


Заметим, что если в массиве есть две пересекающиеся непрерывные неубывающие подпоследовательности, то их можно объединить в одну. Поэтому можно просто проходиться по массиву слева направо. Если текущую подпоследовательность можно продолжить с помощью i-го элемента, то делаем это, иначе начинаем новую. Ответом будет максимальная из всех найденных подпоследовательностей.
Асимптотика — O(n).
Сначала отсортируем всех друзей по возрастанию денег. Теперь ответом будет какой-то подотрезок массива. Далее будем использовать метод двух указателей для нахождения требуемого подотрезка.
Асимптотика — O(n log n).
Будем спускаться по дереву от корня, поддерживая дополнительный параметр k — количество встреченных подряд вершин с котами. Если k превысило m, то выходим. Тогда ответ — это количество листьев, до которых мы смогли дойти.
Асимптотика — O(n).
Для решения задачи будем использовать двумерное ДП. Первым измерением будет маска уже взятых блюд, а вторым — номер последнего взятого блюда. Для переходов будем перебирать все нулевые биты текущей маски. Будем пытаться поставить в них единицу, а затем обновлять ответ для новой маски. Ответ будет состоять из ответа для старой маски, ценности блюда, которому соответствует добавленный бит и правила, которое может быть использовано. Окончательным ответом будет максимум из всех значений ДП, где маска содержит ровно m единиц.
Асимптотика — O(2n * n2).
Для начала посчитаем хэш для всех элементов строки в зависимости от их позиций. То есть хэш цифры k, стоящей на i-й позиции будет равен gi * k, где g — основание хэша. Для всех хэшей построим дерево отрезков сумм, поддерживающее групповую модификацию. Таким образом, запросы на модификацию мы можем выполнять за O(log n). Осталось разобраться с запросами второго типа. Допустим, нужно обработать запрос 2 l r d. Очевидно, что подстрока с l по r будет иметь период d, если подстрока с l + d по r равна подстроке с l по r - d. С помощью дерева сумм мы можем узнать сумму хэшей на подотрезке, а значит можем сравнить две строки за O(log n).
Асимптотика — O(m log n).







Автокомментарий: текст был обновлен пользователем igdor99 (предыдущая версия, новая версия, сравнить).
Что за адовый седьмой тест в первых двух задачах?)
Вылетает за тип
У авторов есть детерминированное решение задачи E, укладывающееся в TL? Похоже, что здесь можно сделать что-то типа корневой по запросам.
13165100 детерминировано и быстро!
То есть вы, что ли, просто реализовали наивное решение, впихнув по 8 итераций в одну? Больше никаких модификаций?
Основное ускорение дает то, что за 1 итерацию сравнивается сразу 8 символов как long long. А то, что внутри цикла выполняется по 8 итераций тоже дало ускорение, но небольшое, порядка 15%.
На самом деле, самое наивное решение с
memsetиmemcmpтоже проходит все тесты, но это уже ошибка автора, так как его "максимальный" тест не совсем максимальный =) На моем тесте в запуске это работало порядка 1.4 секунды.Просто очень сильное колдунство) У меня тоже memset очень быстро работает при заполнении, когда на самом деле операций 10^10. Жаль, нельзя юзать для задач, где значения превосходят 127, т.е. являются интами, там можно юзать 4 массива — каждый показывает очередные 8 бит числа i, но это уже медленнее
На самом деле, думаю и на ваш тест можно пихнуть это решение. Я просто добавил scanf и вывел объявление переменных внутри цикла за его пределы и работает 686 мс. тыц
Задача D хорошая!
DEL
ты живешь под каблуком — у меня весь город под подошвой!
N=228228;Мемный контест
Use __builtin_popcount(int) in C++ for counting non-zero bits instead of new function
I think you wanted to say l+d r and l r-d.But you forgot a case.
For example 12312312,123123 can be solved using that method because is periodic,but the part that remains (12 in our example) has to be compared to the prefix of the same length.
12312312 is periodic, because two bold parts are equal: 12312312 and 123 12312. Everything is OK.
Sorry, we had mistake. Thanks for your attentiveness! =)
Один я считаю, что давать авторским решением хэши — не самый удачный ход?
Полностью с вами согласен, но на момент написания раунда мы незнали других решений этой задачи.
Ну это в целом допустимо, если по другому никак не решается. Хотя, конечно, учитывая наличие системы взломов, довольно весело наблюдать, как твоё нормальное решение приходит и ломает Иван Смирнов :)
Вряд ли Иван Смирнов сломал бы хеш по рандомному модулю.
Ну рандомный модуль — сложно. Вроде рандомного основания достаточно.
