


Hello everybody, Could somebody provide me with a good tutorial for suffix array data structure?
→ Pay attention
Before contest
Spectral::Cup 2026 Round 2 (Codeforces Round 1100, Div. 1 + Div. 2)
23:37:34
Register now »
Spectral::Cup 2026 Round 2 (Codeforces Round 1100, Div. 1 + Div. 2)
23:37:34
Register now »
*has extra registration
→ Top rated
| # | User | Rating |
|---|---|---|
| 1 | Benq | 3792 |
| 2 | VivaciousAubergine | 3647 |
| 3 | Kevin114514 | 3611 |
| 4 | jiangly | 3583 |
| 5 | strapple | 3515 |
| 6 | tourist | 3470 |
| 7 | Radewoosh | 3415 |
| 8 | Um_nik | 3376 |
| 9 | maroonrk | 3361 |
| 10 | XVIII | 3345 |
→ Top contributors
| # | User | Contrib. |
|---|---|---|
| 1 | Qingyu | 162 |
| 2 | adamant | 148 |
| 3 | Um_nik | 146 |
| 4 | Dominater069 | 143 |
| 5 | errorgorn | 141 |
| 6 | cry | 138 |
| 7 | Proof_by_QED | 136 |
| 8 | YuukiS | 135 |
| 9 | chromate00 | 134 |
| 10 | soullless | 133 |
→ Find user
→ Recent actions






Codeforces (c) Copyright 2010-2026 Mike Mirzayanov
The only programming contests Web 2.0 platform
Server time: May/22/2026 17:57:28 (g1).
Desktop version, switch to mobile version.
Supported by

Why not Codechef?
Thanks, actually I've read it before but I need better resources
What do you mean by better resources?
I felt that it is not clear enough for me
Did you learn this data structure from this tutorial ?
No, I don't know suffix array yet, it's still on my TODO list :D But I thought the explanation from kuruma would pretty clear and detailed.
What is suffix array data structure. Can someone explain generally in several words.
It is array p for string s such that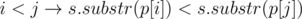 .
.
Simply put, suffix array is a sorted array of suffixes of a given string.
Okay, think what you need for a suffix array in better than O(N2) time. You want to sort suffixes in alphabetical order. Sorting is simple,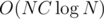 , where comparing 2 suffixes takes O(C) time. The main point is optimising C.
, where comparing 2 suffixes takes O(C) time. The main point is optimising C.
Comparing 2 suffixes = finding their longest common prefix (LCP), then you can just compare the characters that follow after that LCP. The LCP can be found using binary search, where you only need to check if 2 substrings are equal. That can be done by comparing their hashes, and the hash of any substring can be computed in O(1) time with O(N) preprocessing. This way,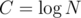 and it's often sufficient (possibly with trying to squeeze into the time limit).
and it's often sufficient (possibly with trying to squeeze into the time limit).
There's a better approach that makes suffix array construction . The previous approach used a custom comparison operator and any suitable sort(). This one uses radix sort (at least I think that's what it's called): you sort the strings by first character, then by the first 2 characters, by the first 4, 8... up to a sufficient power of 2. In step k, you store strings with the same first 2k characters in buckets, which are split into smaller buckets in the next step using the ordering by these 2k characters.
. The previous approach used a custom comparison operator and any suitable sort(). This one uses radix sort (at least I think that's what it's called): you sort the strings by first character, then by the first 2 characters, by the first 4, 8... up to a sufficient power of 2. In step k, you store strings with the same first 2k characters in buckets, which are split into smaller buckets in the next step using the ordering by these 2k characters.
How to do that? Number the buckets in increasing alphabetical order of the 2k characters. Take empty meta-buckets numbered in the same way. Traverse the suffixes in order of non-decreasing bucket number; if prefix s[i..N] is in bucket b[i], then put s[i..N] to the meta-bucket numbered b[i + 2k] — you're sorting them by the next 2k characters, basically. Then traverse the suffixes in non-decreasing order of meta-bucket number and put them back in the original buckets in that order. Tada, they're now sorted by the first 2k + 1 characters! All that's left is splitting the original buckets further, which can be done simply — just when 2 successive prefixes went in a different meta-bucket, then they'll be in different buckets afterwards.
The reason is that when 2 prefixes were in different buckets before, they will be in different buckets (and in the same order) afterwards, and if they were in the same bucket before and in different ones afterwards, then the smaller one will go into a smaller meta-bucket. This is just array juggling in O(N) per step, and you can stop when 2k > N, so the total time is really .
.
Suffix arrays can also be constructed in O(N), but why?
Thanks so mush Xellos :)
Can you please provide the O(n logn) code using radix sort if you have it in your library?
Don't you know to use google search ?
http://web.stanford.edu/class/cs97si/suffix-array.pdf
It is nice blog and you can read this.
https://cp-algorithms.com/string/suffix-array.html