


Hello CodeForces Community!
I am glad to share that HackerRank's World Codesprint 7 is scheduled on 24-September-2016 at 16:00 UTC. Contest duration is 48 hours.
The contest is sponsored by Cardlytics, Ready-talk, Indeed Prime, NCR, Coursera and Sonoma. Contest site will be continually updated to reflect upcoming sponsors.
The problems were prepared by zemen, malcolm, muratt, svanidz1, forthright48, nabila_ahmed and Shafaet. Thanks to wanbo, danilka.pro, ikbal, allllekssssa and niyaznigmatul for testing/pre-solving the problems.
The contest will be rated. If two person gets same score, the person who reached the score first will be ranked higher.
Update: The contest has ended, the editorials are available now. We will announce the winners and update the ratings soon. Meanwhile, let's discuss about the problems!
Update
Only two guys got full score in this contest in 48 hours, they are:
3 guys got 390 out of 400:
- biGinNer
- Patrick Smith
- Miguel Raggi
This suggests that the problem-set was very hard. Apart from the coders in top two, there are two other coders ("Ayman Eltemsahi" and "Ivan Livinsky") who solved the last problem but they are not in top-10.
See you next time!
Happy coding!







Why is submit option not showing for me ?
Is the penalty counted from beginning of contest or from the moment one click "sign up" like on Ad Infinitum?
Beginning of contest; I started 2 hours late, just submitted something and got 5 hours of penalty.
Duh, if I had known about it earlier or if penalty had been counted from moment of signing up than probably I would put a significant effort in achieving a good result, but now I lack motivation :<
It happens to me all the time. In a long contest, I never have the drive to work fast like in short ones.
When you think a little more it is easy to see that penalty must be like this. Otherwise I am sure, even some top coders, would have another profile where they would only read tasks and after that tries to make perfect score 10-20 minutes before current the best!
About loosing motivation I have not tell you. It happens sometime with me too, but also I think this round is not in the same situation because for 14 hours there is not single full score.
Now everything looks much harder than usual, my estimation for the first five they are a little easier than some prvious rounds. But for everything other I had no idea like many coders :D
In the contests where we count penalty from the moment of entering the contest, the number of cheats increase hugely (people open another account to view problems).
Any specific reason to have 48hrs contest instead of usual 24hrs?
For me 24h contest is nicer. You have enough time for thinking, many coders aren't free on Monday + I won't receive 300 more mails with posting new questions on forum :P
I think there is no any specific reason for changing duration, except having bigger number of submission and more participants. This contests became really big in last few months, so there is no reason to not make it even more bigger with changing time :)
For me 48h was much better. Many coders aren't free on Saturday as well.
really cool challenges.. I solved first three but in huge penalty because I signed up after 10 hours
Only after contest ends.
ok sorry for that
Similar Strings editorial is not available now.
Now it's available, refresh.
Similar strings was very nice!
However, I haven't taken hackerrank contests seriously for a long time now because of partial scoring. The difference in scores between my O(n2) and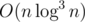 solutions is only 8 points (72 vs 80). It's just too easy to game the system with bad solutions.
solutions is only 8 points (72 vs 80). It's just too easy to game the system with bad solutions.
Hello,
seeing you so active, can you describe your Nlog^3N solution [please please please]? :P
Thanx! ^_^
Think about how you'd solve the problem if it wanted the number of exactly equal substrings. You can solve this with a suffix array and a few binary searches.
Now you should be able to modify the suffix array construction code so that it sorts suffixes based on similarity (ie a suffix "ghg" is sorted as if it were "aba"). The rest of the code is exactly the same. Of course this modification is easier said than done, but I expect hackerrank will have an editorial out soon, so this is just to give a rough idea.
Yay, seems it is there! ^_^
Anyway thanks so much for your answer — how do you compare by "similarity"? Did you precompute mapping array for each position? :O
^_^
EDIT: Oh got it! Than you so much for reply!
Have nice day man!
I achieved only 36 points with rolling hashes. In order to get 80 points I had to implement suffix array, but was not able to debug it well. So partial scoring made sense :)
So, from encyclopedia of random stuff we can learn that useful trick for doing string comparison with regard to alphabet permutation is to replace every letter with distance from its previous occurrence or -1 if it's first occurrence. If we would like to simply search one string in another one we cannot use it directly on transformed strings because of those -1s, but this turns out to be very little problem (one if added to typical KMP). Combined with Aho-Corassick it is sufficient to solve similar task about first occurrence (statement: http://cepc09.ii.uni.wroc.pl/accountant.pdf, solution: http://cepc09.ii.uni.wroc.pl/solutions.html ), but here we are asked about their number. I didn't think about that, but I think there is still a big chance it can be solved that way.
Btw, do you or Um_nik use fact that on hackerrank version alphabet is small? It doesn't make any difference to mentioned approach.
Um_nik uses exactly the property about difference you described in his solution (this was one of my first thoughts as well, but I didn't figure out how to handle -1).
The thing is his solution handles the -1s one by one, so it uses the fact that there are O (alphabet) -1s in any string. My solution needs to compare letter mappings for two substrings, so that's also an O (alphabet) factor.
My solution to Similar strings is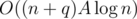 . It is quite complex and it will be hard for me to explain it in English. But if you are interested, you can read my code and ask questions if something is unclear.
