


Hello, Codeforces!
I'd like to invite you to join in Playrix Codescapes Cup for the both divisions that will be held on May 11 at 18:35 MSK. The round is rated and open for everyone.
Problems are prepared by KAN, Al.Cash, MikeMirzayanov and fcspartakm. Huge thanks to Playrix company for making this round possible. Hope you enjoy the round!

Playrix is one of the leading mobile games development companies in the world. Its distributed team consists of 450 professionals from around the world. The company has released three successful mobile free-to-play games – Township, Fishdom and Gardenscapes. All of the projects have consistently been among the Top 50 Grossing Apps for iOS and Google Play since their release.In 2016, Facebook named Gardenscapes game of the year.
Company is looking for Russian-speaking C++ developers.
Prizes from the Playrix company:
- Top 1: iPadPro 9,7 + PowerBank + T-shirt with logo
- Top 2-5: PowerBank + T-shirt with logo
- Top 6-50: T-shirt with logo
- (New!) Random 5 participants (not from top-50, submitted at least once): T-shirt with logo

Congratulations to the winners!
The problem analysis is published.







why all of the jobs in codeforces are for Russian-speaking contestants?
I think it's a matter of the companies which hold contests on CF , not CF itself.
Register again. Previous registration has been cancelled.
How many problems?
Tourist winning another round ? Hope he participates.
why so much hate on this comment lol..everyone knows he will win, and I guess everyone loves tourist — the beast
tourist will complete his set of apple products.
Maybe "multiset" XD
Posted time: 15:35 UTC
Actual time: probably 15:45 UTC
Yes, because they reset the registration.
Hi, everybody.
The offer to organizers from the company Playrix
Considering that the Playrix is engaged in development of games, I would advise to bring some spirit of surprise in a contest :) For example, to add 3-5 small prizes (or T-shirts) which by a randomly method will get to participants outside the first hundred, and maybe the first thousand. It would stimulate attraction to a contest of players.
would be fantastic, no newbies got a tshirt before.
Although I totally love the idea and also love to get a T-shirt, but I think keeping it for the first 50 is better. To encourage low-rate participants to do better and EARN the T-shirt.
I don't urge to take away t-shirts at TOP-50 participants. ))) I suggest to give IN ADDITION 3-5 t-shirts for participants from the first thousand
Great idea, thanks! Playrix will give 5 additional prizes to random participants not included in the top 50. I hope CF will help us with fair random algorithms )
Best Regards, Trushkov Aleksey Playrix
It would be great if you will announce such events more than a day before. Thanks.
Problem prepared by MikeMirzayanov! I'm not gonna miss it.
I predict there will be an obscure Geometry problem.
Given that Playrix is a games development company?
Playrix is one of the leading mobile games development companies in the world.
T-shirt on girl is really great :D
What's her name :D ?
and a very long right hand
I hope there won't be delay before the contest.
Me too XD
Dafuq happened to the right hand of the t-shirt girl?..look at those veins :O
Hope it's easy to understand all the problems, And all participants will enjoy the contest. :)
The T-Shirt Looks Nice
How does back of white T-shirt look?
Rating prediction,
Extensions:
Have fun & high rating:)
PS One guy wrote to me that he couldn't install extension. Does anybody else has the same problem?
I have same problem :(
"An error has occurred There was a problem adding the item to Chrome. Please refresh the page and try again."
I think I got this message when I had slow internet speed
how many problems???
T-shirts very well
Is my luck so poor?
I never get a random prize.
Well considering that 4500 ppl will participate in this round 50 for them will get prizes for sure that leaves 4450 the probability that one will get a prize is 0.0011235955.
Your luck is not poor it's just math.
:)
PS: if you work hard enough you won't need luck cause your probability will be 1.
Actually, assuming 4500 people submit at least once, the probability that you win one of the 5 random T-Shirts is 0.003366496682134068.
Still got a higher chance than finding our soulmate
I wonder if the T-shirts in this contest will be distributed based on an adaption of the formula from the problem in the previous contest 807B - T-Shirt Hunt ...
i think that it will be a little bit tricky one and challenging too.....
What about scoring distribution?
