


Code Jam Round 1B начнется через несколько часов(19:00 MSK).
GL & HF.
| № | Пользователь | Рейтинг |
|---|---|---|
| 1 | Benq | 3792 |
| 2 | VivaciousAubergine | 3647 |
| 3 | Kevin114514 | 3603 |
| 4 | jiangly | 3583 |
| 5 | strapple | 3515 |
| 6 | tourist | 3470 |
| 7 | dXqwq | 3436 |
| 8 | Radewoosh | 3415 |
| 9 | Otomachi_Una | 3413 |
| 10 | Um_nik | 3376 |
| Страны | Города | Организации | Всё → |
| № | Пользователь | Вклад |
|---|---|---|
| 1 | Qingyu | 158 |
| 2 | adamant | 152 |
| 3 | Um_nik | 146 |
| 4 | Dominater069 | 144 |
| 5 | errorgorn | 141 |
| 6 | cry | 139 |
| 7 | Proof_by_QED | 136 |
| 8 | YuukiS | 135 |
| 9 | chromate00 | 134 |
| 9 | TheScrasse | 134 |
Code Jam Round 1B начнется через несколько часов(19:00 MSK).
GL & HF.






Good luck guys!:D
Thank you )
Я правильно понимаю, что тем, кто уже прошел в раунд 2, остается только завистливо вздыхать и ждать дорешку?
Кажется, Вы можете писать этот тур вместе со всеми.
А как в таблице неофициальные участники отображаются? В след. раунд проходят топ 1000 без учета вне конкурсных? Как вычислить свое нормальное место?
Неофициально никто не участвовал.
Входящее после раунда 1А:
Hello LeBron,
Congratulations, you have qualified for Online Round 2 based on your performance in Round 1A. Please note that you cannot compete in Round 1B or Round 1C.
Как решать B?
у меня такое зашло. заполним все как шашки. потом пока не заполнили нужное количество, ищем клетку с мин количеством соседей и туда заселяем). ну и потом перекрасим каждую клетку в другой цвет и опять так сделаем и выберем минимум.
Зашла такая ерунда (по крайней мере, не доказал ее): раскрасим доску по-шахматному, сначала ставим жителей на белые клетки, а когда они закончатся, жадно на остальные (от клеток с наименьшим количеством белых соседей к клеткам с наибольшим количеством), потом наоборот. Минимум из ответов для этих способов будет ответом на тест.
Решение за O(1): Если n ≤ (r * c + 1) / 2, то ответ 0. Иначе давайте выбирать, какие клетки сделаем свободными. Раскрасим клетки в шахматном порядке. Все свободные клетки будут одного цвета. Переберём, какой именно цвет, потом жадно сделаем свободными сначала внутренние клетки, потом клетки, лежащие на границе, но не в углу, потом клетки, лежащие в углу.
The contest in Gym: 2015 Google Code Jam Round 1B (GCJ 15 Round 1B).
Will Round 1A also appear in a Gym? If not Mike, could someone with trainer permissions add it? Thanks.
Can someone help me, how can I see failing test case? Thanks
edit: I found the problem 5 3 9 -> 3 (I had 4)
5 3 9 -> 3 is correct
x is where the neighbor located, and o is empty space
xox
oxo
xox
oxo
xxx
which is the best strategy to get minimum possible unhappiness (3).
Hmm, seriously, I have no idea about A and B. I just wrote brute force and guessed the pattern.
You make it sound too simple...
congratulations
I reduced this problem to the following one. Select M edges from the graph so that they have minimal number of incident vertices, but did not know how to solve it. Any ideas how one can tackle this problem?
Graph is bipartite. Let me denote L, R as two parts of graph where every edge is between L and R.
if n ≤ |L| then the answer is 0 else, we will add more nodes from R part and every node will increase the answer by it's degree in the graph. So just choose those nodes with greedy approach(Which is obviously increasing order of degrees). After then swap L and R and do the same thing.
The problem here is to proof, that we should always take the whole L or R, and not some and
and 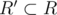 .
.
Yes, I know. I just gave him some ideas as he requested. For me, it was just a guess coming from small inputs and brute force solution. If you can share the proof it would be great!.
It is easy to construct counter-example for arbitrary bipartite graph. In this problem graph is very special.
