


535A - Тавас и Нафас
First of all check if n is one of the values 0, 10, 11, …, 19. Then, let’s have array x[] = {"", "", "twenty", "thirty", …, "ninety"} and y[] = {"", "one", …, "nine"}.

Let 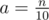 and b = n modulo 10.
and b = n modulo 10.
If n is not one of the values above, then if a = 0, print y[b], else if b = 0 print x[a] otherwise print x[a]-y[b].
Time complexity: O(1)
Another Code by PrinceOfPersia
535B - Тавас и СаДДас
Sol1: Consider n has x digits, f(i) = decimal representation of binary string i, m is a binary string of size x and its i - th digit is 0 if and only if the i - th digit of n is 4. Finally, answer equals to 21 + 22 + … + 2x - 1 + f(m) + 1.
Time complexity: O(log(n))

Sol2: Count the number of lucky numbers less than or equal to n using bitmask (assign a binary string to each lucky number by replacing 4s with 0 and 7s with 1).
Time complexity: O(2log(n))
536A - Тавас и Карафс
Lemma: Sequence h1, h2, …, hn is (m, t) - Tavas-Eatable if and only if max(h1, h2, …, hn) ≤ t and h1 + h2 + … + hn ≤ m × t.
Proof: only if is obvious (if the sequence is Tavas-Eatable, then it fulfills the condition).
So we should prove that if the conditions are fulfilled, then the sequence is Tavas-Eatable.
Use induction on h1 + h2 + ... + hn. Induction definition: the lemma above is true for every sequence h with sum of elements at most k. So now we should prove it for h1 + h2 + ... + hn = k + 1. There are two cases:
1- There are at least m non-zero elements in the sequence. So, the number of elements equal to t is at most m (otherwise sum will exceed m × t). So, we decrease m maximum elements by 1. Maximum element will be at most t - 1 and sum will be at least m × t - m = m(t - 1). So according to the induction definition, the new sequence is (m, t - 1) - Tavas-Eatable, so h is (m, t) - Tavas-Eatable.
2- There are less than m non-zero elements in the sequence. We decrease them all by 1. Obviously, the new sequence has maximum element at most equal to t - 1 so its sum will be at most m(t - 1). So according to the induction definition, the new sequence is (m, t - 1) - Tavas-Eatable, so h is (m, t) - Tavas-Eatable.

For this problem, use binary search on r and use the fact that the sequence is non-decreasing and 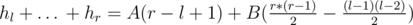 .
.
Time complexity: O(qlog(mt))
536B - Тавас и Малекас
First of all you need to find uncovered positions in s (because rest of them will determine uniquely). If there is no parados in covered positions (a position should have more than one value), then the answer will be 0, otherwise it’s 26uncovered. To check this, you just need to check that no two consecutive matches in s have parados. So, for this purpose, you need to check if a prefix of t is equal to one of its suffixes in O(1). You can easily check this with prefix function (or Z function).

Time complexity: O(n + m)
536C - Тавас и Пашмакс
For each competitor put the point 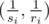 in the Cartesian plane. So, the time a competitor finishes the match is
in the Cartesian plane. So, the time a competitor finishes the match is 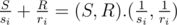 .
.
Determine their convex hull(with maximum number of points. i.e it doesn’t matter to have π radians angle). Let L be the leftmost point on this convex hull (if there are more than one, choose the one with minimum y component). Similarly, let D be the point with minimum y component on this convex hull (if there are more than one, consider the leftmost).
Proof: 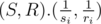 is the scalar product that is smaller if the point is farther in the direction of (S, R). It's obvious that the farthest points in some direction among the given set lie on a convex hull. (S, R) can get any value that is vector in first quadrant. So we need the points on the convex hull that we actually calculate (also we know that the points on the right or top of the convex hull, are not in the answer, because they're always losers).
is the scalar product that is smaller if the point is farther in the direction of (S, R). It's obvious that the farthest points in some direction among the given set lie on a convex hull. (S, R) can get any value that is vector in first quadrant. So we need the points on the convex hull that we actually calculate (also we know that the points on the right or top of the convex hull, are not in the answer, because they're always losers).

