



Hi Codeforces!
The Codeforces Round #438 by Sberbank and Barcelona Bootcamp (Div. 1 + Div. 2 combined) is going to be held on 05 Oct at 9:05 (UTC+2)! The round will be rated for everyone.
This round is organised in collaboration with 2nd Hello Barcelona ACM ICPC Bootcamp 2017 and supported by Sberbank, the biggest commercial and investment bank of Central and Eastern Europe, with over 175 years of history.
150 students from 53 universities, including ITMO, University of New South Wales, St. Petersburg State University, MIPT, Ural Federal University, Tomsk State University, Novosibirsk State University, Saratov State University, Samara National Research, Perm State University, and many other top global universities such as USA’s highest placing team, Central Florida University, along with Canada’s University of Waterloo, high-scoring Asian teams from Hangzhou Dianzi and Singapore, and Tokyo University, as well as Stockholm’s KTH, will be competing as individuals for the online round, which includes those of you from Codeforces!
The past week has been full of intense competitions, job interviews with Sberbank, and contest analysis and lectures by Andrey Stankevich (andrewzta), Mike Mirzayanov (MikeMirzayanov), Gleb Evstropov (GlebsHP), Artem Vasilyev (VArtem) and Mikhail Tikhomirov (Endagorion).
The event is completely international, as teams from all parts of the globe compete and practice side-by-side. They say a picture is worth a thousand words, so here is a selection to give you some idea of what’s happening at our boot camp.















And, once again, we can’t wait to see you all compete on the international stage, smoothing the road towards the April World Finals in Beijing.
The round’s creators are Endagorion, ifsmirnov, zemen and Arterm — team MIPT Jinotega, two-time medalist ACM-ICPC World Final (2016-17). The round is combined for both divisions, will contain seven problems and last for three hours.
Good luck!
Scoring: 250-500-1000-1500-2250-2500-3500
UPD: Thanks for participating, glory to the winners!
We will publish the editorial as soon as the Barcelona Bootcamp activities conclude.
UPD2: the English editorial is here.







Oh Yeah!
I may be looking a little bit too optimistic, but in my point of view, this year is one of the best in part of real companies, education and internet community not competiting, but cooperating to fill our lives with the great feeling of solving good problems.
C Ya on the contest, ppl!
GL & HF
image 9/15: OSI model? I thought the lectures are about algorithms? :D
That was not a lecture, just some random presentation.
I have just read the anouncements and it seems like it's going to be the best round ever. 4 reds wrote this round and there will be 3 hours and div1+div2. I hope that tomorrow will participate more than 5000 people.
With so unusual start time? I don't think so. It would be really good if it wasn't at such unfortunate time. I know it's good for Asians, and it can't be always good for Europeans, but still...
Yes you are right. The competition will be tough bcause of the asians xdddd
Should I sleep before or after the contest?
before :D
I think I'm used to it. TAT
Had you slept during the contest ? That was not a good decision
Typical concern: will the drain be adjusted :)?
And please make differences between point values more geometric. The last problem should be worth a lot lot more than a middle one.
 )
)
Each Data Structure is Special :P
you can't just use rage comics in 2017.
2k17 actually
.
bad timing :(
Why this unusual time? :(
I don't think you used good meme. This fits better IMHO:
Sorry. It was my first time. Probably this tutorial from you will improve me.:)
Meanwhile the community (for you)
How about no?
Out of the recent Division 1 contests, more than half are longer than two hours:
*Round 434 was intended to be 2:00.
Personally, I like when an online contest takes at most two hours, be it a TopCoder SRM, a Codeforces Round, an AtCoder Round, etc. As they get longer, I'm usually unable to fully take part, and so have no love for them.
So, here goes: are there plans for shorter Codeforces Division 1 Rounds as well, for a change? An 1.5-hour experimental round sounds fun.
There are few things often associated with longer contests:
1) more tasks
2) merging divisions
3) harder tasks
4) not adjusted drain
5) bad scoring distribution
4) is always a tragedy, but easily fixable if coordinator cares.
