


Всем привет.
Немного удивлен, что никто не создал тему. Вроде бы уже везде кончился первый тур, так что давайте пообсуждаем задачи.
UPD1. Вот гуглодока с результатами. Можете вносить свои результаты, редактирование открытое, надеюсь на адекватность сообщества. Если будет вандализм, придется перейти на формы
UPD2. Размечтался. Вносите результаты в Google форму
UPD4. Какое-то время действовал скрипт. Но к сожалению, вандалы не дремлют. Пришлось откатиться на формы+ручная копипаста
UPD5. (Автор поста уже не спит :) ). Добавлены все данные по регионам, где проводилось в Я.Контесте.
UPD6. В таблице небольшие проблемы со вторым туром. Мы работаем над проблемой и пытаемся восстановить таблицу и результаты.
UPD7. Пожалуй лучшее, что сейчас можно сделать — забыть про результаты с первого тура и заново составить таблицу уже с результатами обоих туров. Когда таблица примет более-менее адекватный вид, проверьте свой результат и напишите, если что-то не так. Извиняемся за неудобства.
UPD8. Таблица вновь работает. Добавил в пост ссылки на задания и тесты и на контесты в тренировках Codeforces.
UPD9. Теперь можно дорешивать на informatics. Добавил ссылку вниз.
# by AlexKolc: Задания и тесты
Появилось на informatics: 1, 2 тур.







В Тренировках: 2014-2015 Всероссийская олимпиада школьников по информатике, региональный этап, 1 тур.
Почему в тренировках нельзя смотреть тесты? :(
Могут те, кто способны включить тренерский режим.
А кто способен?
Если интересно, зайди в тренировки, справа будет предложение войти в тренерский режим.
нужно быть желтым в 30+ контестах или достаточно просто 30+ контестов и хотя бы раз стать желтым?
если второе, то странно, что не нахожу такой кнопки((
Не знаю. Возможно надо успеть нажать кнопку, пока был желтым, как я и сделал.
Есть где-нибудь табличка Саратовской области?
http://vk.com/wall19725188_397
Да, спасибо, их уже давно выложили :)
Кто-нибудь решил третью без декартового дерева?
Это ту задачу, в которой прямо написано: "Ребята, напишите декартку по неявному ключу. Даже не заморачивайтесь, ничего экстра сложного."?
А вот если не умеешь писать декартку? Я вот корневую написал и норм
Я тоже ее так прочитал. Но я думал, что на регионе не бывает таких структур данных.
Я. Там корневуха.
Чем хорош этот метод — разнообразием. Уже как минимум пять решений этой задачи знаю за корень.
Проходит (на 100) корневая оптимизация: разбиваем массив примерно на кусков, каждый запрос обрабатываем, меняя кусок, в котором находится наша вершина (поддерживая сумму квадратов), как будто других кусков нет. Каждые примерно
кусков, каждый запрос обрабатываем, меняя кусок, в котором находится наша вершина (поддерживая сумму квадратов), как будто других кусков нет. Каждые примерно 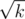 операции перестраиваем структкуру, чтобы избежать слишком различных размеров кусков и порчи асимптотики. Итого
операции перестраиваем структкуру, чтобы избежать слишком различных размеров кусков и порчи асимптотики. Итого 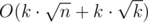 .
.
Но на самом деле там, по всей видимости, слабые тесты (заходило на 100 баллов без перестройки (sic!)).
P. S. Результаты большей части участников из СПб можно найти на neerc.ifmo.ru/school
Да, с rope.
Можно код? У меня не заходит что-то с этим rope.
Вот код: http://pastebin.com/vSrUKXsP Решение зашло на местной системе тестирования за 0.68 секунд, но на codeforces не проходит по времени.
На informatics.mccme.ru тоже не заходит. Видимо, повезло вам с тестирующей системой. ;)
Там есть простенькое дерево отрезков.
А как её с ДО на 100 сдать? У меня только на 80 получилось...
Подозреваю, что никак. ДО там как вариант для решения 3ей подзадачи.А как 3 с ДО решать?
У вас есть список предприятий, который только сокращяется. Строим ДО, с помощью которого будем искать в нём элемент с заданным номером, что аналогично поиску префикса массива с заданной суммой (сумма и есть номер элемента)
Чёрт, точно!
Спасибо большое)
Заведём массив, в котором будем хранить длины у оставшихся предприятий. Также заведём ещё фиктивный массив, который будет показывать, осталось предприятие или нет(1 если осталось. На нём мы потом будем строить ДО по сумме). И ещё один массив, в котором будем хранить указатели на следующую и предыдущую не обанкротившуюся кампанию. Во втором массиве изначально все 1.
