


Привет, Codeforces!
14 февраля 2015 года в 19:30 MSK состоится раунд Codeforces #291 (Div. 2) для участников из второго дивизиона.
Это мой первый Codeforces раунд. Надеюсь, он вам понравится.
Большое спасибо Максиму Ахмедову (Zlobober), Василию Антонюку (Antoniuk) за помощь в подготовке задач, Марии Беловой (Delinur) за перевод условий на английский, Михаилу Мирзаянову (MikeMirzayanov) за платформы Codeforces и Polygon.
Удачи всем!
UPD: Распределение баллов по задачам будет таким — 500-1000-2000-2000-2500.
UPD: Разбор. Простите за задержку)







wish it will be the way to DIV 1 :-)
I hope your next round will be Div. 1 too :)
This round was a Div1 itself... :D
What a shame ! I have a flight on that time. I will miss that round. I hope not to be busy at next contest on codeforces . Contests make addicted :)
You can participate virtually...
I want to be a Candidate Master...
Not everyone gets what they want. For example I want to be a potato, but I can't... Probably the fact that my name isn't GLaDOS helps.
Hey! I just chanced upon this comment, and I see you've become a Master now. Congratulations.
thanks, my dreams come true xD
I want to be a Master i wish my dreams come true like u
That's why I have no girlfriend...
yeah! that's because making out in valentines day is too mainstream for programmers :3
Unless you are a brogrammer.
Relation with Problem.........Codefoces Guy.
hope i will be blue today ...
Why do you need to write that here ?
Psss, nobody needs to write anything here
sorry if you see that I shoudn't write like this..
А условия задач будут доступны только на английском языке?
Раунды всегда и на русском, и на английском есть, это только тренировки могут быть на одном языке. Плюс автор раунда — русский, так что, скорее всего, изначально условия были написаны на русском, а потом уже переведены на английский. Ну и плюс, в анонсе раунда есть благодарность Марии Беловой за перевод задач.
Вы правы. P.S Автор не русский, но да ладно.
Живёт и учится в России* в следствии чего, наверняка, знает русский получше других языков. А так да, извини, я обратил внимание только на университет, а не на место рождения.
Why no div 1 I wanna become master:P
Have Any Problem Of Valentine's Day?
Today is the birthday of the first electronic general-purpose computer.

Happy Birthday ENIAC.
Only single yellow guys have such excellent knownledge
very interesting problem set, many thanks for not setting a valentines theme.. star wars theme was a pleasant surprise
UPD: Finally, +17:-3, including: 1 triple hack, 4 double hacks, 1 last minute hack.
Well done!
LOOOOL!!
Hopeful of being a room winner for the first time :)
Riiiiiiiiidam
tanx
I think so for myself! :D
That moment when you understand Persian :)))
I ridam too
I got WA at #6 on problem C. Anyone knows what it is about?
I solved it using a trie.
I've had WA6 too, and that test helped me... input: 1 1 a a output: NO
I got WA at #6 on problem C. Anyone knows what it is about?
I solved the problem using a Trie.
A hashmap is enough, given the constraints, i think. My approach uses m.log(n)
can you explain your solution? I also used Trie but got TLE on testcase 10.
Hey, can you please explain your approach using hashmap. I couldn't solve the problem during the contest. But have to solve it anyhow, now.
Try this
2 1
aaa
aab
aaa
answer:
YES
It works on this case.
I've used hashing. It gives right for your test but fails on test #6.
This is test case 6, I think
I think I found the case:Answer: NO, because there should be exactly 1-symbol difference.Oops, didn't notice comment on the bottom
I think Pretest 6 has a string equal to original string, when problem says they must differ by exactly one position. Such as this, output should be "NO":
1 1
a
a
OMG! Thanks...
You're right :-(. I didn't pay attention to '**exactly** one position'. Now it works. Thanks!
Как решать С без хешей? А то один японец в моей комнате сломал поголовно всех, кроме сдавших ее на последних минутах.
Я думал о каком нибудь Ахо-Корасике или Укконене, но придумать что с ними нормально сделать — не смог
Я написал бор, не знаю упадет ли, но как мне кажется, вроде должен заходить.
UPD: загоняем все строки исходные в бор, затем когда нужно получить ответ, нужно пройтись по бору dfs-ом, с параметрами (curNodeInTrie, curPositionInString, hadDif) как только нашли ответ сразу же вернем его.