5) is also bad, but this is a more controversial subject, discussed few times. I prefer sth like 250-500-750-1000-1500-2000-2500 and I do not like "standard" 500-1000-1500-2000-2500-3000-3500, because Div1A is worth 1500 and Div1D is worth 3000 pts whereas ratio should be higher than 2 times and if drain is not adjusted then probably submit to Div1D will be worth less than submit to Div1A.
I also do not like 2), I end up with mostly green/cyan guys in room and have nobody to hack on >=Div1B problem and there's nobody to hack my solutions if they contain a tricky case. Moreover if I do a stupid bug in some easy problem I lose a lot of points and I may end up in very far position losing more rating than appropriate.
I basically don't care about 1), but it is kinda a cause for 5) which I don't like.
And I like 3), but this is a rare case that we get more time because of harder tasks compared to reasons like "we wanted to merge divisions and added Div2 tasks to solve for Div1 users"
On the other hand, I actually like longer rounds because they allow me to worry less about working fast and take more time to think through things carefully :)
Any lecture videos available?
It's a typo, that is supposed to be #439.
Ah, at last, finally an early Asian contest for me to raise my ratings.
SILVER SCRAPEs STARTS PLAYING
(League of Legends Worlds starts today at 5 mins before as this round)
Hope problem statement is short... !!!
Unable to view submissions in my room after locking.
EDIT — Works fine in chrome
This is just a suggestion, please ignore if deemed unfit by you.
In longer contests, the points drain for problems is adjusted, which is ideal. However, shouldn't the penalty for a wrong submission be adjusted too? Usually, there are cases when one contestant submits his code after some other person, but still ends up with more points on that problem, because the other person has a wrong submission on the same problem. This makes sense if the difference in their submission times is not too large. However, in longer contests, like today's, the points drain is slower than usual, and hence, a wrong submission is actually far worse than it normally is. For example, there are cases when a person has got his solution passed much after some other person, but still has more points, owing to the other person's incorrect submission(s). All I am saying is that, there is far lesser incentive to finish off a problem quickly as compared to solving a problem in the first go.
PS. This is just a suggestion, and not a complaint or a rant. I wasn't even affected by this, I just happened to notice some others who had been.
RIP rating
Anyone else also did C using case-work ?
lol
Nah, this is just sad. :(
I really think that my one is worst
I did.. :p 31042120
That is the biggest submission i have ever seen.
Ha ha.. I tried every possible case. Took 40 minute to code.
How to solve D ??? I spent 2 hours on it alone :(
It seems that answer cannot exceed 8 but I couldn't proceed more from that.
really ? why the length of the strings can be very long (2 ^ m * 100)
When you combine two strings, you create at most K-1 new substrings of length K
You only need the first K and last K characters from every string where K is the maximum possible answer.
Hack cases for B and C?
B:
6 5 59 1 2, answer is NO
6 5 59 12 1, answer is YES
11 59 59 12 11, answer is YES
most frustrating is when you see a bunch of solutions using doubles, and you know they will fail system test but you don't want to hack them yourself because you know you won't be able to create a good test case to fail them
I'll admit that reading most B solutions was extremely painful, so I actually typed most of them out and just tested them against strong test cases. Now my hands really hurt and I think hacking should allow copy-paste :P
In all honesty I think a problem like B should have strong pretests because nobody likes hacking problems such as these :P
Why will double solutions fail?
I think most of them should fail simply because it's unreasonable to use double to check if two numbers are equal and expect the result to be correct a large portion of the time
what about long double
The general notion that one shouldn't compare doubles for equality is too vague, and doesn't apply probabilistically, since doubles work in a deterministic way.
In this problem, doubles don't seem like much of a problem. For one, distinct positions of clock hands are too far apart to compare wrong. Also, integers are stored with full precision as floating-point numbers, and dividing the same integer by the same constant produces the same result — unless the result is stored in different types (
doubleandlong double) due to, e.g., optimization.for first test case 6 5 59 1 2 doesn't that mean that the minute hand will coincide mesha's starting position?
No, it won't coincide because the minute hand will be between the 5th minute and the 6th minute, extremely close to the 6.
if input is
12 0 0 12 1, what is the answer 'Yes' or 'No'? and12 0 0 1 12I don't quite understand the meaning of the
step overIn problem statement it's guaranteed that one of the query hands won't coincide with any of the hour, minute, or second hands, so this test case is invalid. (In this case, the hour hand is exactly on the 12, so it coincides with the query)
oh. thx!
