


Hello!
Let us remind you that Russian Code Cup 2016 Elimination Round will take place on June 19, 2016 at 14-00 Moscow time. Top 200 from each qualification round can take part in Elimination round, 200 best coders in Elimination round will get branded championship t-shirt, and top 50 will advance to the Final Round that will take place in September. There are money prizes to grab in the Final Round.
Good luck everyone and see you at http://russiancodecup.ru !






I'm wondering what does "Register at http://russiancodecup.ru and participate!" mean in the invitation email?
Maybe they meant "log in" :v
How to solve B? i got WA several times with ternary search.
sort according to non-decreasing L[i] , now if u set number of left legs to L[i] , the number of valid pairs will be number of R[j] ≤ N - L[i] where 1 ≤ j ≤ i , so do coordinate compression and apply a BIT.
A priority queue would do too. Always pop the queue whenever Rtop > N - L[i] because it will never be valid again as N - L[i] is non-increasing. The answer for taking L[i] as the number of left legs equals the size of the queue after popping invalid items.
P.S. Hey fellow doge!! LOL
I sorted the sequences increasing with respect to L.
After that, I iterate in that sequence, let's say at step i we have Li as the left number:
How to solve E???
For each i, compute two values:
This will lead to an O(nlog2n) solution. However I'm not sure if this is intended (sparse table got MLE, segment tree got TLE, segment tree + pruning passes).
There are absolutely no complex DS involved, at least in my solution.
First, think about why it's enough to iterate "x -> 1 + sum of numbers up to x" for a given range until the sum is smaller than x. It's fast enough, since as we're iterating, x strictly increases and so the sum increases quite quickly.
We can find sums in a given range using a Fenwick tree. We'll process numbers in non-decreasing order, add them to the Fenwick tree and deal with iterations in all queries at the same time.
When we've just processed all numbers ≤ x for some query's current x, we can find the sum for its next iteration, check if it's time to stop and if not, move on to the next iteration there. The current iterations for all queries can be stored in a set / priority queue / etc., from which we can take the smallest ones as long as they're less than the currently processed number. Time complexity: unknown, but it passed without any optimisations.
UPD: Downvote logic on CF again. If I'm wrong, why not comment?
You are actually right, it is N log N log K, where K=10^9. Each query will be processed log K times max, and they are in the priority queue.
i used persistent segtree to get sum from L to R with values from x to y. It passes with coordinate compression.
So how to solve E?
I tried complicated O(n * sqrt(n) * log(n)) solution and got TLE on test 27.
One pitfall is that Segment Tree is too slow here :( But Fenwick tree passes.
That can be done online with persistent segment tree code
It looks like you uploaded a wrong code. It doesn't work on the sample, there shoud be inequalities on line 188.
EDIT: OK, the bug is not here, now I don't know how to fix it.
Yes, my fault. There should be += instead of = in line 249. I thought no one run the code which is posted as example:)
I love this piece of your code:
typedef int itn;:DI was sad that I spent the whole contest trying to get D accepted, when I saw tourist and Petr failed it too, I'm completely fine with it now :P
Edit: Same code passes in the Gym in 300 ms, what was up with the time limit for this one?
201st. Nice.
For B,If there are multiple solutions, output any of them? Why did I always get WA on test2...
Are both your numbers larger than 1?
Duh, how is that so many people solved E and some even in 7 minutes :f? I managed to get it ACed, but I think my idea is not that straghtforward. I divided numbers from input into intervals [2k, 2k + 1) and for every such part I built a segment tree taking minimum on interval and prefix sums. Then I did this:
But it still needed a bit of stupid optimizing since I got TLE.
Is that a case that many people had prewritten some structure like "what is sum of numbers on interval [l, r] not larger than x?"
Not the first time most important problem of RCC elimination round is from some other contest. Copy-pasting doesn't take that much time.
I spent about 10 minutes. Copy-paste of Fenwick tree (+2 minutes) and fast input-output.
Well known greedy
We see 2D-queries
To solve the problem in offline sort queries and use Fenwick tree. Implementation is short, 25-30 lines of not copy-pasted code
P.S. Some people said the problem was on CodeChef contest. For me it was a new one.
The problem E is the same as this problem (editorial).
One more resource with problem E: http://cs.stackexchange.com/questions/19651/minimum-number-that-cannot-be-formed-by-any-subset-of-an-array
And that's why I was shocked that someone got AC in 15-th minute of competition :)
How to solve problem D??
Greedy algorithm. First fill all containers to minimum volume. Then, start filling the containers to maximum volume in the order of increasing pi. When filling a container to volume v, reserve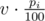 of reagent ci and
of reagent ci and 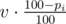 of any reagent (you need to track the total volume of unreserved reagents).
of any reagent (you need to track the total volume of unreserved reagents).
Do you have some ideas why this has enough precision (I'm asking partly because my extremely similar solution failed because of a precision issue)?
It looks like you're operating with numbers as large as 1e10, then the error we get on each operation there is around 1e-6, so it seems unexpected that we can get an answer that's checked with tolerance 1e-6 and pass?
In the first part of my program (when the containers are filled to minimum volume), both
sumvandsumcapare integers, so there is no rounding errors here. In the second part (when the containers are filled greedily),sumvis an integer until the very end. In the last part (when the answer is generated), there are no values as large as 1010. So, the only interesting place is the second comparison betweensumvandsumcap. Well, it works for some reason, quite possibly because of weak tests. In my submission,EPSis1e-9, but it was mostly a guess.Thanks — keeping everything in integers as long as possible is pretty clever! Although as you point out, it doesn't seem to help for the worst possible case.
I've looked at both reference solutions, and they use eps liberally here and there, so maybe the contest authors know why there is no big precision loss here?
In my solution, I've used the same trick with multiplying certain numbers by 100 to avoid imprecision there, but switched from integers to doubles slightly earlier, and maybe have a less lucky eps.
Yeah, it looks like this problem is unsolvable without BigIntegers. Here's a testcase where we can actually pour out all liquid except 100/lcm(1,2,3,..,100) which is about 1.5e-39. So the correct answer is NO, while I expect all passing solutions to output YES.
I hope one day people finally understand that problems with yes/no answers and double are bullshit
Well, they are not bullshit, if say in statement something like "if change all parametrs within blablabla, answer will not change". But probably it can be hard to validate.
Well, it's almost always hard to validate and/or create adequate tests (i.e there should be tests where params within 2*blahblah and that may break smth) and/or nobody cares
If that's done, I agree that's OK
not the first time.... and this passed sample and wa at test 4...
Same me, "cout<<-1<"\n" bring me out of top 200.
The contest in GYM: 2016 Russian Code Cup (RCC 16), отборочный раунд. Welcome to practice!
Thanks for organizers and jury. I liked it!
Will participants not in Russia still receive shirts if we came top 200? I'm just curious as it wasn't clear on the website.
still nobody answer