


Tutorial is loading...
Code
#include <algorithm>
#include <bitset>
#include <cassert>
#include <climits>
#include <cmath>
#include <cstdio>
#include <cstdlib>
#include <cstring>
#include <deque>
#include <iomanip>
#include <iostream>
#include <map>
#include <numeric>
#include <queue>
#include <set>
#include <stack>
#include <string>
#ifdef PRINTERS
#include "printers.hpp"
using namespace printers;
#define tr(a) cerr<<#a<<": "<<a<<endl;
#else
#define tr(a)
#endif
#define ll long long
#define pb push_back
#define mp make_pair
#define pii pair<int,int>
#define vi vector<int>
#define all(a) (a).begin(),(a).end()
#define F first
#define S second
#define sz(x) (int)x.size()
#define hell 1000000007
#define endl '\n'
#define rep(i,a,b) for(int i=a;i<b;i++)
using namespace std;
void solve(){
string a,b;
cin>>a>>b;
vector<string>taken;
int n;
cin>>n;
rep(i,0,n){
cout<<a<<" "<<b<<endl;
string c,d;
cin>>c>>d;
if(c==a)a=d;
else b=d;
}
cout<<a<<" "<<b<<endl;
}
int main(){
ios_base::sync_with_stdio(false);
cin.tie(0);
cout.tie(0);
int t=1;
while(t--){
solve();
}
return 0;
}
Tutorial is loading...
Code
#include <bits/stdc++.h>
using namespace std;
int sieve[100005];
int main()
{
int i, n, j;
cin>>n;
for(i=2; i<=n+1; i++)
{
if(!sieve[i])
for(j=2*i; j<=n+1; j+=i)
sieve[j]=1;
}
if(n>2)
cout<<"2\n";
else
cout<<"1\n";
for(i=2; i<=n+1; i++)
{
if(!sieve[i])
cout<<"1 ";
else
cout<<"2 ";
}
return 0;
}
Tutorial is loading...
Code
#include <algorithm>
#include <bitset>
#include <cassert>
#include <climits>
#include <cmath>
#include <cstdio>
#include <cstdlib>
#include <cstring>
#include <deque>
#include <iomanip>
#include <iostream>
#include <map>
#include <numeric>
#include <queue>
#include <set>
#include <stack>
#include <string>
#ifdef PRINTERS
#include "printers.hpp"
using namespace printers;
#define tr(a) cerr<<#a<<": "<<a<<endl;
#else
#define tr(a)
#endif
#define ll long long
#define pb push_back
#define mp make_pair
#define pii pair<int,int>
#define vi vector<int>
#define all(a) (a).begin(),(a).end()
#define F first
#define S second
#define sz(x) (int)x.size()
#define hell 1000000007
#define endl '\n'
#define rep(i,a,b) for(int i=a;i<b;i++)
using namespace std;
void solve(){
int N,k;
scanf("%d%d",&N,&k);
ll x[N+1];
x[0]=0;
rep(i,0,N)scanf("%lld",&x[i+1]);
partial_sum(x,x+N+1,x);
if(k==1){
ll ans=0;
map<ll,int>m;
for(int i=N;i>=0;i--){
if(m.find(x[i]+1)!=m.end())
ans+=m[x[i]+1];
m[x[i]]++;
}
printf("%lld\n",ans);
}
else if(k==-1){
ll ans=0;
map<ll,int>m;
for(int i=N;i>=0;i--){
if(m.find(x[i]+1)!=m.end())
ans+=m[x[i]+1];
if(m.find(x[i]-1)!=m.end())
ans+=m[x[i]-1];
m[x[i]]++;
}
printf("%lld\n",ans);
}
else{
ll ans=0;
map<ll,int>m;
for(int i=N;i>=0;i--){
ll cur=1;
while(true){
if(abs(cur)>=1e15)break;
if(m.find(x[i]+cur)!=m.end())
ans+=m[x[i]+cur];
cur*=k;
}
m[x[i]]++;
}
printf("%lld\n",ans);
}
}
signed main(){
int t=1;
while(t--){
solve();
}
return 0;
}
Tutorial is loading...