You should see my solution then.
For C:
Ans is YES
What about this test case?
NO
After I solved six problems, I realized the hardest problem(G) is unsolvable to me, so I started to hack other source codes. But when I attempted hacking, there was nothing but never-ending loading bar. Why there were problems although the server was working?
This is mostly related to the browser.
It happens to me on chrome regularly.
I use firefox for hacking and I haven't faced this issue.
Why use Flash even on the submitting form? After preparing the hack test, I had to waste some time waiting for the form to pop up.
Maybe it's to make harder to copy & paste solution(I think it's still possible with some ocr)
Of course you're right. But if that is only the case, I think using Flash only on showing codes is enough.
Why don't we want people to copy-paste solution :P
I think for problems such as B, it would be very beneficial to the sanity of most people to allow copy-pasting for hacking :P
Good day to you,
In my opinion hacking with copy-pase (vs.) hacking with "flash" might pretty different. Hacking flash is mostly about observation & finding a mistake (somewhere). If copy-paste would be allowed, one could easily create stress-tests and hack the solution without even looking at the code :)
Yes, this have some drawbacks, yet I guess this might be the main reason.
Good Luck & Have Beautiful Day! ^_^
Before system tests, it seems that 40 people solved E and 70 people solved F, yet only 14 people solved both. This is weird.
What's the idea behind G? We repeat making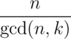 continuous sweeps and then work out the formulas?
continuous sweeps and then work out the formulas?
I think I solved the case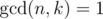 . Considered all n cyclic sweeps. I overlooked that when
. Considered all n cyclic sweeps. I overlooked that when 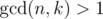 we can make less sweeps and realized it too late. :(
we can make less sweeps and realized it too late. :(
It's not like key difficulty of this problem lies in reducing to case gcd(n,k)=1 by dividing by common divisor and then there are just few simple formulas...
I think there is O(log(n)) solution, we should compute
sigma((i*n/k)/2^(i+1)) 0<=i<=k-1. this can be solved by Euclidean algorithm
Hey, could you elaborate? I don't see how to calculate that, and I also don't see how that suffices to solve the problem.
I don't think my D should pass, but it passed...
I think that in pretests operations did not create anything more than what was in original strings.
And it really passed system tests XD
Is it correct? 31024676
That's hilatious. Mine was about 10x as slow, long, and complex as yours and also passed.
http://mirror.codeforces.com/contest/868/submission/31028937
So seems like my solution is wrong, just change the maximum preserved length of string may result in wrong answer. I'm just lucky.
You can check here: 31053045 (change L to something else, my solution in contest equals L = 500)
Set it to 500, 550, 700, 1000, 567, 543, 510, 100000 will get AC.
However, set it to 400, 475, 499, 501, 600, 456, 511, 512, 10000 will get WA in various tests.
I need one more second to submit my solution for problem D...
Btw, is the solution just iterate the length from 1 to 15, brute-force all binary string of that length and check using DP?
I did the same and did for 1 to 10 only dont know will it pass systest or no
No need for dp — just brute everything.
What is upper bound on answer. I have taken 10 and it has passed pretest not sure about systest
I could prove it for 20 (still should work without TLE but couldn't code in time) but I think it could be smaller than that. There are at most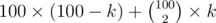 substrings of length k that can be made. Finding maximal k with 100 × (100 - k) + 100 × 99 × k ≥ 2k yielded k = 20 for my very approximate calculations.
substrings of length k that can be made. Finding maximal k with 100 × (100 - k) + 100 × 99 × k ≥ 2k yielded k = 20 for my very approximate calculations.
For 20 i think it will get tle as it will 100*2^20*log100
It's basically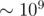 so it may pass, but very close to TLE without a lot of arithmetic optimizations.
so it may pass, but very close to TLE without a lot of arithmetic optimizations.
I just got myself a calculator and this analysis gives k = 17 as the greatest possible value.
For a fixed length k, there are at most 100 different substrings initially, and each move can add at most k new substrings, so we have 100 + k * 100 ≥ 2k, and so k ≤ 10 is enough.
Isn't it k ≤ 11?
