


Tutorial is loading...
Tutorial is loading...
Tutorial is loading...
Tutorial is loading...
Tutorial is loading...
Tutorial is loading...
Скоро...
Скоро...
| № | Пользователь | Рейтинг |
|---|---|---|
| 1 | Benq | 3792 |
| 2 | VivaciousAubergine | 3647 |
| 3 | Kevin114514 | 3611 |
| 4 | jiangly | 3583 |
| 5 | strapple | 3515 |
| 6 | tourist | 3470 |
| 7 | dXqwq | 3436 |
| 8 | Radewoosh | 3415 |
| 9 | Otomachi_Una | 3413 |
| 10 | Um_nik | 3376 |
| Страны | Города | Организации | Всё → |
| № | Пользователь | Вклад |
|---|---|---|
| 1 | Qingyu | 161 |
| 2 | adamant | 149 |
| 3 | Um_nik | 146 |
| 4 | Dominater069 | 143 |
| 5 | errorgorn | 141 |
| 6 | cry | 138 |
| 7 | Proof_by_QED | 135 |
| 7 | YuukiS | 135 |
| 9 | chromate00 | 134 |
| 10 | TheScrasse | 133 |







Спасибо за разбор!
Has anyone tried solving D using a binary search?
WA#15. Also there are some strange things in tests. My answer is OK, even is not same with right answer.
19493469 Anyone want to hack? :P
Yes, http://mirror.codeforces.com/contest/702/submission/19497839.
Seems to work, so far
hacked
I don't have WA on case 15: http://mirror.codeforces.com/contest/702/submission/19508679
Try the function t(x) = time to reach the destination with x repairs. You'll find this function is linear and actually there are two points were an extremum can occur — at x = 0 and near x = d / k. Thus binary search won't work very well.
It is possible with binary search because we aren't looking for extremums but the single minimum. In the binary search compare two consecutive function values (in the middle of range). If they're decreasing set lower bound to right middle; otherwise set upper bound to left middle. My solution is similar but with ternary search not bs.
Is it possible to solve D using ternary search on the number of times we repair the car?
Yes) http://mirror.codeforces.com/contest/702/submission/19487949 No( Hacked...
I don't think so...At first I tried to use ternary search,but for the two chosen points the answer may be the same,causing it impossible to calculate the most optimized result...
Such cases happen if and only if t+a*b==k*b, where the graph of the function is horizontal line. So it works in this problem.
You are right%%%
But then what tests cause ternary search to fail? Or is it just other bugs in their code?
Don't forget to check whether it is better to ride car through all road, because such cases cannot be included in ternary search. Without this checking I got WA on test 15.
Shouldn't the check for that be
Since we require d/k repairs? I see you have
There is no need to repair the car when it breaks down at the post office.
quality: Yes, but i think d%k==0 case will be covered in ternary search (interval; 1,d/k). It is when d%k!=0 that if we cover entirely by car that we will need d/k repairs. Isn't it?
So there is no difference between the two kinds of checking above :)
Still not hacked: 19492314
would you mind explaining your solution ? I just don't seem to get the function u r applying the ternary search on. Thanks in advance :D
The function I'm applying ternary search on is a function that takes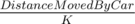 and returns the required time if the rest of the distance was walked. Note that when I leave the car I don't need to repair it, that's why I have ret + = (x - 1) * t, not ret + = x * t.
and returns the required time if the rest of the distance was walked. Note that when I leave the car I don't need to repair it, that's why I have ret + = (x - 1) * t, not ret + = x * t.
I think your solution may be correct.As quailty says,the results of tho adjacent points may be the same only if t + a * k = b * k.In such conditions your solution could still work correctly. P.S I tried to use random testcases to hack this solution,but in 4e8 tests your solution remains correct...
Yes ! Not hacked till now :D http://mirror.codeforces.com/contest/702/submission/19494286
I think the author's solution is much more simple than applying ternary search. Remember, a is always less than b, so that cuts back a lot of the casework you have to do.
The only thing that it "cuts back" is one simple if statement:
if(b <= a) cout << b * d;The thing is you only have to consider driving the car once or drive it almost the whole way, which greatly simplifies the problem. So, you don't have to consider the case where you drive the car between 1 and d/k times :)
a < b by task statement.
Please help... Why the solution of Problem B is working? what is the theory behind it?
The tutorial is confusing or wrong. You should add cnt[curr]*cnt[a-curr] or curr[a]*(curr[a]-1) if a=b.