Погенерил тесты, вроде нормально, а вообще: сейчас систесты покажут =)
UPD: бор зашел за 184 мс
Code Here
А можно поконкретней с бором?
Я, например, решал так: записал весь вход в бор, потом для каждого примера шел по бору и записывал все существующие ответвления. Потом от каждого ответвления пытался найти окончание примера. В какой-то момент на контесте пришло понимание, почему это работает быстро(кажется, не медленнее, чем n*sqrt(n)), но сейчас опять забыл =(.
Как именно в этой задаче можно использовать бор?
У меня хорошое решение с бором + хэшами.
В вершинке бора храним набор хэшей суффиксов тех строк, у которых есть данный префикс, потом перебираем совпадающий префикс (и, соответственно, двигаемся по бору), идём по всем рёбрам из текущей вершины кроме того, которое должно быть при добавлении строки запроса в бор, находим совпадающий хэш с хэшом суффикса строки запроса — YES, иначе продолжаем искать. Дошли до префикса длиной во всю строку — NO.
написал тоже самое, забыл про условие, что различие в 1 букве нужно обязательно. :(
Я тоже использовал бор, но не знаю: "пройдет ли финальные тетсы?". Вот код: 9848296.
Прошло :)
А почему это будет быстро работать?
Мне казалось, что решение с бором будет работать за O(len2). Типа нам придется ответвиться от каждой буквы и пройти оставшуюся длину строки
Чтобы была возможность ответвиться по букве на позиции х, нам нужно скормить бору строку, которая совпадает с запросом на префиксе длины х-1 и отличается в позиции х. Очевидно, что при заданном запросе одна строка словаря подходит не более чем для одного х.
Поэтому возможных ветвлений будет порядка корня из суммарной длины. Для "длинных" строк из запросов — мы можем обойти весь бор, но таких строк будет немного (не больше корня, из-за ограничения на размер входных данных). Для "коротких" строк из запросов — на каждой ветке перебора мы можем зайти не дальше длины строки, а веток будет не больше корня; общее число операций будет не больше суммарной длины таких строк, умноженной на число веток.
Таким образом получаем асимптотику L*sqrt(L), где L — размер инпута.
Написал примерно то же самое, решил обновить страницу до публикации — и увидел, что опоздал =) Красныйбыстр...
Так он всё-таки искал коллизии? Меня он вроде бы взломал, потому что бинпоиск был кривой.
Он использовал тест отсюда
Спасибо, не знал про эту фишку. Но ведь тогда можно было написать хэш по какому-нибудь другому модулю порядка 2^64, а такое вряд ли ломается даже атакой дней рождения.
Перемножить два числа порядка 2^64 — не самый простой код. Поэтому обычно и берут порядка 10^9. Можно даже несколько модулей таких.
10^9 плохо, потому что как раз ломается атакой дней рождения (т.е. за O(sqrt(n)*log(n)), насколько я понимаю). Если брать несколько модулей, то есть способ разделаться с каждым по отдельности, а затем скомбинировать, но строка, скорее всего, получится слишком длинной. А в чём проблема с 2^64, long long же просто? Брать по модулю 10^16+3 после каждого умножения (в качестве основания пойдёт что-то трёхзначное).
Проблема использования 10^16 + 3 проявится, если мы захотим по хешам на префиксах считать хеш для подстроки (описание на e-maxx).
А в чём проблема, собственно? Все те же рассуждения переносятся с 2^64 на любой другой модуль. Просто с точки зрения кода чуть сложнее, т.к. в некоторых местах придётся вставлять A%=P или A=(A%P+P)%P.
Умножение по модулю 2^64 — естественно и быстро. А умножение по модулю 10^16+3 — как-то не очень. В куске, который по ссылке оформлен как i1 < i2 && h1 * p_pow[i2-i1] == h2 || i1 > i2 && h1 == h2 * p_pow[i1-i2], нам нужно умножить два больших числа по модулю третьего большого числа, что дает переполнение. Приходится что-нибудь придумывать — например, делать Russian peasant multiplication (проще говоря, бинарное умножение), но это + к количеству кода и времени работы.
Как же вы посчитаете "h1 * p_pow[i2-i1]" (из статьи) по модулю 10^16 + 3, где h1 и p_pow[i2-i1] — это числа от 0 до 10^16 + 2?
