


→ Pay attention
→ Streams
→ Top rated
| # | User | Rating |
|---|---|---|
| 1 | tourist | 3985 |
| 2 | jiangly | 3814 |
| 3 | jqdai0815 | 3682 |
| 4 | Benq | 3529 |
| 5 | orzdevinwang | 3526 |
| 6 | ksun48 | 3517 |
| 7 | Radewoosh | 3410 |
| 8 | hos.lyric | 3399 |
| 9 | ecnerwala | 3392 |
| 9 | Um_nik | 3392 |
→ Top contributors
| # | User | Contrib. |
|---|---|---|
| 1 | cry | 169 |
| 2 | maomao90 | 162 |
| 2 | Um_nik | 162 |
| 4 | atcoder_official | 161 |
| 5 | djm03178 | 158 |
| 6 | -is-this-fft- | 157 |
| 7 | adamant | 155 |
| 8 | awoo | 154 |
| 8 | Dominater069 | 154 |
| 10 | luogu_official | 151 |
→ Find user
→ Recent actions





Codeforces (c) Copyright 2010-2024 Mike Mirzayanov
The only programming contests Web 2.0 platform
Server time: Dec/23/2024 10:14:55 (l1).
Desktop version, switch to mobile version.
Supported by

OK, I will write here some of mnbvmar's observations with my tiny input. Since this will be rather long, this is more of a rough sketch rather than detailed analysis.
1) If two vertices have equal neighborhoods (in particular, they are not connected to each other), we can remove one. They can be detected using some hashing. From now on we assume our graphs have no such twins. This may sound silly, but we will use it later. Proof is by caseology.
2) We can forget about connectivity requirement. If we find a solution that doesn't fulfill it then it can be transformed to one that fulfills it unless D is empty and C is an independent set (or symetrically with A and B) which can't be the case because C would consist of twins. So in graphs without twins, existences of such partitions with or without connectivity requirement are equivalent and they can be transformed to each other, so these two problems are equally hard.
3) Assume we guessed an edge between A and C. Every vertex now can belong to only two out of four parts. We can express everything easily using 2SAT. However there are two problems. One is that we can't assign all vertices same value because that would result in a partition where one side has one vertex. Second problem is that it has O(n^2) clauses. Apparently both of these issues can be dealt with, but I don't know how.
4) Assume we guessed two vertices a1, a2 from A+B and c from C. We will solve problem in O(m) time. We initially put all other vertices into right (C+D) and start moving them from right to left (A+B) if they need to be on left. v needs to be on left part if it is connected to any of vertices from B or if it is connected to any vertex from A but not to all of them. If there are no more vertices that need to be moved we get a valid partition, unless c is the only remaining vertex on right. This can lead to O(nm) solution.
5) Assume we are given two vertices b from B and d from D. We will solve problem in O(m) time. Consider BFS tree from b and mark vertices on path from b to d, call it P. Let T(v) where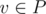 be a set of vertices u so that last vertex of P on path bu in that tree is v. In P there is exactly one edge ac going from A to C. Assume we guessed it. Then for all v < a we have that T(v) belongs to A+B and for all v > c we have that T(v) belong to D (where x < y means that x is before y on that path). If we guessed it we can merge T( < a) and T( > c) and solve it using algorithm from 4). We can try guessing that edge one by one. If done efficiently, every edge in this graph will be processed constant number of times in all executions of 4) algorithm for all guessed edges, because and edge is important only if it is adjacent to T(a) or T(c) what leads to O(m) solution (if we are given b and d). Maybe this algorithm also works if b is
be a set of vertices u so that last vertex of P on path bu in that tree is v. In P there is exactly one edge ac going from A to C. Assume we guessed it. Then for all v < a we have that T(v) belongs to A+B and for all v > c we have that T(v) belong to D (where x < y means that x is before y on that path). If we guessed it we can merge T( < a) and T( > c) and solve it using algorithm from 4). We can try guessing that edge one by one. If done efficiently, every edge in this graph will be processed constant number of times in all executions of 4) algorithm for all guessed edges, because and edge is important only if it is adjacent to T(a) or T(c) what leads to O(m) solution (if we are given b and d). Maybe this algorithm also works if b is 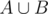 and
and 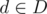 or even if
or even if 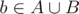 and
and 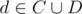 , this has not been investigated in details.
, this has not been investigated in details.
Hmm, I see now article that Lewin linked https://en.wikipedia.org/wiki/Split_(graph_theory). In fact really the only difference between these graph described here and ones in our problem is that connectivity requirement which we proved to be unimportant. Based on "Cunningham (1982) already showed that it is possible to find the split decomposition in polynomial time.[1] After subsequent improvements to the algorithm,[3][4] linear time algorithms were discovered by Dahlhaus (2000)[5] and Charbit, de Montgolfier & Raffinot (2012).[2]" what we need can be probably found in these papers...