For k = 11 the inequality doesn't hold.
oh, got it :)
I used 15. You cannot create more than k new substrings while merging two strings. So the max answer cannot exceed what we have at the beginning plus what we add (m * k), it's something like 20 000
Why can't we create more than k new substrings while merging two strings?
If we merge string s1 and string s2, new substring have to contain part of string s1 and string s2. So we can place it only on the k — 1 last positions of string s1 (otherwise it would be completely in string s1 or string s2). So we can't create more than k — 1 new substrings.
I've just got AC using 6 as upper bound (and I believe 6 is very easy to achieve so upper bound can't be less)
Tests to this task were very weak...
Why downvotes? I wasn't fu**ing with you guys. Post above + this prove that tests were weak.
What the heck ._.? Setters should get familiar with DeBruijn words. My bound was 12, but if I'm not mistaken we can get even 13 if concatenation of words on input is DeBruijn's word of order 13.
EDIT: Ahhh, I see that there was a limit of total length up to 100. My upper bound of 12 works. That makes it harder to construct cases, but 6 is still easily breakable.
Systest started.
Can someone explain the clear logic behind B problem. Also, if someone understands this submission 31012140 I_love_Tanya_Romanova
There are two possible paths from start to finish: clockwise and counterclockwise. For each hand I'm checking which of these two paths it blocks — it will block exactly one of them since it is guaranteed that start and finish are different from position of any hand.
There is a solution if and only if one of two paths is unblocked.
Could you tell me why considering only two problems set is enough (in Problem C)? Is it related to the range of k? If k = 20 then the solution does not work??
How to solve C ? [ Hope you pass System Tests ]
this problem C of today's contest looks like the type of problem where system tests totally crush the solutions..
People On Codeforces are good in Sense of humour
Consider 2 problems, which are exact same in terms of teams who know it. Adding both never make sense, hence we can consider only 1 occurrence of it. Now as there are only 4 maximum teams, there are only 16 different possible combination of question type.
Now consider all 216 possibilities of question set, and check validity.
code
I (and many others I know of) submitted a solution where we checked:
If there's a problem that no teams know, answer is YES.
If there is a pair of problems such that no team knows both of them, answer is YES.
Otherwise, answer is NO.
I haven't formally proved this, but it seemed very logical when I tried some smaller test cases, and it passed the system test. Does anybody have a proof of this?
I have one, but it's not pretty.
This is the only non-obvious part. Let's assume the previous cases are not true, but the answer is still YES.
If there is a problem that is known by exactly one team, all problems have to be known by it (otherwise we'd have answered YES in the previous step).
Now, all the problems are known by at least 2 teams. It follows that k=4 and we need to compose the problemset from problems that are known by exactly 2 teams (otherwise, the number of team-familiar problem pairs would be too large).
Now it's some case-ology to show that no such problemset can exist. W.l.o.g. let's assume two of the used problems are known by teams 1,2 and 1,3. Next one would have to be 1,4 or 2,3 — in both cases we cannot further expand the set.
Wow, that's a very elegant solution! how did you think of that,I was thinking of something a little greedy like but coudnt come up with something.. Please tell me your train of thought , how did you come up with this solution, Have you done problems using this technique earlier or it striked you during contest?! Anyways,brilliant technique!
It's not clear why adding both doesn't make sense, but I think that for k<=4 we can always find a solution of <=2 questions so in fact it is true, but I think your claim will become false if we allow bigger values of k
Yeah, here is a counter-example to the statement "size of answer <= 2" if we allow
k = 6:Each two distinct teams have a common known problem, but if we take all four, each problem is known by exactly two teams.
I can't figure out what's with
k = 5though.It's actually still true for k=5.
Assume there is a problem used on the test which is unknown to exactly three teams. (the four and five cases are easier.) Call them teams 0, 1, 2.
If some other problem is unknown by teams 3 and 4, then the answer is YES and we can use these two problems.
Otherwise, each of the other problems will have been seen by at least one of team 3 and 4. Then we cannot make a test where teams 3 and 4 have seen at most half the questions using the original question. (and we can remove it)
Why it never makes sense to add two same problems in terms of teams who know it? Maybe adding that problem will give us additional 0 to one team and ones to others which wont make problem.
You can prove that if the answer exists, the size of the subset of chosen problems is atmost 2.
