


Qualifcations already happened :). Let's discuss problems.
→ Pay attention
Before contest
Rayan Programming Contest 2024 - Selection (Codeforces Round, Div. 1 + Div. 2)
5 days
Register now »
Rayan Programming Contest 2024 - Selection (Codeforces Round, Div. 1 + Div. 2)
5 days
Register now »
*has extra registration
→ Top rated
| # | User | Rating |
|---|---|---|
| 1 | tourist | 3993 |
| 2 | jiangly | 3743 |
| 3 | orzdevinwang | 3707 |
| 4 | Radewoosh | 3627 |
| 5 | jqdai0815 | 3620 |
| 6 | Benq | 3564 |
| 7 | Kevin114514 | 3443 |
| 8 | ksun48 | 3434 |
| 9 | Rewinding | 3397 |
| 10 | Um_nik | 3396 |
→ Top contributors
| # | User | Contrib. |
|---|---|---|
| 1 | cry | 167 |
| 2 | Um_nik | 163 |
| 3 | maomao90 | 162 |
| 3 | atcoder_official | 162 |
| 5 | adamant | 159 |
| 6 | -is-this-fft- | 158 |
| 7 | awoo | 156 |
| 8 | TheScrasse | 154 |
| 9 | Dominater069 | 153 |
| 10 | nor | 152 |
→ Find user
→ Recent actions






Codeforces (c) Copyright 2010-2024 Mike Mirzayanov
The only programming contests Web 2.0 platform
Server time: Nov/25/2024 21:14:32 (h2).
Desktop version, switch to mobile version.
Supported by

