


Two years ago, the Codeforces rating system was changed significantly. The system is published here.
Let's take a close look at the formula:
- We compute seedi from old rating, so it corresponds to the performances of all old contests.
- mi is the mean of seedi and actual place. Roughly speaking, 50% of it comes from old contests and 50% comes from the most recent contest.
- R corresponds to mi. 50% of it comes from old contests and 50% comes from the most recent contest.
- The new rating is ri + di = (ri + R) / 2. 25% comes from the most recent contest and 75% comes from others.
I prefer smaller rating changes in a single contest, at least for negative direction. Some reasons are:
Why do you put 25% weight on the most recent contest, even for experienced contestants (say, 100+ contests)? However, I agree that if the weight is smaller, it is too time-consuming to raise the rating for newcomers, which can be frustrating. In Glicko (an improved version of Elo), you are assigned a value called RD. This value represents how inaccurate your rating is, and when RD is small, your rating change is smaller. You start from a very high RD, and if you keep competing, this value gradually decreases.
It is possible that someone suddenly becomes stronger in a short period of time. However, the opposite is not true. Yes, if you don't practice, you may gradually decline, but this is much slower. When someone gets very bad performance, it is natural to think that it was because of a bad luck, not because of actual strength.
It is simply demotivating to lose way too much rating because of a single failure.
It seems there was "rating cap" in the old system. For example look at this. His rating changes in #270 and #318 were roughly the same.
What do you think?
UPD. Suggestion for the new formula.
I think slight modification is enough. In the current system, we use
di = (R - ri) / 2
Change it to
di = f(k)·(R - ri)
where k is the number of contests you've participated (so, k = 0 for newcomers).
I suggest f(∞) = 1 / 5, and to compensate that f(0) should be a bit bigger. One possible explicit formula is:
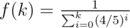







Another point that I'd like to add is that in some contests we have a very high concentration of contestants in short intervals of score. If you take a look at Codeforces Round #429, from positions 200 to 400 we have a little more than 100 points of difference.
Although the difference of points between the 200th contestant and the 400th one were small, their difference in the ranking system will grant them very different rating changes.
I just wonder if there would be a way to weight not only the position in the final ranking, but also the score difference, in a way that in contests that we have some kinds of unbalance (some easy problems and some very hard ones), people with similar level of skill don't get much different rating changes.
Kinda orthogonal thing to this blog, but relevant to ratings systems in general: one may wonder "how can we tell whether new rating system is better than the other one?". In order to answer that question we should come up with a penalizer function for a rating system and the lower penalty the better system is. Current system assumes that if two user with ratings ri and rj compete, their winning probs should be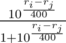 and
and 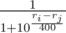 respectively. If n users compete in a contest then we should look at
respectively. If n users compete in a contest then we should look at 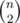 events corresponding to every pair of users (u, v) and if user u won and our model gave him a priori probability p of winning then we should add
events corresponding to every pair of users (u, v) and if user u won and our model gave him a priori probability p of winning then we should add 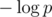 to penalty.
to penalty.
This looks like an interesting data science challenge, to produce a model optimized with respect to some penalty function. It should be possible to implement it using CF API, however I for sure would be too lazy to do it (to do it well I guess that sth like two weeks of work would be required?). But the bottomline is that instead of coming up with another way of magic formulas we can approach problem in a more robust and reliable way. This can be compared to creating a checker to an optimization problem and being able to easily test many ideas and tweak their parameters instead of producing just one solution and believing it is fine.
Some issues we should be aware of: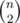 events are surely not independent. How that influences whole reasoning? Does that still hold up?
events are surely not independent. How that influences whole reasoning? Does that still hold up?
1) High rated users constitutes just a tiny portion of all users and maybe minimizing overall penalty leads to doing some weird shit for them? If yes, how we should prevent it? Add some weighting to users according to their rating?
2) These
3) In order to test it properly partition of data to train and test sets should be done and it should be random sample, not sth like "earlier half" and "later half" because if our model introduces something like rating inflation that may influence results. Should we partition events (user1, user2, contest) or contests as whole?