Code
#include <bits/stdc++.h>
using namespace std;
#define mem(x,y) memset(x,y,sizeof(x))
#define bitcount __builtin_popcountll
#define mod 1000000007
#define N 1000009
#define fast ios::sync_with_stdio(0); cin.tie(0); cout.tie(0);
#define ss(s) cin>>s;
#define si(x) scanf("%d",&x);
#define sl(x) cin>>x;
#define pb push_back
#define mp make_pair
#define all(v) v.begin(),v.end()
#define S second
#define F first
#define ll long long
int n,m;
vector<int> arr[N];
int arr1[N];
vector<pair<int,int > > adj[100008]; //max-size
void graph(int n){for(int i=1;i<=n;i++){
int x = arr[i][0];
int y = arr[i][1];
adj[x].push_back(mp(y,arr1[i] )); //arr1[i] stores th color of the edge
adj[y].push_back(mp(x,arr1[i]) );}
}
int col[N];
bool vis[N];
int main(){
//fast //uncomment on submission
cin>>n>>m;
assert(n>=2 && n<=100000);
assert(m>=2 && m<=100000);
for(int i =1;i<=n;i++)cin >> arr1[i];
for(int i = 1;i<=m;i++){
int sz;
cin >> sz;
for(int j =0;j<sz;j++){
int y ;
cin >> y;
arr[y].push_back(i);
}
}
graph(n);
mem(col,-1);
mem(vis,false);
bool p = true;
for(int i = 1;i<=m;i++){
if(!vis[i] && adj[i].size()){
col[i] = 0;
vis[i] = true;
queue <int > q;
q.push(i);
while(q.size()){
int node = q.front();
q.pop();
for(auto pi:adj[node]){
int co = col[node];
if(pi.S == 0){ //if the edge is 0 then give the opposite color.
co = 1 - co;
}
if(vis[pi.F] && col[pi.F] != co){
p = false;
}
if(!vis[pi.F]){
col[pi.F] = co;
vis[pi.F] = true;
q.push(pi.F);
}
}
}
}
}
if(!p)cout<<"NO";
else cout<<"YES";
}
Tutorial is loading...
Code
#include <bits/stdc++.h>
using namespace std;
#define ll long long
#define MOD 1000000007
#define ll long long
#define pb push_back
#define pii pair<int,int>
#define vi vector<int>
#define all(a) (a).begin(),(a).end()
#define F first
#define S second
#define endl '\n'
#define PI 3.14159265359d
#define sz(x) (int)x.size()
ll phi(ll n)
{
ll i,res=n;
for(i=2;i*i<=n;i++)
if(n%i==0)
{
while(n%i==0)
n/=i;
res-=res/i;
}
if(n>1)
res-=res/n;
return res;
}
int main()
{
ll n,k,res;
cin>>n>>k;
res=n;
k=(k+1)/2;
while(k--)
{
res=phi(res);
if(res==1)
break;
}
cout<<res%MOD;
return 0;
}
Tutorial is loading...
Code
#include<bits/stdc++.h>
using namespace std;
#define sd(x) scanf("%d",&x)
#define slld(x) scanf("%lld",&x)
#define ss(x) scanf("%s",x)
#define ll long long
#define mod 1000000007
#define bitcount __builtin_popcountll
#define pb push_back
#define fi first
#define se second
#define mp make_pair
#define pi pair<int,int>
pi arr[100005];
int n,m;
bool cmp(pi x, pi y)
{
int a=min(x.se-x.fi-1,n-2-(x.se-x.fi-1));
int b=min(y.se-y.fi-1,n-2-(y.se-y.fi-1));
return a<b;
}
vector<int>nodes[100005];
vector<int>v[100005],v2[100005];
int de[100005],siz[100005];
void dfs1(int node, int par)
{
siz[node]=1;
for(int i=0;i<v[node].size();i++)
{