The '#' took the perfect place in the picture.
Expecting a 10 minute delay. xD
How many problems? What's the scoring distribution?
5 minutes before the contest: we're still waiting for more info
Look at girl's right hand. What is that monster dude...?
photoshopFAIL
wow.. no delays .. so unusual ..
hope to be in random 5 !!!
MikeMirzayanov please give tourist a new color :O
Did you spend the last ten minutes of the contest making this meme?
yes
you make my day))
how to solve D?
Dp[h][w] in map
But how do you know which extinction you used and which one you didn't ?
dp[h][w*a[i]]=dp[h][w] dp[h*a[i]][w]=dp[h][w] for all i:=0 to n-1
I'm so dumb.
Sorry.
Hope you pass systest.
:)
thanks, you too)
It's fail! TL!
I'm so sorry...Don't worry you'll get them next time.
:)
Notice that for ai >= 3, you will need maximum of 11 items to increase alength from 1 to over 10**5. So you can brute over min(22, n) largest items to divide them into either Length/width. Incase the length is still less, then find how many no of 2's will satisfy Maintain a count of actual length increments done and find the minimum answer.
Complexity: O(2**22 * 20)
I thought this should pass. But this was very close to tle. 940ms first time for me. But after doing some bad optimizations, it passes pretest ins 499ms. (I lost around 400 points on this :|)
If reverse sorted a[] is like five 6, five 5, five 4, five 3, five 2, you can brute over x '6' to width and 5-x '6' to height. And so on for the rest of the unique values in a[]. I think a binary search is required at the lowest level as you may not need all of 5-x 'smallest-digit'. And we must also consider inverted the rectangle by 90degree. The max time this will take is 2*( 2^(2*10 + 2*log11) ).
if you sort in non-increasing order, you should not to skip some extension, answer is some prefix, so you can use dp[idx][pair(curW, curH)] with map 27034588
It is also possible to memoize only one of the parameters (h or w). The other one may be derived from the current index of the dp if you precompute the prefix product of the sequence.
what is the time complexity of this approach? how many elements in the worst case will be added to the map?
In my solution , it's O(max(a,b)) — since there are sqrt(x) different x/y numbers for y belongs to integers. so sqrt(x)*sqrt(x) for the pair = O(x) = O(max(a,b)).
Congrats tourist , i was spectating whole round lol
How to solve C?
Taking fountain with diamond + coin is easy. Then use two pointers\bin search for coin + coin, diamond + diamond pair.
Could you, please, explain how to do that? It looks like a knapsack for me.
When we buy fountain for x coins, we still have c — x coins. So you can sort and find max prefix that you can buy with c — x coins, and find max beauty in that prefix with prefix maximums.
I think that with this approach we can choose one fountain twice.
Nope, we just limit our prefix by i — 1.
Yeah, really, I didn't think about that, thank you!
not if you binary search corectly. you should make hi=i-1 and it is imposible to take fountain i twice
I described that in my comment below.
Could you share your code?
Here (might fail because of bugs)(don't look at the segtree, I haven't used it).
My solution is failing on test 4 . How to handle it ?
well,you have 2 cases:you take two of the same type(2 coins or 2 diamonds) or you take one fountain with diamonds and one with coins.
1 diamond+1coin: you take the most beautifull fountain you can afford for each type
2 diamonds/coins: you take fountain i,and search for another fountain j,such that their beauty is maximal for i,and their cost is small enough
I don't understand how to do that.
you select a fountain i,and say "ok,i would like to buy this fountain and another one of the same type,but i would like to take the most beautifull one i can afford". so beauty[i]+beauty[j] is maximal,and cost[i]+cost[j]<=C(or D,depends on case)
and res will be max of all this cases and case 1(1 diamond+1 coin)
We do O(n) steps to choose fountain i. For each of i we do O(n) operations to find j'th fountain. Right?
we find j in logN steps by sorting the array and binary searching after,but thats the tedious part,and its hard to explain.
