


General Comment
I did not spend too much time on thinking about the execution time since the 6-minute is usually much more than the required in the usual online contest (e.g., 2 seconds for CodeForces for instance). So, for each problem, I took whichever way leading me to code reliably.
Also, for each problem, I did lots of stress testing since I screwed up few contests (e.g., the large input in the previous Google Code Jam) before by not fully testing my codes with respect to the full constraint given by the problem. For A and C, I generated the edge cases manually and compared the computed answers from the brute force approaches and made sure they match. For B and D, I generated the theoretical worst case to make sure they are handled properly using my codes.
Thankfully, I hit few segmentation fault problems 4-5 hours into the contest, from which I tried few approaches to increase the stack size; manipulating the size limit in #include<sys/resource.h> did the trick for me. I was so glad that I did the stress testing because if I did not there was no way that I would have spotted this issue before the submission.
As usual, just in case I found a bug in my implementations though, I waited until 5-6 hours before the submission deadline to start submitting the code; I think it is roughly the optimal time frame, since I would like to chew on the problems a bit more yet I would like to avoid a technical mishap where the URL goes down due to a crazy submission rate in the last minute.
Though I thought I did everything right, during this round, I hit an interesting problem in downloading the inputs for B and D, perhaps because I was not using my own computer (a cluster computer was being used); I am so thankful that it was resolved by contacting the contest coordinator through the feedback.
I checked my solutions with my friends', Petr's, and ahmed_aly's; thankfully, I got a match. Then I tested my codes in the Gym; after removing the system calls, I got a few TLE in D because the original limit was set too tight to 15 seconds; I changed calculating in long long to int and used few other tricks to bring down the time to where it is now: roughly 8 seconds.
10: Homework
This problem can be treated by pre-calculating the primacity using the sieve, followed by the usual trick of the cumulative sum, which was my original approach; the cumulative sum approach works since 2 ≤ A ≤ B ≤ 107 and it would be useful when T is large (say T ≤ 107 queries are asked). However, since T is so small, it suffices to calculate the number in a brute-force way, and the latter was probably the intended solution.
By the way, since the product of first 9 primes is already 223092870 > 107, when k > 8, the required answer is 0; this is precisely the idea I used to compute for the pre-calculated table.
Few ways to make the problem harder would be either making 107 as 1018 (to disable pre-calculating for the table) or making T as large as 108 (basically a constant time per query).
My Submission: 9468217
Modified Submission @CF Gym: 9468787
25: Autocomplete
This problem is a classical question on a trie; I used a fairly standard implementation that I frequently tested in various online judges, adopted from a coding contest bible by JongMan; by the way, it is a great book and you should definitely check that out. I certainly learned and am learning tons from the 2-volume set. I challenge you to find a contest material that is better than that in a book-format.
There is a plenty of room for an optimization especially since the alphabet is limited to only a, ..., z (i.e., only using an array; this is certainly an approach took by some folks), but I used my tested approach to be safe and save some debugging time, especially since the execution time was not too critical.
The system call is disabled in CodeForces Gym. So I had to submit a code without it. It worked out just fine since the default stack size was set sufficiently large.
My Submission: 9468220
Modified Submission @CF Gym: 9468711
25: Winning at Sports
This problem is a standard dynamic programming problem. Given 0 ≤ m < n ≤ 2000, it is sufficient to compute the table explicitly and a lot of contestants did it this way. However, I took the top-down approach, since we may not necessarily hit all the pre-computed values for each valid pairs (n, m) since T is, again, too small.
The key insight is perhaps the following: if we denote the desired quantity using stressfree(n, m) and stressful(n, m) then they both satisfy the recursion of the form f(n, m) = f(n - 1, m) + f(n, m - 1), with some boundary conditions. The base condition is that when either n or m is 0, the required answer is 1 and for the stress-free it is 0 when n ≤ m while for the stressful, precisely the reverse holds, n > m. It turns out we can combine these ideas together and get the answers using just one table, but for the clarity of the implementation, I made a separate function and a table for each.
In my original implementation I cleared out the table each time a pair of inputs is received, but there is no reason to do this. Notice from below that the execution time is improved by a factor of ≈ 4, but again, the execution time is not what I sought after :)
Of course, one thing to take care of is the mod since the number gets too large for some pair (n, m). This can be approached in a standard way by taking a mod in each summation step.
