you don't need to make a better DS -- it is impossible to, red-black tree is very good, but you need to give ONE (1) reason that it could be better in at least one situation.
See blog if you want an example
Good job, I feel like, whether this is actually useful or not, the idea is pretty cool, and sharing it may even allow someone to find some uses to it and/or expand further on it in the future. Keep it up.
Also, wouldn't choosing T in the form $$$2^c - 1$$$ (also in same cbrt(n) range) be a bit faster on average? Since it forces further splits to be on spf = 2 for longer depth
Yes it will be faster in average, actually I used this method in some of my implementations and it achieved a better time. Thank you for this notice.
Amazing work!
Thank you!
GREAT blog , GREAT name and GREAT pfp
Thank you, it is funny to find another fan for the fool.
Great job Great bahnos
Thank you ya coach
Good Work msa.
I suggest adding a paragraph at the beginning to tell the reader what to expect (a DS that has advantages over other Data Structures somehow — will help solve some problems easier — just a DS idea you came up with and why think interesting and want to share, ...etc).
Thank you!
It is a great idea, which solves any confusion!
appreciate it.
Thank you!
I have some questions about this tree.
rebuild_pz()may be called in all the nodes accessed in the operation?Also I think that the implementation you provided can be refactored to be more clear and to remove unnecessary code like this line, as
rebuild_pz()has already been called infind_child;Hello, I am happy that you spent time reading the code, thank you!
For the first question, when I was trying to make this DS, the main structure I had was to make the tree and split only with SPF for each node till I am on a node with prime size, and it was not a right approach then, where we may have an array with prime size, or smaller multiple of prime size, which cause the node to be heavy, then I solved this problem using the T (threshold) approach as the current structure do. So I kept it like it was, you can split using any number that is smaller than T. But the SPF ensures the splits are randomized somehow. You can play around the strucuture, it is just the idea I got then.
For the second question, the 'rebuild_pz()' are called in the find method as I late this rebuild, but logically this rebuild should be called after insert/delete node operation, so the rebuild time must be added to insert time not find, as I assumed, when explaining in the video, we have everything done when I call find function, I just late rebuild operation to enhance the insertion time. What I missed is to provide the rebuild time in the insertion time, I will update it, now the query/insert/delete all have the same time, thank you for this notice.
For the third question, can you clarify more what you mean, if you mean it is the worst-case when N =Q, I used it as worst case and spammed insert operation in the same position to satisfy the worst-case, there are some tests do this in the repo, is that what you mean? If there another worst-case you mean tell me about it to test it.
Yes, the code can be refactored, but I was lazy to do it sorry (=_=)
In the section "9) Total cost of rebuilds across Q operations" you concluded that the complexity is $$$O\left(\frac{NQ}{T^2} + QT\right)$$$, but if all the operations are inserting new item that means $$$Q = N$$$. So, the complexity is $$$O\left(\frac{N^2}{T^2} + NT\right)$$$. When $$$T = \sqrt[3]{N}$$$, the complexity is $$$O\left(N\sqrt[3]{N}\right)$$$.
Yes exactly, this is the final complexity as you mentioned, I did this simplification in the video and in the paper if I remember correctly. I appreciate that you mentioned this.
It is mentioned in the section 10.