It’s easy to see that the answer is the points on the path from D to L on the convex hull (bottom-left arc). i.e the bottom-left part of the convex hull.
Time complexity: O(nlog(n))
In this problem, we recommend you to use integers. How ? Look at the code below
In this code, function CROSS returns 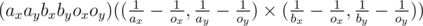 (it's from order of 1016, so there won't be any overflows.)
(it's from order of 1016, so there won't be any overflows.)
In double version, you should have a very small epsilon.
Code of double version by PrinceOfPersia
Another Code With Lower Envelope of Lines by Haghani
536D - Тавас в Канзасе
For each vertex v, put a point (dis(s, v), dis(v, t)) with its point (score) in the Cartesian plane. The first player in his/her turn chooses a vertical line and erases all the points on its left side. Second player in his/her turn chooses a horizontal line and erases all the point below it.
Each player tries to maximize his/her score.
Obviously, each time a player chooses a line on the right/upper side of his/her last choice. Imagine that there are A different x components x1 < x2 < … < xA and B different y components y1 < y2 < … < yB among all these lines. So, we can show each state before the game ends with a pair (a, b) (1 ≤ a ≤ A, 1 ≤ b ≤ B It means that in this state a point (X, Y) is not erased yet if and only if xa ≤ X and yb ≤ Y).

So, using dp, dp[a][b][i] (1 ≤ i ≤ 2) is the maximum score of i - th player in state (a, b) and it’s i - th player’s turn. So, consider s[a][b] is the sum of the scores of all valid points in state (a, b) and t[a][b] is the amount of them. So,
If i = 1 then, dp[a][b][i] = max(s[a][b] - dp[c][b][2]) (a ≤ c ≤ A, t[c][b] < t[a][b]).
Otherwise dp[a][b][i] = max(s[a][b] - dp[a][c][1]) (b ≤ c ≤ B, t[a][c] < t[a][b]).
So we need two backward fors for our dp and another for on i. So, now the only thing that matters is updating the dp. For this purpose, we need two more arrays QA and QB.
QA[b][1] = the minimum value of pairs (dp[j][b][2], t[j][b]) and QA[b][2] = minimum value of pairs (dp[j][b][2], t[j][b]) such that t[j][b] > QA[b][1].second in the states we’ve seen so far. Similarly, QB[a][1] = the minimum value of pairs (dp[a][j][1], t[a][j]) and QB[a][2] = minimum value of pairs (dp[a][j][1], t[a][j]) such that t[a][j] > QB[a][1].second in the states we’ve seen so far. Now updating dp is pretty easy :
dp[a][b][1] = s[a][b] - (t[a][b] ≤ QA[b][1].second?QA[b][2].first: QA[b][1].first).
dp[a][b][2] = s[a][b] - (t[a][b] ≤ QB[a][1].second?QB[a][2].first: QB[a][1].first).
And updating QA and QB is super easy.
Now, let f = dp[1][1][1] and S be the sum of scores of all points. So, the score of first player is f and the second one is S - f.
Time complexity: O(n2)
536E - Тавас в пути
Let's call the answer for vertices v and u with edges e1, e2, ..., ek on the path, score of sequence w(e1), w(e2), ..., w(ek).
Use heavy-light decomposition. Decompose the edges into chains. So, for each Query, decompose the path into subchains. After solving the problem for them, combine them. Problem for subchains is :
We have an array a1, a2, …, an and q queries. Each query gives numbers x, y, l (1 ≤ x ≤ y ≤ n) and we should print the goodness of subarray ax, ax + 1, …, ay.

For this problem, we have too choices: 1.Solve offline with a normal segment tree. 2.Solve online using persistent segment tree. Now, I prefer to use the first approach. Sort the array to have a permutation of 1, 2, …, n: p1, p2, …, pn and ap1 ≥ ap2 ≥ … ≥ apn. Also sort the queries in the decreasing order of l. No for i - th query (in the sorted order) we have information: x, y, l, index.