Glad I'm not the only one. It felt a bit dirty..
Pattern for A? I don't see any easy-to-observe-and-hard-to-come-up observations here. My solution's main ideas were "You have to go through 10k - 1 and 10k for valid k's", "If 10|n, then ans(n) = 1 + ans(n - 1)" and "If I have a digit which is a positions from left and b positions from right I need to perform digit·10min(a, b) operations" and "Reverse is needed unless n looks like 1000...003454, where that 100...00 part is at least as long as half of length"
rng_58 Can you explain your solution of C ?
The problem setter pwned tourist :D
I guess that it is some fake Gennady.Korotkevich, since the original tourist ™ passes to the finals automatically as winner of the previous year.
But the coding style is similar to tourist. May be he is practicing it.
Nope, that's him, the same nickname. Also he needs to participate if he wants to be qualified to the Distributed Code Jam.
Верно ли, что в задаче А по единичке наращивается одна половина, потом число разворачивается и наращивается вторая половина?
Да, и так для каждого разряда.
Еще нужно учитывать, что правая часть иногда 0
А можно пояснить, что значит для каждого разряда?
ну сперва получаем 0 -> 9
10 -> 99
100 -> 999
....
10^k -> n
Я сначала набирал максимальное 10k ≤ n, а потом уже так наращивал половины.
Как решать C?
переобозначим n — количество людей
Заметим, что если наша скорость inf = 360/0, то ответ n.
Посмотрим, при каких скоростях меняется ответ.
Если скорость равна 360/ time * (360LL — d), то ответ уменьшается на 1(мы не успеваем догнать человека)
Если скорость равна 360/time * (360LL — d + 360 * j), то ответ увеличивается на 1(человек успевает нас догнать на 1 раз больше).
Теперь для простых тестов: положим все эти штуки (нет смысла брать больше чем 2n для одного человека) в массив/мап и выберем при какой скорости минимум.
Для сложного теста: эмулируем тоже самое с помощью очереди с приоритетами, тут уже нет смысла брать больчем чем 2n суммарно
Мой код из дорешки http://ideone.com/kaVERe
А олень же может менять скорость когда угодно? Разве константная скорость точно не хуже?
oops! :D
Ну на самом деле понятно почему: Рассмотрим сколько фиксированный человек прошел и сколько мы. Заметим, он нас сколько-то раз обогнал как минимум, заметим что если мы не меняли скорость, то как раз минимум достигается
For A-large, I noticed that the answer depended on numbers like 1,11,101,1001,10001, ... and also if N was of order k, then the answer could be found out by a smaller number of order ceil(k / 2) . I couldnt formulate it exactly. Can someone please explain their solution?
First you want to have same number of digits as n. So, you want to move 1->10->100->.. Let's say you have d digits in total. The best strategy is to move to 100..099..9(d/2 times 9) then reverse this to 99..9(d/2 times)0..01 and add 99..9(ceil(d/2) times) to reach 100..0(d+1 digits).
After that, you would want to make transformations such that, after reverse you have same prefix as n or lesser than that. For example, if you have 10000..0(d+1 digits) and n is of from n0, n1, ..nd, then you have to try for all prefixs n0, ..ni and make 100..ni, ni - 1, ..n0. After that apply reverse to get n0, n1, .., ni00..1. You will have to add ni+1,..nd(suffix) — 1. Make sure that the add component is greater than 1, if it is zero, substract one from prefix and add 1 in the MSD of suffix.
Can you explain why your strategy to move from d digits to d+1 digits is optimal? Is there some standard method behind it or it's just intuitive?
It's intuitive, but can also be proved easily. This problem is adhoc in nature, so there is no standard method(atleast I don't know of any).
Also, you can sort of follow the approach for the second part of the problem in this. Move from 100..0 to 99..9 (both d digits), and add one to that (you cannot avoid adding one if you want to move to d + 1 digits.)
I only knew that the flip cannot increase the digit of a number, so must go from 1-->10-->100... But then I have totally no idea...
Also, I do not know if this is important, but will there be a unique optimal path from number a to number b (a < b), that some number c is in the path and c > b > a?
For example, from 18 to reach 28, will path like ...18-->81-->82-->28 be a unique and optimal one?
From A-small, I think the answer is No, but I cannot figure out why...