So, we sort by beauty or by cost?
by cost
In this case, after sorting the array by cost and getting the position of the fountain with less or equal to (total coins — coins for selected fountain) coins, wouldn't one need to check for all fountains less than this found price as well? Then, will it still be logN?
yes,because it would be something like max(beauty[1],....beauty[j]),which can be precalculated with another array,where V[i]=max(beauty[1],beauty[2],....,beauty[i])
I have used the same approach but my solution is giving WA on test 4 .
Well,You did something wrong in the code than. Belive me,this approach is good,and i got accepted with it
"ok,i would like to buy this fountain and another one of the same type,but i would like to take the most beautifull one i can afford"
But can it be a situation like we can choose 2 fountains in one currency without that fountain we chose in the first time?
Yes,thats why you take each fountain i from 1 to number_of_same_type,and after you do a max
@Reol , I have done same thing as you are mentioning. But was getting WA for 4th testcase... can't figure out what is mistake,,,
Exact same case with me. I did binary search and keep getting WA on 4th test case.
@hrushikesht, binary search ???
I thought it was simple knapsack problem... where picking up 2 fountains was compulsory :| ... Can't say for sure...
well its pretty hard to do knapsack on this,considering you would end up with O(N*C*D) plus,you can choose a maximum of 2 elements,so that would be a costant of 2
@georgerapeanu
What I mean by knapsack is that.
firts of all split fountains which can be bought by only diamonds , and only coins,,, then given list of fountains which can be bougth by only coins,,, use knapsack for them ,,, and DP table size will be ,,,
(number_of_coin_fountains * 2) same goes for number_of_diamond_mountains*2 size for other process... Since costs of fountains are within the 10^5 ,,, that was most preferable approach(in my opinion),,,
wouldnt it be O(C*number_of_coin*2)?
because you should take care of the cost,and you are at index i,and you have selected k fountains so far
@georgerapeanu,,,
yeah , my bad,,,
it will be maximum 100000*2 ,,, and we can fill up the DP table in linear time...
but now, you must be getting an idea,,, which KNAPSACK I was talking about
I used segment tree range maximum query to find the best pair
Can you please elaborate more on the approach?
There are 3 cases: 1. Get 1 fountain with diamonds and 1 with coins, 2. Get both with coins, 3. Get both with diamonds.
Case 1 is easy: buy the most beautiful ones that you can afford.
For cases 2 and 3 you can use 2 separate segment trees: st[0 or 1][i] = most beautiful fountain that costs i coins (0) or diamonds (1). Iterate through all fountains. If you take fountain i, you have c — cost[i] coins left. Let this amount be x. Use range max query on first segment tree to find the most beautiful fountain whose cost is in the range 1...x and take the sum of current one's beauty and this one's. Then, store current fountain in the segtree. The same applies for diamonds, just use another segtree.
From each case you get a value, answer is the maximum of these. Be aware of the situations when you can't buy two fountains.
Observe that you can either pay with coins only, diamonds only or both.
Sort by Coins or Diamonds whatever the case and have a dp array such that dp[i] is the fountain with biggest beauty in the range [0..i].
We can use binary search for any of the cases.
In the last case, iterate through the coin array and use binary search on the corresponding Diamond array.
I think all three cases should produce a best value.
I was thinking about dp[i], but it can be that for some i1 and i2 that i1 + i2 <= d/c dp[i1] and dp[i2] will be the beauty of the same fountain, or did i misunderstood something?
There are three ways of purchasing two fountains:
In the first case, just consider, for every type, the maximum beauty among the fountains whose price is lower or equal to the number of coins of this type. Then, the maximum beauty is the sum of these two.
Then, sort fountains separately according to their price, and precompute for every fountain the maximum beauty with a fountain whose price is lower of equal than this fountain. Then move from most expensive fountain to cheapest one and update the answer if you can.
Complexity in O(nlog(n)).
I did not solve it but those who find segtree easier than bin search can try this for the cases coin+coin and diamond+diamond. For every cost x, maintain two values, the two maximum beauty available and call them b1 and b2. If there is only one, set b1 to -inf and if there is none, set b1 and b2 both to -inf. Now build a segtree over the costs and every leaf node stores the maximum beauty possible with the given cost. If you select a fountain with cost x, replace in segtree with the second maximum beauty and query the segtree. Repeat this for every possible cost.