Although I have not tested, I am sure the same approach would work fine even when the bound is a bit larger (say 20000) or T is larger. I am curious to derive the explicit formula for the two quantities for any pairing (n, m), which can surely be done by, at least, a generating function; I originally thought about the problem using this pathway, but gave up on it since the boundary condition was tricky and the dynamic programming was more than sufficient (and easy enough to code).
Addendum: It turns out the problem is related to the Bertrand's ballot theorem/monotonic path and/or Catalan numbers. Check either the Wikipedia entry here or discussion below for more details. This is the approach I was trying first (using the generating function and etc.) but quickly resorted to the standard way since there was no real reason to think too hard about it unless I already knew the identity; now I do :)
My Submission: 9468238
Modified Submission @CF Gym: 9473189
40: Corporate Gifting
This is yet another standard dynamic programming problem, this time on a graph. The problem statement forces us to a directed acyclic graph; it is directed since it is a managerial relationship and acyclic since two employees are never responsible for each other. Also, since each node has a unique manager and the CEO has no manager, this would force us to a tree with a root at the CEO node.
For each node, we have to save the children in the adjacency list; the matrix is not feasible since N can be as large as 200K. The list would be certainly fine since we are given a tree. Once we have that, to do the DP, only thing we need to take care of is the recurrence relation.
Given that a current node uses a gift x, what is possible for the child? The only restriction is that if gift y is used for the child, y ≠ x. Respecting this, we would like to find the minimum. Of course in the leaf node, we would choose either 1 or 2, depending on whether its parent has already used 1 or not. So, we are led essentially to the following recurrent relation on a node in a tree:
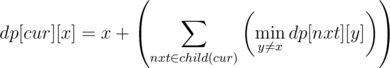
where dp[cur][x] is the minimum attained where the current node is using a gift x. So, at the end, all we need to output is dp[1][0] where 1 denotes the root node and 0 is the sentinel value not used in the computation. The only real issue now is to think about the bound on x, which turned out to be quite trickier than I originally imagined.
I originally thought that the bound has to be 3, but during the stress testing I realized that on some random instances I can get it as large as 5. Then I started comparing the result of 3, 4, 5, 10, 15, 20, and 50. While I compare those results, I tried to come up with the bound on it explicitly. Then, the crude bound I got was log2(n), which led me to believe that the bound of 20 was enough. I thought about it a little more and in the morning I improved the bound to log3(n), which led me to believe that the maximum x would be 11 when N = 200000.
Just in case I did not carry out the estimation right, I fixed my bound to 15, from 20; I did not go all the way to 11, since I did not want to cut it too close. I could not find a test case that actually used anything beyond 7 during my random search and thought it was safe enough; I figured I would check whether the answer would change if I used different bound for the provided input and surely enough no change was detected from fixing the bound to 20 or 50, from 15. So I decided to submit the version that used 15 at the end.
After the contest ended, I had a conversation with Ralph, who led me to believe that the right sequence is perhaps the order-consecutive partition, yet to be fully verified; from anyone who can prove this rigorously, I would love to get to know your insight! (See more details here) :)
My Submission: 9468244
Modified Submission @CF Gym: 9468722
Final Remark
To summarize the topics covered in this contest, they were, in short:
1) homework: sieve
2) autocomplete: trie
3) winning at sports: standard dp and Catalan number
4) corporate gifting: dp in DAG and order-consecutive partition
I started entering more online contests and take some online judges (like Timus, SGU, CodeForces Problemset) seriously. Foremost, I would like to thank paladin8 who is patiently coaching me through this entire process. I think it is working out pretty well and I will continuously put some efforts to improve! I now also have a table that keeps track of daily solved problems, coding tricks, and etc.
My current goal is to solve at least 3-5 problems/day from the Timus online judge with a goal of surpassing 500 problems by the mid-year; since I have ~260 problems down, I only have about a half way to go! If there is anyone who would like to join my pursuit to solve the problems in the Timus OJ, please let me know via a private message; I am sure I would get more motivated by a small group going through it together :P
I am hoping this entry would help at least some people out there :)
Any feedback would be much appreciated!!