4) Take ties into account
It seems to me that the Glicko rating system is already optimized this way (see the initial paper, chapter 3.4). I believe there should already exist some paper that address this issue more directly, although I couldn't find any. Possibly misof can say more here, as he works on these topics.
My intuition is that if you define probability that ri beats rj then any rating system that converges to this probability will (at infinity) minimize the penalty. The only question is how well it converges (and also how well it handles that skills can change in time).
I believe that your issue (1) is relevant only if (2) holds. For just two people games (like chess) there seems to be no problem even with ELO, which is not the best one. (2) itself seems like a more serious issue though. I believe it's addressed in misof's thesis by considering user vs task instead of user vs user directly.
Smaller rating changes for the negative direction will cause 'rating inflation'. Btw, your thoughts somehow remind me the old Codechef rating system, it was awful. The difference between top and new user was > 30k (if I remembered), carl.
If red coder's performance was terrible, it means that there are easy problems which he is not used to solve. Also rating should be equal to his current skill level, not past skills. I don't think that CF needs new rating formula.
Needless to say, rating depends on performance of other coders as well as his.
I think you mix skill level and performance. If I solve a problem with probability 50% then this is my skill level. If I happen to solve just 1 of 5 problems on a single contest then it doesn't mean that my skill level dropped to 20% even though my performance was 20%. In fact, with 50% skill level there is 15% chance that I score 1/5.
To say that my skill level dropped, this has to happen in many contests in a row. The point is that it's quite unlikely because I may become slower (thus dropping to 45% overall) but won't forget how to code Dijkstra in one month. On the other hand, it is likely that I learn more and my skill level increase. That's why a performance drop is most likely just random while performance high might be both random or skill increase.
Do not forget that rating depends on other coder's skills(or performance) too
In a good rating system, my rating depends only on my skills. Others' skills come to the picture only when I want to know the rating difference.
The probability to solve a problem was obviously a simplification, problems have various difficulties. When I want to know my performance, I treat other contestants as a measure of contest difficulty (assuming that on average their performance equaled their skill) and use this to calculate my performance. This doesn't depend on any particular contestant's performance. This also doesn't matter if most of the participants had lower or higher rating than I did. The only thing needed is that there are many of them so that the difficulty measure is statistically valid.
I read this blog, and I found this blog is related to my blog. I think if rating change got smaller from negative, the distribution graph will change widely. I recommend that using code forces API and making distribution graph to simulate or using past contest data :)
I think the demotivating risk of rating change is the place that AtCoder win. AtCoder rating starts from 0, and his/her rating got nearer and nearer to the force. So there are less rating decreasing in AtCoder than TopCoder, especially the first 5 contest.
In addition, there are less rating change in AtCoder than Codeforces, both up and down. For example, there are few 100+ rating change for people who already participated 20+ rated contest.
So my idea is using AtCoder rating system generally, but if his/her success in the contest (for example, rating 1400 got 20th place in Div.2) the rating gain should be large value, as CodeForces. (I didn't say that I recommend, and this is only my opinion.)
I would like to offer another thought to this.
In chess, all the 'Master' titles, (more than the experts) are awarded for life. In other words, once you become a grand master, you remain a grand master no matter what your rating is. I would like it if CodeForces follows the same system. Your title should always remain the highest 'Master' title you have attained. However, a title of expert is not permanent.
Having the same title would cushion the blow of having ratings dip suddenly. What do you guys think ?
People would still judge you by your color.
I'm sorry but now the rating looks crazy...
http://mirror.codeforces.com/contests/with/yosupo
http://mirror.codeforces.com/contests/with/Petr
Which should be rated higher?
Definitely I think that codeforces rating changes too much based on recent contests (for experienced competitors). (Though congrats to yosupo on impressive recent perforomance.)
For example, people always say "I hope I do well on this contest so I get high rating", and even top competitors have changes of 100-200 rating in one contest. But in chess, no one talks about the effect of a person's most recent games on their rating. At most they will look at trends over time, and I think that's how it should be with ratings...
Auto comment: topic has been updated by rng_58 (previous revision, new revision, compare).