No binary search needed. Since the maximum possible price is not that big, it can be solved as follows.
Let's compute fc[i] := (id1, id2) such that id1 is the index of the most beautiful fountain with the cost at most i coins, and id2 is the index of the second most beautiful fountains with the cost at most i coins.
Similarly, fd[i] := (id1, id2) such that id1 is the index of the most beautiful fountain with the cost at most i diamonds, and id2 is the index of the second most beautiful fountains with the cost at most i diamonds.
These two tables can be easily computed in O(n) starting from i = 1 (or O(n*log(n)) if someone is lazy) if you have fountains grouped initially by an exact price.
After that, the only thing to do is to combine the results considering all the cases: you pay only with coins for both, you pay only with diamonds for both, you pay with coins for one and with diamonds for the other.
I think it's awesome how computational geometry problems can be so conceptually simple and yet so hard to solve in contest time (ok probably because it was the last question too).
What's the solution for E? (I get the strange feeling that some sort of clever gradual refinement might somehow pass, since it is almost a linear programming question.)
Edit: seems like modified mincost maxflow might work...
Great contest I liked the problems very much...C was a little bit tedious tho.
How to solve D ?
:)
Since 2^18 > 1e5, you only need something like 60 items with best cost.
2^17 > 1e5 and 34 items total I believe.
I think so, but I hate tight bounds so I decided to take 55 elements :D
What is 4th testcase bro ? (for C question)
Sort the array a, and then try all possibilities by having last k elements in use? I used multiset array to store variantions of h and w, for some k and then go thru all of them in (k-1) array and try to multiply. As the multiplicator is at least 2 the multisets size might not explode :D
it doesnt get TLE ? :O
C was easy to code using BIT. Not at all tedious. code
ankububble can you please explain your concept behind your code .... thanks
Sure.
Let dp(i) denote the max beauty when you have to pick 2 fountains from first i fountains and you are selecting the ith fountain. When I am calculating dp(i) , I need to iterate over all j<i, and select the fountain that passes the budget and has the max beauty. This is O(n^2). BITs are used to speed this up.
I used BIT to compute prefix max. For fountain of price p and beauty b, I set bit[p] = b. To compute fountain with max beauty within price range <= K, we can take max from bit for prefix of length K.
Hope this helps. Have a good day!
solved
There are random t-shirts again, so we will use a similar algorithm to the one used several months ago. We have a pseudo-random generator based on testlib.h. The seed will be the winner score in the Tinkoff Cnallenge Final Round on Saturday. The printed integers are the winning places, the ties are broken by the time of last AC.
you use number_of_participants_with_positive_score while in announcement tshirt is for those who have at least one submission
Fixed!
Why do you use seed from the next contest?
So that no one can claim the system is rigged.
So winner score is 8876 and number_of_participants_made_at_least_one_submission is 3465,
I get these five numbers: 903 935 1552 1591 2272
If I am correct then the T-shirts go to Acarus Xris MashiroSky orz010orz Abuccts
The seed is 8876, the
number_of_participants_made_at_least_one_submissionis 3465. So the winners areCongratulations!
I need help in Problem D.
I need to solve this Subproblem.
Given an array A = [a1, a2, a3, ..., an] and an Integer X.
Get a Sub Sequence B = [b1, b2, b3, ..., bm] from array A such that b1 * b2 * b3 * ... * bm is >= X and as minimum as possible.
Hint: Note that bi >= 2. So you need at most 17 elements to make their product > 10^5.
Hint2: Suppose you are kinking K numbers. You will sort them in descending order and pick the first K numbers.
Nice Trick :D Thank you.
Submitting problem A and passed pretest: YES! I did it! I'm the f**king genius! Let's check the dashboard. WTF?! tourist solved problem E already?
We know he is a legend :) But he solved E after 41 minutes while you solved A after 22 minutes.
22 minutes: Submitted. 22 minutes ~ about 26 minutes: In queue. I checked dashboard: he got '-1' on problem E So, you're right. It should be 'He has submitted problem E already' exactly.
Due to technical reasons the system testing and the rating update will probably be delayed a bit.
Why people vote this comment ://////
my question too ... !
because he is the codeforces co-ordinator.