In problem C, winning at sports, it was given that n>m always. Also the answer for 1-0 should be 1 1 as this is a both stressful and a stress-free victory. Right?
Indeed. I already specified 0 ≤ m < n ≤ 2000 constraint above :)
For
x-0, the answer must be1 1for anyx>0. It is a little odd that in this corner case, the definitions of stress-free and stressful match up. Not sure whether it was intentional, but since they included two corner cases of this type in the final input, I am inclined to say so.1000-0 is a very stressful victory indeed :)
I think the problem statement is vague about this and they could consider accepting both "1 0" and "1 1" answers for such cases.
Problem statement is crystal clear in that matter.
Well, then it is just me :D
I have failed D because of a wrong assumption as well.
Congratulations to all advancers!
You mentioned a book my JongMan. Can you please provide the link?
Please check a private message (PM).
Is the book publicly available? I would like to read it, too.
Please check the PM I just sent you :)
Interested in the book as well, thank you
Please check the PM I just sent you :)
Interested in the book as well, thank you
Please check the PM I just sent you :)
Interested in the book. Maybe you should give a public link. Thanks.
Please check the PM I just sent you :)
Could I get a copy as well?
Can i get a copy of the book thanks
I would like to read it too, can you tell me the title of this book :)
Thanks for your response back in the form of PM :)
I wood like to read the book too :)
Amazing! Can I have one too?
Can I get a copy as well?
Please check the PM I just sent you :)
Pls, thx!
Would you mind giving away one more !Thnx
Can I get a link to he book, please? :)
Please check the PM I just sent you :)
I am interested in the book too. Would you please provide me with a link?
Can I have the book too please?
Could you send me the link too, please?
I am also interested. Can I get a copy ??
Well, could you provide a link for this book? I would like to have a look at it. I know, this was before two weeks, but better late than never.
Intersted in the book as well, thanks.
Can someone give me a link to the book ?
I think it should be posted publicly so that anyone(years and years forth) can also read it.
I think C is much easier and can be solved using Catalan Numbers. The number of ways to get a stressful win is the Bth Catalan Number.
The number of ways to get a stress free win is
where C(N, k) is the binomial coefficient.
You can find more information here: http://en.wikipedia.org/wiki/Bertrand%27s_ballot_theorem
Awesome! This is precisely the type of "closed form" solution I was looking for during the contest; I was getting close to the Catalan numbers, but was not quite there yet. Therefore, I took the safe approach of the dynamic programming instead.
I suppose the solution I provided above works perfectly assuming a contestant 1) does not have a prior exposure to the Bertrand's ballot theorem/Catalan number or 2) want to approach the problem using the "standard programming paradigm" rather than relying on a mathematical identity.
If you check Catalan Number, the monotonic path is precisely the application equivalent to our problem. I should have tried harder to look for this connection rather than doing the dynamic programming blindly :)
But either way, I guess the inherent complexity of the code does not change by much since both solutions require Θ(n·m) computation.
Edit: there is a solution using Θ(n) computation. Check this out!
I have found first numbers of stressful victories to be "1 2 5 14 42 132" by brute-forcing all permutations of scorings. Googling that sequence led me straight to Wikipedia page on Catalan numbers. And Catalan(0) is indeed defined as 1 for convenience. My first solution gave "1 1" for the "1-0" test. But I diagnosed this as nonsense during the 6 minutes and corrected to "1 0" :)
I also debated about this for a quite awhile before I decided to go with the definition in the given problem; after all, it never specified that a given sequence of game cannot be both stress-free and stressful. It is sort of like the clopen set.. It is weird there is a set that is both open/closed intuitively, but such does because of the way each object is defined in a mathematical language.. Hope this helps?
Can someone tell me whats wrong with my solution for D? It gives a WA in the Codeforces Gym.
What I did was that, I would assign the gifts in a bottom up manner. Starting from the leafs, which would all be assigned one. For every other node, which has some children, I will store the values of the gifts of their direct children in a set, so when I have to assign a gift to any parent, I will choose the first minimum gift value which is not present in the set. This way every employee and manager should have different gifts, and the least possible gift would be selected.