EDIT: I made a quick look on two papers mentioned here and it looks like they are impossible to digest within one day or something. They do not try to find an arbitrary split, but construct whole split decomposition that fully defines structure of all splits in graph in some way. Such result is of course much more appealing, but of course also much harder and it doesn't seem like it is easy to extract getting an arbitrary split from them.
Wow, thanks a lot! I think from your comment, from Lewin's ideas in the blog comments and from Theorem 4 from the paper https://arxiv.org/ftp/arxiv/papers/0902/0902.1700.pdf linked from the Wiki page I can put together a O(n*polylog(n)) solution.
First, we run a bfs from an arbitrary vertex which we assume to be in A+B, and split vertices into layers. Now C will be a subset of some layer. Let's iterate which one, in decreasing order. Now we split the graph into: layers with smaller numbers — all those are definitely in A+B. Layers with larger numbers we split into connected components, and each such connected component is either completely in D or completely in A+B. We will initially have them as candidates for D and the incrementally mark as being definitely in A+B. For our layer, we will keep a color for each vertex, initially all colors are the same, with the invariant that all vertices of C must be of the same color.
We will maintain the following hash: sum of tags (random numbers) of vertices that are definitely in A+B, or are in the same layer and of different color, that are adjacent to this vertex.
While we can, we do two types of updates: - Take all pairs of vertices in our layer that are of the same color but have different hash, and make them of different color, updating the hashes correspondingly. - Take a connected component that is a candidate for D from bigger layers that is connected to two different colors in our layers, and move it definitively to A+B.
I claim that we can do all those updates in O(size(layer)*polylog) since we can maintain connected components in a DSU (hence decreasing order of layer), for each component maintain a multiset of adjacent colors, and always traverse the adjacency list of a smaller set of vertices being recolored.
After all updates are done, we end up with some coloring and some candidate components for D such that each such component is connected to exactly one color. Now if there's at least one such candidate component, then we can take this component and everything it's connected to between our layer and candidate components in bigger layers as our C+D. If there are no candidate components, we should check if there's at least one edge between two vertices of the same color in our layer, and if yes, we should take the corresponding connected component within our layer as C (with empty D).
The only thing that this solution is mishandling is the second layer: there our layer + all following layers have n-1 vertex (i.e. A+B definitively contains only one vertex, the source of our bfs), and all vertices of our layer have the same color — so if everything is connected we will try to take the entire n-1 vertices to C+D which is forbidden, while there might be a solution that takes a subset of those n-1 vertices. I hope this minor detail can be handled somehow :)
Do you think this will work?
I guess in the worst case we can handle the minor detail with an extra log factor if we pick a random bfs source and claim that a second random vertex is in A+B — this should succeed with probability at least 50%.
Actually no extra log factor required: first, suppose P is our bfs root, and Q and R are arbitrary vertices from the second layer. Then either Q is also in A+B, R is also in A+B, or Q and R are both in C+D so we can find this solution by using Q as root and putting R in A+B.
(in other words, we can find two vertices of the same half in any three vertices :))
Well, it's not so simple: we need two connected vertices in the same half, so both the random approach and the three vertices approach don't work, and the minor detail remains unresolved.
OK, so the minor problem can be solved using the ideas mentioned above: if we remove vertices with identical neighborhood, we don't have to care about connectivity, so the three vertices approach works fine (at least two will be in the same component).
However, I'm still getting TLE — I guess too much of Java's Map-to-HashSet :)
Try here, Java works much better on CF.
Thanks for the idea! Still TLE, although on a later test. Other tests with size 200000 work around 2.5s, so it looks like I need to speed up 2x or so.
But on CF I can copy the contest into a mashup and increase the TL, so now I know that it passes in 5.9s. My 2x estimate was super accurate :)
The complexity is O(nlogn).
Congratulations to aid on getting it accepted in the Prime contest itself!