I think you should better look the message than the writer of it:/
Because he is informing the community so most people don't start expecting immediate system testing. This in my opinion is a respectful thing to do.
systesting started fairly fast...guess rating change is going to be a bitch.
I removed cheaters and recalculated the ratings.
When will the (random) tshirt winners be announced? MikeMirzayanov
Hi:
I understand that the contest is finished, but is there a way to still submit my code, just to test for myself..?
Cheers
Usually the problems will be added to the problemset, you can upsolve them there
After system test finishes
You can upsolve after system testing.
The contest is over but I am not able to see the submissions of other users. Why is it so?
For C, I separated coins and diamonds. Applied knapsack on both of them individually. Then I just checked the maximum 2 values that can be generated taking care of if 2 fountains cannot be generated. Is this method wrong?
TLE and MLE Unless you did one hell of an optimization.
Thank You. I missed to consider memory limit completely.
there are 3 choices :
1) 1 cois + 1 diamond
2) 2 coins
3) 2 diamonds
the first is easy , the second and the third are the same
you have a vector of pair for each type { price , beauty } sorted in ascending order
try the first fountain to be v[i] with price p1 and you have coins-p1 left
the second one will be from range [ 0 , min(i-1, upper_bound(coins-p1)-1 ) ]
now take the one with max beauty ( precalculation )
something like that ...
Thank you for your help :)
In some last minutes, I used brute force way with
O(n^2)for problem C and passed the pretest. So the pretest is weak and it is the chance for some cheater who passing it by this way, then open other solution in the same room to find the "real" solution.Well, it doesn't make a difference, does it? He/She cannot resubmit his/her solution. And it was more or less obvious from the constraints that an O(n^2) solution would time out, so he didn't necessarily have to look at an optimal solution to figure that out.
Someone can have fake account and see others' solution with locking in fake account, then write in his real account.
That can also be done if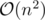 doesn't pass pretests...
doesn't pass pretests...
Yes but then it requires solution that passes pretests with intended complexity. This is harder, thus making cheating harder, which is a good thing.
How do you think XD
Why was the memory limit so tight in C? I got memory limit exceeded with only 2 segment trees and total memory of around 12 * 105. My contest got ruined because of this :(
By the way, how much memory can I declare when 256 MB is the limit?
Edit: Nevermind, memory limit wasn't tight. I'm just stupid.
I have the same problem )=
No there will be a different issue. 12*10^5 easily fits 256 MB.
I got same error, the problem was in my build function, say if count of 'C' is zero, u shld take care of this in ur build(1,1,count(C)) in the segment tree for C(Coins)
Oh god! I think you're right! I'm so stupid -_-
Yes. That's it. I wasted the entire contest on that. Lesson learned I guess.
Your contest got ruined because you are used to use segment trees everywhere, even if there is much simpler solution.
Nothing wrong in that :P. segment trees is not "complex"
Hats off for strong pretests. Update: I meant in D mainly, and I didn't see many hacks in general.
lol
Someone know why MLE here http://mirror.codeforces.com/contest/799/submission/27036789 I only use 10^6 integers or where am I wrong?
You can't see others' submissions before systest. Can you pastebin it?
Sure, it's a little ugly
...
Were there pretest on D that needed rotation before answering? Its sad that after trying optimization to fit into tle , i forgot this part and now i will get WA...
I don't undertstandAbout my memory
MX=1e5;two (int,int)[4 * MX] = 2*4*4*4*MX = 128*MXtwo int MX = 2*MXall 128 * MX + 2 * MX = 130 * MXI think int array[1e6] = 4 MegabyteI tnink**** **** **** ******My memory about 50 Megabyte + (void with other) <= 256 Megabyte**Why memory limit? 27037536
...
How to solve A? xd
We can iterate through time and compute the number of cakes that we can do in that time.
I solved it like this: First, I calculated time needed for oven 1 to bake all the cakes. t1 = ceil(n/k)*t
Then I do t1 — t which is the time the last batch of cakes were put in the oven. If it is less than equal to d, there is no need to build another oven.
if (d // t) * k + k >= n then answer is NO, else answer is YES
Can someone tell me why my approach for C is wrong?
