


Добрый день!
VK Cup 2015 — Раунд 1 (неофиц. интернет-трансляция, только Div. 1) — это неофициальный повтор Раунда 1, открытый для всех участников из первого дивизиона. Это означает, что если вы не принимали участие в VK Cup 2015 (например, вы старше 23 лет), решили прекратить участие в нем или не прошли квалификацию, то вы можете зарегистрироваться на VK Cup 2015 — Раунд 1 (неофиц. интернет-трансляция, только Div. 1) и принять в нем участие.
В интернет-трансляция — соревнование с индивидуальным (не командным) участием, по результатам трансляции будет пересчитан рейтинг всем ее участникам. Задачи будут предложены как на русском, там и английском языках.
На соревновании будет использована плавная динамическая система (с шагом 250). Подробнее о ней можно прочесть здесь.
Не забудьте зарегистрироваться заранее на раунд. Желаем удачи!







При попытке зарегистрироваться, я получаю alert "Unsupported participation type"
Временный эффект был, попробуйте еще раз.
as i can see there is a time difference from the original round and the mirror round. Does the problem set could have seen before the round starts?
No, it will not be published for non-VK Cup participants, and VK Cup participants will not be able to take part in online mirror.
I am not going to be participating in the mirror, but I would like to ask a question on behalf of those who will be. How you will prevent cheaters who will compete in the VK round and then compete with another account in the mirror round? I am quite sure that there are highly rated people with additional d1 rated account, as we see in d2 competitions often times new accounts show up, place in the top 10, and then never do anything again. Of course one could say that this is against the terms of service, and is cheating obviously, but as we can see from d2 results this often does not stop people. In addition this time the reward for these cheaters is much greater. If they are already willing to cheat to try and win a d2 contest, would they not want to cheat even more when they have the opportunity to win a d1 round by spending 4.5 hours solving the problems. This is why if I were a red competitor I would be very scared about participating in this mirror, because what happens when you end up competing with a cheater who is actually red in real life, and has 2.5 hours to spend on the problems before you start? The answer it seems is that the honest red's rating will go way down. Anyway I hope I am wrong about this, and that the ethics of the Codeforces community will prevail, however I sadly will not be surprised to find tomorrow at the end of the mirror round several purples with only 1 previous round competed in at the top of the leaderboard, and this will be very sad for all the rest of us.
This round is something like an experiment. Actually, I do not see much motivation to cheat here: it is hard, but it is possible to understand persons who register new accounts to be in top of D2-rounds. It could be fun for someone, but in case of this round I don't see any fun. It is not funny, but boring to solve problems if you saw them before.
We had an option here: to host only VK Round 1 or to add an event for everyone. I think that it is better to trust participants and to organize contests than to suspect everybody and not to do contests. You see, programming contests mostly have many ways to cheat but I don't think that is the reason not to do contests.
So good luck.
Why is it for div1 only? Only because estimated difficulty of problemset is too high for div2 users, or there are some other reasons behind this?
Probably for that reason. It's also quite interesting: round 1 already is too hard for div1?
Maybe there just aren't easy problems.
I have no stats about distribution of qualified contestants by color, but right now among 375 registered teams (in official Round 1) only 214 have team rating >=1700, and for individual ratings stats are even worse. So these guys will have a hard time in case of hard problemset.
I guess one reason would be to discourage cheating? If you can create a new account and immediately join, then cheating is much more appealing than using your main Div1 account. And in this particular case cheating is relatively easy as the official round is before the unofficial one, and the tasks could easily be leaked.
Atleast, out of competition for Div 2?
Рейтинг будет пересчитываться отдельно для основного тура и отдельно для зеркала, так как будто это два разных соревнования?
По отдельности.
Unofficial But Rated : WOW.
Unofficial But Rated : WOW.
official for CF but unofficial for VK ,very simple
Where is official VK Cup 2015 Round 1 ? it's not in contests anymore, there is only mirror of it
Go to the russian part of the site. It's there.