Ну тогда согласен, просто с этим не сталкивался и не заметил, что там нужно умножать на степень основания. В таком случае считать хэши по двум взаимно простым модулям порядка 10^9 по отдельности видится мне самым надёжным выходом.
Да никаких проблем. Но код увеличивается. Лично я, в большинстве случаев, выберу способ решить задачу с помощью суфавтомата, пожалуй, чем с такими хэшами с элементами длинки. Но дело вкуса, пожалуй =)
Тут элементов длинки не больше, чем в задачах с условием "Выведите ответ по модулю 10^9+7."
Так же мало кода, как и в:
?
How to solve A.Or what is test 8 for problem A.
I failed this pretest in my first submission, i guess it's something like:
And answer is:
number shouldn't have leading 0 so check if 1st character is 9 or not if it is nine do nothing if not change to 9-s[0] or not accordingly if it is greater than 4 or not . rest all was just checking if character if greater than 4 change to 9 -character less let it be
So what is anser for 9999.is it 9 or 9000 or what
9000
I don't know... but by 'with no leading zeros' I understood that you can't write 0003 (for example). I think that the statement should say something like 'with the same nuber of digits'.
What do you think?
The problem should have mentioned "with the same number of digits"! :(
Yes , actually this is very poor statement in the question.I am very disappointed like this type of problem statement [user:Zlobober][user:antoniuk].I am also wonder how some top guys think about this in the only first chance.
Some number where first digit is 9, i guess. Like 9631 with answer 9331.
What was the hack test on C?
Overflowing the length in a char array? (up to 6*10^5)
Just time outs?
WA with the same string as in dict?
I submitted a brute force that passed the large pretest (took some work) just to hack on C XD, thinking it was overflowing the char array, but everyone used cin >> string so nothing for me
Somehow no one hacked my solution (maybe not enough time)
EDIT: WHAT, my brute-force C passed systests...
ML/TL for generating all possible strings and putting them into map.
WA for using hashes modulo 2^64.
Not necessary 2^64. I have hacked a few solutions that use one hash modulo 10^9 + something. It is also possible to find a collision for two hashes, too(but this generator is slightly harder to implement).
I don't think people are so brash, but maybe this is the case
UPD. Turns out that post had only Russian version. That post is about hash collision generator, code: http://pastebin.com/JfTEUwCe
The one I hacked is looping with strlen(s), which is, of course, linear time.
pretests are a bit weak, i think. I got pretests passed in my first approach where space complexity was O(n^2) [Unnecessary though]
O(Nsqrt(N)) didn't pass. T^T
Is in the problem E answer is polynomial of degree ~100?
I think matrix exponentiation is the answer..
Весь контест пытался понять. Что здесь не так? Просветите, пожалуйста. 9844828
P.S. Если нет доступа, задача C, WA6: http://paste.ubuntu.com/10225587/
Кажется, я понял
Весьма интересно, что теста на неверное понимание условия задачи не было в семплах.
How to solve B ?
Is solution of 514E - Darth Vader and Tree related to matrix multiplication?
yeah I'm pretty sure.
I think that it's similar to this problem: https://www.hackerrank.com/contests/w10/challenges/towers.
Let's say that dp[i] is equal to number of vertices at distance i. d[i]<=100, so you need only values of dp[i-1]...dp[i-100] to calculate dp[i]. And this calculation can be represented by matrix multiplication, where variables are dp[a],dp[a-1],...dp[a-100], and you are multiplying this vector by some matrix to get dp[a+1],dp[a],...,dp[a-99].
In order to solve original question you have to add one more variable, ans[i]=ans[i-1]+dp[i].
How to solve B ?
Count the number of groups of vectors (positioned to x0, y0) so that for each pair of vectors in the group, their dot product is zero, and no vectors in different groups give zero as their dot product.
I did a brute force . take the position of gun let it be a,b . then for i=1..n .maintain a array called as killed[i] denoting if you killed ith enemy or not. start a loop from 1 to n check if killed continue. otherwise break .let this position be m. find coefficient of line passing through a,b and this point then for elements m+1..n check if it comes under the line .if it does mark killed[] =1 ; check if all are killed if it did break and print the count
I construct
a, b, cin equationax+by+c = 0for(x0,y0)with(xi,yi),i = 1..n. And you should makegcd(a,b,c) = 1 and a > 0. After that, you can sortn equation (a,b,c). Remove(a_i,b_i,c_i) == (a_j,b_j,c_j)byuniquein C++. So that you have the result inO(NlogN)Hey i did the same but got WA on 8th test case ..
http://ideone.com/uzEJcW
My code link ..