Допустим, к нам приходит запрос на обновление. Тогда мы с помощью ДО можем найти V не убитую вершину. Далее мы её делим пополам и распихиваем по соседям с помощью третьего массива. Ну и конечно же, обновляем ДО и третий массив.
Теперь. Как с помощью ДО найти V-ую вершину? Пусть мы находимся в вершине ДО. Мы знаем, сколько ещё не убитых предприятий в левом и правом сыне. Тогда если в левом их больше, чем V, то V лежит где-то в правом сыне, и мы переходим к правому сыну, попутно вычитая из V количество предприятий в левом. Иначе идём в левого. Как только мы дошли до листа, то этот лист и является искомой вершиной.
Чем 3-я подзадача отличается от 4-й для ДО?
В третьей предприятия только удаляются. А в 4 они могут ещё и раздваиваться.
Дерево отрезков с динамической паматью. Пользуюсь тем, что начал отрезков, которыми владеют предприятия не так много (даже при раздваивании). Могу объяснить всё решение, если пока не стало понятно.
Снизу есть код pastebin.
Не можете, пожалуйста, на pastebin залить?
А то ссылка не работает.
http://pastebin.com/EE6E6y0F (Обновил до рабочего решения. Размер поддерева хранил в типе данных char...) Без проблем
Идея решения с деревом отрезков такая:
Можно хранить информацию о соответствующих предприятиях в индексах 1, 1 + a1, 1 + a1 + a2, ..., 1 + a1 + a2 + ... + an.
Написашем дерево отрезков для поиска kой единицы и присвоением элементе с индексом i. Дерево отрезков при таком запросе затрагивает
O(log(sum))вершин. Поэтому нужно хранить те вершины, которые будут посещены.Код
Но кода в этом решении примерно столько же, сколько в решении с декартовым деревом, да и использует оно
O((n + k) * log(sum))памяти.Решение с order_statistics_tree. Учитывая то, какая нам нужна функциональность, можно легко заменить его на сжатое дерево отрезков.
У нас в регионе принудительно забрали все условия. У всех так же?
Нам явно сказали, что можно брать с собой
Нет, у нас волонтеры — пофигисты :)
Мне одному показалось, что первая сложнее второй?
Во второй есть структуры данных (префиксная сумма, максимум, как кто там писал...), а в первой только перебор с формулой. Да и в первой задаче вторая подгруппа оценивается раздельно. Да и по статистике первая проще.)
Да, но обычно первая пишется с прочтения, а не вторая (да и третья). А у меня наоборот получилось.
Хотя мб проблема в том, что я долго не мог осознать, что периметр — удвоенная сумма сторон...
Я тоже не сразу понял, что такое периметр :)
Я тоже сначала думал, что периметр — это сумма сторон. Долго не мог понять, что не так с тестом из условия :)
Боль. Первая 100. Вторая 0. Третья 100. Четвертая 27.
"Я Станкевич, я придумал весь контест..."
Знал, что плохо/никак пишу Декартово дерево. Вчера наткнулся на пост о нем, подумал "может повторить?", но решил, что его же все равно не будет, потом повторю. Аукнулось :<
Если тут есть те, кто работали с Яндекс.Контестом — как всё прошло? Были ли очереди тестирования?
.
Возможно, я могу приоткрыть немного инсайдерской информации о том, как у нас в регионе это проходило и вполне могло бы проходить в любом другом регионе, у которого олимпиада проводится на чём то не особо крутом и поддерживаемом и при этом ЦМК меняет правила проведения.
Прелюдия.
Где то в декабре нам абсолютно случайно попадает информация о том, что в этом году в олимпиаде меняется два достаточно существенных правила — проверка заданий во время тура и проверка подзадач по правилам балл только за группу тестов. Наша старушка-система конечно же не была в состоянии проводить мероприятие согласно этим правилам по двум причинам. Первое — ввиду обязательности проверки во время контеста на достаточно большом количестве тестов и при этом отсутствие в явном виде в системе возможности параллельной работы сразу нескольких воркеров(чекеров) на удалённых машинах мы обеспокоились пропускной способностью системы. 4 задачи * минимум 10 попыток * 20 участников * 1 минуту в худшем случае на проверку 1 человека. Итого 800 машино/минут надо было бы выдать за 5 часов. А чекер то всего один и, как подсказывает математика, его производительность за 5 часов слегка меньше. Второе — новые правила проверки, выдача отчётов. Требуется переписывать и веб часть и сам чекер для удалённой машины. В общем, очень старая система на perl с файликами в качестве БД и очереди проверки. Допиливать её без опыта работы с perlом и без написания тестов на новый функционал — удовольствие ниже среднего.
