


C 15 марта по 22 апреля Институт компьютерных технологий и информационной безопасности Южного федерального университета проводит II Открытый чемпионат Юга России по программированию.
В этом году в соревновательную программу Чемпионата входят шесть турниров:
Командный турнир по спортивному программированию (все желающие, команда из 2-3 чел., очный финал 22 апреля);
Турнир игровых стратегий Code Warriors Challenge (все желающие, команда из 2-3 чел.);
Турнир школьников (школьники 9-11 классов и студенты колледжей; победители и призеры турнира получают льготы при поступлении в ЮФУ);
Турнир Junior Contest (школьники не старше 9 класса, не имеющие серьезного опыта участия в олимпиадах по программированию);
Турнир по программированию на языке Scratch (школьники не старше 7 класса);
Личный турнир по спортивному программированию (для студентов ЮФУ).
Каждый турнир проводится в 2 этапа: отборочный онлайн-тур и очный финал в г. Таганроге (20-22 апреля).
В Чемпионате могут принимать участие все желающие из России и других стран, независимо от возраста, уровня образования, специальности, места работы и т.п. Участие в Чемпионате бесплатное для всех категорий участников.
Партнерами Чемпионата являются ведущие IT-компании Юга России.
Регистрация, расписание и другая информация доступны на сайте Чемпионата: www.contestsfedu.org
Отзывы о прошлогоднем чемпионате: http://mirror.codeforces.com/blog/entry/51716
Тренировка по задачам прошлого года: http://mirror.codeforces.com/gym/101364







Автокомментарий: текст был обновлен пользователем Seryi (предыдущая версия, новая версия, сравнить).
С Code game challenge в этом году, если честно, странновато поступили. Кто ж для такого формата отборочный этап вводит? =) (просто бы допустили всех тех, кто прошел отбор командного турнира). С другой стороны, получается, по сравнению с прошлым годом изменений в самой игрушке практически не будет?
Отбор для CWC — это в большей степени пробный тур для знакомства с движком, чем отсев. Но участников во всех турнирах суммарно очень много, поэтому жюри вынуждено формально ограничивать число финалистов и для CWC. Тем не менее, вангую, что мест хватит всем, кто зарегистрируется и сделает на отборе хоть что-то :)
По поводу движка и изменений в игрушке напишет один из авторов.
Все изменения игровой механики будут в финале, формат соревнований не изменится. В отборочном туре изменений не будет, за исключением того, что моделировать бои можно только со встроенными стратегиями.
А как просмотреть задачи отборочного тура предыдущего года ?
Сейчас тестирующая система с задачами прошлого года недоступна. Но ничего выдающегося в отборочных задачах нет — как правило, это 2-3 простые задачи + 2-3 задачи посложнее (часто из наших же контестов давних и не очень лет) из расчёта на решение большинства из них участником среднего уровня в течение 2-х дней.
Отбор в первую очередь делается для знакомства участников с тестирующей системой и отсева участников, для которых основной тур будет заведомо слишком сложным. Учитывая, что многие из прошедших отбор, впоследствии не приезжают, пройти отбор несложно.
Кстати, в этом году отбор и финал командного турнира впервые пройдут на Yandex.Contest, но все личные турниры пока останутся на собственной системе тестирования.
Ясно! Надеюсь задачи будут интересными :) !
В Yandex.Contest сейчас почему-то Java медленно работает — даже решения за линию с маленькой константой занимают по 200мс, и на многих задачах приходится переписывать на плюсы (пару раз десятикратный прирост скорости получался после переписывания). На кф с этим все хорошо. У всех такая проблема, или только у нас?
На Oracle Java 7 x32 Ваше решение F проходит c запасом, на Java 8 и Java 7 — TLE. Видимо стоит всем участникам рекомендовать во избежание проблем отправлять именно на него.
Спасибо! не знали)
Как решать F?
надо писать после контеста,например сейчас.
