


The Codeforces Marathon Round 1 is over (results comment). As the final solutions are being tested, I think many participants will want to share ideas and learn alternative approaches. I'll start with the ideas I tried myself, both successful and not; as I've seen in the submissions, the contestants have more ideas, but I hope they will share themselves. For each of the solutions below, the numbers in square brackets are minimum, mean and maximum score when running on 1000 tests locally. I have to note in advance that the constants and technicalities in the solutions are not considered optimal: the score just shows approximate relation between ideas and may often be improved a bit. -----
Solution 1 [4099 4159.699 4288]: random.
Just print 5000 random bits 100 times.
Solution 2 [4160 4226.294 4365]: last bit memorization.
The last checked bit is always wrong. For example, if the answer for an attempt is the number 4050, it means that the error number 2000 happened exactly on position 4050 of our string. Let us fix the right value of this bit. When subsequent random strings are generated, all fixed bits have their known values, and other bits are generated randomly.
Solution 3 [4182 4291.374 4453]: find several bits.
This is a two-part solution. In the first part (90 attempts) the attempts go in 45 pairs. The first attempt of pair i is generated randomly (except for the fixed bits which we already know). The second attempt of pair i differs just in i-th bit and in the last checked bit.
What information can we learn from such a pair? For example, let the first attempt give the result 3980, and the second one (with bits 1 and 3980 changed) resulted in 3975. This means that, firstly, bit 1 was right in the first attempt (because it got further). Secondly, error 2000 of the second attempt is error 1999 of the first one, so between bits 3975 and 3980, there are no errors.
Similarly, if the result of the second attempt is greater, for example, 3981, we know that bit 1 was right in the second attempt, and also that there are no errors between 3980 and 3981 (this time, it does not help because there are no bits either).
For a pair of attempts, we find the exact values of three bits on average.
In the second part of the solution (the remaining 10 attempts), let us just generate random strings except that we take fixed bits into account. There are 135 fixed bits on average, and one more after every attempt.
Solution 4 [4260 4369.927 4498]: find several bits symmetrically.
This is a two-part solution. In the first part (90 attempts), the first attempt is random, and each subsequent (i-th) attempt takes the previous one and inverts bit i and the last checked bit. As in solution 3, observing the change in answer, we can not only find the true value of bit i for future use, but also find two bits on average around 4000. However, now we find three bits in each attempt, not in each pair. Note that we can't put the right values of the first 89 bits right away, so the bits we learn at the end are more symmetrically distributed around 4000.
In the second part of the solution (the remaining 10 attempts), let us just generate random strings except that we take fixed bits into account. There are 267 fixed bits on average, and one more after every attempt.
That's it for my solutions which find some particular bits. Looking at the preliminary scoreboard, we can conclude that more than half of the participants invented something better. The useful heuristic to take to other solutions is to always memorize that the last checked bit is wrong.
Solution 5 [4429 4533.129 4671]: segment inversion.
Split our 5000 bits into segments of length, say, 45. For the first attempt, generate a random string, and in each subsequent attempt, invert the next segment. After inverting, we compare two numbers and know for sure which version was better: inverted or non-inverted; choose the best of the two and proceed to next attempt.
Why does this work at all? Intuitively, the average deviation on a segment is large enough, so there will be enough segments for which inversion changes the answer much: for example, if a segment contained 19 right bits out of 45, after inverting, there will be 26 of them. If, on the contrary, we transformed 26 into 19 — return the 26 (and the previous result, too) by inverting back.
The constant 45 is a rough estimate; it seems that many participants chose 40 in similar-looking solutions.
Solution 6 [4399 4582.368 4723]: segment inversion with recycling.
Put the 4000 first bit positions in the "present" pool, and the remaining 1000 positions in the "future" pool. For the first attempt, take 79 random bits from the "present" pool and invert them all. If the result changed by more than 10, it means that the inverted "segment" has a large enough deviation. Let's use it: fix all these 79 bits in the better of the two states (either leave every bit as it is, or invert every bit). Otherwise, let's also put the bits into the better of two states, but instead of fixing the bits, put them into the "future" pool.
When the "present" pool is empty, look at the "future" pool, move all bits visited at least once (bit 4999 is most likely not visited) to the new "present" pool and continue.
As we now reuse bits which don't give us much profit when fixed, we can take longer "segments": their length is 79 instead of 45 in solution 5. This means that the average deviation in a "segment" also increased.
The constants 79 and 10 were chosen by a small search.
Solution 7 [4539 4702.079 4878]: segment inversion with recycling and memorizing.
Do everything as in solution 6, but recall the idea from the previous line of solutions: the last checked bit is always wrong. The profit from this idea has almost no dependence on large segment inversion.