First, I try to match 1 fountain of C with 1 fountain of D. In that case it will be the most beautiful of each one that I can afford. The other case is to get 2 fountains of C or 2 fountains of D.
So I sort them by cost, and build a segment tree of maximum beauty within range. Then, for each fountain, I take its cost and binary search the most expensive fountain that I can afford (which will give me an index j in the array the segment tree was based on). Then I just query the segment tree for the range (i+1, j). Then take the maximum of every iteration on both types.
Code: https://ghostbin.com/paste/ogevq
Wrong Answer on pretest 4.
What if the fountain of maximum beauty lays in the range from (0,i-1) ? It doesn't look like you account for that
well, then it would have been found on an early iteration. I always take the fountain i with the fountain returned by the query. If the best fountain to pair with i (let's call it j) is before i itself, then in the iteration of j the query would have returned i.
Why aren't others solutions visible?
Just wish I am lucky enough to get a T-shirt, please :)
Any help in B please?
here's my code it's long but very easy to understand.
Note: SF(x) means scanf("%d", &x)
Code
:)
I used set of tuples: (color1, price, color2). It contained each t-shirt twice: (front, price, back) and (back, price, front). So on queries i choose the cheapest t-shirt of given color using upper_bound and erase it from set twice( (front, price, back) and (back, price, front) ). If there's no t-shirts of such color, answer is -1.
My solution: http://mirror.codeforces.com/contest/799/submission/27022263
Short solution : code
I solved B using set in O(mlogn) but my solution didn't care about number of colours, though it was limited to 3. So now I wonder whether it can be solved in linear time or not?
Great contest!
it's just the opposite
Why WA11 on E? Can somebody help me?
Is the general solution to fit some 'both like' decorations + minheap on the rest of the decorations?
Why TLE on B 27019672. As far as i know the erase function returns number of elements deleted.
Because of erase works really slow and you call it many times!!
Who can solve B faster than me? (249 msec)
Can you explain more ,I mean erase should be log(n) and in worst case , I was erasing 3*200000*log(600000)=1.2*10^7 operations which should have worked right?
It's because you use set which for some reason it is much slower, maybe someone else can explain that.
same code AC using set http://mirror.codeforces.com/contest/799/submission/27041754
Can you tell me why one passed and the other didn't 27045354 and 27019672
My solution to problem C got WA because I was comparing a price with a beauty by mistake, the idea was to compare two beauties. After the contest I fixed that and I got AC. How could the first solution have passed the damn pretests!?
WA on 27 in D. ARGHHHHH!
Probably failure to consider rectangle rotation? I also WAed 27 of D by forgetting to swap variables: "if ((curr >= a && area/curr >= b) || (curr >= a && area/curr >= b))"
The Magic returns again Random_shuffle (: http://mirror.codeforces.com/contest/799/submission/27038984
Sometimes I think maybe try random but never have enough confidence to really try it
I believe this shit is the reason of KAN's comment about that the results are not final :D
So weak pretest on C. Jesus, there was only 10 tests and all of them were soooo simple. Nice trap)
Problem B-: link-: http://mirror.codeforces.com/contest/799/submission/27030194
Can any one please have a look at my code it gives Runtime error on pretest 9 ??. i can't figure it out why..??
You should store (*it) in a variable then delete it from various sets. Consider x=1 and v[1].size()=1. You first delete it then use (*it) for i=2, and i=3 which is invalid and cause run-time error.
You know you are legendary when you fail E on system tests but you are still the first
27040141
this submission should get wrong ans
printing -1 for this case
100000 100000 1 1 4
99999 99999 99999 99999
c 27040159
what is the problem with this?
The results (and rating change) are not final yet, the final results will be within several hours.
What's the problem?
Cheaters were removed.
seems nothing changed
My rating was 1538 and now 1537.
what is problem of this code
First thing to do when you get RTE: Check the arrays bounds!!
Hey I was also getting runtime error on Case 9 this but as soon as I did del = *it and then used this del to erase then it got passed this but I am unable to understand why this is so ??
