


Hello everybody,
Last year I read that dynamic trees exist, that is trees in which we create only the nodes we need since there can be a lot (say we have indices 1,...,10^9). I thought it's cool and wanted to know more about it. I googled a few times "Dynamic BIT", "Dynamic trees" or something like that but I found nothing...
Recently I participated in BOI 2015 and there was a problem that required a segment tree for 60 points and dynamic segment tree or AVL Tree which I can't code for full score so I wasn't able to get more than 60 on it. Now, I tried googling "Dynamic Segment Tree" but found nothing...
Can somebody please explain how dynamic segment trees work and give me an implementation, I would appreciate your help!
Thanks in advance! :)
UPD: Thanks everybody for the help, I understood it! So basically, we initially have the root only which stores the whole interval ([1;10^9] for example). Then the update/query goes exactly like in the normal segment tree but if we don't have a child of some node but we need it, we just create it and go on. I implemented Horrible Queries from SPOJ (I know that a normal segment tree is enough, but I wanted to test it). Here is my accepted code, it might be helpful for somebody who has problems with this structure — http://ideone.com/hdI5aX.







My implementation
So many compilation errors (
It's because I chose the java compiler
Oh, right )
Thanks, I got it! :)
You can use coordinates compression technique. For example if we have 105 numbers each less than 109 you can sort them and give every unique number an index, so you will have up to 105 element and you can use segment tree easily. I've seen an implementation to dynamic segment trees using pointers and stuff but I prefer this technique to not complicate things..
Unfortunately, you could not use this technique as the task in question was interactive, so online solution was required.
Main idea: in dynamic segment tree we create a node only when we need in it.
Example: "Monkey and apples" from IZhO 2012 — Given an array of size 109 and 2 types of queries — assign 1 to segment [L, R] and get sum on segment [L, R].
Tree: We can create struct with four parameters (sum, assign_value, left_node, right_node).
Update: Apply the main idea. Assume that you stand in node 1 (segment [1, 109]) and you need to assign 1 to segment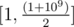 that means you need to go to your left child in tree. If your current node haven't got left (or right, doesn't matter) child we can just create it, can't we? You can do it easily — just keep counter.
that means you need to go to your left child in tree. If your current node haven't got left (or right, doesn't matter) child we can just create it, can't we? You can do it easily — just keep counter.
Get sum: Again assume that you need to find sum on segment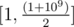 and you are currently in node 1. If your current node haven't got left child that means that you never updated this segment so it have zero sum else you can just return it's sum.
and you are currently in node 1. If your current node haven't got left child that means that you never updated this segment so it have zero sum else you can just return it's sum.
Links: Problem (Day 2, F), tests, my code, jury's code, participants' codes.
P.S Sorry for my poor English.
Thank you very much for your explanation, the jury solution helped me too! :)
You can find my implmentation in ADJA's github repo https://github.com/ADJA/algos/blob/master/DataStructures/ImplicitSegmentTree.cpp.
Thank you, it was really helpful! :)
Hi, I used your technique for solving CSES salary queries but getting TLE. Will technique work for time constraint of this problem? https://cses.fi/problemset/task/1144 Pleas find code https://ideone.com/pKCqoP
This is cool usage of the technique!
I think the TLE is coming from IO speed: you're using just cin, and the input is approaching 10^6 ints.
can someone tell me why am i wrong?
http://ideone.com/BxPXmD
NO! What is wrong with you? This is an year old post!
There is another idea for that. It is more easy to code but every query will have O(lg2).
Use map for saving segment tree (or BIT(fenwick tree) ). like this : 18066766.
You can use unordered_map too.
Actually, I have always used that for dynamic fenwick but it never came to my mind to do it for segment tree, thanks. BTW, is there a way to make dynamic fenwick tree that works in log instead of log^2 (excluding unordered map because such tree didn't perform well if I remember correctly)?
Yes, you can write your own hashtable. If you do choose a good version of ht you'll get O(logn) on most cases.
These two posts can help you about
unordered_map:Is unordered_set faster than set?
Any thing about unordered_map
Actually, I have looked at your blog before, but it seems like I have missed the last update, thanks! :)
BTW,
s.max_load_factor(0.25)is not really a solution. Check the memory consumed by a program with/without those tricks (at least forstd::unordered_map).