if(de[v[node][i]]==0&&v[node][i]!=par)
{
dfs1(v[node][i],node);
siz[node]+=siz[v[node][i]];
}
}
}
int dfs2(int node, int par,int s)
{
int maxi=0,maxinode;
for(int i=0;i<v[node].size();i++)
{
if(de[v[node][i]]==0&&v[node][i]!=par&&siz[v[node][i]]>s/2)
{
return dfs2(v[node][i],node,s);
}
}
//printf("%d\n",node );
return node;
}
int decompose(int node)
{
dfs1(node,-1);
int cen=dfs2(node,-1,siz[node]);
// printf("%d\n",cen );
de[cen]=1;
for(int i=0;i<v[cen].size();i++)
{
if(de[v[cen][i]]==0)
{
int x=decompose(v[cen][i]);
//printf("%d\n", x);
v2[cen].pb(x);
v2[x].pb(cen);
}
}
return cen;
}
int level[100005];
int main()
{
//freopen("in.txt","r",stdin);
//freopen("out.txt","w",stdout);
int i,j,k;
sd(n);
sd(m);
for(i=1;i<=m;i++)
{
sd(arr[i].fi);
sd(arr[i].se);
if(arr[i].fi>arr[i].se)
{
swap(arr[i].fi,arr[i].se);
}
}
sort(arr+1,arr+m+1,cmp);
set<int>s;
for(i=1;i<=n;i++)
s.insert(i);
k=0;
for(i=1;i<=m;i++)
{
if(arr[i].se-arr[i].fi-1<=n-2-(arr[i].se-arr[i].fi-1))
{
nodes[k].pb(arr[i].fi);
set<int>::iterator it=s.upper_bound(arr[i].fi);
while((*it)!=arr[i].se)
{
nodes[k].pb(*it);
it++;
}
nodes[k].pb(arr[i].se);
for(j=1;j<nodes[k].size()-1;j++)
s.erase(nodes[k][j]);
}
else
{
while(*s.begin()!=arr[i].fi)
{
nodes[k].pb(*s.begin());
s.erase(s.begin());
}
nodes[k].pb(arr[i].fi);
nodes[k].pb(arr[i].se);
int l=nodes[k].size();
set<int>::iterator it=s.upper_bound(arr[i].se);
while(it!=s.end())
{
nodes[k].pb(*it);
it++;
}
for(;l<nodes[k].size();l++)
s.erase(nodes[k][l]);
}
reverse(nodes[k].begin(), nodes[k].end());
k++;
}
while(s.size()!=0)
{
nodes[k].pb(*s.begin());
s.erase(s.begin());
}
reverse(nodes[k].begin(), nodes[k].end());
k++;
sort(nodes,nodes+k);
map<pi,int>m1;
for(i=0;i<k;i++)
{
for(j=0;j<nodes[i].size()-1;j++)
{
if(nodes[i][j]==nodes[i][j+1]+1)
continue;
else if(m1.find(mp(nodes[i][j],nodes[i][j+1]))!=m1.end())
{
v[m1[mp(nodes[i][j],nodes[i][j+1])]].pb(i+1);
v[i+1].pb(m1[mp(nodes[i][j],nodes[i][j+1])]);
m1.erase(mp(nodes[i][j],nodes[i][j+1]));
}
else
{
m1[mp(nodes[i][j],nodes[i][j+1])]=i+1;
}
}
j=nodes[i].size()-1;
if(nodes[i][0]!=n||nodes[i][j]!=1)
{
if(m1.find(mp(nodes[i][0],nodes[i][j]))!=m1.end())
{
v[m1[mp(nodes[i][0],nodes[i][j])]].pb(i+1);
v[i+1].pb(m1[mp(nodes[i][0],nodes[i][j])]);
m1.erase(mp(nodes[i][0],nodes[i][j]));
}
else
{
m1[mp(nodes[i][0],nodes[i][j])]=i+1;
}
}
}
for(i=1;i<=n;i++)
level[i]=1e6;
int cen=decompose(1);
//printf("%d\n",cen );
queue<int>q;
i=0;
q.push(cen);
while(!q.empty())
{
j=q.size();
while(j--)
{
int z=q.front();
q.pop();
level[z]=i;
for(int l=0;l<v2[z].size();l++)
{
if(level[v2[z][l]]==1e6)
{
q.push(v2[z][l]);
}
}
}
i++;
}
for(i=1;i<=k;i++){
//printf("%d %d\n",v2[i].size(),level[i] );
printf("%d",level[i]+1 );
if(i!=k)
printf(" ");
}
printf("\n");
return 0;
}
Tutorial is loading...