Я прекрасно понимаю Ваш отрицательный отсыл к моему комментарию, и я ни в коем случае не пытаюсь оправдать себя, но все же объясню, почему во время тура задал вопрос: 1) Да, этот пункт звучит не убедительно, но я задал вопрос за 10 (!) минут до конца тура, и физически не успел бы "сфальшивить", написав решение. 2) Этот вопрос я задал поздно ночью, в расчете на то, что, когда проснусь утром, то прочту идею решения/решение, и начну свой день с мыслями об этой задаче, что, например, лично для меня важно, если пытаюсь что-либо дорешивать :)
Если ты про командную, то вот наше:
Заметим, что два пути пересекаются, если нижняя из самых верхних вершин путей (lca) лежит на обоих путях. Тогда решим задачу о том, сколько путей пересекаются, используя этот факт, а потом из общего количества путей в дереве вычтем это число и получим ответ.
Тогда сначала найдём lca всех путей. Теперь надо для каждого пути посчитать, сколько же lca лежит на его пути (как это сделать опишу в конце). Из этого числа надо вычесть единицу, чтобы не считать свой собственный lca. Это и будет количество путей, пересекающих текущий.
Теперь мы могли посчитать какие-то пути дважды. Это происходит в случае, если lca двух путей совпадают. Тогда пройдёмся по всем вершинам, пускай количество путей, у которых lca находится в текущей вершине — это
count, тогда вычтем из общего количества пересечений величинуcount * (count - 1) / 2. Всё, осталось вычесть из общего количества путей найденное число и получим ответ, то естьanswer = PATHS * (PATHS - 1) / 2 - intersections.Для того, чтобы считать количество вершин на пути, можно использовать такую структуру данных, как
Heavy-Light Decomposition, которая позволяет узнавать сумму на пути в дереве заlog(TREE_SIZE). В нашей HLD значением в вершине будет количество путей, у которых lca находится в ней. Внутри HLD мы использовали дерево фенвика, так как все необходимые операции для создания HLD и запросов на ней — это добавление в элементе и запрос на отрезке. Также с помощью HLD можно находить lca, так что не придётся строить никаких дополнительных структур для этого.Итоговая сложность решения
O(TREE_SIZE + PATHS * log(TREE_SIZE)). При этом, наше решение на яве отработало дольше, чем за0.8 секунд, тогда как ограничение по времени было в1 секунду, так что писать нужно аккуратно, иначе можно запросто влететь по времени.P.S.: Хотелось бы призвать сюда Артёма temich Носова, может у него есть более интересное решение.
P.S.2: Код.
А как вы решали E?
Для начала поймём, как движется линия, проходящая через нас и через машину. Увидим, что как бы машина не двигалась, точка пересечения этой линии с координатой
y=0(там, где стоят колонны), с течением времени движется равномерно.Также учтём, что ответом на задачу является сумма ответов для каждой машины по отдельности, так что будем решать задачу для каждой машины и потом просто сложим результаты.
Допустим, машины движутся со скоростью
carVelocityпо координатеy=carY.Для того, чтобы посчитать, на какой координате X на линии
y=0находится машина, которая начала своё движение в координатеX=carStartв момент времениtime, нужно воспользоваться формулойtime + (carStart+carVelocity*time)/(carY+1).С помощью этой формулы можно посчитать координату, на которой начнётся и закончится путь на прямой
y=0. Собственно, задача свелась к тому, чтобы, зная координату начала и конца движения по прямойy=0, вычислить, какое время на этой прямой не было колонны.Для того, чтобы решить эту задачу, воспользуемся методом сканирующей прямой. Будут события четырёх типов:
- Колонна началась
- Колонна закончилась
- Отрезок начался
- Отрезок закончился
Событий последних двух типов будет всего два и только они будут изменяться при изменении машины. Тогда создадим массив событий наCOLUMNS*2+2элемента, каждый элемент которого хранит тип и координату. Элементы типов 3 и 4 будут в начале подсчёта для машины добавляться в массив и конце удаляться, остальные элементы лучше добавить в массив перед обработкой какой-либо машины. Для сканирующей прямой необходимо, чтобы события шли в определённом порядке. У нас этот порядок определяется координатой события. Так как колонны даются в отсортированном виде, можно каждый раз при изменении массива (добавлении/удалении событий типа 3 и 4) "досортировывать" его за линию (так же, как это делается в сортировке пузырьком).Всё, теперь у нас есть полностью заполненный и отсортированный по координате массив событий.