Oh, my bad, sorry, thank you
i love contest i want register i hate you div1 only MikeMirzayanov is it problem if div2 coders register and contest will be unrated for them?
You ask us to not participate in the official VK Cup, however you make the unofficial Round Div 1 only.
Can we do gym contest while the VK cup round goes on !! I m in div2 , so want to practise there .
You will be able to take part in it virtually after contest ends.
Sorry , I meant while the VK cup goes on , can i participate in some other gym contest . Because vk cup is not allowed for me .
Oh, I do not have plans to restrict gym features.
We do not have a heart? We want VK Cup
We do not have a heart? We want VK Cup
Are the problems sorted in order of difficulty?
This contest is only for Div 1 and it is rated . I think many coder's are unfortunately goes Div 2 Because it is rated. lol.....
The site is not letting me register.. At first it said "My submission for C has been hacked" even though the contest hasn't started.
Now its giving me a popup telling me that i'm registered, but nothing happens and I'm not on the registration list
Popup has been sent by error in website because of teams participation.
Are you sure that you didn't confuse between offcial R1 and internet-mirror?
This contest is Hello 1394(Iran). Happy new year and wish good rate
Delayed 15 mins :_(
actually its 10 mins :)
Now it's 15 mins :D
15 mins now!!
One more postpone with 5 minutes and I win 100 dollars to my friend.
Do you lose it otherwise? :D
How much of it would you donate to codeforces? We could make a deal...
As I have already lost, I let you have 100% of it. So, my friend wants to know when he will get his money?
I got bored, so let me spend those few minutes before the contest by writing a joke:
If you have a homework that need at least two hours of working , how can you do it in only five minutes??
just do the homework in last 5 minutes before the starting time of a contest on codeforces because it feels like 2 hours.
Well, no cheaters because of delay?
Actually, E was the easiest problem.
I found B easier. And expect a lot of sysfails on E because there were hacks on that problem on main event
Mhm, maybe. B, D and E seemed about the same difficulty to me, but it had the most submissions very quickly.
Yes, I understand. But to code it in 3 minutes when at official round it took at least 10 minutes for the first team? And one more important point: a lot of coders start to read from A at CF rounds. So, to read & understand at least two problems and then implement it so quickly? I'm not sure...
Where is rooms?
rated?
Yes rated ):
Мы участвовали в официальном раунде. На трансляцию не регистрировались. Вот как выглядит список задач, если войти в трансляцию: При этом, это не соответсвует множеству тех задач, что мы заслали в официальном раунде. Нажатие на замок ни к чему не приводит.
При этом, это не соответсвует множеству тех задач, что мы заслали в официальном раунде. Нажатие на замок ни к чему не приводит.
Задачи B,C — не такие же.
A, E — вы сдавали?
Нет, спасибо. Это отвечает на вопрос "почему присутствуют зелёные", но остаётся два вопроса "почему отсутствуют красные" (посылки по A & E были) и "почему там замок"?
First time to see a contest in which E is the easiest problem :D
E — Easy
B — Basically easy
D — Doesn't seem like greedy, but it is!
C — Can't be bothered to make a funny name for the letter... oh wait
A — Aw shit!
Can you tell your solution of problem C?
I didn't read it, I spent the last 40 minutes solving A (I don't know where I fail, since my approach uses quite general approaches).
For each query, you want to know if there is a rook at every row/column of the special area.
At least for my solution, you need to check the conditions separately for rows and columns. For the rows: sort the queries by increasing order of x1, then for all rows keep the leftmost rook such that xR ≥ x1. The query is valid if xR ≤ x2 for all rows (use a segment tree to check that).
Do the same for the columns, and take the queries that passed any of the tests.
This seems pretty annoying to code though, I wonder if anyone has something easier.
This should be simpler:
i got the same idea after this contest, but how to built a segment tree to get how many elements are greater than some value(i sweep from left to right).
I know how to solve with SQRT descomposition, but querys with that is too expensive O(sqrtN * log(sqrtN)), updates in O(sqrtN), with segment tree, i don't have the faintest idea how to do that.