Я верю в то, что больших дырок между простыми не бывает)
На всякий случай можно написать пятерной хэш с пятью случайными модулями, сгенерированными в java, а еще сравнить в каждом запросе 10 случайных символов, чтобы они совпадали
Это уменьшает вероятность ошибки, но не исключает её полностью. Всё-таки, хотелось бы, чтобы существовало решение, которое с гарантией на всех входных данных даёт правильный ответ.
Так оно существует)) Вот: 13165100
In Problem B:
How the inner loop (inside the outer one which iterates from 0 to n) of the two pointers method affects the complexity.
Here's my solution :
http://mirror.codeforces.com/contest/580/submission/13175844
I thought it would give me TLE.
can anyone explain the complexity ?
In your loop, you don't reset st, so, st and i would be incremented at max. the size of array.
(None of them are re-initialized to zero)
Got it, thank you :)
What is this "method of two pointers" ???
I think this link can help
Yes, I saw that. But, that link describes on 2 arrays. Here we have 1 array only...
The same concept :)
In E, isn't it possible that hashing will create collisions and hence give an incorrect result? If yes then hacking solutions in E will produce incorrect results for hacks that should be succesful.
Fortunately, nobody knew which mods and bases were used in authors solution :)
I know that the probability of error is small if we choose a good base and a good prime but that doesn't mean that we can ignore the probability that there were collisions in the authors solution as well right?
Actually it does. Lets do a little math. Assume that N = 105. There are (105)2 substrings of the input. Authors are probably using 32-bit integer to store the modulo, to make calculations easier assume that mod = 109, It means with a uniformly random distribution, for each 0 ≤ x < 109 there are 10 substrings where each of them has a hash value equal to x. For each query probability of collision is equal to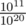 , because there are 109.102 ways to choose collision pair and (1010)2 ways to choose any two substring. It means for each query probability of having a correct answer is 1 - 10 - 9, which means probability of having correct answer for all test cases is (1 - 10 - 9)105.80 = 0.992.
, because there are 109.102 ways to choose collision pair and (1010)2 ways to choose any two substring. It means for each query probability of having a correct answer is 1 - 10 - 9, which means probability of having correct answer for all test cases is (1 - 10 - 9)105.80 = 0.992.
It's up to you to worry about %0.7 probability of fail.
Thanks for the probabilistic insight, is really helpful :)
What about two primes? Like two bases and two mods.
My solution to problem B is giving TLE. SOLUTION
Here I have an index j which is run from the end and if the difference is within d then I do not check further for the subsegments of this segment.I do this for every i from 0 to n-1.I am not able to figure out why the TLE.
Your solution goes to O(n^2) because of the for loop in line no. 29.
Consider the following example: d = 5 5 15 25 35 45 55 65 75 This is the array of money values (values of n[i].m in your case). For i = 0, j starts at 7 and reduces till 0. For i = 1, j again starts at 7 and reduces till 1. And this continues for all the values of i.
For a general n, the complexity of this loop would be n + (n — 1) + (n -2) + .... This is O(n^2)
Can someone explain E in a little more details please? I've never used hashes before and I don't know how to pick the base — why does this work? I mean, there are 10^100000 possible serial numbers, and that's a lot more than possible values of hashes. So why don't we worry about that? How to estimate how good is our picked base?
Also I don't quite understand this segment tree. Seems pretty tough to implement. Is this some kind of modificated segment tree for updating range and querying sum on range? I never really knew how to implement it (only segment-point and point-segment variations), let alone modifications. How can we support this group modification for all hashes — just a little sketch, please? :)
For question D can some one explain how the answer is coming 37 for this test case?
5 5 5
3 3 3 3 3
3 4 6
4 1 2
1 5 7
5 2 4
2 3 5
Thanks!
1 5 2 3 4
Yeah i got it . Thanks by the way!
Can someone please explain the time complexity in question 580D? How is the time complexity O(2^n * n^2)? We are taking dp[(1<<18)][18], should it not be O(2^n * n) ?
inside the recursive function we do an O(n) loop over all dishes. so we have a table of size (1 << 18) * 18 with O(n) to fill each cell so overall the complexity is O(2^n * n^2)
Oh! I get it! Thank you.
Please, can someone help me understand what's the problem with my submission for 580A? =/
http://mirror.codeforces.com/contest/580/submission/13188909
That's convert your code.
as this question is very old(5 years) and i am not able to solve this question please can you help me with solving it just mention the states of dp and transitions...please
Which question are you talking about ?
if atual < ant but seq < longest, you should let seq equals 1. because it's a new sequence
Well, I believe that the std of problem E can be hacked.