Общий центр проверки.
Но слава богу, ЦМК обещал предоставить для регионов общий центр проверки решений на базе Я.Контеста. Казалось бы, записывайся на работу с ним и проблем нет. Но тут начинаются бюрократические трения об местных организаторов, которые не особо хотят нам выдать документ со всеми подписями и печатями, предоставляющий нашему председателю жюри права координатора. Они решают это обсудить. В этот момент мои нервы не выдерживают и я на всякий случай начинаю писать новую версию проверяющей системы. Времени то было ещё достаточно. В конечном итоге, перед самым НГ нам вроде как дают добро и мы получаем возможность официально работать с Я.Контестом. В результате, мы решаем использовать Я.Контест как основной вариант, как запасной вариант я продолжаю писать свою. Проходят новогодние каникулы. По своим убеждениям на eJudge мы посматриваем с опаской (и, видимо, не зря) — слишком много "ручек" и нюансов его работы.
О, Оу.
На первой неделе после выходных дней мы отсылаем заявку в Я.Контест и начинаем ждать ответа. Ответа не приходит до 16 января. Мои нервы не выдерживают опять и я пишу в личку VK представителю проверяющего центра с просьбой хоть как то обработать нашу заявку. Вечером этого дня нам отвечают. Наш координатор получает письмо с инструкциями, мы радостно тестим пробный тур, пишем пару сообщений жюри через интерфейс (не ляжет ли веб морда и какова оценка по длине очереди проверки, если много регионов решат переложить проверку на Я.Контест; смогут ли жюри смотреть сабмиты своих подопечных и сами потыкать систему до и во время туров) и на эти сообщения вообще почти не отвечают. Пятая точка начинает пригорать от такого расклада перед самой олимпиадой и в авральном режиме начинается поиск запасного варианта. Я уже выхожу на работу и не успеваю дописать свою, председатель жюри каким то чудом допиливает старую систему на перле под новую проверку буквально за пару дней до мероприятия, для добавления ещё одного воркера просто разводим участников на два разных сайта. Параллельно с этим как обычно мы ещё должны подготовить рабочие места, прорешать задачи и т.п. В общем, экшена выше крыши.
Итог.
Так как Я.Контест продолжает игнорить наши вопросы и пароли к нам приходят чуть ли не в день пробного тура, мы, офигевшие от такого уровня сервиса, решаем отказаться от использования Я.Контеста и проводим олимпиаду на том, что было. Все проходит нормально. В результате участники получают практически отсутствие очередей проверки при полном соблюдении правил олимпиады. Разбор пишется мною наперегонки с участниками уже прямо во время тура. Вот такой miracle :-).
Боюсь представить, что могло бы произойти в регионе в аналогичных условиях, если бы там вообще могло не оказаться людей, которые могли бы подпилить свою legacy систему или не было бы на это времени. UPD: А вот и пример.
PS: Извините за много эмоций, но это была самая нервотрёпная областная олимпиада за 5 лет моего участия в её орг. комитете.
UPD:Если кому интересно — разбор задач II тура: 1-3 задачи, 4-ая задача
Это явно завышенная оценка, предполагающая, что каждый из участников будет решать решать каждую задачу и сдаст по ней 10 решений.
На самом деле у нас, например, в среднем было 12 сабмитов от одного участника за время тура. Итого при 12 участниках получаем — 12 * 20 = 240 минут на тестирование, при времени тура в 300 минут. Конечно, это всё распределено неравномерно, но и время тестирования в 1 минуту на сабмит завышено, там не во всех задачах будет по 50 тестов.
По моей оценке один инвокер должен справляться примерно с 50 участниками, при 20 участниках дополнительные инвокеры не нужны.
Да, на практике оказалось, что участники отправили примерно в 4 раза меньше решений. Ну и мы вежливо попросили не абузить систему:-). Но если что — мы должны были быть готовы и к более активной сдаче задач и отдаче отчётов с приемлемым ожиданием для участников (у нас пару раз всего решения тестировались параллельно на обоих машинах). И задач, где обход TL является основной проблемой (хэши, перебор), могло быть больше и тогда бы они могли бы очень упорно с минимальными модификациями пытаться протолкнуть решение. В конце концов, они не должны страдать от того, что им дали права на полную проверку во время тура.