How I would word it:
You are counting the number of times each number appears in the sequence. Then for each power of 2, p, you look for each number n that appears in the sequence to see if p-n is also there. If it is there, then there are (p-n)*n pairs you can make from those two numbers, except if p-n=n, in which case there are only (n)*(n-1) pairs you can add.
errr... I think it is pure math... you can see my solution below 19500454
thanks a lot.
In problem B, we must remember to avoid counting pairs of the same element. If the current value ai, which we process, is the power of 2, we need to add cnt[2j - ai] - 1 to an answer (look at the second test). At the end, we also have to divide our reulst by 2 because we counted all the pairs twice.
For D consider the function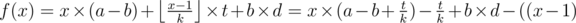 modulo
modulo 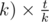 .Now we want to find
.Now we want to find 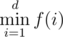 .If we fix x modulo k then the function is increasing or decresing,depends on
.If we fix x modulo k then the function is increasing or decresing,depends on 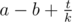 so we can take the min x and the max x and it remains to find value of function at only 2 × k points,the first k points and the last k points of the interval 1..d.
so we can take the min x and the max x and it remains to find value of function at only 2 × k points,the first k points and the last k points of the interval 1..d.
Complexity O(k).
19488570
You're totally over complicating the solution. There is a simple O(1) solution.
It is not important how complicated is solution while i get AC with small number of tries.
The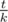 in your function is it double or integer division please ?
in your function is it double or integer division please ?
double,i transformed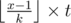 to
to 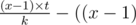 modulo
modulo 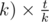 ,you need the second form only to observe what points you need to check,you can see that i used the first form in my source.
,you need the second form only to observe what points you need to check,you can see that i used the first form in my source.
Thanks.
I'd like to explain my solution of F.
T, find the next t-shirt one may afford if they cannot affordT, call itfail[T].go(all customers, all t-shirts, 0, 0).And
go(customers, tShirts, ans, spent)does the following things:customersis empty, return now.tShirtsis empty, set the answer of allcustomerstoansand return.C1be the customers that can affordspent + cost of tShirts[0]andC2be the remainding ones.go(C1, tShirts[1]..., ans + 1, spent + cost of tShirts[0]).go(C2, fail[tShirts[0]]..., ans, spent).EDIT: It's hacked.
Doesn't seem true to me.
There should be a way where almost all M of customers end up in different recursion calls (we need only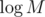 t-shirts to do that I guess). And every single one of them can end up taking all of t-shirts except of first
t-shirts to do that I guess). And every single one of them can end up taking all of t-shirts except of first 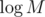 ones. So I think there is a test (which shouldn't be hard to create) where your solution is O(MN)
ones. So I think there is a test (which shouldn't be hard to create) where your solution is O(MN)
UPD:
Not completely correct, I'll try to hack you.
For question 3 I used the following n*m approach which timed out at test case 13.Can I improve it? http://mirror.codeforces.com/contest/702/submission/19495043 here's the submission code
Yes, surely you can. You are currently using two for loops that give the complexity O(n * m). You can use binary search to find the closest tower for every city. This reduced the complexity to O(n * log(m)).
thank you for problem E , it's so clever
first time to solve something like this
any similar problems ??
IOI 2012 — Scrivener uses a similar idea.
Almost the same problem : http://www.ioinformatics.org/locations/ioi11/contest/hsc/tasks/EN/garden.pdf
Hey, not exactly what you asked for but a very important subject that uses a similar idea is LCA (Lowest Common Ancestor) in O(n * log n), there are plenty of problems about it online but I did a quick google search and couldn't find anything quick, although I'm sure you could with some patience. If you can't, message me and I can send you some problems and sample code using this idea.
Problem C using the Two-pointers approach: 19503041
can you please explain your algorithm.
it's so simple I guess; all you have to do is find the Maximum shortest distance between two towers and a city in between, so as typical
Two-pointersalgorithm suggest you have to indiceslandr::lfor the cities array andrfor the towers array, then you move therindex whilecity[l] > tower[r]by then we havetower[r] >= city[l]so we check the right distance between them which istower[r] - city[l]under the condition thatr < mand the left distance i.e.city[l] - tower[r - 1]also under condition thatr > 0and get the minimum out of these two i.eThe shortest range that the city[l] can be covered with; achieved by the comparison of the distance of those two adjacent towersand then you have to maximize this property as much as possible!The technique is simple and very intuitive, I recommend this one too, to sharpen your skill 51C - Three Base Stations
Why this has been speed up ( almost half of time ) just by sorting the array ?
19503212 19503179
when the 1st element is 1e9 , it's the worst case
I'm very curious to hear about problem F... :)
It seems that some solved it using treap, right ? It's not something you see everyday ! Can anyone give us some clues on how to solve it ?
I came up with following method during contest:
Then, we can maintain the dp value backward. But, maximum j can be 109. Thus, we need some copy-on-write structure.