Try this test:
You can see my code
you get all N points and you insert tan((y-y0)/(x-x0))in an array tan and the answer is the number of different numbers of array tan .
well, let's count the number of the different slope k = (y — y0)/(x — x0). I think so!
I did that but I lost 100 point due epsilon precision. What is the default precision we need to use to compare two doubles?
Consider two doubles a and b equal if fabs(a-b)<=EPS, where EPS is something like 10^(-9).
Then, the number should be 10^(-9). I used 10^(-4) and 10^(-6), getting WA in both. AC after 10^(-9) with the same solution.
Correct answer is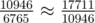 .)
.)
2. With epsilon 10 - 6, the answer seems to be1; the numbers are close enough. (If you're wondering, the differences 6765, 10946, 17711 are consecutive Fibonacci numbers, which is whyGot it! Thanks.
in such cases when you are not sure of what value to assign to eps, you can use
and let the compiler do the rest.
I did the same, and it worked like charm. 9834951
I tried storing numerator and denominator seperately as int after taking gcd, and it worked. You can view the solution here
Find the slope of each point with respect to gun. Store them in set. Print the size of the set.
If denominator while calculating slope is zero, assign it some infinite value. I hope it helps.
Umm did you store the slopes in a double? There could be precision errors then.. not sure though. I prevented myself from doing it this way due to the possibility of this error.
Yeah stored them as long double. I hope there are no precision errors.
Edit: It passed.
I stored each slope in a set of doubles and my solution passed tests. Guess I got lucky.
An alternative would be to write a fraction class as such:
Or perhaps BigDecimal (seeing how this is Java code)
I calculated the slope of the line (y-tY)/(x-tX) and stored it in a map. In the end I just print the size of the map. Can anyone help me with the complexity of this?
I guess in the worst case it would be
as you have to insert N different slopes in worst case, and each insertion would take at most logN time.
I counted the number of differents tans, but I got WA on test 8. Anyway, what is the test 8?
( area == 0 ) this is my solution which WA on test 8 ( area < 0.00001 ) this AC
you choose x1 y1 one point and erase it and ans++ then erase which point on line x,y to x1,y1
if which points on line erase it
I sorted the points by their slope with (x0,y0) and then compared p[i] and p[i-1] using (p[i].y-y0)*(p[i-1].x-x0) == (p[i-1].y-y0)*(p[i].x-x0). If False, increment the number of shots.
I also counted number of unique slopes with a c++ stl set (9839367). It got WA. But surprisingly, replacing scanf with cin got AC !!!
Can somebody explain what's here:
WA: http://paste.ubuntu.com/10226578/
AC: http://paste.ubuntu.com/10226581/
Guys, it`s magic I just move declaration of set at WA code to main scope and got right answer
Code
Full 8 test
WTF?
Seems like that this magic feature forks only under MinGw G++ 4.8 and 4.9 (at Ms works fine) In my Linux machine with g++ 4.9 with same compile keys it works fine.
Can someone make disasembly of this code(dont have win machine with Mingw right now) or explain ?
Yes, seems magical. Did spent quite some time yesterday. Didn't disassemble as could not produce on local. I did played around quite some using the "custom invocation" of the code forces and have noticed the following(not sure how relevant they are).
Whatever be the case, please update if anybody find the reason for anomaly.
I think this may be the answer: https://isocpp.org/wiki/faq/newbie#floating-point-arith2
Yes, something like this might happened. Thank you for a nice link.
Actually Hon solo in problem B was fun.Have you seen "that's my boy movie" :D i don't think you remember Hon solo if you have seen it.
Кажется, некорректное условие в задаче А: В условии не сказано о том, что длина числа должна быть неизменной, поэтому, по логике: 900 должно переходить в 009 = 9 (инвертируем первый, а так же последний, чтоб получился положительное) 999 должно так же переходить в 009 = 9 (инвертируем первые два, а последний не инвертируем чтоб получился положительное) Но, поговорив с другом после контеста, оказывается, что его код прошёл, т.к. он делал для случая, когда длина чисел остаётся неизменным. PS: ы, давно не заходил)
Так ответ не должен начинаться с 0.Поэтому из 900 никак нельзя получить 009.
Там ясно указано, что "Число не должно содержать ведущих нулей."