Then, use two pointers. Keep a pointer = n and Initially we have a binary string b, of length n with all indices set to 0. Then in each query:
for i = 1 to q
while (pointer > 1 and l[i] >= a[pointer])
Set p[pointer]-th bit of b (from left) to 1
pointer = pointer - 1
answer to query number index[i] = T(bx…by)
Now, we should fins T(bx…Ty). For this purpose, we need a segment tree. In each node of the segment tree, we need to keep a package named node.
struct node{
int p, s, cnt, tot;
};
A package node is used for calculating T of a binary string c. p = the number of leading 1s, s = the number of trading 1s, cnt = the total number of 1s, tot = the T value of the binary string after deleting its leading and trading 1s.
Merging two nodes is really easy. Also after reversing c, we just need to swap p and s.
So, we can determine the node of this subarray in subchains.
After solving these offline for subchains it's time for combining.
Merge the node of subchains in the path from v to LCA(v, u) then merge the result with the reverse of the nodes of answers in the subchains in path from LCA(v, u) to u.
Time complexity: O((n + m)log2(n))
Code by PrinceOfPersia (This was one of the hardest codes I ever wrote in competitive programming :D)

If there's any suggestion or error, just let me know.







Bloody hell that was the fastest editorial I have seen o.O
Editorial faster than systest done. pride of tehran prince of persia
You didn't keep your word, commented here without entering div-1.
Wow, fast editorial and some nice picture! Really appreciate for your great effort to make this contest
Thank HosseinYousefi for the pictures :D
Thank viber for pictures :|
So they are viber stickers?
yep but they'r cool
I think that 536B problem has weak test-cases, you can check my accepted solution (wich I think is not correct)
Yes.. My aceepted code gave output 5 in case 70..
it is not only fast it the best editorial with pictures and codes in different languages! Thanks for round!
Good Contest
Heavy-Light decomposition on 2-hour contest? Seriously?..
Of course, I understand, that it is a cool task. I liked solving it. But when I realized, that I have to code HLD, I almost cried.
I don't blame you for bad task – it is really cool, but not this time. It is not that I personally want to see on Codeforces round :(
HLD has been in CF contests before. Also, the decomposition itself is just a DFS, it's pretty easy when you know the idea well.
Still some guys solved this problem, unlike E from your(Codeforces Round 239 (Div. 1)) contest:)
does anybody think that the problem is too hard for Div2 C? just asking, i spent 3/4 of my time for figuring the solution and no clue at all :'(
Div. 1 A is definitely the worst problem I ever seen. I know many people (including me) who has no any idea how to prove their AC solution.
Have you ever heard about OI !? Codeforces is not just for practicing ACM ICPC, also for OI. In OI there are thousands of tasks like this.
Isn't there full feedback in OI?
Not everywhere, like COCI ;) :P
How aren't you afraid to submit a solution that you are not sure it'll work? Aren't you afraid of the penalty? I almost never risk but it seems like not risking isn't a good practice...
Well, a bit of sixth sense and logic, I guess. Many people submit this problem and have AC. Also, there were no hacks on it at all. And also it is the first problem. It means that solution might be very very stupid, so...
And anyway if choice is between submit something bad and submit nothing, what will you choose? :)
If the scoring is partial, of course, I will submit something bad and I will try to optimize it as much as possible but when the scoring is like in CF with -50 penalty for wrong submission I think that I won't risk. But next time I will try not to be so afraid to risk and I will see what will happen :)
You get the -50 penalty only if you actually end up solving that problem. So it is always better to submit something you are not sure of than nothing :)
That's right, next time I will be more confident.
"Definitely the worst problem I have ever seen" — are you serious man -.-? This problem has really short and easy proof. Even if we assume that proof is hard then "definitely worst problem I have ever seen" is 1000 times too strong statement than it should be.
Why in Div.2 C in example
2 1 4
1 5 3
3 3 10
7 10 2
6 4 8
first answer is 4? Cos as understand the length of first 4 karafs are: 2 3 4 5 -> 1 2 3 5 -> 0 1 2 4 -> 0 0 1 3 -> 0 0 0 2 -> 0 0 0 1
When choosing m items, it is not necessary that they are continuous.