Any hint with segment trees please?
You don't need to know "how many", all you need to know is whether there is at least one or not. Similar example: on the given interval you need to check if there is any number greater than X. That can be solved by taking maximal value on the interval and comparing it with X.
haha, i understand, just in my case maximal value is enough, but about how many element greater than some value, is possible to do that with segment tree?
One of the ways to solve this problem: for every vertex of a tree store sorted list of all entries of rooks at it's segment, and also for every rook remember it's position in this list for every vertex it belongs to. And also build a fenwick tree in every vertex.
Now do basically the same as in simple solution — move column by column, when you meet new rook — remove previous rook at this row (if exist) and add this one. But in simple solution you were only updating a value of minimum in some vertices of a tree, and here you have to update Fenwick trees for all affected vertices. You should update those trees in such way that there are always 1's for entries which are last at their horizontal line right now and 0's for everything else.
Now to answer query "how many?" for vertex you need to count sum at some suffix of Fenwick tree for this vertex.
The rectangle is defended by rooks if and only if it either has rooks on every row or it has rooks on every column (both taking only rectangle's range into account). Since those two are symmetrical I will describe only how to check whether there is a rook on every row. We will answer the queries in offline, sort queries by their left border and go left to right. Sort the rooks left to right as well. Now going left to right you need to remove the rooks from the board which are to the left of the query currently being checked. If you remove such rooks then for each row you can check what is the leftmost rook in that row. If you take max of these values across all rows in the rectangle (using interval tree for example) and compare the result with rectangle's right edge you will find whether it has any rooks missing or not.
You can also use interval trees for a different solution. Again, this is to check just if every column has a rook.
Keep for each column the intervals where you dont have rooks (if you have rooks at y's 1 2 5 on a column you have the intervals 3-4 and 6-M). You build a segment tree over these intervals and in a subset of columns (x .. (x + y) / 2, (x + y) / 2 + 1 .. y) you keep all the intervals from the 2 subsets (left and right) that are not contained in another interval. Now just query if the column subset (x..y) contains in interval that contains y1, y2 (from the query in the statement). If this stands true, that means there exists a column not covered by a rook.
A -- why? Just use hashes to compare cyclic shifts in .
.
and why does it work?
Лёх, в смысле, почему? Задача: выбрать мининмальный цикл сдвиг из каких-то. Решение: перебираем все, какие надо, из них за O(nlogn) хешами берём минимум. А какие надо, определяется по min баланса на отрезке и разнице балансов концов.
Вопрос о том, почему хеши не отгребут?
И, судя по обсуждению в ВК и твоей посылке, ответ — ни почему, отгребут
Хотя можно использовать двойные, да (об этом сразу я не подумал)
Ну блин =))) Я же на дорешке сразу перепослал с простым модулем и ОК получил. Всё норм.
Да, про то, что хеши можно написать нормально, я иногда забываю:), не люблю я их:)
А ты тогда не пиши, ты копипасть! =) StrComparator
Да, надо бы позаполнять библиотечку, только руки не доходят.
Только я теперь не копипащу, а генерю:)
(Russian version in edit history)
This might be a silly thing to ask, but… how can you be sure that, when hashing a whole million of bits (and that’s only because we’re limited to parentheses here; we could easily have had letters) to just 64 bits, there won’t be any collisions that break the solution in one way or another?
Let hash-function is seem random. Then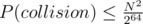 . Where N — number of substrings to hash. If N ≤ 108, it's small enough (10 - 3).
. Where N — number of substrings to hash. If N ≤ 108, it's small enough (10 - 3).
So basically, you just hope for the best?
Well, that’s one way to do it. I just thought it was customary to always expect the worst case in competitive programming.
Yes, I always hope. Always, when I use randomized algorithms. Like polynomial-hashing, like Miller-Rabin, like Schwartz–Zippel
Not to belittle your main point, but Miller–Rabin is deterministic for finite input given the right (constant) set of bases. 2, 7 and 61 cover all 32-bit integers, while 2, 325, 9375, 28178, 450775, 9780504 and 1795265022 cover all 64-bit integers, or so the Internet told me back when I copied these lists.
