


This blog post is motivated by an interesting problem I solved today: Timus 1846. I knew about segment trees previously for solving range-minimum query, but was not fully aware of the obvious generalizations of this nice data structure. Here I will describe the basics of a segment tree and some applications.
Problem
The problem that a segment tree can solve is the following. We are given an array of values a[0], a[1], ..., a[N - 1]. Assume without loss of generality that N = 2n; we can generally pad the computations accordingly. Also, consider some associative binary function f. Examples of f include sum, min, max, or gcd (as in the Timus problem). Segment trees allow for each of the following two operations on O(logN) time:
- compute f(a[i], a[i + 1], ..., a[j]) for i ≤ j; and
- update a[x] = v.
Description
So how does a segment tree work? It's quite simple, in fact. We build a single two-dimensional array t[0...N - 1][0..n] where t[x][y] = f(a[x], a[x + 1], ..., a[x + 2y - 1]) where x is divisible by 2y (i.e. most of the entries are ignored, but it is easiest to represent this way). We can initialize the entries by the following procedure:
- t[x][0] = a[x]; and
- t[x][y] = f(t[x][y - 1], t[x + 2y - 1][y - 1]) for y = 1, ..., n,
where the second step uses the associative property of f. The logic is that t[x][y - 1] computes f over the range [x, x + 2y - 1) and t[x + 2y - 1][y - 1] computes f over the range [x + 2y - 1, x + 2y) so when we combine them we get the corresponding computation of f for t[x][y]. Now we can describe how each of the two operations is implemented (at a high level).
We'll start with computing f(a[i], a[i + 1], ..., a[j]). It's pretty easy to see that this amounts to representing the interval [i, j] as disjoint intervals [i1, j1];[i2, j2];...;[ik, jk] where each of these is of the form [x, x + 2y - 1] where x is divisible by 2y (i.e. it shows up in the table t somewhere). Then we can just combine them with f (again using the associative property) to get the result. It is easy to show that k = O(logN) as well.
Now for updating a[x] = v, notice that there are only a few terms in the segment tree which get affected by this change. Obviously, t[x][0] = v. Also, for y = 1, ..., n, only the entry t[x - (x&(2y - 1))][y] will update. This is because x - (x&(2y - 1)) is the only value divisible by 2y (notice the last y bits are zero) that also covers x at level y. Then it suffices to use the same formula as in the initialization to recompute this entry in the tree.
Code
Here's a somewhat crude implementation of a segment tree. Note that the value of IDENTITY should be such that f(IDENTITY, x) = x, e.g. 0 for sum, + ∞ for min, - ∞ for max, and 0 for gcd.
void init() {
for (int x = 0; x < N; x++)
t[x][0] = a[x];
for (int y = 1; y <= n; y++)
for (int x = 0; x < N; x+=(1<<y))
t[x][y] = f(t[x][y-1], t[x+(1<<(y-1))][y-1]);
}
void set(int x, int v) {
t[x][0] = a[x] = v;
for (int y = 1; y <= n; y++) {
int xx = x-(x&((1<<y)-1));
t[xx][y] = f(t[xx][y-1], t[xx+(1<<(y-1))][y-1]);
}
}
int get(int i, int j) {
int res = IDENTITY, h = 0; j++;
while (i+(1<<h) <= j) {
while ((i&((1<<(h+1))-1)) == 0 && i+(1<<(h+1)) <= j) h++;
res = f(res, t[i][h]);
i += (1<<h);
}
while (i < j) {
while (i+(1<<h) > j) h--;
res = f(res, t[i][h]);
i += (1<<h);
}
return res;
}Application
One possible application is letting f just be the sum of all arguments. This leads to a data structure that allows you to compute sums of ranges and do updates, but is slightly less efficient than a Binary Indexed Tree. The most well-known application seems to be the range-minimum query problem, where f is the minimum of all arguments. This also allows you to compute the least-common ancestor of nodes in a tree.
Lastly, in Timus 1846, we can use it with f as the GCD function. Every time we remove a number we should update the corresponding entry to zero (effectively removing it from the GCD computation). Then the answer at each step is f(a[0], a[1], ..., a[k]) which can be computed directly from the segment tree.







Yes, you are right. But I think it is easier to think about it as a 2-dimensional array and only use the 1-dimensional compression when you have to.
"But I think it is easier to think about it as a 2-dimensional array and only use the 1-dimensional compression when you have to."
If you are doing zkw segment tree anyways might was well do it in O(n) memory, as opposed to this (arguably more intuitive) O(n^2).
Building an O(n^2) segment tree is very expensive, your implementation took O(n^2) just to build the tree. Sparse table can be built in the same speed and compute rmq in O(1), as opposed to O(logn).
The only advantage this 2D segment tree still has over the sparse table is O(logn) updates, but many problems where segment tree is useful probably won't allow huge O(n^2) preprocessing anyways.
1D Array Segment Tree: http://mirror.codeforces.com/blog/entry/18051
Sparse Table for RMQ: https://www.geeksforgeeks.org/range-minimum-query-for-static-array/
Clarification: zkw segment tree is iterative segtree
you actually need 2*2^(log(N)+1) for memory, don't you? It contains O(N) leaves, not nodes. But our colors suggest i'm wrong and you're right, can you share your prof?
2 * 2 ^ (log(N) + 1) = 4 * N = O(N)
I don't really say they are equal. Please read this.
BTW, it can be easily extended to 2D or 3D arrays, but in this case it takes (2 * n)^k memory, where k is 1, 2, 3 for 1d, 2d, 3d, ...
upd
@Alias I would like to know how to update and query in 2d segment tree??
there is two ways. look at implementation.