Original :- 2 3 4 5
Step 1) 2 2 3 4
Step 2) 2 1 2 3
Step 3) 2 0 1 2
Step 4) 1 0 0 1
Step 5) 0 0 0 0
oh, thanks
Is it allowed to convert 2 0 1 2 to 1 0 0 1 when it is written in the problem that heights must be distinct to bite them? As I understood it from this statement: "For a given m, let's define an m-bite operation as decreasing the height of at most m distinct not eaten Karafses by 1".
Distinct karafses, not heights of karafses
The m do not have to be consecutive. Can do 2345 -> 2234 ->1223 -> 1112->1001 -> 0000
In Div1B, why should we only check the overlappings of consecutive occurences? Why then, say, 1st and 3rd occurences can't overlap in a bad way?
If 1st and 3rd overlap in a bad way, and at the same time 2nd and 3rd are OK, then 1st should also overlap in a bad way with 2nd.
Well...why? I don't get that :( These mutual substrings can be very very different. And, as far as I can see, we know simply nothing about them. Could someone please prove this?
Any position from the part in which 1st and 3rd overlap should belong to both 2nd and 3rd; it can't be to the right from 2nd, because 2nd ends at least as far as 1st does, so in this case it should be also to the right from 1st. In the same way you can prove that it can't be to the left from 2nd.
And the fact that intersection between 2nd and 3rd is OK tells you that they have same corresponding characters, so there is no difference for you — compare your char with given char in 2nd or with same char (but at other position) in 3rd.
Woohoo, now it's clear! Thank you very much! :)
I think of another approach(with also linear complexity and same amount of code and easy to proof)
First, fill the string according to the nearest constraint for each position. Second, run a string matching algorithm to see if they really matches.
In Div 1 C, why doesn't the function CROSS overflow? It involves multiplication of 6 numbers in the order of 10^4. Could anyone explain it more explicitly?
You start with the following:
(1/ax — 1/ox)(1/by — 1/oy) — (1/ay — 1/oy)(1/bx — 1/ox)
You only wish to check the sign of this value, so you can multiply by any nonnegative number. That being the case, let's multiply by (oy*ox). This gives some nice cancellations:
(ox/ax — 1)(oy/by — 1) — (oy/ay — 1)(ox/bx — 1)
Then multiply by (ax*by), cancelling on the left, and keeping it separate on the right:
(ox — ax)(oy — by) — (ax*by)(oy/ay — 1)(ox/bx — 1)
Again by (ay*bx):
(ay*bx)(ox — ax)(oy — by) — (ax*by)(oy — ay)(ox — bx)
Now we have an expression which only involves a maximum of four successive multiplications. You can verify that this is the same as the expression given in the editorial.
Thank you so much.
I could not find an expression which fits in LL in contest time. That was why I used double and got WA.
At div1C I got WA. I don't know why..here is how I thought: a person i can win if there exist any R, S > 0 so that S / si + R / ri <= S / sj + R / rj is true for every j != i. We can, now, consider S = 1.If S != 1 we can just divide the equation through S and it's the same thing.So it becomes: (R / S) / ri + 1 / si is minimum.What does this looks like? it is exactly the trick of the problem batch(IOI 2002) so I kept a stack and made a conveX hull.Please help me find where my mistake is. Thanks in advance
Why in div1 A max(h1, h2, …, hn) ≤ t ?????
Because if hn>t, then after t decreases hn will be at least hn-t>0 so you can't cut it. I came up with this but I wasn't able to prove that the condition is enough...
Thanks.
EPIC fail, I've coded stupid algorithm for D with O(n) comparison, I've made a couple of mistakes (didn't consider that indexes start with 1 and tried to read y_i even if m=0), and it failed on 33th test.
Now I've fixed these errors, and my inefficient solution passed all tests. WTF? :D 10721289
Seems like it's PyPy's magic optimization. Same code fails with Python: 10721757
Cute photos
http://ideone.com/Gzqugt Why my solution gives WA on codeforces for the problem 535B — Tavas and SaDDas.
It breaks for the case n = 474744 on codeforces but shows correct output on ideone. Help!
Same problem here:
http://mirror.codeforces.com/contest/535/submission/10711672
Can somebody explain in detail how to solve DIV-2 C as I am unable to understand the editorial.There's a lemma.Is that a standard lemma. if Yes can anyone give me the link to that lemma .If no can someone prove that it will be the optimal way to arrive at maximum r because I am unable to think how to approach solution if say t is such that more than m is the answer.In short I mean is the above two conditions enough to get r.If yes then how can we prove that.Please help.
