



522A - Репосты
Для решения этой задачи надо было проитерироваться по записям о репостах и поддерживать для каждого пользователя длину цепочки, которая заканчивается в нем. Здесь удобно воспользоваться ассоциативным массивом из строки (имени пользователя) в целое число (длину цепочки). Например, для С++ такой структурой данных будет просто map<string,int>. Назовем такую структуру chainLengths, тогда при обработки строки вида <<a reposted b>> надо просто выполнить присвоение chainLengths[a] = chainLengths[b] + 1. В качестве ответа надо вывести максимальное из значений chainLengths, что можно подсчитывать на лету.
Пара тонкостей: в начале надо занести chainLengths["polycarp"] = 1;, а всюду при работе со строками приводить их к нижнему регистру (или верхнему), чтобы сделать сравнение строк нечувствительным к регистру букв.
Пример такого решения: 10209456.
522B - Фото на память
В этой задаче для каждого i фактически надо было найти:
- Wi, равное сумме всех заданных wj без wi,
- и Hi, равное максимуму всех hj без hi.
Для подсчета первой величины достаточно найти сумму s всех значений wj, тогда Wi = s - wi.
Для подсчета второй величины достаточно заметить, что либо искомое значение есть просто максимум по h, либо (если hi совпало с максимумом) это второй максимум (т.е. предпоследний элемент при сортировке по неубыванию). Второй максимум, как и максимум ищется за один проход по массиву.
В таком случае, для нахождения как Wi, так и Hi требуется O(1) действий, то есть O(n) суммарно на всё решение.
Пример решения: 10193758.
522C - Chicken or Fish?
Для решения задачи необходимо заметить, что при наличии недовольных пассажиров (т.е. тех, для кого ri = 1), существенную роль играет только первый из них, так как остальные вполне могут быть недовольными именно тем блюдом, которое не хватило первому из таковых.
Пусть массив b — это массив максимальных возможных количеств порций каждого из блюда на момент старта обслуживания Поликарпа. То есть просто массив b надо заинициализировать массивом a, а каждый раз, когда ti отлично от 0, то делать b[ti] = b[ti] - 1 (уменьшать количество порций блюда). Кроме того, пусть unknown — это количество пассажиров, про которых неизвестно какие точно блюда им достались (то есть для них ti = 0). Пусть величина unknownBeforeUpset — это такое же количество, но до первого недовольного.
Таким образом, есть два основных случая:
- недовольных пассажиров нет вообще, тогда блюдо i могло закончится тогда и только тогда, когда b[i] ≤ unknown (жадно отдаем это блюдо всем пассажирам, для кого их точное блюдо неизвестно),
- недовольный пассажир есть, этот случай разберем подробнее.
Каким блюдом мог быть недоволен первый из таких пассажиров? Очевидно из списка кандидатов надо выкинуть все такие блюда, которые упоминаются не раньше него (значит, что они закончится до него не могли). Из оставшегося набора блюд достаточно перебрать все блюда и проверить могли ли они закончиться до этого пассажира. То есть блюдо i могло быть тем блюдом, что привело в недовольство первого недовольного, если одновременно верно:
- это блюдо i не упоминается на этом пассажире или позже,
- это блюдо i такое, что b[i] ≤ unknownBeforeUpset.
Для всех таких блюд, очевидно, в ответе должно стоять Y (они могли закончится к Поликарпу). Кроме того, из всех таких блюд наибольшую степень свободы дает блюдо с наименьшим расходом (количеством порций b[i]). Выберем именно такое блюдо и в остаток пассажиров с неизвестным блюдом restUnknown = unknown - b[minFirstFinished] попробуем поместить все вхождения каждого из других блюд. То есть блюдо j могло закончится до Поликарпа тогда и только тогда, если для него b[j] ≤ restUnknown (то есть закончилось то блюдо, что расстроило первого из недовольных, а следом — j-е).
Такое решение работает за O(m + k).
Пример решения: 10212686.
522D - Ближайшие равные
Воспользуемся тем, что задача задана в офлайн-формулировке, то есть все запросы можно считать до нахождения ответов на них.
Пройдем слева направо по массиву и составим новый массив b, записав в b[j] расстояние до ближайшего слева парного j-му элементу значения, то есть a[j - b[j]] = a[j]. Если такового нет, то запишем в ячейку бесконечность.
Эти значения соответствуют расстояниям между парными элементами и записаны они в позициях правых элементов в этих парах.
При рассмотрении запроса на отрезке [l, r] нам не нужны вообще такие пары, что начинаются левее l, а минимум надо искать среди пар, что заканчиваются не правее r.
Отсортируем все запросы по l слева направо. Тогда при прохождении по запросам можно поддерживать, что для запроса [l, r] в массиве b установлены бесконечности для всех пар, в которых левый элемент левее l. Для этого просто предподсчитаем для каждого элемента ближайший справа парный next[i] (то есть верно, что b[next[i]] = next[i] - i), и при покидании ячейки i будем записывать в b[next[i]] значение бесконечность.
В таком случае, для ответа на запрос [l, r] надо просто найти минимум на префиксе до индекса r включительно по массиву b. Это можно делать быстро разными способами (дерево отрезков, дерево Фенвика).
Асимптотическая временная сложность такого решения составляет 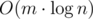 .
.