Who can help me with practice problems on 2d-, persistent and compressed segment tree? I appreciate links to OJ problems.
Must be okay with you. :)
Lazy means "Update value only when you need it" .
That is you keep a flag at the "parent node" , and update the children only when you encounter them while querying.
Could you please give me an idea of how to implement a 2d-segment tree?. For example, to solve the problem 11297 — Census. Thanks in advance.
The idea behind 2D segment tree is that you first build segment tree for every row, then you build segment tree for every column. Its easier to operate with NxM array if N and M are degrees of 2, if not, you can fill the array with 0s, but if memory is more important, you can do without it. For example, you have the following 4x4 array:
1 2 3 4
4 3 2 1
5 6 7 8
8 7 6 5
Build a segment tree for every row. It will look like this:
10 3 7 1 2 3 4
10 7 3 4 3 2 1
26 11 15 5 6 7 8
26 15 11 8 7 6 5
(the first element of the row is the sum of elements (1...n), the second is the sum of (1...n/2), the third is the sum of (n/2+1...n) ...
Then build a segment tree for every column of the above matrix in the same way:
72 36 36 18 18 18 18
20 10 10 5 5 5 5
52 26 26 13 13 13 13
10 3 7 1 2 3 4
10 7 3 4 3 2 1
26 11 15 5 6 7 8
26 15 11 8 7 6 5
The tree contains 2N-1 rows and 2M-1 columns, and our initial matrix starts with element (N,M)
If you want to update element (x,y), you update it, then all its parents in its column ((x,y/2),(x,y/4),...(x,1)), then divide x by 2, and do the same thing while x>0.
For finding the sum of the rectangle with opposite vertices (R1,C1) (R2,C2) (where R1<R2 and C1<C2) recursively, start from the first row(of the tree), If the range of the row R has no intersection with (R1...R2) then return 0, if the range is not completely into (R1...R2) but has an intersection, then call the function for its children ((R*2) and (R*2+1)). Finally, if the range is completely into (R1...R2) we do the same thing with the tree in the Rth row, but this time we return tree[R][C] if the range of the Cth element of the Rth row is completely into (C1...C2).
The complexity of queries is log(N)*log(M).
Very nice explanation, thank you.
here is a tutorial about 2D segment tree. Link
You might need google translate if you are not Russian. :)
Do you know about other problems where segment trees should be used with some other associative binary functions?
You could solve these:
http://coj.uci.cu/24h/problem.xhtml?abb=2125
http://mirror.codeforces.com/problemset/problem/339/
Thanks for your reply. I already solved the first one long time ago, and as I remember it was not about using some associative operation, but storing the progression terms in the nodes with lazy propagation. As for the second one, the link points to nowhere.
this one is more interesting: http://coj.uci.cu/24h/problem.xhtml?abb=2511
this one its only a sum: http://coj.uci.cu/24h/problem.xhtml?abb=1850
this is only a sum but it's in 2D: http://coj.uci.cu/24h/problem.xhtml?abb=1904
and for the Interval Product problem, you dont need lazy propagation, but you need it for this one: http://www.spoj.com/problems/HORRIBLE/
Links to coj.uci.cu problems actually uses pid instead of abb.
I wrote that long time ago, today the links are broken.
We can generalize that a bit more: Let (M, f) be a semigroup (that is, a set M together with an associative binary operator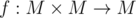 ).
).
Let (T, c) be a monoid with identity element tid and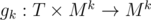 a family of transformation functions (range updates), that take as their arguments a parameter
a family of transformation functions (range updates), that take as their arguments a parameter 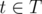 and a sequence
and a sequence 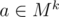 and output a sequence
and output a sequence 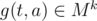 of the same length. gk should respect the monoid structure of t, i.e. for
of the same length. gk should respect the monoid structure of t, i.e. for 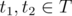 , gk(c(t1, t2), ·) should be equivalent to the composition
, gk(c(t1, t2), ·) should be equivalent to the composition  and gk(tid, ·) should be the identity function. Intuitively, this allows us to compress a series of updates into one single update.
and gk(tid, ·) should be the identity function. Intuitively, this allows us to compress a series of updates into one single update.
Let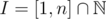 be the set of integers between 1 and n.
be the set of integers between 1 and n.
A segment tree is able to maintain a dynamic sequence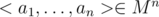 . It allows the following operations:
. It allows the following operations:
It is able to do so in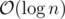 time per operation if the following conditions are met:
time per operation if the following conditions are met:
The implementation works by assigning nodes to ranges in a binary tree-like fashion and storing f(al, ..., ar) and a lazy update t inside the node responsible for the range [l, r].
The tree can be implemented without any further knowledge about the internal structure. It just needs implementations of f, c, h and it needs to know tid.
This characterization is general enough to directly allow a scenario like:
Here the values in M are tuples (min, max, sum, length) and the values in T are tuples (action_type, v). The functions f (combine range data), c (combine updates) and h (apply update to range data) look like this (in pseudo-Haskell pattern matching syntax):
We also need to supply tid = (add, 0).
For problems like http://www.spoj.com/problems/SEGSQRSS/ or http://www.spoj.com/problems/GSS3/ we need to get a bit more creative and store additional values in the M tuples that are not actually needed to answer queries directly, but to implement the function h efficiently.
Correct me if I'm wrong, but an
O(nlogn)is getting TLE on the problem you stated initially. Here is the problem: Timus 1846Unfortunately, I can't provide a link to my solution since the solutions are private. But I'd be very happy to hear a solution using Segment tree since any segment tree must use
O(nlogn). Correct me if i am wrong again!Thanks in advance
My solution is O(n*log n) using Segment tree and gets AC in 0.39 execution time (in Java).
I think this should be named "sparse table with updates". Thanks for your effort anyway!