I think 18-->81-->82-->28 is the optimal path when you go from 18 to reach 28.
But, it's NOT a part the optimal path if you want to reach 28 from 1, because from 1 to 18 needs 18 moves, and from 1 to 20 needs only 20 moves. It's trivial that 18+3=21>20. That is caused from a unnecessary flip move, because you should use <=1 flip moves from any two-digit number to 11,but 18->81->82->28 have 2 flip moves.
In my solution, the optimal path from 1 to 20 is 1->2->3->4->5->6->7->8->9->10->11->12->21->22->23->24->25->26->27->28(20 moves).
Sorry for my bad English...
yes I knew it is not as I passed A-small, but I did not have a strong proof on it...also I guessed in same digit range (100-->999, or 1000-->9999), at most 1 flip is used, is that true?
it's illegal in this problem, because ai + 1 should be greater than ai.
Sorry if I missed it, but I did not see this in problem statement...(though by common sense it should be true)
OK, looks like yesterday I misread the statement, and this quickly led me to the correct solution :D
It is true, but it should be proved.
How to fail in a contest:
2*r/2written instead of2*(r/2)R*C <= 10000and notR, C <= 10000like you assumedBTW, I checked your code, and there's at least one flaw in your rust template. In this line:
io::stdin()is protected by mutex, and itsread_line()function is implemented like this:You can lock it one time and read everything directly from internal buffer:
this can lead to significant speedup.
Thanks, I'm still learning :)
I am not particularly fond of this input macro anyway, because it has to allocate and deallocate a
Stringfor every line. But I know no good way to make it work without temporaryStrings.I think Round 1B is relatively harder than 1A, isn't it?
At first, I think the first problem should be easy as in round 1A, but it turns out to be quite error prone with lots of tricky cases if one uses the greedy implementation. And I realized not many people have solved the large input, so I decided to solve the small input by dp and look at the other problem.
Again, I thought that I might not completely solve the second and third problem, so I focus on the small input. With B,
R*C<=16, so I just consider all combination of placements. With C, where there are no more than 2 hikers, the answer can only be 0 and 1.After solving these 3 small datasets with 36 points, I thought that's enough to advance since I was ranked around 300 (it turned out to be wrong as at the end, competitors with 37 points advance). But it's quite relaxed for me, then I can look at the large input of the first problem. My solution is that, with a number has k digits, we first need to reach
10^(k-1), and then for the digit d at position i (0-indexed), there's 2 ways to increment it, either10^ior10^(k-1-i), except for i=0. For example, if n=3902, we need to reach 1000, then increment to 1093, flip to 3901 and increment to 3902. In case n is divided by 10, we solve n-1 first. To be sure, I have tested the result with everyn<1000000, compared to the result of the dp approach.For large input of the second problem, when
N<=(R*C+1)/2, then the answer is obviously 0, we can always allocate the tenants so that there is no pair of neighbor. The allocation is similar with white(or black) squares of a chess board. WhenN>(R*C+1)/2, we consider empty squares instead of occupied squares. We need to maximize the number of borders of those squares. So first, we start with the inner square with 4 borders, then the edge with 3 borders and last, the conner with 2 borders. The allocation again looks like a chess board. We need to consider 2 cases: choose (1,1) or not.I haven't figured out the solution for large input of last problem yet.
Rank 1001
Congratulations! you should notice that there are some people had advanced to next round ranked in 1000th! ^_^
I dont understand your point , those who advanced in round 1A cannot take part in 1B . So rank 1001 is not supposed to decrease . But if someone is proved of plagiarism only then rank will improve ( which actually happened in 1A and 1001 th person went to the round 2 )
Check the scoreboard again. :)
Ohh wow, how wonderful indeed. Jeez, now I feel really bad for "newSolar".
Problem A and B really twisted me from inside. I want to make sure same doesn't happen in next round. Any pointers/links to similar problems like problem A and B? I have 4 days to prepare for the next chance. Also in general if someone has comments on preparing for rounds like these will be really helpful. Thanks
Practice on round 1C from 2014 and 2013. For the preparation of the round, maybe this video will help you. Mimino mentions this idea of generating the first elements of the series, to detect a pattern. Good luck!
Just curious, why only practice on round 1C from previous years? What's the difference between 1C and 1A/B every year?