


Всем привет!
Мы рады сообщить, что 6 октября в 15-00 состоится очередной контест, подготовленный командой Samara SAU Teddy Bears.
Этот контест использовался для определения команд, которые будут выступать за Samara SAU в сезоне ACM ICPC 2012-2013. Контест будет несложный, видимо, немного попроще предыдущего нашего контеста.
Контест закончился! Спасибо всем, кто в нем участвовал. Теперь вы можете написать виртуальный контест (регистрация по этой ссылке), или просто дорешать задачи.
Что еще надо сказать:
Ввод-вывод: стандартный консольный (такой же, как в раундах Codeforces)
Пользователям GNU C++ не рекомендуется читать и выводить 64-битные числа с помощью %lld







Сделай ссылки относительными:
/team/212,
/gym/100030.
Иначе ты рискуешь перекинуть участника (например, меня) с http://www.codeforces.ru на http://codeforces.ru и напомнить о баге, что авторизация не сквозная
Это не баг
Категорически не согласен. Это баг, но легкообъяснимый. Я считаю, что codeforces.ru и codeforces.com — зеркала, отличающиеся языком по умолчанию и авторизировавшись на одном, я автоматически должен авторизиваться на другом. Не могу представить ситуацию, когда отсутствие такого — ожидаемое поведение.
А про codeforces.ru и www.codeforces.ru я вообще молчу.
Это был сарказм. Сорри что без смайлика
Почему так не любят %lld?
Бампище
Возможно ли будет начать эту тренировку в 16-00 виртуально? Например, тем, кто опоздает на час.
Нет, придется ждать окончания. Вопросы по этому поводу, как понимаете, не ко мне :)
а будут ли свеченые задачи?
на сколько сложный контест, примерно по сложности такой как региональные командные олимпиады в Самаре?
Скиньте условия. Ссылка не работает.
Ну вот зеркало на всякий: http://acm.ssau.ru/statements/000006.html
спасибо
Хороший контест. Как решать F и H?
В H легко показать, что нам достаточно знать размер самой большой кучки. Будем обозначать позицию через размер этой кучки. Тогда если позиция вида 2^k-1 (т.е. размер максимальной кучки 1, 3, 7...) — она проигрышная. Иначе мы своим ходом всегда можем поделить так, чтобы размер максимальной кучки стал проигрышным — и поэтому позиция выигрышная.
F. Допустим, у одной вершины в данный момент нет одного поддерева. Но мы знаем, какие значения могут придти в это поддерево, к тому же это интервал значений. Отсюда выходит решение: храним все пары интервалы+глубина в сете, и когда приходит новая вершина, то соответствующий интервал из сета удаляем, а вставляем два новых, которые на уровень глубже, а к ответу прибавляем глубину.
Непонятно, зачем хранить интервалы значений. Можно заметить, что при добавлении нового числа его предком будет или самое близкое "слева" число в дереве, или самое близкое "справа", причем выбор будет сделан в пользу более глубокого в дереве. А ответом для числа как раз будет глубина предка.
Поэтому хранить в сете можно пары <число, глубина>. На каждой итерации находить наименьшее число, больше нового, и наибольшее, меньше нового, можно с помощью встроенных операций сета.
А где-то можно увидеть стендинги с Самарского оффлайн контеста?
Вот тут, например
Ну так призраки есть. Галку "показывать неофиц" ткните.
Тогда призраки наоборот убираются.
смотря в каком состоянии перед этим был монитор
То есть? Открываю монитор, там все и галочка, убираю галочку, убираются призраки, нажимаю стрялR, страница перезагружается, показываются только участники без призраков, нажимаю галочку, появляются призраки вместе со всеми. Что значит смотря в каком состоянии?
Значит если сейчас их нет, они появляются, иначе убираются. Я предположил, что у него их в момент задания вопроса не было.
Понятно, я подумал что вопрос именно в том, чтобы посмотреть отдельно результаты онсайта. И я думаю, что этого функционала явно не хватает.
Как решалась D?
Решим обратную задачу: найти количество способов получить число N из 1, переходы осуществляются тогда не делением, а наоборот — умножением на какое-либо число.
Для этого найдем все делители числа N, это можно сделать за sqrt(N). Теперь посчитаем легкую динамику: dp[i] — количество способов добраться до числа i от 1. Для каждого делителя "влоб" будем перебирать все делители же, в которые мы можем из него можем перейти и обновлять для них ответ.
Так как делителей N порядка N ^ (1 / 3), то наша программа будет иметь время работы примерно O(sqrt(N) + N ^ (2 / 3)) = O(N ^ (2 / 3)), что прекрасно влазит по времени, также как и массив размера N по памяти.
Как Е — фальшивомонетчики решить?
(p*p+q*q)/(p+q)
а почему именно такая формула?