I think the trick in this qualification was to submit something for all problems, and don't spend too much time optimising. Even if the answer was extremely sub-optimal, as long as it passed verification the score for each problem would be in 50-70 range, which would give a total between 250-350.
If all you're after is qualification to the final round, I'm pretty sure quite simple brute force approach for all tasks is enough — but it's important to do all of them, as a loss of even just guaranteed points (40% or so for most problems) is too big to be compensated by good scores in others.
Unfortunately, I don't see the problem statements (they seem to be removed from the website), so I'll tell what I remember:
Eurovision Song Contest (71.5/100) — this one was made by other team member, so no comment.
Network (75.6/100) — the first idea I thought of was the most successful here — just starting at a random house, then BFSing to the closest unvisited house, without even looking at costs (apart from obstacles). I tried treating fields with cost>threshold as obstacles or randomly taking the second-closest house instead (and taking best result of many iterations), but this was giving worse results.
Palm Tamagotchi (67.3/100) — given scores of other teams, I guess many of them used the same approach as we did — use only Grow commands, building the needed tree, then reset to time=0 and build the next one, until all trees are processed. That is, we completely ignored possibility of reverting to non-0 time and deleting some branches.
Puzzle (75.6/100) — greedy approach, that is: for all postions, try to fit every possible puzzle in any orientation. If impossible, go to next square and repeat. After going through the whole board, check whether the number of completed pieces is greater than best solution so far and if so, save this solution. Then repeat the whole process thousands of times after randomly shuffling the puzzles.
Firemen (72.1/100) — hill-climbing algorithm. First put fire stations at random places, then make thousands of iterations of loop, in which one of the fire station is moved in random direction (in the first iterations, by distance equal to half of the board size, then gradually decreasing to 1 step per iteration), then cost of current configuration is computed and compared with current best, saving current one as best if needed. The cost itself was computed using BFS from all stations at once in O(nm) every time. Likely it was possible to avoid so many calculations, but this worked nicely anyway.
I guess we could squeeze an extra ten or so points from the third task, as probably even a small improvement in score could throw us above teams using similar approach. But the contest was aleady ending, so we decided not to implement more ambitious solution, in order to have any solution at all. Turned out to be a good decision — leaderboard shows we're 28th, which, if 'm correct, places us in the finals.
Let's also discuss the rules: it is said that "20 to 30 teams with highest score in qualifying round that will be invited to participate in finals" so I wonder, is it 20 or 30 :)
Also, I wonder if I'm the only one who thinks that current scoring rules are weird. We didn't submit 3 tests in EUR and 3 tests in NET, and it turned out to be a very bad idea: random low-quality submissions on these tests scored 6-7 points, so this costed us more than 10 positions in the leaderboard (also I wonder how is it possible that all scores on these tests are above 6? Do I misunderstand the scoring rules?). As a random suggestion: maybe have a simple baseline (not public) for each problem, and submissions which score below the baseline get zero points?
As for the problems. Our approaches were as follows:
STR: greedy algorithm, choosing point at each step which minimizes target function on this step. Apparently this is suboptimal on many tests (especially the smaller ones), but is scored 9.9 on the largest test.
PUZ: brute force solves smaller tests, larger tests are (partially) solved by brute-force with cutoffs
PAL: greedy, on each turn pick the palm which can be obtained from one of the already generated palms in the smallest number of steps. This works really good, and I guess many other teams implemented smth similar (looking at scores)
NET: generate some sane permutation of houses, and then perform hill-climbing starting from the permulation. Use Dijkstra to obtain score for a given permutation (this probably was a bad idea, because it was really slow on big tests).
NET: We can merge the houses that form a connected component into a single vertex, it greatly reduces the runtime. There are at most 2000 such components in any of the tests.
Regarding to NET: In my team, both I and Marcin did it more or less independently and we both came with a trivial idea of picking a random start house and then take the nearest one according to Dijkstra. I also coded hill-climbing which tried to swap to houses in that permutation, but surprisingly that hill climbing improved my scores just by ~ 1% :/ (I expected rather something like 1/3 xd). I don't know why, but Marcin achieved a bit better results even though what I was doing was a superset of what he was doing.
So my main point of interest is that hill-climbing. Did it improved your results a lot? Maybe in my case it didn't help a lot, because that Dijkstra already created something almost optimal locally.
Btw to speed things up, I wasn't clearing visited in Dijkstra (I was visiting already visited fields, but I was overwriting old entries) and I was ending it as soon as I reach first new house, so it surely helped a lot.
Regarding to scoring: Have you seen formula for result of a submission? It's 10·(p + (1 - p)·(1 - log(m + 1) / log(n))2), where p is a guarantee points coefficient, n is number of teams and m is a number of teams which overperformed you. For p=0.4 (which was a case in few problems) and m~=n/2 (which is achievable by any feasible solution) it gives ~6 points :P. I analysed that formula yesterday and understood that first priority goal is to submit anything that grader accepts.
Oh, wow, n in this formula means the total number of teams, not just the number of teams with a valid submission? This doesn't make sense to me (intuitively), but this proves the value of reading rules before the actual contest :)
Regarding NET: getting initial permutation from Dijkstra is a good idea, we didn't do it. We just used Dijkstra to find a path given a permutation (so hill climbing substantially improved this solution). I guess with a proper initial permutation, there's little need in hill climbing.
EUR: 83 6 Just considering as a knapsack problem(just vote for itself), use gain/cost efficiency to greddily pick which country to vote. Looks very suboptimal but it's enough for a fairly acceptable score
Allow voting for any country with best efficiency -> 95+
Thanks for the contest! I was solving Firemen and Network and enjoyed both of them. One of the most exciting parts was how to write some reusable code for grid problems :)
I'd like to point at one thing: because of some teams with very long names (especially #COSANOSTRA#TEMANTURAL#ANONIMOWIBIAŁKOHOLICY#EATCLENTRENHARD — they had no spaces in the teamname) standings were a bit screwed and it was pretty annoying to scroll horizontally each time. I don't really know what to do with this issue. Maybe just limit the team name with, say, 30 characters, or display such long names like #COSANOSTRA#TEMAN....
Results of particular tasks were so wide that even without those long names it would be screwed. By the way, I wouldn't blame teams, rather organizers :P. It wasn't like that when I was preparing Marathon :D.
STR/Firemen (#1 place) — generate many random placements and choose the best one. Improve it in loop with climbing hill. Choose a random cell, find the nearest 2-5 stations and try to move them a bit many times. Chosen stations are close to each other so we can care about their surroundings only. Tests #7 and #10 were very dense (51% and 20% of cells can be stations) so I rewrote my program. There I generate one random placement and this time in loop I move only one station to its neighbor. It turned out to be great solution for those two tests and I had the best scores by huge gap.
And super-awesome-optimization for PAL — instead of resetting to time 0, we can grow two children from root first and later always reset to time 1. We can do it because in all trees a root has two children. It gave me 78.4 points.
Did you receive invitation email for qualification round?
Do you need personal invitation for qualification round :P? Even though we were first team to fully register, they have sent me 4 e-mails that only x days remained till the end of registration, I suppose those were good reminders :P.
No, I don't need. But it would be good if they sent reminder letter day before, like Codeforces.
I'll write something about PAL (as I had pretty decent scores on this task).
First of all, we don't want to revert back to beginning when getting between two sought configs. In fact, if we have two trees Ta, Tb of sizes a and b, there's a standard dynamic quadratic-time programming solution which computes the size of their largest common rooted subtree (let call this subtree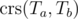 ).
).
OK, so now we would like to describe the whole process as a rooted tree in the space X of binary rooted trees (that is: 'vertices' are binary trees and vertex c can be a child of p if Tc is a subtree of Tp). Let's order trees from input in any way we like: T1, ..., Tn. Then we take any two consecutive trees Tp, Tp + 1, find their common subtree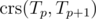 and insert it instead of them. Continuing the process, we finally arrive at one subtree. Reverting the whole process, we construct a rooted binary tree in X whose leaves are the sought trees. Whole construction uses only growth potion and well-chosen time reversals.
and insert it instead of them. Continuing the process, we finally arrive at one subtree. Reverting the whole process, we construct a rooted binary tree in X whose leaves are the sought trees. Whole construction uses only growth potion and well-chosen time reversals.
Now the whole thing is probably better than many solutions (it's now better than "construct a tree, delete it, construct next tree, ..."). But there is still some room for improvements. I used a O(n3) dynamic-programming algorithm for finding a good order of joining the trees (its idea is almost identical to finding optimal matrix multiplication order). Moreover, I used some hill-climbing over the permutation of trees in the input. Both improvements probably gave me a comfortable win on inputs 7-10.
Also a note on PUZ: some people (including me) may have known the puzzle as Eternity II. Input puz07 has the same dimensions as original puzzle. Can someone prove/disprove it's the same instance of problem? :P
Tutorial: How to win Marathon24 qualifications?
Answer: Just convince mnbvmar to be in your team.