Solutions are completely unreadable. Specially for the first two questions!
why im getting runntime error
include
include
include
using namespace std;
define f(i,n) for(i=0;i<n;i++)
typedef long long int ll; typedef vector v; typedef vector< vector > vv; typedef pair<int,int> p; typedef unsigned long long int ull; int main() { ll n;//number of friends ll d,i,j;//scale for poor ll m,s;//money and friendship of the each friend cin>>n; cin>>d;//friendship factor ull friend_temp=0,friends=0; vector < p > mp(n); for(i=0;i<n;i++) { cin>>m>>s; mp[i].first=m; mp[i].second=s; } sort(mp.begin(),mp.end()); for(i=0;i<n;i++) { friend_temp=0; for(j=i;mp[j].first<mp[i].first+d;j++) { friend_temp+=mp[j].second;
}
Put your code here or here and post only the link here
Why memset and memcmp work in problem E? :s
because the final order is o(n * q / 32)
and it seems that (1e10 / 32) isn't big enough for cf servers ...
why WA in test 20 ?
http://ideone.com/76fCx6
This is your corrected code=)
Thanks a lot igdor99 :) i missed this case
Sorry Guys,
I would't have asked if I could have figured it out myself.
For question C I implemented a simple dfs algo but get WA for test case 26.
Any Ideas?
http://mirror.codeforces.com/contest/580/submission/13208683
Edit:ignore my previous comment
13212382
d[y] must be 1 before you do this d[y] + = d[child];
Can someone explain the solution for B in a little more details please?
After you sort them by money ascending order, if M[i]+d <= Mj, then M[i]+d <= M[j+1]. If person j has at least d units of money more than person i, then person j+1 too, so the answer will lie in a contiguous subsequence.
So you can use two pointers pi and pj. pi will point to the left-most person and pj to the right-most (starting both in 0 and incrementing pj). If at some moment M[pi]+d<=M[pj] (Person pj has at least d units of money more than person pi) then you will have to increment pi until M[pi]+d>M[pj]. The answer will be the segment with largest sum of friendship factor.
chotto_matte_kudasai 's solution for E is very nice :)
I'm trying to solve problem E using Segment tree and String hash. My code gets WA29, outputs "NO" instead of "YES", and I fail to find what's wrong in it. Here is the code I submitted Elise-580E.
Could you help me?
Did You get it? I am also facing the same problem.
can someone pls explain me the logic of question no 580D.
UPD modulo and randomization helped.
Can anyone tell me what is wrong with test # 75 http://mirror.codeforces.com/contest/580/submission/13208727 http://mirror.codeforces.com/contest/580/submission/13229611 I even checked hashes bf http://mirror.codeforces.com/contest/580/submission/13229546 They are equal with all keys I tried. Thank you
Hi Infoshoc how did you resolve that problem? I have the same problem with that case 24274322
Could someone give me some links about hash functions? I've studied it in class but superficially. We talked about hash functions in an abstract mode (i.e. we suppose that f is a good hash function without specifying the body, we only saw the basic hash functions such as f(x)=x%m) without seeing nothing about base of the hash or how to merge two hashes into another (in order to make the sum tree). So in contests i don't know how to approach it in order to make a good hash function or how to manipulate it. Thanks in advance!
http://mirror.codeforces.com/contest/580/submission/13820453 I keep getting TLE at test 10 for A. What's wrong?
http://mirror.codeforces.com/contest/580/submission/13820822 Shortened the code, only one loop but still TLE at test 10, this is mad.
Change array size to 100000 from 10000. AC :)
Долго думал, что где-то я уже видел задачу B.
И бинго, я вспомнил.
Задача B — абсолютная копия задачи с областной олимпиады в Беларуси 2013 года. Тур второй, задача 2. Единственное отличие задачи B от задачи с области, так это то, что в задаче B нужно было написать if для проверки что можно обновлять ответ.
Условие задачи с области — Link.
Hi Can anyone help me with D.Kefa and Dishes. I have used top-down dp but my solution is giving TLE. I think I have followed the same process as in the editorial with same time complexity. Thanks in advance. My solution:
Can anyone explain why changing the code 24234913 to 192701811 give AC. Just by changing the "set bit count process" to "__builtin_popcountll" ?
Edit: Another Ac 192702606 just change the process of set bit count. Count till there is a set bit in number not till n. I think "__builtin_popcountll" has similar internal working so it get ac.
I think it is due to the tightly bound-in problem you are not getting AC.
Why there is runtime error on test 27 of 580C using python? http://mirror.codeforces.com/problemset/submission/580/54878038
BFS solution for C (Kefa and Park): https://mirror.codeforces.com/contest/580/submission/77761479
https://mirror.codeforces.com/contest/580/submission/253436860
Hello, can anyone please figure out why is it giving TLE, it does have a O(n) TC.
for A.
580A - Kefa and First Steps
289820389 I think it's the correct code. but cf judge show it's wrong for test case no 4..
but.. cf judge show
Verdict: WRONG_ANSWERwrong answer 1st lines differ - expected: '6', found: '7 '