This was run recursively, so for higher values of N, the stack size had to be increased.
This greedy is not optimal. Try case 0 1 1 2 for an example of when it fails (answer is 6).
Thank you. Is it possible to solve this problem using a greedy approach, or is dynamic programming necessary?
I've solved C with only one function:
9468727
The function computes the victories of the first kind. Victories of the second kind can be seen as a victory of the first kind for the second team + adding up the rest of points to the first team. There is only one way to add up the remaining points since you have no choice (the second team will not score anymore). Also, we know the first score is always greater than the second, so we can deduce the number of victories of the second kind is independent of the first team's actual score.
Indeed. I noticed quite a few contestants solving the problem in precisely the same way as you mentioned. Alternative approaches were either this or reducing the problem down(?) to the computation of the Catalan number; it is not really a "reduction" in a traditional sense since the inherent computational-complexity does not seem to change.
I would love to hear if anyone had a better solution than Θ(n·m) either in space or time (in the worst case), but at this point it seems hard to believe. But anyhow, all of these ideas point singularly towards the Catalan number so everyone should be sufficiently happy with the treatment now.
Edit: I was blindly wrong above, about the complexity. See Lewin's correction below :)
Edit: fixed links
C can be solved with linear time preprocessing and constant time per query. See here: http://mirror.codeforces.com/gym/100579/submission/9478437
The idea is basically sergioRG's, but there exists a closed from for the function he mentions.
Edit again: If you're interested in how to derive this, you can look up catalan's triangle.
I can definitely believe that; unfortunately I think I am blocked to look at the submission (it says "You are not allowed to view the requested page"), but I can definitely imagine how it would look.
I do believe it would require some sort of Θ(n·m) computation, right? It could be pre-computed and cached on a table, of course.
Edit: wrong, Lewin's approach turns out to be way better; I guess I should never assume anything :P
oops, sorry, I had coach mode enabled. Try this link: http://mirror.codeforces.com/gym/100579/submission/9478437
It only takes O(n) preprocessing, and constant time per query.
Got it :) That seems like an overkill, but definitely a solid approach, especially for a much higher constrained problem. Let me go ahead and fix my previous comments. Thanks for the heads-up. Let me know if you see any other things I might have missed in the blog entry :P
If A[k] is the ordering-consecutive partition (http://oeis.org/A007052), one can prove that there is a tree of size A[k] whose optimal solution requires k different prices:
For a given k, let's define a k-tree to be a tree that has a root of price k in all its optimal solutions. Then, a tree with a single node is a 1-tree, of size A[1] = 1. A root with two children is a 2-tree, of size A[2] = 3. A root with a single child is not a 2-tree, because the root can have price 1 (and the child 2).
A 3-tree must have at least 3 1's under its root, for otherwise I can increase the 1's into 2's, and decrease the root from 3 to 1. Similarly, a 3-tree must have at least 2 2's under its root. Therefore, we can build a 3-tree by putting under its root 3 1-trees and 2 2-trees. The size is 3 x A[1] + 2 x A[2] + 1 = A[3] = 10.
In general, we can build a k-tree by putting under its root k+1-j j-trees, for j = 1, ... , k-1. One can prove by induction that the size of this k-tree is A[k].
Since A[k] grows exponentially, the number of prizes grows at least logarithmicallly. A proof that log is also an upper bound was given here: http://mirror.codeforces.com/blog/entry/15829#comment-207606
Problem B can be solved with a c++ set
let's say that we must type the word W,
first we insert it in the set (our dictionary) as the statement says, and then we can use set's lower_bound method, and upper_bound method to find the words that more look like W, and compare these with W and compute how many characters indeed we need to type to make W.
Of course this solution is O(N log(N)) but has space O(N). With Trie sometimes the memory could be a tricky thing i guess.
If you're running the code locally, you probably have several GB of memory, so it's really not a problem.
For problem B, hashing works as well. Just make hash of each prefix of each word and insert it into a set. First hash value (prefix) of each word which is not in the set is the minimum length of that word.
Here's my code
Alternative approach to B is to put strings in a set one by one and find max length of common prefix of previous and next element at each iteration.
In D. Can we just in each subtree store two best colorings: color of root and answer for this subtree if root has some color?