Вероятность равна сумме вероятностей двух событий. 1) Перед нами первая монета, и при следующем броске она упадет орлом 2) Перед нами вторая монета, и при следующем броске она упадет орлом
Первая вероятность равна (p/(p+q))*p. p/(p+q) — вероятность того, что перед нами первая монета; p — вероятность орла во втором броске на этой монете.
Аналогично вторая равна (q/(p+q))*q. Просуммировав, получаем указанную выше формулу.
Вероятность того, что в первый раз выпадет орёл — 0, 5p + 0, 5q. Вероятность того, что в первый раз выбрана первая монета и выпадет орёл — 0, 5·p. Известно, что в первый раз действительно выпал орёл, поэтому по формуле условной вероятности вероятность того, что выбрана первая монета —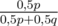 . Для второй монеты, соответственно, вероятность быть выбранной есть
. Для второй монеты, соответственно, вероятность быть выбранной есть 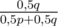 . Далее, если выбрана первая монета, то вероятность получить орёл при втором броске есть p, если вторая — q. Поэтому общая вероятность есть
. Далее, если выбрана первая монета, то вероятность получить орёл при втором броске есть p, если вторая — q. Поэтому общая вероятность есть
Thanks a lot to the following participants for their solutions of problem J:
You made my day :D
Treap?
Cartesian Tree!
Actually, the last one is Splay Tree o_O
Splay is not too hard, if you understand it. I think i did. Even with complexity analyse. Treap is common only in russia and close contries. Mostly they use AVL or RB, as far as i know. They both have same rotate as Splay. And this is the only hard place to code.
Cartesian tree ^_^
А как адекватно сделать I? Я делал бинпоск с мапами (правда с мапами упало по тл, пришлось делать с сетами, правда с сетами упало по тл, пришлось делать с приорити_куеуееееее).
Достаточно одной priority queue. Нетрудно понять, что в каждый момент времени выгодно выбирать самый дорогой экзамен. Отсюда решение: итерируемся по моментам времени, в каждый момент времени заносим в priority queue все экзамены, которые становятся доступны сейчас, а потом достаем самый дорогой. Так делаем, пока не обработаны все экзамены, или пока priority queue не пуста. Очень простое решение за N*log(N).
Блиииин. Точно. А я что-то сразу свёл задачу к такой: бинпоиском выбираем максимальную цену за экзамен, считаем для каждого экза время первого и последнего возможных дней, и далее пытаемся сдать все экзамены в соответствии с поставленными рамками.
у меня такое же решение, только я потом избавился от бинпоиска.
а именно: вот мы зафиксили какую то цену, получили кучу отрезков. и надо в каждом из них выбрать по точке, чтобы они не совпадали. решается довольно стандартной жадностью с сетом — сортим по правому концу и идем жадно справа налево. так вот, если где то что то не срослось — увеличиваем нашу макс. цену на 1. тогда все наши отрезки увеличатся на 1 и все уже выбранные точки можно сдвинуть вправо на 1. ну и так далее, пока не срастется. и после этого идти жадностью дальше как ни в чем не бывало)
я запускал это решение в 2 прохода — сначала считал суммарное количество увеличений макс. цены на 1, а потом вторым проходом уже находил точные положения точек.
Представим, что мы не сдавали экзамены, пока последний по хронологии экзамен не станет доступен. В этом случае у первого экзамена будет стоимость cost[1] + (day[n] — day[1]), у второго — cost[2] + (day[n] — day[2]) и т.д. Очевидно, что тогда оптимально будет сдавать экзамен с максимумом такой величины.
Но в каждой величине присутствует day[n], если мы его вычтем из каждого значения, порядок не поменяется. Значит мы нашли критерий сравнения двух экзаменов: cost[i] — day[i]. Чем выше этот показатель, тем раньше экзамен надо сдавать.
Теперь все вообще просто: считываем все экзамены, сортируем их также по дню начала, но при равенстве дней раньше ставим экзамен с большей стоимостью. Также будем хранить первый день, в который возможна сдача экзаменов.
Все, для решения все готово. Экзамены будем для простоты хранить в куче (heap, priority_queue). На каждом экзамене пытаемся сдать экзамены, уже находящиеся в куче, если возможный день их сдачи раньше дня открытия текущего экзамена. После этого пихаем в кучу текущий экзамен и переходим на следующую итерацию. В конце надо не забыть достать из кучи оставшиеся в ней экзамены.
Асимптотика решения, как видно, O(n * log(n) + n * log(n)) = O(n * log(n))
В задаче В — праздничный торт, надо было двумя указателями проходится?
Да
Ну если лень с ними возиться и хочется побыстрее получить Accepted, можно было сделать бинпоиск (так как разница площадей сначала одного знака, а потом другого), или вообще тернарник :D
А так, конечно, два указателя решают.