In DIV2 C why is
max(h1, h2, …, hn) ≤ ta condition ?Because in each m - bite, each number decreases by at most 1, so if an element is greater than t, then it can't be turned into 0 after t operations.
OH YEAH!! DAMN!!
What does (m,t) mean?
Exciting contest. LCA, never think about that.
Why am I getting Memory Limit exceeded? Div 1 B http://ideone.com/KfmcEK
Could you tell more about your solution, because I can't understand the logic of it.
It's giving wrong answer.I actually tried to use failure function of KMP algorithm to check if the suffix of the current ith positioned macth has the same prefix as i+1th position match.
Great contest,Great editorial,and Great codes by Haghani his solution for Div 2.B looks Awesome.When will the ratings change?
Can anybody please tell me why I am getting wrong answer at test 32 for DIV-2 problem D. http://mirror.codeforces.com/contest/535/submission/10722317 I am not able to see the complete input here.
We don't see complete input too. You have missed 4 million in answer, just test your code locally on small tests.
For Div.1(B) my submission is here After submission I thought it would failed system,but it passed the system. I want to know why it works??Can it works in similar problem??
Could you tell more about your solution, because I can't understand the logic of it.
In my code, in vis[] array I keep -1 if string P does not matches corresponding position when I start matching the string from that position. for Malekas' subsequence(y1, y2, ..., ym) I check it is possible to substitute string P in that position by the information of vis[].
Why this solution gets AC(10721675), if it uses hashes with one simple MODULO? I think there can be collisions. Are pretests weak or I have a mistake in my arguments?
There can be collisions, but I believe the likelihood is small enough to be negligible.
A hash collision cannot cause you to report 0 when the answer is nonzero. It can only cause you to report nonzero when the answer is 0. For example, the following could happen: p = "abcd", indices = [1, 7, 9]. Then we build the string s = "abcd??ababcd", and want to check it for consistency.
This string is inconsistent, because at position 7, we have "abab" != "abcd". We will return a wrong answer if we incorrectly report that it is in fact consistent. The modulus is 10^9 + 7, so that the probability of this error is approximately 1 in 10^9. If there is exactly one inconsistency, the chance of error is 1 in 10^9; if there are more, the chance of error is astronomically less, because you need to get the wrong answer for all of them.
You can design tests that will break certain choices of the modulus + base of the exponent, but it is extremely unlikely that any particular choice will break as long as the modulus is large.
You don't need even hashes, the tests are very poor. Check out my accepted O(|p|*m) solution: 10721289. It simply compares substrings of p for each y_i.
Any other ideas for DIV1 problem C ? Other than using the convex hull to determine the points .
Checkout JeBeK's Solution.
If I am not mistaken, this solution will have big accuracy problems, when many of points lie on one circle with (0, 0) (so their inversion images lie on one line).
Unfortunately, I didn't managed to solve it during contest, because I had two arrays declared as [1200] instead of [12000] and got Runtime Error, but now my code works fine : 10721253
We can remove competitor I, if we find some competitor J and S[j]>=S[i] && T[j]>=T[i] because he will not have any chances to win. So all values of S[i] and T[i] will be different for all competitors,and because of S[i],T[i] <= 10^4 we can say then now N is at most 10^4.
And then I checked every I,J pair and calculated what is Maximum and Minimum value of S/T where I can win,and if it's non-zero interval, we can say that competitor I can win if S/T will be between L and R.
So my code works in O(10^8), Yes I am lucky
Wrong answer at 51 for problem A div-1. with message-
wrong output format Expected integer, but "1e+006" found , actual answer is 1000000
why are you matching answers as strings? match values!!
10714667
Div1A.
I think the induction is not just on sum of {h}, but on t also.
In Div1 C, suppose ri > rj. Then can't we always find R, S such that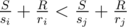 ? Like, choose S so small that the contribution due to that becomes negligible, and choose R such that
? Like, choose S so small that the contribution due to that becomes negligible, and choose R such that 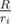 is significantly (relatively) lesser than
is significantly (relatively) lesser than  . Is this fact true ?