Мне очень жаль, что вам показалось что я вас игнорирую. Я наверняка переоценила свою способность оперативно отвечать быстрее чем за 4 дня (с 12 по 16 января) на письма от двадцати человек и я прошу прощения, что это принесло вам столько неудобств.
В действительности, как я рекомендовала в информационном письме, задавать вопросы о системе используя интерфейс вопроса в жюри на пробном туре не было лучшим способом получить информацию о платформе :) .
Для того, чтобы нарезать уже готовые к выдаче участникам логины и пароли основных туров, как мне показалось, суток вполне достаточно, да и таймлайн был описан в первом же письме региональному координатору, просьбы выслать раньше не поступило. Мне немного неприятно, что после достаточно вежливого отзыва уполномоченного регионального координатора вы так резко отзываетесь о проделанной мной работе, тем не менее надеюсь что в следующем году все пройдет в более удобном для вас режиме.
Ну мы же взрослые люди. Не всегда эмоциям нужно иметь место в официальных письмах. Да и когда писалось это письмо мы уже чуток поостыли.
Мы честно надеялись, что ЦМК отдаёт себе отчёт в тех процедурах, которые предлагает использовать. Что мероприятие такого уровня в Яндексе не будет организовано так, как оно было организовано, платформа будет заранее подпилена под нужды соревнования в том числе для жюри и будет учтена повышенная нервозность региональных жюри, когда они впервые вынуждены отдать техническую сторону мероприятия в аутсорс.
Ещё раз прошу простить мне весьма эмоциональный фидбэк, но я не мог не поделиться капелькой эмоций, которые испытал. В конец концов, из-за этой неразберихи мы едва не сорвали планы выхода на всерос двум нашим лучшим школьникам.
Кто-нибудь еще использовал принцип включений-исключений в первой задаче? )))
Воу. Переберем меньшую размерность до корня... ??? PROFIT!!1
Это-то да...
А ответ равен solve(B, D) - solve(A - 1, D) - solve(B, C - 1) + solve(A - 1, C - 1), где solve(X, Y) — кол-во пар (N;M), что NM ≤ X и 2(N + M) ≤ Y.
Ну да, но, как по мне, это overkill :)
А можно чуть поподробнее об этом решении?
Перебираешь меньшую сторону до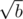
Код
Понял, спасибо!
Я пытался, с ходу не заработало, поэтому написал какой-то бинпоиск.(Если мы конечно одно и то же имеем ввиду)
Да, я так же делал. Хотя до такого решения дошёл далеко не сразу :D
Я думаю, все и так ожидали, что задачи усложнятся. Как думаете, после 180 есть какой-нибудь шанс?
Мне кажется об этом есть смысл судить только после второго тура.
А вы в каком классе?
Как вам вообще введение групп тестов с баллом только за полное прохождение и (хоть какая то компенсация, но существенный геморрой для жюри) отображение отчётов во время соревнования? Абуз таких тестов во 2ой и 3ей задаче кажется существенно понизил баллы не особо сильным участникам.
Деление по группам на регионе — моя мечта. Вечно нервировало, когда ты выходишь с маленьким, но верным баллом, а тут к тебе подбегают: "Азаза, в четвертой рандом шаффл и какое-то шаманство 60 набирает." :)
Как? Наконец-то!
Так суть же в том, чтобы отсеять сильных участников. Так что всё хорошо сделали :)
Может быть слабых?
Смотря в каком значении. Но суть всё равно ясна :)
Кто как решал четвертую?
Базовая идея в том, что фиксированному адресу соответствует небольшое количество шаблонов, поэтому прежде всего следует перебрать сам шаблон (перебирается то, сколько остается слева и сколько — справа).
Дальше задача сводится к получению количества вхождений строки в словарь (хэши или бор).
Без хаков такое не проходит все тесты, поэтому я сделал следующее: для начала сложил все шаблоны в бор (с map, конечно), подсчитав количество вхождений в вершинах; затем для очередного шаблона я перебираю только "левый" шаблон, а затем иду по бору этой строкой, при этом, проходя по символу '/', я дополнительно добавляю к ответу вершину, достижимую из текущей по ребру с символом '*', покрывая таким образом все "правые" шаблоны, соответствующие фиксированному левому.
Упорно ML'илось на VC++, но как-то зашло на G++11 =)
Говорят, заходило решение и с хэшами, но вместо map использовали массив и бинпоиск.