Я сделал тернарнк. Получилось весьма быстро.
Это невероятно. В задаче J я не подумал про список. Тогда, была, конечно, возможность писать дерамиду, но в голову пришёл один оффлайн изврат. Идея такая: пробегаем данные один раз и выясняем конечную позицию. Дальше запихнём в сет все позиции от 1 до сколько_будет_в_конце, и пойдём по входным данным назад: при insertLeft уберём из сета первую позицию левее текущей, и на неё в массиве запишем данное число; аналогично при insertRight; при moveLeft идём на первую позицию справа, которая есть в сете; moveRight аналогично, слева; если print, то запомним для него позицию. После этого пробежим по массиву, и в пустые ячейки запишем значения изначального массива. В конце концов идём по всем print и печатаем значения массива по запомненной соответствующей позиции. Кошмар.
Да-да, я также J на пустом месте усложнил http://mirror.codeforces.com/blog/entry/5409#comment-106890
Can someone explain me why the answer is Constantine in the first sample test in problem H?
Make sure that you don't miss the word "each" in the statement
Никого не удивляет, что победители сдали две задачи (E и J) одновременно с плюса на 53 минуте? Вообще разрешается участникам команды писать раунды за несколькими компьютерами?
На тренировках это формально не запрещено... Так что это вопрос, насколько сильно будет мучать совесть по этому поводу.
Кстати, во время контеста в онлайне был только один аккаунт из этой команды, другое дело, со скольки компов под ним одновременно сидели. Возможно, что они на самом деле играли с одного компьютера, две задачи подряд — такое все-таки бывает, а убирать из таблицы за такое — жалко. Тем более что когда-нибудь в этот контест придет vepifanov и наведет в нем порядок :D
I can't understand the sample I/O of problem E. I think the answer is (p + q) / 2,could you please tell me how to get the correct answer?
Probabilities of choosing the coins before and after the first throw are not equal.
It's an application of Bayes' theorem.
P(B | A) = P(A |^| B) / P(A) = (1/2 * p * p + 1/2 * q * q)/(1/2 * p + 1/2 * q)
P(B) = probability to get heads on the second throw, P(A) — probability to get heads on the first throw. P(A |^| B) — probability to get heads on both throws.
So P(B | A) is the probability to get heads on the second throw if we are given that we got heads on the first one.
I see, Thanks a lot! :)
How is getting a head second time after getting head on first throw a dependent event? Pls explain. Shouldn't both be independent events?
Задачи хорошие.
Кстати, учащиеся 11 класса — поступайте в СГАУ! Посмотрите, как у нас легко отобраться на соревнования ACM ICPC! Можно целых пять сезонов участвовать! Это вам не МГУ или СПбГУ или ИТМО, где некоторые команды оранжевых, а то и красных на NEERC никогда не попадали!
а у вас общаги дают?
Конечно! Все для участников ACM ICPC!
Я слышал, что у вас отчисляют :D
А я слышал, что пофиг ^_^
Ок, как к вам можно перевестись?
Как минимум, можно закончить бакалавриат в своем вузе, а потом поступить к нам в магистратуру. Перевод — это уже сложнее, подозреваю, что надо поискать на сайте универа, в частности, там есть такая пдфка. Ждем тебя в нашем любимом универе :)
Хорошо, мишки, не буду портить вам рекламу. Сегодня на вашей улице праздник. СГАУ — замечательный вуз. И очень радует, что вы многие свои локальные соревнования выкладываете в тренировки. Другие вузы, следуйте примеру :) Хотя то, что написано в предыдущей правке, не перестает быть правдой.
Согласен почти со всем. Хотя то, что написано в предыдущей правке, не перестает быть правдой :D
Ололо. Битва рекламистов. Я в магазин за попкорном...
UPD. Ну вот :(
Как и предыдущий контест, этот так же прошел на высоте. Спасибо за хорошую организацию и хороший проблемсет. Жаль что мы тупили в концовке.
Прорешал вчера контест виртуально. Несмотря на то, что задачи в-принципе легкие, E, F и H мне очень понравились.
Кстати, какое количество задач у вас считалось проходным?
Последняя прошедшая команда решила 9 задач. Кстати, это вроде бы легко выясняется...
Could someone give me the editorial for problems of this contest?
Pls explain the approach for Problem J — Product Innovation
Simulation using a linked list.
How to solve M
Go all vector saving the last occurrence of the value v [i] was in position i, and then for each current position look at it already existed an equal element earlier, if so, create an edge of the current position for this last occurrence. Just make a bfs or dp to find the shortest path.
How to solve problem H? I thought in grundy numbers, but I dont see independent stacks.
Why does this submission for problem A TLE Submission ,, is my HashSet causing this TLE?
Yes
How to solve this problem, then any hints?
Why isn't Grundy working for H? How to approach this one?