Considering the transition of dp, for i-th dp value. It's actually the concatenation of [0, ci) and [0, 109 - ci] of i + 1-th dp value. Then, we need add more 1 in the range of [ci, 109](lazy-tag can work).
Thus, it requires a copy-on-write structure which can maintain duplication, move, and range addition. Finally, we can find the answer in dp[1][bi] by querying the 1st dp value in that structure.
Treap seems to be that required structure. However, I never implemented a copy-on-write treap so far, not to mention a duplication.
Look forward to easier solution!
UPD: It seems that LHiC solved it with this method.
Are you sure that the data structure you described even exists? A treap which has split, merge and duplicate operations is questionable because if you merge a tree and its copy, the priorities are not random anymore.
Yes, it does exist. A treap with duplication can actually be maintained, but, in a different way.
When merging two normal treap, one will decide which root of sub-treap will be root by their pre-given random value. However, when duplication, the pre-given random value won't be random anymore. Thus, instead of giving a random value at the very beginning, now, we decide which one will be root by their size in this way:
When merging, the probability of choosing the root of each treap is proportional to its whole size. It can be proved that time complexity will also be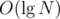 .
.
Also, as I mentioned above, LHiC got accepted with this solution at 19527903.(Although, it's just in time.)
Thank you
I can't understand from the code, how do you perfom duplication.
Could you describe it in more details?
Thanks in advance.
I have another solution that also uses a split-merge treap (different than eddy1021).
The core of this problem is to efficiently simulate the greedy buying process. Let's store all the query values in a treap. Each treap node will store information about the current value of the node, and the number of t-shirts bought by it. When we meet a t-shirt that costs c, everything in the treap with value ≥ c should be decremented by c and then their number of t-shirts bought should be incremented by 1. Then we should somehow fix the treap so that the keys are in proper order again.
First, split the treap by keys < c (treap L) and ≥ c (treap R). Apply a lazy key decrement and then a lazy t-shirt increment to treap R. Now, we can do something like mergesort. While the smallest value in treap R is smaller than the largest value in treap L, we extract it from R and insert it into L. When no such elements exist, we merge L and R and move on to the next element. At the end, the answers are in the treap nodes.
The total time complexity is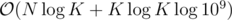 , because we only need to move the smallest element in R into L at most
, because we only need to move the smallest element in R into L at most 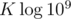 times. To show this, let's consider when an element from R would be moved into L. We know that in the beginning, before the lazy updates, all nodes in R are greater than all nodes in L. After we updated, the smallest nodes b in R is less than the greatest nodes in L, a. Recall that the price of the current t-shirt is c. Before the update, we had a < c ≤ b and after the update we have b - c < a. Combining these, we have b - c < a < c ≤ b, adding c to all terms, b < a + c < 2c ≤ b + c. The important part is b < 2c, since that implies
times. To show this, let's consider when an element from R would be moved into L. We know that in the beginning, before the lazy updates, all nodes in R are greater than all nodes in L. After we updated, the smallest nodes b in R is less than the greatest nodes in L, a. Recall that the price of the current t-shirt is c. Before the update, we had a < c ≤ b and after the update we have b - c < a. Combining these, we have b - c < a < c ≤ b, adding c to all terms, b < a + c < 2c ≤ b + c. The important part is b < 2c, since that implies 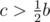 and so the value of b after the update will decrease by a factor of at least half every time we move, guaranteeing us that a node can only move
and so the value of b after the update will decrease by a factor of at least half every time we move, guaranteeing us that a node can only move 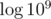 times.
times.
If you think I made a mistake somewhere, feel free to hack me at 19506886.
So, you don't actually need to make the comparison with the greatest element in L, just splitting R in ≥ 2c and < 2c, and then inserting all the elements in the second treap one by one into L would also give you the same complexity.
it seems completely strange, since I agree with proof, but I get TL... Someone can tell me where is my mistake? Thnx
To generate random priorities, you are putting values from 1 to K in a vector and then shuffling it. I did the same and got TLE on test 62. I removed it and assigned priorities randomly, it gets AC. Don't know the reason why putting priorities in a vector gives TLE.
Because random_shuffle() uses rand().