Code
#include<bits/stdc++.h>
using namespace std;
#define sd(x) scanf("%lld",&x)
#define slld(x) scanf("%lld",&x)
#define ss(x) scanf("%s",x)
#define ll long long
#define mod 65536
#define bitcount __builtin_popcountll
#define pb push_back
#define fi first
#define se second
#define mp make_pair
#define pi pair<int,int>
ll dp[17][65538][17];
char a[20];
ll b[20];
ll mo[1100005];
ll f(ll m,ll p,ll pos)
{
if(dp[m][p][pos]!=-1)
return dp[m][p][pos];
if(pos==0)
{
if(((1<<m)&p))
dp[m][p][pos]=1;
else
dp[m][p][pos]=0;
return dp[m][p][pos];
}
ll j=0;
for(ll i=0;i<=15;i++)
{
j+=f(max(m,i),mo[p*16+i],pos-1);
}
return dp[m][p][pos]=j;
}
int main()
{
//freopen("in.txt","r",stdin);
//freopen("out.txt","w",stdout);
ll t,n,i,j,k,l,r,m,p,ans1;
mo[0]=0;
for(i=1;i<=1100000;i++)
{
mo[i]=mo[i-1]+1;
if(mo[i]==mod)
mo[i]=0;
}
memset(dp,-1,sizeof dp);
f(0,0,16);
sd(t);
while(t--)
{
ss(a);
n=strlen(a);
l=0;
for(i=0;i<n;i++)
{
l=l*16;
if(a[i]>='0'&&a[i]<='9')
l+=a[i]-'0';
else
l+=a[i]-'a'+10;
}
ans1=0;
if(l>0)
{
l--;
j=l;
for(i=0;i<n;i++)
{
b[i]=j%16;
j/=16;
}
m=p=0;
for(j=n-1;j>=0;j--)
{
for(k=0;k<b[j];k++)
ans1-=dp[max(m,k)][mo[p*16+k]][j];
m=max(m,b[j]);
p=mo[p*16+b[j]];
}
ans1-=dp[m][p][0];
}
ss(a);
n=strlen(a);
r=0;
for(i=0;i<n;i++)
{
r=r*16;
if(a[i]>='0'&&a[i]<='9')
r+=a[i]-'0';
else
r+=a[i]-'a'+10;
}
j=r;
for(i=0;i<n;i++)
{
b[i]=j%16;
j/=16;
}
m=p=0;
for(j=n-1;j>=0;j--)
{
for(k=0;k<b[j];k++)
ans1+=dp[max(m,k)][mo[p*16+k]][j];
m=max(m,b[j]);
p=mo[p*16+b[j]];
}
ans1+=dp[m][p][0];
printf("%lld\n",ans1);
}
return 0;
}







Can someone explain me the C Molly's chemical value. What would be the time complexity of the solution?
O(log(base(k)[(10^14)])*log(n)*n)
Explanation:- 1. distinct power of K => log(base(k)[(10^14)]) 2. total distinct sum= total maximum distict cumulative sum is n , as we are using map for the search total searching complexity for required sum is log(n). 3. and array size is n . - See solution : Solution Link
I want to share an alternative solution to Problem D which uses 2-SAT. Let p and q be the switches of a door. If the door is locked (equal to 0) you need to get it to 1 applying p or q, this the same as doing . Similarly if the door is unlocked (equal to 1) you should do
. Similarly if the door is unlocked (equal to 1) you should do 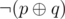 (because you want that the door doesn't change).
(because you want that the door doesn't change).
Then you should transform each of this expressions so that you get a conjunctive normal form, you can do it like this:
And now for each door you have one of this expressions and you can do 2-SAT with this.
And then you can see that when you added 1 one-way edge, you also added its reverse as well thus you can easily solve this problem using disjoint set.
Beautiful solution!
wow
Можно пожалуйста вопрос про D. Предположим мы ходим по графу и разукрашиваем его, допустим текущая вершина покрашена в цвет 1. Далее мы продолжаем его разукрашивать, и каким-то образом идем по ребру веса 1 в эту же вершину и цвет не совпадает, мы сразу выводим "NO". Но разве мы не можем пойти по какому-нибудь другому пути, где их цвета совпадут? Почему это работает ?
Если ты покрасишь 1 вершину в один цвет, то есть только один способ покрасить оставшиеся вершины. Ты ходишь по вершинам и разукрашиваешь их. Если ты смог покрасить весь граф по выше описанному алгоритму, то ответ есть, иначе если ты не модешь разукрастить граф, то ответа не существует. Подумай над этим.
can you check my account? 2 problems were accepted but my rating don't change!
Your submissions were skipped because someone has the same code as you. Did you use ideone.com or other online IDEs? If yes, many people had a chance to copy-paste your solution(cheaters)
oh no, I give my code to my friends :|
For problem C, using unordered_map gives TLE on test case 101, whereas it gives AC using maps. Aren't unorderd_maps supposed to give better runtime or is this because of the rehash or something ?
Because of collisions unordered_map works with complexity O(n) in worst case while worst case for simple map is O(logN)
776C — Molly's Chemicals why unordered_map cause TLE?
I just replace unordered_map with map.