Перед началом итерирования посчитаем длину отрезка
len = (X координата начала отрезка) - (X координата конца отрезка). Потом посчитаем скоростьspeed = len / TIME(TIMEиз условия, это сколько времени человек идёт).Чтобы ходить по всем событиям нужно поддерживать флаг
meStarted, который равенtrue, если мы дошли до координаты начала отрезка, а также надо поддерживать флагcurrentOpened, который равенtrue, если на текущий момент мы находимся вне колонны.Проходимся по всем событиям:
meStarted=true, то прибавим к ответу расстояние от позиции предыдущего события до текущей. УстановимcurrentOpened=false.currentOpened=true.meStarted=true.currentOpened=true, то прибавим к ответу расстояние от позиции предыдущего события до текущей. УстановимmeStarted=false.Теперь поделим ответ на скорость и добавим к общему ответу эту величину.
Также нужно учесть, что скорость могла быть равна 0, это происходит когда
carY=-carVelocity. Тогда надо посмотреть, что точка, в которой мы постоянно находимся (на осиy=0) не находится внутри какой-либо колонны. Если это так, тогда ответом будетTIME, иначе ответ равен нулю.Ещё могло случиться так, что координата конца отрезка находится левее координаты начала, тогда просто поменяем их местами.
P.S: Код.
По поводу F: есть решение без HLD.
Как и у тебя сначала посчитаем количество пар пересекающихся, а потом из этого получим ответ.
Сначала, сгруппируем все пути по
lca.Теперь будем обходить дерево с помощью
dfsи поддерживать активные пути (активизируются как мы проходим вершинуu == lca(path[i].begin, path[i].end).Мы находимся в вершинке
u,path_by_lca[u]— для которыхu == lca(path[i].begin, path[i].end),cnt == |path_by_lca|.К ответу добавляем
cnt * (cnt - 1) / 2(очевидно, что между собой они пересекаются) и добавимcnt * (количество активных путей заканчивающихся где-то в поддереве вершины u).Пометим пути
path_by_lca[u]— активными.Запустим
dfsдля детей.Пометим пути
path_by_lca[u]— как не активные.Теперь как поддерживать активные пути и считать количество активных путей заканчивающихся в поддереве заданной вершины:
a. Заведем дерево Фенвика на Эйлеровом обходе дерева. Тогда мы можем выполнять такие операции: - Добавить значение в какую-то вершинку. - Посчитать сумму значений вершинок в поддереве какой-то вершины (будем делать запрос на сумму по первому и последнему встречанию вершинке в Эйлеровом обходе).
b. На шаге 3, просто добавим
+1к концам путей изpath_by_lca[u].c. На шаге 2, для подсчета активных путей заканчивающихся в поддереве --
fenwick.sum(start_time[u], end_time[u]).d. На шаге 4, прибавим
-1к концам путей изpath_by_lca[u].Ассимптотика получается такая же: O((N + K)·log(N)), но должно работать несколько быстрей, так как операции попроще.
Код: https://ideone.com/oQFacf
Во втором пункте, наверное, надо отнимать от ответа величину
cnt * (cnt - 1) / 2?А вообще да, интересное решение, спасибо) Надо будет написать его на яве и сравнить время выполнения.
Ну само изложенное решение считает количество пар пересекающихся поэтому прибавляем.
А потом в самом конце вычтем из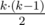 .
.
Но можно и вычитать в
п. 2обе величины из ответа.Привет! Решение практически такое же, различается только в деталях. Давай насчитаем 2 величины. Во первых для каждой вершины посчитаем, для скольких путей эта вершина -- lca. Пусть это будет
count[v]. Теперь давай для каждой вершины так же посчитаем, сколько у нас путей проходит через нее и идет в верх по направлению к корню. Посчитать легко -- просто давай заведем вспомогательный массивчик, в котором для каждого пути на концах прибавим 1, а в lca отнимем 2. Сумма по поддереву и есть то, что нам нужно. Пусть этоgo_up[v]. Теперь что бы посчитать, сколько путей пересекаются с тем, что мы зафиксировали -- давай найдем сумму всехcountдля пути, и прибавимgo_upдля lca. Искать суммуcountна пути просто. Давай просто скажем, чтоcount_sum[v]-- это суммаcountот корня до v. Тогда сумма на пути от a до b -- этоcount_sum[a] + count_sum[b] - 2 * count_sum[lca(a, b)] + count[lca(a, b])]. Получается, что все, кроме нахождения lca -- за линию делается.PS. код Зашло за 125 мс.