Эта фраза может относиться к выводу ответа, то есть при получении 009 на самом деле выводить 9.
Ну тк, не должно содержать в конечном итоге. Мы получаем 009, потом удаляем 00, и вуаля, ответ удовлетворяет условию.
Еще хз, прошел или нет, кстати
В условии сказано, что число не должно начинаться с нуля.
// не видел ответы выше
"Запись итогового числа не должна начинаться с нуля.", то есть запись числа после применения некоторого количества операций инверсии цифры не должна начинаться с 0, так что 999 не может перейти в 009. Запутаться можно, но условие корректно.
нет, не корректно. "Запись итогового числа" — это именно число в целом, а не первая цифра. Т.е. читать "привести число к обычному виду". На то, что это относится к формату вывода, а не вычислениям, указывает и повторение этого условия в разделе "Выходные данные" — "Число не должно содержать ведущих нулей." (в ином случае это условие было бы лишним)
Да, я ошибся, не правильно понял фразу "число не должно содержать ведущих нулей", думал что это эквивалентен "выводить ответ без ведущих нулей" ))
please help me problem C
For each query string s with length L, there are 2L possible variants (i.e. replace each character by the other 2, and since you can do this only once, there are 2L such possibilities). You need an efficient data structure to check whether the variants are in one of N strings. I think using trie is sufficient enough.
I use
setin C++ to saven stringinset S. After that, withstring iinm string query, consider positionj,we havestring x = sandset x[j] = {'a','b','c' \ x[j] != s[j]}.You canfind xinset SinO(log(N)). I think it ok becauseThe total length of lines in the input doesn't exceed 6·10^5well, i solve it with map (as set) and i couldn't submit it in 2 seconds :(((((
"You can find x in set S in O(log(N)) " Not true. Comparing two strings needs O(length(x)) if they have a very long common prefix, so it's O(length(x)log(N)). Consider this case: 1 1 aaa...aa aaa...ab (The first consists of 300000 'a' and the second consists of 299999 'a' and one 'b')
you make a robin-karp(hashing) all strings of the dictionary but with a different letter at each step ( if str[i]=='a' you get 'b' and 'c') and you insert this value in a hash at each step... and for queries you make a classic robin-karp at string Q and check if this value is in hash... You should double hashing for safety(two different bases and two different MOD)
I'm not sure if it's correct solution, but you can try to do it with hashing. For each n strings, calculate their hashes without each single letter. Next, do the same with strings from query but this time if any hash of ith string existed before, then answer is "YES" otherwise answer is "NO". There might be some problems, when some strings are equal, but it's not that hard to deal with.
let's define that: a is number of character 'a' b is number of character 'b' c is number of character 'c' we need to find out at least one element in this set: { [a — 1][b + 1][c], [a — 1][b][c + 1], [a][b — 1][c + 1], [a + 1][b — 1][c], [a + 1][b][c — 1], [a][b + 1][c — 1] } and compare them with
string tto satisfied the condition! we should use map(or set) to save the input string with [a][b][c]. I think it could process in 3 seconds :D !I think that is wrong, check this test case: 1 1 caaa aaab
the answer is NO
4 unrated handle spotted the top 5 in current standing! They're unpredictably good o.O
UPD: In final standing the number decreased become two and both of them are the top 2! Fast system testing by the way.
To solve problem C, Is "c++ STL set" just enough?
I think it's not, I have used hashing to solve it. BTW, during the contest I wanted to hack a solution with set, but when I tried to send the test it was loading for a while and then nothing — I had to try again and then happened the same. If it turns out that set isn't enough I will be kinda sad :D
Unfortunately for me,set is not enough. I passed pretests,but in test 20 I got Time Limit.
А что там в D? Я хотел написать бинарный поиск по длине отрезка использующий дерево отрезков чтобы подсчитать макс на отрезке.
Да, я так и делала.
Если написать это неаккуратно, то есть риск поймать TL.
Чтобы улучшить асимптотику, можно вместо бинпоиска по ответу использовать два указатели.
P.S. А дерево отрезков можно заменить на мультисет.
Скорее всего, вместо дерева отрезков нужно использовать Sparse Table.
А можно и за O(NM), если мультисет заменить на очередь с максимумом.
А как мультисетом считать максимум на отрезке?
Если мы используем два указателя или бинпоиск+sliding window, то у нас при переходе от одного запроса к другому удаляется что-то с префикса запроса и добавляются какие-то новые элементы на суффиксе. Если это окно, то удаляется крайний слева и добавляется первый справа, если два указателя — в зависимости от того, какой указатель и на сколько мы двигаем.