Why they made pretest in D so that you don't need to swap(a, b) in no way ant it still passes pretests, when after real tests it fails :/ My solution
D was such an amazing problem indeed
I guess my solution is a bit odd but it takes 78ms to finish
My idea was to deal with the easiest two cases separately, that's when the answer is 0 or 1
For the general case:
We are told that the smallest ai value is not less than 2, which means that in worst case we need 17 elements for each side a = b = 100, 000, w = h = 1, n = 100, 000, that's 34 elements at most, cool isn't it
Well that number 34 makes it seems like it's dynamic programming with bitmasking, hmmm maybe but I couldn't utilize this fact much
Anyway let's take a look at the worst case, we have 34 elements and we need to choose a subset of these numbers, multiply them together with one of sides, then multiply the complements of said subset with the other side and check if we can enclose an a * b inside
But 34 is a big number, I would gladly do something like that if it was something like 17, but hey, what if split it into 2 halves, each of which is at most 17 elements, that's 217 subsets -- we can sort the second one in descending order and then loop over each subset in the first half, for each one I want to find the best match in the second sorted half, we may add with each subset the value of its compliment, do something like partial sums over them such that subcomplement[i] = Maxi: subcomplement[0..i]
Now we can do for each subset in first half a binary search over the range of subsets, if we can satisfy:
w * subleft[i] * subright[l...r] > = a and check if h * subleftcomplement[i] * subrightcomplement[r] > = b or when w,h are swapped and a,b are swapped i.e. four cases then there is a solution using 34 elements
We can try to reduce the count to the half and repeat the process around log2(34) times
Basically we are doing binary search over answer (count) and using meet in the middle technique to check it quickly
Not so sure about the big-O though, may be O(2m / 2 * log2(2m / 2) * log2(m)) and m < = 34
Anyway here is the link
27042867(Submission link)
I believe the expected solution was along these lines. I was trying to do something similar during the contest time. However, I am still not sure how many people got a simple bfs like solution to pass this constrains. It seems like they are actually exploring a tree with a branching factor of 2 (either multiply the current number to w o h) and the shallowest solution can be upto depth 34. Obviously many branches can be easily pruned but why was this optimization so significant?
For a fixed set of extensions, let the final area of the field after applying all of them be A. Then if A/(a*b) > 100000, there must be a solution (Consider moving field extensions from the width to the height 1 at a time).
So A < 1e15. Notice that all states we have are divisors of A, and that no number below 1e15 has too many factors (cannot remember how many, but it's way way less than 2^30). Thus pruning is very effective.
Wont there be multiple states corresponding to one divisor of A.Could ou please elaborate on the proof.
This is similar to the knapsack problem https://en.wikipedia.org/wiki/Knapsack_problem. Here the value and weights are the same. Consider the following solution:
Number the items 1 to n. Consider the set S={0}. For 1 to n, do:
Update S' to be S union {S*w_i}. That is, we add to the set S the new possible values that we could form with items up to n. To do this, we just need to add at most |S| values, i.e. the size of the already existing set. The pruning of repeated values keep the size of |S| small.
If |S| is bounded by 100000, then we require at most 100000 operations per iteration of the for loop, which is still a lot less than 2^30, and hence runs in time.
I have done the same. Forgot to swap h, w and perform it again. I used set for those 34 elements. When for a particular mask, I select some of those 34 elements, I remove them from mask and give it to h, then to make w >= b, I greedily reverse iterate on the set till I make w>=b. code
I also thought subsets are 2 power 34 . So dynamic programming might time out. But if u observe states are not distinct unless all a[i] are distinct . The states will keep repeating(and 17 is possible only if all a[i] are two). So as 10! is less than 10^5 . Total states will be around 2^20 or so (this is just intuitive). So this is the reason why dp works
Problem C, any case just as test 4 but simpler ?
UPD: AC .. sorry for inconvenience.
How to solve problem E? Thanks.
Denote set of decorations liked by both to be A, set liked by Arkady only to be B, set liked by Masha only to be C, and set liked by neither to be D. Sort these sets in ascending order by cost and keep their prefix sums.