Code
What is the problem subset in the following case:
4 4
1 0 0 1
1 1 0 0
0 1 1 0
0 0 1 1
I think we have to consider all four problems for a valid problem set.
Edit: Choosing (1st and 3rd) or (2nd and 4th) problem is sufficient
The first and the third problems are sufficient. No team will know more than 1 problem.
Oh Yes! Sorry. My bad.
any proof?
Lets convert the binary matrix into a vector of binary numbers and arrange them in increasing order of highest bit.
If the minimum maximum bit is 1, then the last team should know every problem.
If the minimum maximum bit is 2, then you can use inequalities.
If the minimum maximum bit is 3, then there is a balance between bit-4 and bit-3 which will be broken after cross-matching.
If the minimum maximum bit is 4, then team 1 knows every problem
when they do system testing manually...
how to solve B ? i have tried it but failed on test 56 (:
Then you did not solve it.
I just divided the clock into 12*60*60. Hour hand moves by 1 such unit every second. Minute hand moves by 12 such units every second. Second hand moves by 720 such units every second.
Then just compare these values with t1*3600 and t2*3600 and that's it.
Okay, just to be clear on this — so the whole question depends on the system being dynamic, not static right? Is that correct? My attempted solution tried finding opens paths in the clockwise and anti-clockwise directions consider the point in time in which t1 and t2 are considered. That worked for the sample cases, but failed miserably in the pretests.
Could you please go into a bit more detail about your logic? That would help us beginners a lot. Thanks!
Every second, all hands move in clockwise direction. In order to measure this precisely I divided the clock into 12*60*60 units (the total number of seconds in the whole turn on the clock — 60 seconds in minute * 60 minutes in hour * 12 hours in total). Now you can observe that with every second hour hand moves by one such unit. Minute hand completes the whole turn within an hour so you divide 12*60*60/60*60 = 12 units with every second. Second hand completes the whole turn within a minute, so you divide 12*60*60/60 = 720 units.
Once you scale the values, you have precise integer values of hands positions. You can then compare these values against t1 and t2 (you have to scale them too by *= 3600). The comparison is simple — just check if none of the hands block one way or another:
http://mirror.codeforces.com/contest/868/submission/31017176
Thank you so much for the explanation! It makes so much more sense now. The worst part is that it is a very simple concept as well, isn't it? I really must stop overthinking things. Thank you again for taking the time to lay it out so well — it really helped me understand the solution.
You're welcome. I'm glad I could help.
As regards simple concepts — that's almost always the case with short contests. I used to call these tasks tricky as they really require to get a trick — sometimes an observation, sometimes just restating the problem in a much simpler way, sometimes reducing to something simpler. I hope that finding such ideas will be easier with practice :)
You can divide clock like this guys said, but it wasnt necessary. I only converted hours to seconds: hours = 5*hours + minutes/60 + second/3600. and minutes to seconds: minutes = seconds/60 You must work with doubles,but suprisingly it wasnt problem, i got AC without having precision troubles.
Tests to D are very weak. My buggy code got accepted after the contest.
can you please explain this one also !
My code was checking initial values in strings and then was setting prefixes and sufixes only if the concatenated strings were remembered as whole strings. If they were not remembered as whole strings (it means their length was greater than 109) it just checked new strings on the concatenation of sufix and prefix of these strings and do not set new prefix and suffix. Which means that if this string will be concatenated in future, it will present empty prefix and sufix.
It fails this test:
BTW, it is also interesting that you could have stored all the generated strings up to 109 length and it would fit within memory limit: 254500 KB
Edit: I corrected that bug during the contest and lost 180 points. It showed up that it was not worth it. Very mean as usually when I do not notice such bugs my solutions fail and when I noticed them, they are not caught by systest...
Edit2: Test exceedes input size but you can get the idea of the problem. Submission: http://mirror.codeforces.com/contest/868/submission/31030570
Edit3: When I fixed the bug and I tried 109 upper_bound it exceeded memory limit but I'm pretty sure something around 90 would fit. Don't want to check it though.
B 46 test case: 10 50 59 9 10 is it ok ??? bcz in statement it i found Misha's position and the target time do not coincide with the position of any hand. so how it becomes a valid case ?