Будем хранить все элементы отрезка в мультисете — тогда для ответа на запрос достаточно взять последний элемент мультисета. Это логарифм. Каждый элемент будет добавлен в сет 1 раз за проход и удален тоже 1 раз за проход — это тоже логарифм.
А можно за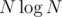 , если делать вместо бинпоиска спуск по дереву, или, еще проще, использовать sparse-table, и идти по убыванию степеней двоек.
, если делать вместо бинпоиска спуск по дереву, или, еще проще, использовать sparse-table, и идти по убыванию степеней двоек.
Я решил за O(n * log n * log n), RMQ + перебор начала отрезка + бин поиск конца.
I've used unordered_map in problem C, but I've got hacked. What could be the problem?
The time complexity of your code is O(n^2) in the worst case. I used a test with two arbitrary strings of length 3*10^5 to hack your solution.
I got TLE in test 28 :( .. my time complexity is O(m * l * log(n)) where, l is length of string in each query. m,n are from problem statement. Can anyone explain how this doesn't run in the time limits? Upd: (m*l)<=6*10^5 (from statement) and log n cannot exceed 18
The time complexity of your solution is not O(m * l * log(n)). Just consider the input that consists of two string: each of them is a letter 'a' repeated 3 * 10^5 times. Your solution makes O(n^2) comparisons for this test.
i am submitting div2 3rd ..but its not showing me the case i m wrong on...!!!!
I am very sad about
problem D.This is my code in contest and this is my code after contest. They different exactly one positionL = 0andL = 1. If I have10sto think that, then I canacceptproblem D andmy standing not low.So sad I didn't get rank 10, just because I missed the word "sequence" QAQ.
Finally, top 10 for me!!! :D
I'm the pathetic No.11 QuQ...
I've used Hashing to solve C. Here's my code 9849480.
It failed on the test #27. It's "..." testcase.
What's wrong with my code?
Collision?
Maybe...
WA on same case :(
My hashing has collision. I add checking function for 2 strings when their hashes are the same and it became accepted!
Problem A , in my opinion has a very ambiguous problem statement what is the answer to:- 90 90 or 9?
My point is, they should have explicitly mentioned whether the number should not have leading zeroes before printing the answer, or during computation.
Read the problem statement. You should not have a zero at starting index after performing inversions. 9 is not allowed as it is actually "09", which has trailing zeroes
I asked author what could be the answer for 9 as it was ambiguous and he said "No comments" -_-'
I get MLE on problem C. I solved it using a Trie. Can anyone have a look on my submission, please?
ML in problem C! :(
I got MLE on problem C at #19. I solved the problem using a Trie. Can anyone have a look on my submission, please?
I am stuck at MLE, too. this solution seems to use Trie but does not cause MLE... I don't know why, though...
The solution is embarrassingly similar to mine. Yet i get MLE. WOW! :-)
That is really strange my submissions in practise is also giving MLE on test #19.
In your query function, you are passing the whole string and doing recursion. So each time you call query, the whole string will be copied and this increases the memory as well as the time. So I think if you just pass the string by reference
string& sinstead ofstring sit might resolve the MLE problem.Can someone explain the algorithm behind this code: http://mirror.codeforces.com/contest/514/submission/9850107
It's a technique which can be used to find max(a[i..j]) when we have queries of increasing i and js. However the code given by you is not that efficient. Take a look at this submission: We can use a C++ 'deque<int>' to answer all the queries in a total of O(n) time.
It's lengthy to explain why the algorithm works (after all it's not too complicated), but the whole operation is expressed as follow:
Everytime we increase j (a.k.a push a[j] into processing) we remove
deque.back()while it's smaller than a[j], thendeque.push_back(a[j]).Everytime we increase i (a.k.a pop a[i] from processing) we remove
deque.front()from the deque ifdeque.front()is a[i].The answer for each i..j query is always
deque.front().In order to limit the sum, each time we increase j (process the next element), we increase i until {sum} ≤ k
Thanks much for the algo, it's really simple. In step of increasing j you forgot to push_back(a[j]).
In my opinion Problem A description was not clear.For input 90 output should be 9 according to problem statement but test data says answer is 90."Length of output number must be equal to length of input number" this single line of statement should have been added.