We fix the number of decorations we pick from set A to be x. Then we need at least (k-x) items from set B and set C, and (m-x-2*(k-x)) (call this number KK) remaining items from any set. The (k-x) items from set B and C we can just optimally pick the cheapest items. For the rest, we need to pick the cheapest KK items from any of the sets B,C,and D. Call this final optimal set of KK items to be S. We can binary search for the maximum value M in S (look for the minimum M such that the number of items <= to M in sets B,C,D sum up to more than KK). To do this for each set B,C,D we binary search again for number of items less than M and sum them up. If the minimum such M gives us L items that are <= M, then we subtract (L-K)*M from the prefix sum since all the over-counted items will have cost M.
Loop through all possible values of x (0 to |A|) and get optimum answer.
I had a similar idea.But I saw many people solve it with segment tree. Can someone elaborate on that?
After fixing x, we are trying to solve the following problem:
Find sum of z cheapest items in the union of the following arrays:
We can keep a segment tree to tell us this quantity. Note that as x increases, we keep looking at larger suffixes of B and C, so we can keep two pointers for B and C and maintain all the candidate values in a segment tree, and report the optimal sum in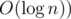 .
.
Ugly Code
By the way, did anyone else think that problems A-E were sort of standard logically, and focused more toward implementation? I think there is a huge jump in difficulty from E to F. E isn't really difficult to solve on paper but tricky to code quickly..
Thanks a lot for the help!
I think this problem can be done greedily by using 2 min heaps and 1 max heap. In one heap we will keep all the decorations with weight(cost) for common to both and 2*weight for dec that is liked by exactly one.Second heap for minimum common decoration not yet picked(after all buckets are filled).Third for costliest decoration(belonging to exactly one) which has been picked.If we've not filled all the m decorations we remove from third heap and insert from second one.
B.Submitted
Can anyone say why my source code takes 280ms (in n=1.0*10^5) and takes over 3000ms in n=2.0*10^5)? I think it's time complexity is O((m+n)logn)... I guess why the program works slowly is that I used std::deque...?
cf) I used struct to save p,a,b and saved that structs(t-shirts) at the deque(one,two,three) and sorted and when the buyer want to buy t-shirts, I used "pop_front" and "erase" to erase one t-shirts.. I think "erase" is cause of TLE...
please help me
I guess that your idea may be right.
Complexity Linear on the number of elements erased (destructions). Plus, depending on the particular library implemention, up to an additional linear time on the number of elements between position and one of the ends of the deque.
quote from:deque::erase
I think the final tests for C are too weak. I got AC in the contest 27031840 , but now I realize that I made some mistakes when I decided to reduce the execution time. ex.it will WA on the data below
Now I have fixed the mistakes.27044385 [If you guys can find other mistakes, please tell me. thx!]
Sorry for my poor English.XD
Problem D is also solvable with Meet-In-The-Middle.
Here is my code 27046475
When will the editorial be available?
when will the random 5 participant who get tshirt be posted .
When will be the editorial uploaded?
for problem C
is it ok to sort by bi/qi and then use binary search?
i did that, sorted by bi then binary searched over bi.
i mean sort on (bi/qi)(devide :D)
No, you can't. Cause worst case is O(n^2), like you picked most quality thing, now you have only 5 c it doesn't mean, what you should buy most expensive thing, cause it can have lower quality then cheap. Sry for me english)
I meant that the binary search is useless in this situation
What is the intended solution in F? I've accepted solution with no more than 24n queries to the segment tree in upsolving but had some troubles fitting it in time limit. I've seen some solutions without this data structure, maybe someone can share his approach?
I've posted the problem analysis. My code is 27058630, it uses no more than 2m + 6n queries to segment tree.
MikeMirzayanov KAN, When will you announce the five random T-shirt winners ?
Obviously, after Tinkoff Challenge Round.
Why so serious? My corrently account is sina-ss you send me whats your problem
My corrently account is sina-ss you send me whats your problem
What are your mistakes in solutions to B?
if(n == 123) puts("LOL");
The cheating idea was shared a few days ago by a person who had 20 account in top 30.
feeder
I have seen solutions of C using fenwick tree( also called Binary Indexed Tree or BIT) such as this one : (http://mirror.codeforces.com/contest/799/submission/27019364) Can somebody explain this ?