You may modify Miller-Rabin to be more determenistic, but basically Miller-Rabin says "let consider any random number!". And it gets error with probability <= 1/4.
The thing is, using the (finite and constant) sets I posted instead of random numbers gives a probability of error of exactly 0, making the test completely and utterly deterministic and reliable.
There’s also a version that gives the same result for arbitrary input ranges with the assumption that the generalized Riemann hypothesis is true, but it’s asymptotically slower: it’s basically “try all potential witnesses up to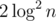 ; the number is a guaranteed prime iff all of them fail”.
; the number is a guaranteed prime iff all of them fail”.
Of course, if you want an arbitrary input range and can’t accept the factor, the classical Miller–Rabin is probabilistic as you said.
factor, the classical Miller–Rabin is probabilistic as you said.
Note that, when the probability of failure in your algorithm is less than, say, 10 - 15, it is less than the probability of a hardware failure. So, when solving a problem, it's customary to discard that probability, as it's customary to discard the probability of hardware failure when running your implementation.
Wow, I totally misread the fact that you have to use 2 different bills only in problem E, and only realized that 10 minutes before the end. Needless to say, time penalty when submitting at 01:57 is rough :D
Yes, I missed that as well, because that completely crucial info was hidden in one inconspicious sentence xd
What is the Hacking Case Of Problem E? TLE Case Or Any Critical Input Pls Suggest Me
I think that was TLE case!!
We made one array overflow hack
n*n*k*q fails because 5000*5000*20*20 is roughly 10^10. I was surprised to see the number of div1 coders who submitted using this approach.
Can you explain the solution?
Here is my solution:
Hope it helps!
Hm, my solution of A: STL magic to get all rotations where the answer is minimum (btw trivial minimum), then suffix array to sort rotations. It fails on pretest 11...
UPD: found it, I computed the costs of rotations incorrectly.
According to the results, your solution on pretest 11 is actually lexicographically smaller than the judge output, so you must have produced an invalid solution somehow. My solution is the same algorithm but it passes pretest 11 if that matters.
Check the balance of first 113 chars
You can find the costs in O(N), and then the minimum lexicographic rotation for a minimum cost set in O(N) also, it is way more elegant than suffix arrays.
Can you please explain in more detail how to do second part in O(N)?
O(N) suffix array? :D
You mean elegant O(N) suffix array? :D
Sure, there is an algorithm which finds the smallest rotation of a string in O(N). Explaining it would take long, so I will leave code here in C++ : The string S has length n and it is 0-indexed .
mi=0; p=1; l=0; while(p<n&&(mi+l+1<n)) { if(S[mi+l]==S[(p+l)%n]) l++; else if(S[mi+l]<S[(p+l)%n]) { p=p+l+1; l=0; } else if(S[mi+l]>S[(p+l)%n]) { mi=max(mi+l+1,p); p=mi+1; l=0; } }After this, the minimum rotation will begin at position mi. As you can see, we asume that the solution begins on position mi, and we compare it with p on the course.In our problem, we set mi as the first position where the rotation is good, and p as the second one; and in the algorithm we advance with p to the next good rotation, because we need the minimum lexicographic rotation only for some of the rotations calculated earlier.
I explained why this works at http://www.quora.com/How-does-the-minimum-expression-algorithm-by-Zhou-Yuan-work/answer/Fernando-Fonseca-2. Using this on this problem didn't come to mind during the contest though, well thought.
Also, nice template :P Hilfe! Das Monstrum im mir wird explodieren!
Thanks for the link! Why is the algorithm called "minimum expression"?
To be completely honest, I had never heard of that algorithm before answering the question, so I just copied the name from the title.
I can theorize on why, though: if you're working on a problem in which all rotations of a string are equivalent (this would happen, for example, if you were considering a circular necklace or people sitting on a circular table), then all rotations of the string would actually be different expressions for the same arrangement. The minimum expression would then be the lexicographically smallest way to describe a certain arrangement, and it can be used to associate each arrangement with a unique representation.