. Is this fact true ?
Consider the case with the following speeds (20, 2), (3, 3), (2, 20). Now while comparing (20, 2) with (3, 3) you may say lets make R large enough such that (3, 3) overtakes (20, 2) while running, but this means that (2, 20) guy will beat (3, 3) guy. Same argument applies other way around.
So, while 2nd guy can beat 1st guy and 3rd guy individually, he cant beat them both at once, hence, he cant win.
UPD: Values were wrong previously. My thanks to Swistakk for pointing it out.
It's funny because your reasoning sounds good, but for that data (2, 2) guy can win :DD. But If we will change it to (20, 2), (3, 3), (2, 20) then everything works as you described.
Ah, my bad. I was simply using a sample case I had found somewhere else and justifying that. Lesson learnt.
I got a different solution on Div1-C wich doesnt involve geometry or convex hull , (i got it accepted after the contest )
step 1: sort the pair<int,int> A[200666] (the read variables)
1) okay now the first ideea that comes in my mind is that it dosent matter how i chose S and R , what matters is their ratio S/R (i think this can be proven somehow , but its prety intuitive anyway)
2) so lets set lets say ,S equal to 1 , since it dosent matter
3) for every element i , as i iterate trough the sorted elements I will keep an interval , lets denote it (x,y) wich means if the S/R ratio is on the segment(x-y) then this element will be the fastest.
4) a first observation is that every segment is of type (0,y).
5) so i can binary search the y
6) i will keep a stack, if i get over an interval (0,y) wich has y bigger y than the last i will pop all the elements from the stack untill i cannot do it anymore.
im sorry for bad english , im really tired :D
Oh i just realized that this, in fact is building the convex hull upper envelope , except instead the cross product, I binary search the intersection point of the lines :) Lmao.
299's editorial came out but 298's is still not finished :D
Div2 B: solved in O(num of digits in n). Did Zlobober way. simple short code. Visualized it as a binary tree. in n, left to right, for each 4 go right and left for 7.
Looks like I've the smallest code for Div2 B problem :P
http://mirror.codeforces.com/contest/535/submission/10711739
ORLY?
(just sort by solution size)
Shiz! Didn't know that. Thanks. But still, loved getting small code accepted, while large codes of some of my friends failed.
Well .. I got an accepted o(q) solution for DIV 2 problem C which was also DIV 1 problem A without use of binary search that is o(1) per query
http://mirror.codeforces.com/contest/535/submission/10715662
Only two conditions are needed for binary search in Div2 C. I cannot understand how only these are sufficient enough to solve the question.
Another way to find if there are any contradictions in Div1B is to try to actually build string s by simply assigning any of the valid possible characters to each covered position (and we can build this in linear time by choosing the character determined by the most recent number in the input sequence), do KMP on it and check that the string p is found at all the positions from the input,
During the contest, I knew to use Z algorithm for Div. 2 D / Div. 1 B and then take into account the uncovered ones. But the problem is a bit unclear to me: it says that Malekas listed down ALL possible positions of his favorite string. Well then what happens if we make his favorite string using the uncovered positions? If he is not allowed to do that, then the answer is no longer 26uncovered .
Am I incorrect in noticing this or is there a clarification in the problem that addresses this?
Thanks.
...Then Malekas wrote down one of subsequences of x1, x2, ... xk (possibly, he didn't write anything) on a piece of paper...
I have a question for div2 C. Suppose there is a list of random values(h1,h2,h3,..,hn). We need to find maximum value of r where r<=n. Is it possible now to solve in the similar way using this method
max(h1, h2, …, hn) ≤ t and h1 + h2 + … + hn ≤ m × t? Thanks in advance.Yes. But you will need RMQ. Total complexity becomes O(Q lg N lg N) I believe
very good problems!
Very Nice Problem! Love it!
could you explain, when did i do mistake? It is 536B - Tavas and Malekas (Div1|Problem B) P.S. prefix-function is exactly correct. 10726241
I've got my solution AC on "536B — Tavas and Malekas", but after that I've discovered a test where my solution gives a wrong answer:
Solution gives non-zero answer, but clearly it should be zero on this test. Could U please add this test to a test set? My guess is that solution does not need to check a full match of a substring, but just the first letter match.