The hour and minute hands will be a bit ahead of 10, so it is a valid test case.
Sent same solution with other compiler and it got accepted.
The pretests seem too weak in D , I didn't memoize my DP hence my complexity should have been something like 2Q * (Something related to K) and Q was upto 100.
how to solve D?
Guys i dont get these statement with B problem...
4th pretest : 10 22 59 6 10 ANS = YES
Ok, there is a path between 6th hour and 10th hour, even if our point is directly on the hour hand we can get it
But 5th pretest : 3 1 13 12 3 ANS = NO
But why? Here there's the same situation in my opinion.. there is a path between 12th hour and 3rd hour, but we just have to go backwards and our point is also directly on the hour hand just like in 4th pretest...
why answers are different? cannot we go backwards? The task statement says that "he doesn't have to move forward only: in these circumstances time has no direction"
What do not i understand?
Because seconds hand is at 13, minute hand is little ahead of 1. Because minute hand is a little ahead of 1, hour hand is a little ahead of 3. Hence answer is NO.
Just imagine a clock. At exactly 3 o'clock the hour hand is at the position of 3. When one minute and 13 seconds has past, the hand is a bit further than position 3. So it is between 3 and 4.
How to solve F?
http://mirror.codeforces.com/blog/entry/8219 Divide and Conquer.
I too used Divide and conquer optimization but got TLE ... Can you check this once? 31025909
for(int i = m; i > cap + 1; i--){ tmp += arr[a[i]]; arr[a[i]]++; }
This makes your code O(n^2) for some case. Check the go function here to optimize it: http://mirror.codeforces.com/contest/868/submission/31021372
Why go function doesn't change the complexity of your solution?. I realized that D&Q could work but I couldn't come up with an idea to calculate the cost..
Let's see the movement of both pointers:
Right pointer: when it gets to [l, r], it comes from r + 1, goes to the mid, solves [l, mid — 1] ending in mid — 1, solves[mid + 1, r] ending in r (so when it comes back, it is in mid — 1 from the previous call). So for each range [l, r] it will move O((r — l) / 2). If you take the sum of every range it will be O(n*logn)
Left pointer: when it gets to [l, r] assume that it starts on optr, it will move on [optl, optr] to find the answer, move back to the optimum point, solve the left part (going back on the optimum point after the call), go back to the optr and solve the right part. So for every range you take the 2 * (optr — optl) and that's O(n*logn)
The idea is the same as parallel binary search for the complexity of moving the pointers.
Wow thanks, man. It's very clear now.
Isn't it similar to what we do in Mo's Algorithm?
It is but at the same time it isn't because the way you divide the queries you want the answer is:
online
not in buckets of size sqrt(n) for the left pointer
your
gofunction is awesome! you're so smartCan someone explain how to solve D?
Hey all,
In the contest, I got hacked by the following test case (Problem C — Qualifications Round):
The answer for this should be "YES", isn't it? Question 3 only has 2 teams which know the solution, and that is less than or equal to half of k=4. Am I missing something here? (The judge says that the correct answer is "NO").
Thanks!
You misunderstand problem.
The number of known problem for each team should be less than or equal to half of total number of problem in problem set.
For given example, total number of problem in problem set ( T ) is 1.
The second team know 1 problem, but this value is greater than T/2.
So given example is invalid.
Thanks for the reply, ainch96. I think there was some problem with the formatting — fixed it. The given example has
3problems with4teams in total. Can you please explain this test case (or have I interpreted your answer incorrectly?)I will give simple example for given test case.
For given problem A = {1,2,3} you can choose some of them.
Let assume that we get two problem S = {1,2} ( |S| = 2 )
Then, Team 1 know problem 1,2, Team 2 know problem 2, Team 3 know problem 1,2, Team 4 know problem 1
For this, Team 1 know 2 problem, which is greater than |S|/2. So this is invalid case.
For all nonempty problem set, {1},{2},{3},{1,2},{2,3},{1,3},{1,2,3} ,they are invalid. Get it?
Sorry for my English. I'm not the native, so i guess there are so many grammar error and word error.
Ahhh! Now I get it — stupid mistake from my side in understanding the problem. So, basically, the problem set size keeps changing depending on how many we are considering at one time, but I was checking against a fixed number (one of my several mistakes in this problem). Also, this explains why some solutions I had checked were enumerating subsets. Hmmm.