I have another solution that doesn't require treap
Consider we process all the queries together, and for every item, we try to make the customers buy it.
for every customer, we maintain $$$S_i$$$(the money the ith person currently has).
let's maintain $$$\log{C}$$$ buckets. for person i having $$$S_i$$$ money, we put him in the $$$\lfloor \log{S_i}\rfloor$$$th bucket later on, I will use the term "person $$$i$$$ goes one bucket down" meaning that $$$\lfloor\log{S_i}\rfloor$$$ will be decreased by one after buying the following item, and that he should be put into the lower bucket.
now when we see process an item costs $$$V$$$ (let $$$k:=\lfloor\log{V}\rfloor$$$)
we know that
everyone in bucket $$$j \lt k$$$ won't buy this item
Some people in bucket $$$k$$$ buy this item, and everyone that buys this item goes some buckets down
all people in bucket $$$j \gt k$$$ will buy this item, and some of them will go one bucket down
more specifically, for case 2, for everyone in this bucket that can afford $$$V$$$, will buy this item and goes some buckets down.
for case 3, we can maintain a tag on each bucket $$$x$$$ which means how much everyone's $$$S_i$$$ is decreased. Then, for every $$$S_i - V \lt 2^x$$$ should go one bucket down.
to maintain it, we can simply use a set to simulate a process, since everyone goes down a bucket at most $$$\log{C}$$$ times.
let $$$Q$$$ be the total number of item, $$$N$$$ be the number of customers
Total Complexity $$$O(N\log{N}\log{C} + Q)$$$ amortized
Hello ,for D I used binary search. I found how many stops there are at most, and I set two variables l, r as l = 0 and r = stop then I used a boolean toLeft(to hold what was the last direction I headed towards) and then I calculated that time for 'mid' . But my solution got hacked. my submission is here : Can you guys tell me what I am missing ? http://www.codeforces.com/contest/702/submission/19497043
What test hacks a ternary search in problem D?
I have a different idea to solve E which complexity may be O(n).
Each point has only one edge,we can shrink point. This can be done in O(n).
After this, we get a new graph. The new node is a node from original graph or a circle. And we find that each node in this new graph will enter a circle finally.
Suppose u->v1->v2->(circle), k arcs in the circle can calculate in O(1): convert the n node circle to 2*n,cal the prefix sum.
Now we just need to cal the node not in circle dfs v2 then v1 then u, also maintain the prefix sum. So each node res can be done in O(1)
I have not code it, Is that right?
what about min ?
You can use sparse table for it I guess.
I don't think it helps here , even you put nodes in an array in some order , path of size k for one node will not contain a contiguous subarray on it always.
On problem B editorial, I think the part "Then we need to make cnt[ai] – and add the value cnt[ai - cur] to the asnwer." would be better as "Then we need to add the value cnt[cur - ai] to the answer and increase cnt[ai]". I don't know if I'm correct, but it was the way I understood the solution. I'm considering cnt[x] starts empty before iterating. Maybe you meant the oposite, and cnt[ai] should be decreased before adding cnt[cur - ai] to the answer, but it was not clear from the editorial statement.
How to solve 702C — Cellular Network use two pointers in linear time?
19489128
http://mirror.codeforces.com/contest/702/submission/19533271
how to slove E?
The idea is parent jumping : You calculate the answer for the 1st parent, then the 2nd parent using the answer for 1st parent, then the 4th parent answer using the 2nd parent answers, 8th parent using the 4th parent answers etc... You can see my code for more details (it's very short and simple)
Similar applications of this idea include finding the LCA and IOI 2012 — Scrivener.
My code : 19509132
19516878
implemented editorial!
(E):amazing question and tutorial!
How to solve problem D using ternary search?
You can do ternary search over the number of times the car will be repaired.
I wonder if we could solve F by taking advantage of the following fact:
Consider that the shirts are sorted by decreasing quality and increasing cost, a shirt must be picked after a shirt that has the LEAST quality among the shirts which has a higher quality and lower cost.
By this, we can build a prefix sum array and a sparse table of minimum value (or BIT, segment tree) of the sorted array to solve the problem. We use binary search on the sparse table to find the first t-shirt that the customer could buy, then use binary search on the prefix sum array to find the last t-shirt the customer could buy in a row until he doesn't has enough money, then use binary search on the sparse table to find the first t-shirt that he could buy with the remaining gold, until there no longer exists a viable shirt for the customer.
However this approach seems to be extremely weak against some testing case like this (sorted in quality): $1,$100,$2,$101,$3,$104 (All customer carries $99) .... I wonder if there exists a way to optimize this approach to take care of such case?
I used this approach and got hacked because of TLE. see 19493544
когда появится разбор F?
What does mean the expression " residuary t-shirts " from problem F ?
The shirts that are left after each move
Прошла неделя
Серьёзно? 4 месяца нет разбора по F?
When will the editorial for F be added?
how to solve 702F — T-Shirts?
Tutorial for F?
F это какая-то секретная задача, решение которой нельзя разглашать?
Прошло 13 месяцев, разбор на задачу F так и недоступен...
Can anyone tell how to solve problem F?
......