Забавно, но очевидное решение на Java c HashMap проходит по времени без дополнительных приседаний.
На C# аналогичная ситуация с Dictionary. Признаться говоря эта задача мне показалась слишком легкой, да и зашла она с первой попытки.
(Третья группа, но оставшиеся тоже должно проходить): запомним хэши (по модулю 264, длина строк позволяет считать по этому модулю безбоязненно) всех фильтров и отсортируем массив (пусть это v).
Для каждой строки-адреса отметим все её подстроки, являющиеся правильными адресами (их не более 25, так как всего не более 5 частей в имени сервера и в имени сегмента). Тогда понятно, что добавив (или нет)
*.в начале и/*в конце мы получим фильтры, подходящие по данную строку. Легко понять, что все подходящие фильтры получаются таким образом, а всего к одной строке подходят не более 25 + 5 + 5 + 1 = 36 фильтров.Посчитаем хэши всех этих фильтров и просуммируем количество вхождений конкретных хэшей в v. Это число и есть ответ для данного адреса.
"Асимптотика"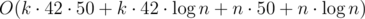 (раньше вместо 42 было 36). Получает 96 баллов. Чтобы получить 100 баллов нужно было отдельно хранить хэши для четырёх типов исходных фильтров (в зависимости от содержания/отсутствия "*." и "/*") и избегать чрезмерного копирования памяти.
(раньше вместо 42 было 36). Получает 96 баллов. Чтобы получить 100 баллов нужно было отдельно хранить хэши для четырёх типов исходных фильтров (в зависимости от содержания/отсутствия "*." и "/*") и избегать чрезмерного копирования памяти.
P. S. Как меня правильно поправили, фильтров 5·6 + 5 + 6 + 1 = 42, так как имя раздела может быть пустым.
Вообще то фильтров 42.
UPD5. (Автор поста спит). Добавлены все данные по регионам, где проводилось в Я.Контесте.
Спасибо. Проснулся, обновил пост :)
Товарищи, а правда, что на регионе не должно быть справки по языку?
По идее должны быть.
P.S. В Москве на компах у всех была папка с Корманом и Седжвиком. На вопрос организаторам в честь чего такая радость, всех заставили удалить))
Вчера на туре писал на C++ (Visual Studio 2008), возникла проблема с возвращаемым значением какой-то функции. Захожу в справку — ничего нет. Попросил помощи у организаторов. Ответ был примерно такой: "Вы идёте на олимпиаду по информатике и должны знать язык. К справке по языкам доступа нет". Есть ли в положении о проведении момент, что справка по языку должна быть? Или это на усмотрение организаторов?
В Москве — это где? В 1С не вроде не было, либо было, но [почти] никто об этом не знал. На сайте olympiads.ru висит некоторая документация, но она не очень удобная (жаль, нет зеркала cplusplus.com/reference/). А еще там доки по питону 3.4, а тестилка поддерживает только 3.2, я даже внезапно обломался на этом (чуть другие регэкспы).
В 1с во всей аудитории, где я был , на рабочем столе была папка books с книгами
Разберите B пожалуйста
Допустим мы удалили какой-то отрезок. Тогда призы можно взять либо полностью слева либо полностью справа. Насчитаем для каждого префикса и суффикса максимальную сумму, которую можно получить если он нам полностью доступен.
Пусть мы удалили отрезок [L,R]. Тогда второй получит приз в размере max(pref[L-1],suff[R+1]). Переберем все возможные удаляемые отрезки и найдём минимум этой величины.
Массивы pref и suff строятся за O(N) (типа частичных сумм) Возможных отрезков тоже O(N). Обновление ответа за О(1). Итого О(N).
Спасибо, и правда просто решается
хехе, а у нас не было проверки на конечных тестах. Kemerovo region forever :C
Это как? На тестах из условия проверяли?
Судя по тому, что я знаю (где-то ВК писали об этом), да
думаю, в Астрахани такая же песня была =)
Была. У нас вообще не было тестирующей системы.
На листочке компилировали?
А почему мой результат не захотели внести? Я конечно понимаю, что он несколько странный получился (60-100-100-100), но все же.
Возможно, просто случайно пропустили/удалили. Отправь форму ещё раз.
Класс? Барнаул не очень подходит.
Как-то я привык, что после региона город идёт) 11
Добавил.
Давайте побеседуем о задаче номер восемь.
Я бы предложил подождать еще хотя бы час, потому что в Калиниграде контест только что должен был закончится, а все-таки возможны какие-то задержки.