Nope. "The decimal representation of the final number shouldn't start with a zero."
You could've assumed that you just had to remove the leading zero.. It's not clear...
You can't assume things in a programming contest.
Any deterministic solution for C?
I solve it using trie, created a trie for each different length of strings and brute-forced to check if there was a string in the respective trie in each query.
http://mirror.codeforces.com/contest/514/submission/9843858
For problem C,why people get TLE in test #19?
Suppose,this solution
O(3 ^ len)
which solution will pass? How to optimize it?
You can use Trie data structure ....
My code for problem C : http://mirror.codeforces.com/contest/514/submission/9843731
Hope , this will clear your concept about Tire .
Why is rating update taking so long?
Even systest is freezed in the end for some reason...
Updated:)
in Problem C O(m*l*ln(n)) with hashes and default c++ set gets TL on #20.
*solution 9841888
То чувство, когда перемудрил. 514A - Чубакка и число . Мой код — 9838729
Перемудрил, говоришь? 9832281
Объявляется челлендж — кто больше намудрит в A.
I can't find my mistake about C problem, I used hash with unsigned long long
this is my soution: 9844038
Is there any problem if I substract from unsigned long long?
This is another similar solution, he used two hash, but I'm sure colisions is not my mistake ...somebody?
9836207
http://mirror.codeforces.com/blog/entry/16365#comment-212594
Sorry. Got the mistake.
I am sad I took TLE in C using set-stl,but I am happy because I achieved my first goal that was blue. Now it is div1. I hope to achieve that soon :D. I say that,because I want gray-green users that with "correct" practise everyone is able to achieve everything,and never give up.
А заморозка сегодня закончится или нет? Даже рейтинг уже обновлен, а заморозка до сих пор.
Guys is there anyone who could help me understand why my submission gives wrong answer in test case #6? By my calculation the output kills 3 droids even though checker comment states my solution kills only 2 of them. Any help is greatly appreciated.
"How many shots from the weapon of what type should R2-D2 make to destroy the sequence of consecutive droids of maximum length?"
You have been destroyed 1, 3 and 4th droid, so your sequence has length 2. In the correct answer, 2, 3 and 4th droid is destroyed, so the sequence has — better — length 3.
Word 'consecutive' is the key.
P. S. Sorry for my english :)
Why do I get MLE for problem D? http://mirror.codeforces.com/contest/514/submission/9850749
I have used segment tree so 4*N*5 memory, plus one more array of N*5 (both int). As N is just 100000, this should not exceed 256MB memory limit.
I also did segment tree and passed. Maybe you can take a look. 9865631
Yeah, I got it later. I am creating 2 new arrays p,q in every call to query. This must be adding up to the memory as the arrays must get stored in the recursion stack. (Not sure, but I think this may have been the cause). When I removed that part, and instead passed an array to the query function, I got my solution to pass. http://mirror.codeforces.com/contest/514/submission/9858833.
Anyways, thanks for your reply! :)
My 2 cents, since everyone writing about problem C seems to have tried hashing:
The similarity condition imposed is Hamming distance = 1. This is a metric space and can be solved with any of the metric tree structures. I used a BK-tree, and I got AC.
Your solution is interesting. Can you explain your solution ??
How he managed to get the solutions before starting of the contest ??
See that '00:28' near his handle? It means he's a virtual contestant (submitted the solutions after the contest finished).
That's virtual contest. I think he first took 5 submissins which passed all tests, started virtual contest and submitted them on the first minute.
When editorial is going to come? It will be interesting to see author's solutions to these problems :)
I'm working on it.
Done.
Still waiting for jury to start upsolving... :/
How could always the new comers be in the top list in division 2 ?!!!
They are usually Div 1 coders that make new accounts.
Is O(M*N*log^2(N)) using segment tree supposed to TLE for problem D ?
No.
Rebryk, I think data set of problem C ( 514C - Watto and Mechanism ) of today's contest was a little bit weak. Consider this submission: 9852063 which fails the test case:
Should not the output be
NO? It givesYESinstead.Thanks. :)
Yes. You're right. It's my fault.
became expert for the first time
i am getting memory limit exceeded on test 18 in C... i have used map<string,int> to do it.. can anyone suggest the reason for this? and also what would be a more memory efficient way of doing this question...