In this version, it made sense to make the segment even longer: the constants 79 and 10 changed to 99 and 18.
These were solutions with segment inversion. The best of them achieves the rank of 20-30 in the preliminary scoreboard. The weak sides are that we change only a small portion of the string, and as a result get only few bits of information on average. Additionally, we fix the whole good segment forever. Which of these can be improved and how is a story for some of the top performers to tell.
Solution 8 [4251 4403.645 4594]: discrete probabilistic in each position.
Let us make 99 random attempts. In each of the 5000 positions, memorize the probable bits. For each attempt with result at least 4000, mark its bits up to the last checked one as probable in their positions. For each attempt with result less than 4000, invert it and mark inverted bits up to the last checked one as probable.
In the last attempt, for each position, choose the option which was marked more times as probable.
Solution 9 [4433 4601.678 4773]: discrete probabilistic in each position with memorizing.
Let us try to improve the previous solution.
First, recall that the last checked bit is always wrong, and fix all such bits.
Second, learn to use not only the sign of the result (trivially: is it less than 4000), but also the magnitude. For example, if 2000 errors are somehow distributed among 4001 bits, it is less informative than 2000 errors distributed among 4100 bits.
Taking fixed bits into account, we can translate each attempt into a piece of information of the form "there are 1999 errors in t bits". In each of these t bits, record that the probability of it being right is 1999 / t. In the end, just take an average of all such records.
In the last attempt, for each position, choose the option which turned out to be more probable.
Around one third of the contestants implemented something better than the described solutions which calculate probabilities separately in every position.
The next idea is full inversion. Let us use attempts in pairs, and the second attempt of each pair be full bitwise inversion of the first. Each such pair of attempts gives information in the form "in the segment from lo to hi, there are exactly err errors". Indeed, let the first attempt of a pair give result 4015, and the second 3980. In total, there are 4000 errors in the segments [1, 3980] and [1, 4015]. Moreover, there are exactly 3980 errors in total from 1 to 3980: each bit was once in each of the two possible states. So, there are exactly 20 errors from bit 3981 to bit 4015.
We can now perform different operations with these segments: intersect them, search for a string conforming to all gathered information, if it is too hard to find, search for the most conforming string. My solutions with such segments get mean results between 4400 and 4500, but are already technically involved. Sure one can do better.
A bit of problem history. Initially, it was designed as a hard probabilistic problem for a contest with ACM ICPC rules. The plan was to try several approaches and see if the simple and weak ones can be separated from thoughtful and strong by choosing the appropriate constraints. However, the first few solution ideas refused to line up in an order resembling their complexity, so I had to put the problem on hold. On the other side, this problem fits well in a contest with partial scoring since there are a few quite different approaches which are easy enough to invent and implement.
Last but not least, I owe my thanks to Natalya Ginzburg (naagi), Andrei Lopatin (KOTEHOK) and Mike Mirzayanov (MikeMirzayanov) for their help in preparing and running the contest.







So, I'd like to share my approach (1st place before systests so far).
The first thing to do for me was to implement evaluator. Input strings are random (there are no patterns in tests to my knowledge), so the scores are fully reproducible locally. So I don't get why many of participants (even in top-10) have lots of submits with scores going up/down randomly — am I missing something?
I tried to estimate the best possible score from information counting reasoning. Assuming we're getting responses in range 0-5k, it is 12-13 bits per response, 1200-1300 bits for the whole session, which seems enough (we need to get 1k bits of information to win). However, any sane approach I could think of would be getting responses in range 4k-5k, so it is less than 10 bits per response, so this is really tight. With this reasoning, I was surprised to see such high scores in scoreboard, but nevertheless decided to try to solve the problem.
My first idea wase to try some greedy/hill climbing approaches. Unfortunately local evaluation was showing scores around 300. Maybe with some careful tuning it can produce better results, but I didn't want to spend my time on tuning. So I decided to abandon this direction and use my brain instead.