По положению о проведении во всех регионах старт должен быть от 5:00 до 10:00 по Москве, так что он закончился уже час как везде.
Хм. Мне казалось в 10 по местному. Вполне допускаю, что я не прав.
В Калининграде уже всё закончилось. Начало было в 9ч по местному.
Итак, для начала. Кто это придумал?)))
В каждой компоненте сильной связности есть гамильтонов цикл, который можно найти за O(n2), компоненты образуют цепочку... Дальше рассказывать?)
Рассказывай:)
Как находить гамильтонов цикл?
Инкрементально.
Давай сперва за куб. Есть цикл длины k, как его увеличить? Можно попробовать какую-нибудь вершину вставить в середину. Если никого нельзя вставить, вершины разбились на два класса -- входящие и исходящие, между этими классами есть ребро в нужную сторону (потому что сильная связность).
UPD: Просят подробнее. Если из вершины v есть ребро в цикл, а из цикла есть ребро в v, то v можно вставить в цикл. Если таких v нет, то для каждой вершины x или все рёбра из x в цикл (тип A), или все рёбра из цикла в x (тип B). Из B есть ребро в A (хотя бы одно, иначе граф не сильносвязный), найдём его, перебрав все рёбра, и удлиним таким образом цикл на две вершины.
Круто, ну а как это делать за квадрат я уже понял:)
Насколько это известный алгоритм? Я его не знал и выдумал на туре.
Алгоритм за куб достаточно известен; он обычно используется в доказательстве наличия гамильтонова цикла в сильно связном полном орграфе классе так в 7-8 на математическом кружке; наличие цепочки из всех вершин в полном орграфе ещё более известное утверждение.
О наличии алгоритма за квадрат слышу впервые.
Хорош ;-)
За куб достаточно широко известен (рассказывают на маткружках, в универе). За квадрат я первый раз познакомился с ним (тогда пришлось придумать) на сборах к межнару в 2007-м, с тех пор встречал его всего пару раз.
А можно пояснить, что дальше, когда мы уже нашли гамильтонов цикл? На туре я понял, что нужно копать в его сторону, но ни как его найти за квадрат, ни что делать дальше я не придумал. Просто даже если мы его нашли, у нас n интересующих нас рёбер, каждой проверяется за O(n^2), и того куб, как получить квадрат?
От каждой вершины v цикла есть ребро в v+1 и ребро "максимально назад по циклу" back[v]. min[l,r] -- минимум back[i] на отрезке [l,r]. Теперь наращиваем компоненту:
while min[l, r] < l: l = min[l, r]Получается проверка каждого ребра за линию.Вроде можно за квадрат из другой идеи. Давайте будем по одной вершинке добавлять, а искать перечисление КСС в топологическом порядке с указанием гамильтонова цикла в каждой КСС. Тогда новая вершина либо новая КСС, либо попадает в старую (тогда ее куда-то в цикл можно поставить), либо замыкает отрезок из КСС в одну КСС (разрываем крайние на месте соответствующих ребер, остальные произвольно и соединяем).
Огонь решение!
Да. Просто сразу очевидно, что в любом полном ориентированном графе есть цепочка. И её тоже можно найти за квадрат. А вот что с ней делать — непонятно.
Путь то да, но цикл круче.
Как обрабатывать первую компоненту сильной связности:
Изначально предположим, что ни одно ребро не меняет кол-во совершенных вершин.
Делаем
ans[k] += cnt[0] * (cnt[0] - 1) / 2;Теперь берем каждую вершину, у которой ровно одно входящее ребро. Если мы его развернем, то она единственная останется совершенной, поэтому делаем
ans[k--], ans[1]++;Берем все вершины, у которых ровно одно исходящее ребро. Если мы его развернем, то она перестанет быть совершенной (а все остальные еще будут), делаем
ans[k--], ans[k - 1]++;Но одно и то же ребро может быть посчитано два раза, тогда, очевидно, в силе первый вариант, делаем
ans[k - 1]--, ans[k]++;В чем проблема?
А в том, что это заходит.
Если обновят тесты, думаю, будет по -30 пачке людей...
Эм... На 100ку?
Да, как ни странно.
Ломается (вроде бы) на
Выдаёт
Не спорю, ломается разными способами. Но ни один из них не попал в последнюю подгруппу.
Жюри собираются что-нибудь с этим делать?