Another solution for problem B(DIV 2)!
Is it correct for a solution for 536B of O(p.size()^2 + m) to be accepted? This solution has!
It's not O(|p|2 + m), look at the
breaks. Also look at test #59. In this test, |p| = 106.What do you mean by look at the breaks? That implementation obviously using brute force approach to find the borders(both prefix and suffix) with O(|P|2) complexity.
I don't understand how it even works. Look at the third part of the nested cycle, there is
++i, not++jthere. Sojis always zero and it just finds if the first letter of the suffix is the same as the first letter in the entire string.I think your observation totally matches my finding (pls, see my comment above about check of the first letter only).
Wow, I did not notice that bug :P
You are soooo right. The how in the world does this thing even work? This is a solution written by me, so I can confirm that that is a typo/bug.
what does 'parado' mean?
Well, I had the same question and decided to ask google translate to translate it from English to Bulgarian. It offered me to try with Spanish and when I translated it from Spanish to English it said that parados means for two( link ) which actually matches the explanation.
'parados' is not even a spanish word. I think he meant paradox.
Okay, I should not use google translate anymore :)
How to do the 536E(div 1 E) using the persistent segment tree?I want to know the way to solve online.... thx.
Now, I know the way to use the persistent segment tree to deal with it online.
Solved
By the way, I think it would be nice to add
O(n)solution to editorial. E.x., 10735154problem С DIVISION 1. "Proof: is the scalar product that is smaller if the point is farther in the direction of (S, R). It's obvious that the farthest points in some direction among the given set lie on a convex hull. (S, R) can get any value that is vector in first quadrant. "
i-th points is minimal if : j = (0 .. n) ->
|R/S| * sqrt(|(1/ri)^2 + (1/si)^2|) * cos((R, S)^(ri, si)) -|R/S| * sqrt(|(1/rj)^2 + (1/sj)^2|) * cos((R, S)^(rj, sj)) <= 0
Why don't we care about second multiplier? It's not clear for me. Also for point L we can just take vector(R = INF, S = 1), now it's minimal. Symmetrical we can take for D (R = 1, S = INF). But how can we proof that for every point on the path we can take a vector (R, S) which makes that point muinimal?
In Problem D div 2 what should be the answer if the test case is : n = 10 , m = 2 p = "ibic" m --> 1 3 as I found 2 AC solutions one of them get answer 0 ans the other gets 456976
Answer should be 0. One "ibic" starting from index 0 and the other from index 2, not possible.
i can't understand answer of problem D in div1, why QA keep the second minimum sum and count? my friend can't understand your blog either... can you write more proof about QA and QB?
mybe you can write to me? my e-mail is 978632333@qq.com. i'm SOOOOOOOOO curious about this problem!!!
div1 C test 43 is: 3 1000 3000 1500 1500 3000 1000
and it's answer is: 1 2 3 when we change x -> 1/x we have this points: p1: 0.001 0.0003333 p2: 0.0006667 0.0006667 p3: 0.0003333 0.001
the convex-hull has 3 points, the leftmost point is p3 and the bottom one is p1 and the path between p1 and p3 dose not have p2 what is my mistake?!so the anse
Great contest PrinceOfPersia
Is the following intuition correct. If (1/s, 1/r) lie on the convex hull, (s, r) will also lie on the convex hull. I am not able to imagine what exactly will happen with these points. But the line joining these points will become a hyperbola. Any ideas for me?
I have a hell big confusion. Please help me out: In Div. 2 D: consider test case: 7 2 babx 1 3 jury's answer is 26. But here s[4] = 'x' because of y1 = 1, s[4] = 'a' because of y2 = 3. 2 different values cannot be at the same position. So, answer should be 0.
In 536B — Тавас и Малекас can someone explain why the answer will be 26^(uncovered) as it might possibly generate new matches that were not encountered like: Say length of s = 4, p = "a" then in such scenario s = "a??a" replacing second and third position would generate new matches of string p in string s, whereas the question says that numbers all matches is given and fixed.
The dog is really funny!