And, no, your English is absolutely topnotch. Thank you for the explanation! It helped a lot! :-)
Can anyone give me hint for problem E?
It's easy to see, that the criminals will hide at the leaf nodes. And so the policeman will catch each criminal at leaf nodes.
Perform dynamic programming: dp[c][v] = time to catch c criminals, if the policeman is currently at a leaf node v.
Is that enough? Computing these values is not trivial.
I get it with reading your code. Thanks so much.
Could you elaborate on the DP relations? What are the transitions from dp[c][v]? I tried exactly this state but the transitions got messy. :\
You can compute the value dp[c][v] using a binary search. Criminals want to be found as late as possible, therefore you look for the biggest time that is possible for the criminals to archive (using a good spreading).
Checking if a specific time >= M is possible, you simply place as many criminals as possible at each leaf, such that either choice of the policeman ends up in a time >= M. (placing x criminals at leaf u takes cost[v][u] + dp[c-x][u] time).
Here is my implementation: 31030667 (variable naming is quite messy, but I hope you get the idea)
Is bitmask dp required for solving C?
You can solve it just by brute force with bit. You don't have to use dp.
How to arrive at the maximum number K in the question D ???
I used such idea. For K you should get 2^K different substrings with length K. Let's denote that we have string S with L length.
Count of different substrings with length K for string with size L are equal L — K + 1.
Then we have next formula: 2^K <= L — K + 1 => 2^K + K — 1 <= L
maxL ~ 10^4 (each step you add string with size 100)
=> maxK ~ log2(10^4) ~ 14
Correct me, if I'm wrong.
MaxL isn't 10^4, each step you can add the last two strings, then maxL is 2^m
Yes, you are right it was my mistake)
can u please explain the whole solution?
Then, how do we get the upper limit for k ? According to your explanation, the maximum value of k can be 100.
How could snowy_smile solve pF in two minutes...?
submission history
They used at least 2 different templates. Not to mention Tabs vs Spaces.
31016987 31017265
Andrey Stankevich is the best teacher during the bootcamp, does anybody have any English lectures that are downloadable from him?
Is there a glitch, every unrated person is given a rating of 1378 (Even unsuccessful submissions ), please explain.
You will receive rating updates as long as you have made submissions during the contest, even if none of them are successful.
Just realized this when practicing problem E:
" the criminals can move with arbitrary large speed "
My brain during the contest: OH SHIT, ARBITARY SPEED SPECIFIED BY THE INPUT? NOPE NOPE NOPE NOPE NOPE JUMP TO F.
Jokes aside, is there anyway to solve the problem in decent complexity with a bounded velocity for the criminals?
Can anyone please tell me why my solution for C works. First of all I treat each problem as binary number. Then I push all the numbers into a vector a. Since there are at most 16 numbers so I just check if there are any numbers a[i]&a[j]==0. If exist then yes, if not then no. I don't know why I thought up such an idea but I can't find any case to disprove it. http://mirror.codeforces.com/contest/868/submission/31036399
I solved it with exactly the same method. I also want to know the proof.
When there is 0000 problem we have solution.
When we have 3 zeros problem we only have to have any task that '1 team' doesn't know. If there is none, we answer NO.
When all problems has at most 2 zeros we can't take 1 zero problem, because there can't be less zeros than ones globally in chosen problems.
When we have 0011&1100 or 0101&1010 or 0110&1001 we have solution. When we don't have any pair of that type, we can have at most one number from each pair, so 1, 2 or 3 of them. One won't work. When we take 2. problems, always one team will know all 2. When we take 3 problems always one team will know at least 2. So 0011&1100, 0101&1010, 0110&1001 are only solutions in that case.
So we accept when we have one pair from following numbers (+ column permutations)
0000 (this with itself makes zero)
0001 and xxx0
0011 and 1100
This works cause when correct problem choice is possible, there exists set fulfilling requirements with at most 2 problems. And a[i]&a[j]==0 does the same.
It makes sense~nice
Да Да
When will the editorial be published?
Never waited so long for the editorials.
Seems Barcelona Bootcamp activities are not getting concluded.
The wait is finally over :p
It's been 2 days...and still no tutorial...