В любом случае, это не сильно что-либо поменяет. Снизятся баллы у пары-тройки людей максимум, причем вряд ли это повлияет на их проход на финал и на призерство на регионе (если оно вообще сильно важно). Лично мне важны были по большей части только качественные результаты (то, как я порешал), а наличие/отсутствие 30 баллов за решение, посланное из-за отсутствия нормальных идей в последние 5 минут контеста, погоды не сделает.
Никогда не поверю, что жюри хотя бы одного региона снимет баллы по задаче после контеста.
Согласно действующему порядку проведения всероссийской олимпиады школьников, жюри регионального этапа с этим ничего делать не будет.
Поскольку функционал жюри — проверка решений по утвержденной методике, то есть по предоставленным тестам. Выяснение того, насколько эти тесты качественно подготовлены, подготовка новых тестов в функционал жюри регионального этапа не входит. Более того, у жюри нет полномочий оценивать решения участников как-либо иначе, кроме как посредством предоставленных тестов.
По восьмой задаче вроде есть ещё такое решение.
Самая интересная часть задачи -- это переворачивание ребер в первой в топологической сортировке компоненте связности, остальные части решения такие же, как и в других решениях этой задачи.
Обозначим за k размер первой компоненты сильной связности.
Посмотрим на вершину v в этой компоненте. Поймём, какой будет ответ для ребёр, входящих в данную вершину. Рассмотрим множество вершин S, из которых идут ребра в нашу. Посмотрим на вершину u из множества S. Заметим, что если из неё идёт ребро в какую-то другую вершину w множества S, то ответ для ребра (u, v) равен k, т.к. из вершины v достижимы все вершины, в вершину u можно дойти из всех вершин, а из u в v есть путь (u – w – v). Значит единственная вершина, для ребра из которой мог поменяться ответ это вершина-сток множества S.
Мы можем найти эту вершину за O(N2 / 32) с помощью bitset-а. Для каждой вершины будем изначально хранить bitset вершин, из которых в эту вершину есть ребро. При обработке вершины v запишем в bitset множество S и для каждой вершины из S про-and-им ее bitset смежности с bitset-ом множества S. Если для какой-то вершины таким образом мы получим снова множество S, то это и есть искомая вершина t. Эта часть работает за O(N3 / 32) суммарно для всех вершин.
Теперь нам надо определить количество достижимых из v по обратным ребрам (т.к. по прямым из v мы можем дойти до любой вершины компоненты), запретив ходить по ребру (t, v). Для этого запустим из вершины v dfs, который будет хранить bitset вершин, на данный момент не достижимых из v. Изначально там все вершины компоненты кроме v. Далее при обрабатывании в dfs-е вершины u мы and-им её bitset смежности по обратным ребрам с bitset-ом недостижимых вершин и, если получившийся bitset ненулевой, запускаем dfs от всех ненулевых битов, не забывая удялять их из bitset-а недостижимых вершин. Ненулевой бит мы умеем искать за O(N / 32), изначально для каждой вершины недостижимых вершин не более N, так что асимптотика этой части и всего решения O(N3 / 32).
В Тренировках: 2014-2015 Всероссийская олимпиада школьников по информатике, региональный этап, 2 тур.
Все третью динамикой по профилю делали?
Зачем сразу профиль?
Я там написал по сути 3 одномерных динамы и всё.
О, тогда расскажи как.
Видимо, "замостить x столбцов, чтобы ничего не торчали", "замостить, чтобы торчат квадратик сверху" и "...снизу".
Ну по сути это одно и тоже. Но поскольку профилей мало, видимо легче писать так.
У меня одна одномерная (длины n*2), но я правда только на 60 сдал (думаю, можно и на 100 точно также, но я не успел). Верхние ячейки нечетные в массиве, нижние — четные. Для верхних берется сумма из двух предидущих (dp[i] = dp[i-1] + dp[i-2]), для нижних — из четырех (dp[i] = dp[i-1]+dp[i-2]+dp[i-4]*2+dp[i-5]). Надеюсь, ничего не напутал, немного подзабыл уже.
На 60 баллов это просто числа Фибоначчи.
Числа Фибоначчи — это когда только плитки 2*1
А, действительно, условия недочитал.
Рекурсивный перебор с запоминанием заходит на 60, на 100 тоже возможно, кажется, доработать, но у меня не получилось за время контеста
"Рекурсивный перебор с запоминанием...", который по сути является той же динамикой.
Я понимаю, да. Но динамику, по моему мнению, продумать несколько сложнее, чем реализовать "тупой" алгоритм, а потом допилить к нему запоминание ;)
Обычно это довольно просто трансформируется в обычную динамику.