. It is quite complex and it will be hard for me to explain it in English. But if you are interested, you can read my code and ask questions if something is unclear.
That's very clever! I realized we can also do something similar with suffix automata (I used your code as a base, hope you don't mind): http://pastebin.com/V9Lvq8TL
Here one can find some discussion about similar problem.
I have some doubts regarding the problem Inverse RMQ :
Are we only allowed to shuffle the array and find a lexicographically smallest segment tree or are we also allowed to change the actual numbers in the given array.
As I read, you can't change the numbers in the given array.
Even I thought the same and approached the problem in this way :
1. Put all the numbers in a multiset
2. If the number of unique numbers is not N then the answer is "NO"
3. If the number of unique numbers is N then I start by filling the leaf by ascending order of the numbers in the multiset
4. Now I maintain the Segment Tree invariant
tree[i] = min(tree[2*i] , tree[(2*i)+1]). I check whethertree[i]is present in the multiset . If it is not then the answer is "NO" . If it is present then I decrement it's frequency by 1 .But this approach gave me only 13 points . I think I misinterpreted the problem . Can someone please help .
My Submission : LINK
Good day to you!
[sorry can't access link]
Anyway — the main priority belong to Frequencies (and afterward to values). This means that most frequent value must be in leftmost PATH . Second most frequent value must be in the leftmost PATH of right subtree. This works recursively with following 2,4,8,16,..most frequent values.
Now you would like to put these values in increasing order. BUT! Only if this is possible. Sometime a situation might appear, that you have to "skip" position because you have "too low" element.
Anyway: I would recommend building from top to bottom!
"NO" appears:
A) Whenever it is not true, that frequencies are in following frequence?:
1xN
1xN-1
2xN-2
4xN-3
8xN-4
...
and so on
Also when you come to situation, when you would pick least frequent value (as minimum) — but you must be sure, it can't fit somewhere else.
Good Luck!
Oh I realise my mistake now . I've been so greedy to find the lexicographically smallest answer that in many cases even if an answer exists my code can say "NO".
Hackerrank hasn't yet unlocked the submissions that's why the link is not working. Anyways my code is entirely wrong. I'll try your approach.
Thanks a lot
It's interesting how the author played around the two words which has totally different meaning thorough out the problem statement. Though only
shufflingis allowed.either shuffled or altered the elements.Can you use the altered data to restore the original array?could not be constructed by shuffling some segment treecan any one explaine the "Summing Pieces" solution please! .. I can't understand or proof the dp formula
Man! you posted the question before contest end and you were pounced with negative votes. Now you post the same question after the contest and there is no love! Welcome to CF community!
I'll explain my approach. I listed a table
rows representing the number of the element. i.e. 1st row is 0th element, 2nd row is first element and so on.
The columns represent the size of the subset.
The value in the table is the no. of times the element occurs in the subset of the size.
For e.g. N=8 gives the table below. This means that the first element occurs in subset of size one 64 times. The final answer is a0*(t00*1 + t01*2 + t02*3...) + a1*(t10*1 + t11*2 + t12*3....) and so on.
Calculating the above values needs O(N^2) solution which is not enough.
So I calculated sum of first row and used it to transition to sum of second row in constant time.
We can observe that the value change for a column across rows is constant. For e.g. if we have to increase the value in the third column, we will always increase it by 8 (see change table below). So I use subset sum to increase the values of required columns.
My code. Needs hackerrank login.
thank you so much for your explanation it is very helpful .. when I asked this question before the contest end I apologized later for my fault and edited the question then asked it after the contest to make it legal .. however thank you and for CF community!
I too solved the problem by finding a pattern , but I felt bad because I wasn't able to prove/deduce how that was occurring .
I wrote a brute force recursive solution to find the number of occurrence of each subarray . Then it's very easy to calculate the sum efficiently .
As you can see the leftmost and rightmost subarrays of each length can be calculated separately and the rest can be calculated by simplifying the sum using prefix sums .
Here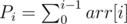 (arr is the given array and it's 0 based indexed.
(arr is the given array and it's 0 based indexed.
The sum on the left of each column is the sum of all subarrays of that length except the leftmost and rightmost .
My Code
I would like to share an alternative approach which I think is more straightforward, requires very less thinking and more algebra.
First, for an array of length n, denote a(n) as the number of ways to partition it into contiguous subarrays. Then a(n)=2^(n-1) and a(0)=1.
For any element in the array, we need to find the number of times it lies in any particular subarray. If the element i lies in a subarray of length k, then a[i]*k*(number of times this element is in this subarray) is added to the final answer.
Consider the element at index i. Also, let j<=i and k>=i, then for any i, we have to find the following sum:
Carefully simplifying the above sum, we get: z=3*2^(n-1)-2^(n-i)-2^(i-1). Add a[i]*z to the final answer.
I used the same method
Is there any way to solve the "Recording Episodes" problem other than the 2SAT approach mentioned in the editorial? Maybe using Dynamic Programming? Or is 2SAT the only feasible solution, atleast for the given constraints?
the problemset was really interesting and balanced. how much does it actually take for a tshirt to deliver? it's written 6-8 weeks in the website. but i'm really curious because i won something from a online contest first time in my whole life.
It should take 6-8 weeks but sometimes it might take longer. If it takes more then 10 weeks, contact support.
Congrats for winning your first t-shirt!
What's your hackerrank handle ?