Пример решения: 10192075.







D можно было и онлайн сделать, для небольшого усложнения и восстановления баланса относительно С. Решение получается не на много сложнее.
Преобразуем исходный массив в список всех таких пар, где пара содержит индексы равных друг к другу элементов, между которыми нет такого же по значению элемента. Например 1,2,1,3,3,1,2 преобразуется в (0,2),(2,5),(3,4),(1,6)
Отсортируем эти пары по левому концу. Выкинем все такие пары, внутри которых есть хотя бы одна. Это сделать несложно за линию — если предыдущая в отсортированном списке имеет второй элемент, превосходящий второй элемент текущей пары, то эту предыдущую пару можно убрать.
После этого в списке останутся пары отсортированные одновременно по левому и по правому краю. Рассмотрим запрос. Пусть i-ая пара — самая левая, которая попадает в интервал запроса, а j-ая — самая правая. Очевидно что все пары между ними также попадают в запрос. Эти граничные пары можно найти бинпоиском, проверяя, для простоты, только левый и только правый элемент пары соответственно. Если построить дерево отрезков по длинам пар, то беря минимум из дерева от i до j получаем ответ на запрос.
Итого O(m log n) за онлайн решение.
Пример: 10213124
Авторское решение легко модифицируется в онлайновое (с той же асимптотикой) персистентным деревом отрезков. Единственный минус такого решения — O(n log n) занимаемой памяти.
у нас онлайн за m * log(n) с бинпоиском по ответу и минимумом на отрезке(с помощью разреженных таблиц).
А как сделать бин поиск?
Заведем массив b[j], как в авторском, и массив c[j], который, аналогично первому, содержит расстояние до ближайшего правого. Построим две разреженные таблицы по этим массивам.
Научимся определять, что ответ на [l;r] не меньше x. Сначала используем b[j] для этого. Нас интересуют только такие j на [l;r], что j - b[j] ≥ l. Поэтому достаточно взять минимум по b[j] на отрезке [l + x;r], так как нас интересуют b[j] ≤ x лишь внутри этого отрезка.
Однако, мы могли не учесть некоторые b[j] ≤ x для j из отрезка [l;l + x - 1]. Рассмотрев c[j] аналогично b[j], но уже для [l;r - x], мы учтем и их. Наша функция возвратит true, если хотя бы один из двух полученных минимумов меньше или равен x, и false в противном случае.
Понял. Спасибо!
Мы делали так: находим минимум на отрезке [l,r-x] по массиву b, о котором в разборе все описано, и если он больше за x — значит нужно увеличить x. Более подробно в нашем решении, которое ТЛилось из-за того, что про разреженные таблицы вспомнить мозгов не хватило...
В задаче B можно было не использовать вектор высот людей, а хранить индекс самого высокого, самый высокий рост и второй по величине рост. Тогда при итерациях по циклу сравнивать индексы и в зависимости от этого — выбирать значение высоты
У нас зашла sqrt-декомпозиция со сложностью на запрос и
на запрос и 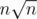 препроцессинга. В общем-то, по сравнению с авторским преимущество решения только в том, что оно отвечает за запросы в онлайне.
препроцессинга. В общем-то, по сравнению с авторским преимущество решения только в том, что оно отвечает за запросы в онлайне.
Пройдем слева направо по массиву и составим новый массив b, записав в b[j] расстояние до ближайшего слева парного j-му элементу значения, то есть a[j - b[j]] = a[j]. Если такового нет, то запишем в ячейку бесконечность. А как это быстро сделать?
Проще всего — идти по массиву слева направо и параллельно хранить в map'е для каждого числа позицию его последнего вхождения. Тогда при рассмотрении очередного числа мы можем быстро узнать, было ли такое число раньше, и если было — где именно оно было в последний раз.
Альтернативный метод — записать все числа в вектор пар число-позиция и отсортировать его. Тогда для каждого вхождения каждого числа соседние вхождения этого числа в оригинальном массиве будут его соседями в этом векторе.
Выходит n log(n) не посчитали в сложность?
You can also use an unordered_map whitch is based on hash function and has O (1 ) complexity for updates and queries so the complexity will be O ( n ) for this step.
English translated version of D (in case anyone wants to refer to it but refrains due to language :) )
We will use the fact that the task is set in an offline wording, that is, all requests can be counted until answers to them are found.
We will go through the array from left to right and compose a new array b, writing in b [j] the distance to the nearest left jth element of the value, that is, a [j — b [j]] = a [j]. If there is none, then we write infinity into the cell.
These values correspond to the distances between paired elements and they are recorded in the positions of the right elements in these pairs. When considering a request on the segment [l, r], we don’t need at all such pairs that begin to the left of l, and we must look for the minimum among the pairs that end not to the right of r.
Sort all queries by l from left to right. Then, when passing through queries, it can be maintained that for query [l, r] in array b infinities are set for all pairs in which the left element is to the left of l. To do this, we simply calculate for each element the next pairwise next [i] on the right (that is, it is true that b [next [i]] = next [i] — i), and when leaving cell i we will write in b [next [i]] meaning infinity.
In this case, to answer the query [l, r], you just need to find the minimum on the prefix to the index r inclusively in the array b. This can be done quickly in different ways (tree of segments, Fenwick tree). The asymptotic time complexity of such a solution is.