The direction of thinking was as follows: suppose we have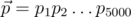 — a vector of probabilities of each bit being 1 (for convenience let's denote
— a vector of probabilities of each bit being 1 (for convenience let's denote 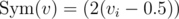 ). We can use these probabilities to sample queries somehow, and then update them somehow. How to estimate these probabilities? I tried to do it fairly, but failed: if queries depend on each other, it is too much pain. Instead I looked at it from a different angle. If we have query s1... s5000 and response l, it means that
). We can use these probabilities to sample queries somehow, and then update them somehow. How to estimate these probabilities? I tried to do it fairly, but failed: if queries depend on each other, it is too much pain. Instead I looked at it from a different angle. If we have query s1... s5000 and response l, it means that 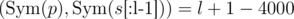 and
and 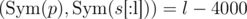 ((x, y) are dot products, s[:l] is truncated vector — python-style notation). So for q queries we have 2q linear equations which represent a hyperplane in 5000-dimensional space. We're interested in points within the cube [ - 1, 1]5000. Unfortunately, there can be plenty of such points. How to pick one? Intuitive assumption is that if we're treating all bits equally (which might be untrue due to the nature of the problem), we need some way which is symmetric over coordinates. So, I tried to just pick projection of
((x, y) are dot products, s[:l] is truncated vector — python-style notation). So for q queries we have 2q linear equations which represent a hyperplane in 5000-dimensional space. We're interested in points within the cube [ - 1, 1]5000. Unfortunately, there can be plenty of such points. How to pick one? Intuitive assumption is that if we're treating all bits equally (which might be untrue due to the nature of the problem), we need some way which is symmetric over coordinates. So, I tried to just pick projection of 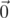 on this hyperplane — it is symmetric and intuitively seems reasonable. (note: maintaining this projection can be done by smth similar to Gram-Schmidt orthogonalization and is expensive resource-wise; I didn't see many solutions with high working time on status page, so probably I was the only one doing this)
on this hyperplane — it is symmetric and intuitively seems reasonable. (note: maintaining this projection can be done by smth similar to Gram-Schmidt orthogonalization and is expensive resource-wise; I didn't see many solutions with high working time on status page, so probably I was the only one doing this)
We get some estimation of probabilities of 0/1 on each position, but what to do with it? Natural idea is to sample queries based on these probabilities, but it doesn't work very well: the probabilities are too close to 0.5. I tried to address this by multiplying the probabilities by a constant in logodds space (i.e.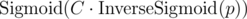 ). This worked quite well: with constant C = 20 I got around 772 avg score on 1000 tests, and submitted this (getting 77571 on pretests).
). This worked quite well: with constant C = 20 I got around 772 avg score on 1000 tests, and submitted this (getting 77571 on pretests).
Then, in the last hour of the contest, many participants started submitting solutions which were rather close to mine on pretests. And since the variance is rather high, it was possible that they're actually better than me, so I had to submit an ugly hack to get a better score. (As a matter of fact, I had this ugly hack prepared for a while, but didn't want to submit it because it is ugly). Once can guess that multiplying probabilities by 20 in logodds space is likely suboptimal. Instead we can introduce a (piecewise-linear) curve, and try to move its points and see if target score increases. This is tricky because the target score is random. I used fixed randseeds for tests and for sampling inside solution, and 1000 iterations to compute average score. Maybe it would work even better if we don't fix seeds and do smth similar to stochastic gradiend descent, but with 1k iterations computational resources are bottleneck. Nevertheless, such tuning gives ~+10 points (so avg score is ~780), and the solution with the ugly tuned curve gets 78465 points on pretests.
Looking at the scoreboard, there are plenty of solutions close to mine, which probably use different (greedy?) approaches. I really would like to know how do they work — are there any beautiful greedy ideas, or just hardcore tuning?
Thank you for sharing!
I like the vector interpretation, and how it helps to see and express the idea of orthogonalization.
Regarding information quantity, I'd like to note two points.
On one hand, we actually get ≈ 8.03 bits of Shannon information per query if we just calculate it by definition, so if we intend to learn some specific 1000 bits, we have only ≈ 803, so it won't be enough.
On the other hand, we don't want any fixed positions, any ≈ 1000 positions will do. Formally, of all 25000 possible bit strings, we would be satisfied with any one with 0 to 1999 errors. That's C[5000][0] + C[5000][1] + ... + C[5000][1999] ≈ 24849, so for some ideal way of classification, just 151 bit of information could be enough. Of course no one submitted such a solution, and getting any close to such ideal classification with reasonable complexity is perhaps impossible.
Yet another dumb solution:
Take 10 generation of 10 such requests: sort results of previous generation, merge first result with some others (I tried to merge with probabilities of the same ratio as first result to second in pair. Though this idea wasn't really successful and I stayed with equal probabilities), second with some and first with random string. First 10 are random strings, of course.
It's about 350 per test if you choose constants and params of merge wisely.
All in all, it was pretty interesting competition but random was too significant(?). I couldn't get proper strategy to improve results, just tried lots of random stupid ideas some of which all of a sudden brought me satisfying result.
Still I hope that these competitions will become regular on codeforces!
I wasn't able to get more than 510 per test in average with this solution, it's pretty simple anyway.
Divide given string into parts (I've chosen 25 parts of 200 bits each), try random substring on part several times (for 25 it was 100 / 25 = 4) and select best of these. And save wrong answers every time.