When you use
if (f[s])with a new strings, it makesf[s] = 0and therefore uses|s|additional bytes of memory.Try to use
set <string> fandif (f.find(s) != f.end())instead ofmap <string, bool> fandif (f[s]).thanks a ton :D that was a new thing for me :D
Can somebody please check why I got a run time error on test_25 http://mirror.codeforces.com/contest/514/submission/9848840
I have tried the test case on my computer and it worked.
this contest really interesting though i didn't solve any problem. actually i wonder why i can't solve at least problem A, and then i know that because some case (case 8) like this:
input :91730629
my output : 1230320
answer : 91230320
in my opinion, i think my answer actually didn't wrong because we could make the minimum positive number by inverting 1st, 3rd, 6th, and 8th character from the input and discard the leading zero. is somebody has the same opinion with me?
the length of the output should be the same as inputs ! :)
really? then i should miss that in the description :)
btw, which statement says that?
It is exactly because the statement never said that you can discard any digit. Which means you can only invert digits but then the result cannot contain leading zero(s).
You should not make your own assumptions.
Problem description says: "transform the initial number x to the minimum possible positive number by inverting some (possibly, zero) digits". so you can't discard leading zeros,only operation you are allowed to do is invert some (or zero) digits.
I used TRIE in Problem C but perhaps it should be String Hash? Anyway I FST beautifully.
I used TRIE in Problem C but perhaps it should be String Hash? Anyway I FST beautifully.
Where is editorial???
Sorry, I'm a slowpoke
Done.
Good job)
I got AC on 514B - Han Solo and Lazer Gun,but I alos have a question. gun is situated at the point (x0, y0). can stormtrooper at (x0,y0),too ? if so, i think some code maybe got WA。
I am trying to solve C problem. I see a lot of solutions where there is something like this :
for (int i = 0; i < n; i++) { ... for (int j = 0; j < s.length; j++) {
where n <= 3*10^5 and s.length <= 6*10^5 , so in worst case it works in 9*10^10 ~ 10^11 . Why it pass ? How can I calculate the worst complexity withing given time limit ?
if n = 3 * 10^5 s.length can't be 6*10^5, because 6*10^5 in the worst is a sum of all s.length
Yes, thank you. I misunderstood problem statement. Anyway, is there any good algorithm to determine the worst complexity withing given time limit ?
What does it mean: withing given time limit?
Time limit in this problem is 3sec.
I want to know algorithm with 2 inputs complexity, time limit . The output will be answer YES/NO For example:
C = 10^6 T = 1 s => YES
C = 10^19 T = 1 s => NO etc
1 second on Codeforces is ~ 2 * 10^8
Total length of all strings in input is 6*10^5, thus, the code you described does 6*10^5 iterations.
Your solution couldn't even read input if these two loops would TL
The problem A has too many traps, and some of them is so boring, such as the fist digit can't be zero. I think it is meaningless......
What is/are the other trap(s)?
Why does this give TLE for problem C? => http://mirror.codeforces.com/contest/514/submission/9853243
In problem C, I did not understand why the hash value of a string will not overflow long long. And if I mod using a 4 digit prime then there should be collisions.
Given the clue, "The total length of lines in the input doesn't exceed 6*10^5. Each line consists only of letters 'a', 'b', 'c'.", there can be a string of length 10^5 whose hash value can be huge.
I used mod 10^16+3 and base 203. Collisions are still possible but have a very low probability. However, there are solutions that do not use hashes, for example: http://mirror.codeforces.com/blog/entry/16394
Thanks for the link :)
Hi, somebody else used hash for the problem C?
I have WA #6 but I don't know why. Any help would be appreciated! :)
http://mirror.codeforces.com/contest/514/submission/9860261
The string must differ by one char, i.e. here's the test: 1 1 aa aa
NO
Oh, right... I didn't see that constraint. Thanks a lot!
You helped me 5 years in the future 5 years ago. xD
For hashing, if I use 101 then I get WA for test case 8 but if I use 257 then it is accepted. Why so?
I chose 101 because the ascii value of c 99, hence I thought 101 was enough.
If you see a passed solution you think is wrong, is there a way to hack it in the practice room?
NO
that's too bad, it would be nice to be able to double-check that your hack was correct, and also keep other people for thinking a wrong solution was actually correct.
Codeforces Round #291 (Div. 2) champion ppfdd got AC on problem C.
But there is massive hack for his code.
While hashing, He converted a,b,c to 0,1,2.
So the result for this input:
the output generates
which definitely WRONG ANSWER.
There should have been at least one test case regarding this factor. :3