Код После того, как нашли lca всех путей, за один dfs-проход для каждого lca в текущей вершине добавляем к ответу все пути, lca которых уже встречалось, но ни один из двух концов пути не лежит в текущем поддереве. Собственно, в коде функция
solveэто и делает, а возвращаетsetвстреченных концов путей. Вроде, это n * log2(n), но заходит за 307 ms.Как решить задачу E и F в турнире школьников ? У меня к задаче F были решения ДП за O(n^2) и рекурсивное решение ,но не одно из них не были верными. А к задаче E я просто перебирал и это тоже было не верно.
E можно решить банальным перебором от числа N включительно. Если в нашем числе меньше разрядов чем d*2, то делаем число 1 и d-1 нулей (пример N=228,d=4, то начинаем перебор с числа 1000).сам перебор делаем так: считаем сколько разрядов у текущего числа и потом делаем такой for(INT mid=d;mid>=sz-d;++i). То есть мы разбиваем текущее число на 2, левое число — от 1 разряда до sz-mid, второе с mid до sz. Во втором числе главное проверить, что первый разряд у него не 0. После нахождения этих чисел проверяем их на простоту. Если они оба простые, значит мы нашли ответ. При проверке на простоту главное не забыть, что 1 не простое число и при нахождении двух чисел в форе нужно использовать операции / и %.
А на самом деле! Я при переборе очень глупые ошибки сделал.Спасибо большое !
А как задачу F с распилом брёвен решить Mr.Nobody43 ?
F можно решить динамикой. Сначала добавим два дополнительных распила в начале и в конце на 0 и l, а потом уже считаем стоимость минимального распила подбревна между i-м и j-м распилом. Вот код, чтобы стало понятнее: http://mirror.codeforces.com/contest/4/submission/36429917
До меня дошло,спасибо большое Mr.Nobody43 !
Seryi ,а будет ли возможность дорешать задачи ?
Задачи несколько разбросаны по Банку задач, но найти их там и дорешать можно :) A201, 159, 176, 177, A173, A185, SFU_2012_C, FAVT_2011_D
Спасибо большое !
Seryi ,а как можно посмотреть задачи юниоров и порешать их ? Они тоже в банке задач ?
Открыл доступ. Начиная отсюда и на следующей странице: http://contest.linserv.inostudio.net/index.php?page=TaskBase.php&StartN=480
Спасибо большое !
Условия по Junior полные тут: https://drive.google.com/file/d/1o613EpVyquDA7lWZEquG3sOuqQ8NmLmv/view
Здравствуйте дорогие посетители сайта! Не мог бы кто-нибудь помочь — объяснить решение задачи С ("пары сдвигов") в минувшем отборочном туре по командному программированию? У меня было несколько разных рабочих вариантов, но ни один не подходил по лимиту времени 1 сек.
Посчитаем количество вхождений cnt[i] каждого из символов в строке. Пройдёмся по всем парам <i, j> символов алфавита и прибавим к ответу abs(i — j) * cnt[i] * cnt[j]. В конце умножим на N и разделим на 2, чтобы учесть все сдвиги и повторы. Это верно, потому что позиции символов значения не имеют — все циклические сдвиги всё равно пересекают все символы. Код по ссылке.
Seryi , а когда будут известны участники финального тура оффициально ?
На сайте уже есть: http://www.contestsfedu.org/
Спасибо большое Seryi ! Вот у меня такой вопрос. Что нужно заполнять ,какие бланки и т.д ? Будет ли предоставляться еда,жильё ?
Для граждан РФ всё просто. Придёт письмо, в котором оргкомитет спросит "приедете?", и для участия будет достаточно подтверждения в ответном письме, ну и собственно приехать — никакого другого официоза. Для граждан других стран могут потребоваться ещё какие-то согласования, которые будут уточнены непосредственно в переписке.
Насколько мне известно, питание не обеспечивается. А вот вопрос с жильём решаемый, если позаботиться заранее, бывали случаи, что участникам давали места в общежитиях. Рекомендую задать этот вопрос также в ответном письме оргкомитету.
Спасибо большое ! Я буду ждать письма .....
Итоговый монитор тут https://contest.yandex.ru/contest/8063/standings/