One minor improvement to Solution 7 is to do segment inversion with segments of variable size, the size of which depend on the amount of bits at the present pool at your disposal. The present pool is updated at each query with the new bits visited. This amounted to a tiny improvement with respect to fixed size.
Please! Look the status!
I want to share my easy solution. It's very short. It's 68000-70000. 18629511
Seems that CF contest rating is irrelevant on maraton contest. Look the color mixed on scoreboard.
People who have more free time have the advantage even if their skills are equal. It's what happens when a contest lasts for several days. I don't have a lot of free time, so I don't see a point to take part in such long marathons at all.
However, if the duration was 4-5 hours, I'd participate. The results would be far more relevant, and it's surely more fun — to write something working in deadline conditions. So, how about holding such contest?
During 4-5 hours it is impossible to generate and test many ideas. So it will be too random competition about how lucky you are in your first guess. Actually our team spent about 10 hours in total (and last three hours were useless), but may be we were lucky and it could take more time.
The problems for short marathons could be simplier. And after 20-30 contests any randomness will disappear, just like in Codeforces Rounds.
Take
MarathonDeadline24, for example — they have 2 marathon-style problems for 5 hours in the qualification round, just as I suggest, as one person usually codes one problem there. Nobody complains and everyone is happy with it.In codeforces rounds there is a lot of randomness =)
I am not sure, that there will be enough problemsetters for 20-30 well designed problems for 5 hours.
At last Marathon24 they have 5 marathon-style problems for 5 hours. And it was huge random. But it was ok because for top teams it was easy to get into top-30 and qualify.
May be you are talking about Deadline24. It was even more huge random, because they gave problem very similar to past problem from TCO Maraphon. Everybody who participated (for example I) got huge advantage.
Why do you say there's a lot of randomness in Codeforces rounds? What make Codeforces rounds different from another competitions. Or do you mean there's a lot randomness in competitive programming contests in general?
Variance is inversely proportional to the duration of the contest. Acm-style team contests are less random at least due to bigger duration.
There are already a lot of contests that have 4-5 hours duration. It's pretty cool to have something different. Your idea sounds interesting as well, but it's nice to have more marathons that last for 10 days, where you can solve 1 problem without being stressed out by tight contest duration restrictions. I enjoyed this marathon so much, so props to authors and I hope to see more of that stuff in future + maybe separate ranking for marathons.
I mean 4-5 hours marathon contests. How many of them do you know? I know only Marathon24 / Deadline24 qualification.
I understand that. I don't know about 5 hour marathons. What I wanted to say is that format when you have to stay concentrated on solving problems for 5 hours is very common, but I personally prefer much longer duration and more chill process. Anyway, it would be nice to have 5-hour marathons here as well and compare (5 hours vs 10 days) community feedback.
There is also first day of Wide Siberian Olympiad. It is an onsite contest though, and the problem is in Russian only.
Google Hash Code
Any info on the T-shirt winners?
Marathon still have no status "ended". I think something will be changed.
The results are final. Congratulations to the winners!
778886) ilyakor774606) savsmail772473) hakomo770837) Nicolas16759469) MrDindows744666) aimtech: zeliboba, yarrr740863) PalmPTSJ739006) HellKitsune728997) IPhO728961) haminhngocThe program used to generate random T-shirt winners: code on IdeOne.
(16) Andromeda Express: ainu7, Astein
(55) Mediocrity
(85) quailty
(97) Kniaz
(101) waterside
(134) SteelRaven
(158) khadaev
(182) Thr__Fir_s
(184) Simon
(188) GoogleBot
Also, thanks to everyone participating! Good to see that people are interested.
Cool contest!
Omg! Omg! How lucky =D
Was the seed
12345somewhere in the contest announcement?Or was it chosen arbitrarily after the contest?
Next time if you forgot to mention the method of drawing you can use a seed from the future from random.org.
No, but seed
12345appears in example solutions, which somewhat reduces the arbitrariness.Do you mean random.org provides random numbers which can be requested in advance but become available only after specific point in time? I don't see such option.
Other than that, yeah, it's better when the exact way of generating the random sequence is announced in advance but still cannot be abused. Sorry it didn't happen this time.
https://www.random.org/sequences/?mode=advanced
Use pregenerated randomization from (date)
Determine the earliest date that is NOT available yet (currently it is 2016-06-24). Announce this date to the participants. Then tomorrow go back to random.org to make the draw.
Or similarly you can just generate one seed integer using https://www.random.org/integers/?mode=advanced but then you also need to announce the min and max.
Something like this, for a date after contest end? Got it, that's neat, thanks for showing!
Min (11) and max (201) can be determined by Update 2 in the original post, once the results are final.
I haven't seen the problem statement. Can someone post a link?
Sure.