AC code : http://mirror.codeforces.com/contest/776/submission/24956397
TLE code : http://mirror.codeforces.com/contest/776/submission/24956380
can someone tell me why? please.
solved now.
AC code : http://mirror.codeforces.com/contest/776/submission/24956769
They do this often: http://mirror.codeforces.com/blog/entry/4898
Problem D
Can someone please help me debug this code
The approach was following:
1. Find controlling switches for every room and join them with edge weight 0 if room is open else with edge weight 1.
2. If room is open it means sum of toggling times of switches controlling it, should be even,therefore edge of weight 0 is added and vice-versa. (Edges therefore denotes parity of sum of toggling times to open this room.)
3. After the graph is constructed look for an odd-weighted cycle in the graph.
4. Existence of an odd-weighted cycle would mean there are two different paritys of sum of toggling times of same pair of switches , which is not acceptable ,Hence ans is "No"
Can someone please explain the dictionary part in problem C.
You don't have to watch at every prefix before current position, with dictionary you can easy find number of required sums with log(n). Otherwise u will get TL, cause of O(log(10^14)*n^2)
I dont undertand Problem C at all.How are we distinguishing whether we are getting subarray sum or subset sum?How are we making sure we are taking subsegment.I just dont get it. Please someone help and clarify in Laymen terms.
I also don't understand the method described in editorial, but I can tell about my solution =)
Let's say we have an array A = [2, 2, 2]. The total number of different subarrays looks like that (I will write all of them as pairs of indices [start, end]):
[0, 0], [0, 1], [0, 2],
Subarrays starting with 0[1, 1], [1, 2],
Subarrays starting with 1[2, 2].
Subarrays starting with 2In total there are 3 + 2 + 1 = 3 × (3 + 1) / 2 = 6 different subarrays. For an array of size n there are n × (n + 1) / 2 subarrays — too much to handle them one by one. That is why we split them cleverly into groups.
As you can see from the picture above there are 3 different groups of subarrays. I will call the group of segments that starts with index 0 as group0 = {[0, 0], [0, 1], [0, 2]}. The group of segments starting with index 1 as group1 and the last group with a single subarray as group2.
Why should we split them like that? This will allow us to reuse calculations for the first group0 in the other groups in the following order:
group0 ⟶ group1 ⟶ group2
That is, we first calculate the sums for all of the subarrays in the group0 directly without any clever manipulations like that:
Now I will place these sums in a
map<>, because we need to count how many times a certain sum has appeared among subarrays in group0:And now we are ready to reuse them in group1. First thing that we know is that in the best case, even if all of the sums of subarrays in group1 will match our requirements (powers of k) the number of subarrays in group1 is smaller than in group0 by 1 (number of subarrays in group0 is 3 and number of subarrays in group1 is 2). That is why we have to get rid of one of the subarrays in
cnt[].What subarray sum we need to get rid of? That is subarray [0, 0], because it doesn't intersect with any of the subarrays in group1:
Now
cntcontains sums of the 2 subarrays: [0, 1] and [0, 2]. But they start at 0, so we cannot reuse them as if they are subarrays of group1...But we can notice one thing if we put remaining subarrays of group0 with subarrays of group1 in front of each other:
group0: [0, 1], [0, 1, 2]
group1: [1], [1, 2]
You see? They differ only in one thing: subarrays of goup0 include the element A[0], but subarrays of group1 are without it! So we can reuse all of the sums in
cntby shifting the value that we want to look up by A[0]. For example, if we want to check how many subarrays from group1 have a sum = 4 we will do the following:hey pixar!!Can you please post your solution link here...
Sure!
My original solution (I was describing it in my comment): 24936305
Solution based on the idea described in the editorial: 25086867
Problem C Molly's Chemicals can be solved using divide & conquer: 24957185
First we compute prefix sum in O(N)
Divide the array into half, until it has 1 element left. We try to recursively find the desired segment sums from left half and right half (The segment TOTALLY fall into those half)
For conquer part, we add up the return value from left half, right half, and those segments which cross the middle line, which can be calculated as follows:
Together we got T(N) = T(N/2) + O(NK lg N)
I tend to see K as a constant, so I think T(N) ~ O(N lg^2 N)
In question C, can anyone please explain the author's solution..
Can someone help me find my mistake for Div2/D. I am solving it using 2-SAT and getting WA on test 24 25295970
Why doesn't author give a link https://en.wikipedia.org/wiki/Euler%27s_totient_function ?
Wow, problem D is a bad problem
wow