Какие прогнозы на проходные баллы? Если брать такое же кол-во 9-10-11 классов, как в прошлом году, то для 9 классов есть вероятность, что порог задвинут ниже 400
В этом году опять есть "один представитель от региона".
Мой прогноз: 420-470-525. Может, чуть выше.
В таблице "популярна" ошибочная замена
100 100 100 70на100 100 70 0во второй день, например у Богомолова, Куликова, Лобанова и Макарова.У Лазарева еще. Только 100 100 100 50 на 100 100 50 0
Да, При одном из обновлений скрипт случайно потер данные по пятой задаче, сдвинув баллы. Извините. Мы работаем над решением этой проблемы.
Ветка обсуждения пятой задачи.
А что там обсуждать? Количество рёбер на два если нечётное, и количество рёбер на два минус количество вершин если чётное.
Да, нечего, просто для полноты списка ссылок в посте.
Ветка обсуждения шестой задачи.
Как же у меня сгорело на туре от порядка инпута в ней. Писать решение 7 минут, чтобы потом искать несуществующую багу в длинке с полчаса.
А зачем там длинка? Если нужно большое число сравнить с влезающим в long long, то можно его сперва сравнить с
4e18(или другой подходящей константой) в long double.Ну, у меня логика была такая: "Так, тут бинпоиск. Ой, переполнение. Заслал на сервер, посмотрел, есть ли int_128, не оказалось, прикинул, что чем что-то выдумывать проще написать длинку"
Можно было попробовать unsigned long long и написать аккуратно условия в бинпоиске (сначала сравнить, поделив, а потом уже обычное условие).
А ещё можно воспользоваться делением. Можно ведь поделить и прибавить 1. И сравнить со вторым множителем.
Там даже аккуратный unsigned long long. заходил
У меня на яве обычный long зашел. Но мое первое решение крашнулось тестах на шести, долго думал, что из-за того, что как раз не влезает. Оказалось, что double просто точности не хватает при делении, которое использовал для нахождения кол-ва дней, переписал все на long и зашло.
Там можно обойтись обычными long long int, если в качестве правой границы бинпоиска взять число, скажем, X/((A+B+1)/2)+2000 (вместо двух тысяч подходила, скорее всего, любая константа такого порядка). При этом переполнения не возникало
Можно было посчитать в long double, затем перевести в long long
Меня заминусуют, но я не знаю, зачем надо было придумывать что-то ещё, если можно было мгновенно написать решение в 7-14 строк на Java или на Python.
Всё очень просто — для этого надо знать джаву или питон:)
Не у всех на регионе есть джава или питон.
Но они же вроде есть в требованиях, нет?
В рекомендованных, но не в обязательных вроде.
Да тут у некоторых олимпиада вообще чёрти как проходит, а вы про питон... Так и вспоминаются золотые слова из материалов олимпиады: "В то же время, развитие в стране информационных систем проведения олимпиад по информатике с автоматической проверкой решений задач создало все условия для проведения регионального этапа во всех субъектах Российской Федерации на уровне заключительного этапа олимпиады по информатике и международной олимпиады по информатике..."
Как-то сложно всё) В простом long long всё заходило.
Там же по сути надо было проверить, что выражение ax + by >= val, где x, y, val <= 1e18 Тогда получаем, что если a > 1e18 / x или b > 1e18 / y, то значение выражения мы можем считать числом, которое заведомо больше val. Иначе это всё спокойно вмещалось в простой целочисленный тип данных.
Забавная задача, не сразу зашла
В общем, я осознал на сколько я аутист и жалею, что не нашел этот сайт раньше. Я уже точно не помню, чем руководствовался, но у меня прошло вот такое шаманство. Решение
Там же бин. поиск, ну прям очевидный. Хотя проблема с верхней границей может быть, так что я ее приблизительно определял как-то так: Исходник(C#)
А подставить значения и ручками определить верхнюю границу — для слабаков?
Можно же просто взять x
Или так. Я просто имел ввиду, что верхней границей можно считать 10^18, потому как ответ ни при каких значениях х не превысит этого значения.
У вас инты резиновые что ли?
В 64-битном C++ есть __int128_t, я через него делал
В 64-битном GCC есть __int128_t.
Или это намек на то, что Visual C++ — компилятор неведомого науке языка?
Избежать переполнения можно было так:
Можно вместо умножения делать деление.
Т.е если надо проверить a * x >= b, можно делать (a + x — 1) >= b / x.
Если вдруг надо
Регионы
Появились новые результаты регионов.