Thanks! But why does the loop in your last, succinct version stop at
i+k==len? Shouldn’t it wrap around to check the whole rotation? Similarly, why does the loop in the code Kira96 posted stop atmi+l+1==n?Actually, if mi+l==n, I should stop because that letter isn't within the range [0,n-1]. Oops, my bad :).
really bad problem statements :(. long, hard to understand and with constraints hidden among the story
what is the point of long statements?
There's a solution running on pretest 4. Because of that, the systest is stuck at 100%.
Problem D used a very simple greedy solution. It was so simple that I couldn't believe its correctness (as there were few people solved it). I spent much time to hack it, but failed. So I decided to code it.
Also those low constrains made me to be not sure about greedy solution
When will the problems be available in the Problemset?
UPD: They're now available.
I lost about 30 minutes for problem E because I didn't read condition "at most two distinct denominations", and finally failed system tests because of runtime error :(
BTW, after we saw the problems , don't you think that the problems are not that hard to prevent div2 from participating ?
And also in this div1 contest easiest problem from VK Cup wasn't used (problems B-F from VK Cup were presented there, but in shuffled order and with minor changes in some of the tasks); so I guess div2 contest can be obtained from div1 round by changing problem A (which was used as F at VK Cup) to problem A from VK Cup and changing problem B to it's simpler version from VK Cup (there was no <=n/2 lying limitation).
My code for problem B failed system test 22. Could someone tell me what's the problem?
How to solve problem E, please somebody who can explain his idea?
"and the bills may be of at most two distinct denominations." now i understand why everybody say too easy, damn it!!
This is so ridiculous. :[
Well, there are other parts that you might miss there. I have missed K <= 20 and have implemented extended Euclidian algorithm to solve it for arbitrary K. It was O(Q * N^2 * log (2*10^8)) and after getting hacked with TLE optimized down to O(Q * N^2), but it still wasn't enough to avoid TLE.
So, side question. Is there anything better than that if K can be also large?
Why are previously accepted solutions for 529C - Rooks and Rectangles getting Runtime error on test 31?
n is 300000 :-" !!
The problem statement still says 1 ≤ n, m ≤ 100 000, 1 ≤ k, q ≤ 200 000. Also why was that case added after the contest? Really annoying. :/
Fixed.
Thanks.
about problem C : in input say n<=100000 ; but in test 31 n=3e5 !!! :(
In problem B: trying every height in the input to be the maximum height gets WA on test 18, while trying all heights from 1 to 1000 gets AC!
WA: 10389037
AC: 10389163
At least one person won't lie on the ground, so why my solution is not getting the correct answer by trying all the given heights?
At least one person does not lie on the ground, true, but it isn't guaranteed that the highest person is someone standing up.
For example,
2
5 10
11 8
Oh, thank you!
Something unusual:
Why do these submissions not get TLE?
10386307, 10388227, 10386918
The problem statement currently clearly says "time limit per test: 2 seconds".
Submissions during the contest seem to have timed out at 3000ms, so maybe the time limit was changed? Also, anta must have a lot of courage to stick with a solution running in 2963ms on pretests!
I remember during the contest it was 3 seconds
wow , i just found out how slow reading with stream's are on problem C:
over 2 sec's (TLE) with streams
450 ms with scanf
You should use cin.sync_with_stdio(false);
mhm thanks for the tip that worked fine , i got AC but still 1000 ms compared to 450;
btw ,how does this work, why it has halved the runntime.
I'm not so sure how this works, but maybe this post helps: link
Am i wrong or the problem A was so easy for only 10 people sent it in the contest? As you can see I am purple guy, and I had the basic ideia during the contest in 5~10 minutes and solve it after contest without help. I think i did not solve it correctly, because nobody was passing it. So, I thought i could not solve it. Was that the hardest problem in the contest?
Honestly, I found C a bit harder than A, but A had such little submissions because : 1.Nlog^2(N) for SA might not get passed. 2.It was a lot to code.