


Привет, Codeforces!
27 июня в 17:35 по Москве начнётся Educational Codeforces Round 46.
Продолжается серия образовательных раундов в рамках инициативы Harbour.Space University! Подробности о сотрудничестве Harbour.Space University и Codeforces можно прочитать в посте.
Раунд будет рейтинговым для участников с рейтингом менее 2100. Соревнование будет проводиться по немного расширенным правилам ACM ICPC. После окончания раунда будет период времени длительностью в 12 часов, в течение которого вы можете попробовать взломать абсолютно любое решение (в том числе свое). Причем исходный код будет предоставлен не только для чтения, но и для копирования.
Вам будет предложено 7 задач на 2 часа. Мы надеемся, что вам они покажутся интересными.
Задачи вместе со мной готовили Адилбек adedalic Далабаев, Роман Roms Глазов и Михаил awoo Пикляев.
Удачи в раунде! Успешных решений!
UPD: Разбор задач.
У меня также есть сообщение от наших партнеров, Harbour.Space University:
Hi Codeforces!
For our programming boot camp’s next iteration of Hello Barcelona Programming Bootcamp, Harbour.Space University in collaboration with Moscow Workshops ICPC, ITMO University, Moscow Institute of Physics and Technology, Saint Petersburg State University and Codeforces is bringing the best training practices and coaches to Barcelona to prepare 150 students for winning medals in the next ICPC World Finals.
It's extraordinary to see the entire cultural spectrum meet at the boot camp over a common love of programming and learning, and this autumn, we will be doing it again.
Our boot camp will once again feature the all-time greats Mike MikeMirzayanov Mirzayanov, Andrey andrewzta Stankevich, Michael Endagorion Tikhomirov, Gleb GlebsHP Evstropov, Artem VArtem Vasilyev, Ivan ifsmirnov Smirnov and other world renowned Russian coaches to train the participants.
Expect the most challenging problems, surprise guests and speakers, a branded hackathon, and finally the online round held on Codeforces, so everyone can join the onsite participants, at the finale of the event.
During the nine days of the event from Sept 26 to Oct 4, 2018 in Barcelona, teams will be participating in practice contests, problem discussion sessions and lectures.
Learn more about Barcelona ICPC Bootcamp
You can ask any questions by email: hello@harbour.space
UPD. Контест завершён!
Поздравляем победителей:
| Место | Участник | Задач решено | Штраф |
|---|---|---|---|
| 1 | Farhod | 7 | 353 |
| 2 | MrDindows | 7 | 362 |
| 3 | tzuyu_chou | 6 | 205 |
| 4 | Wild_Hamster | 6 | 248 |
| 5 | spj_29 | 6 | 252 |
Поздравляем лучших взломщиков:
| Место | Участник | Число взломов |
|---|---|---|
| 1 | halyavin | 225:-5 |
| 2 | MarcosK | 22:-3 |
| 3 | sfialok98 | 5 |
| 4 | Rhouma | 4 |
| 5 | FakeGuy | 3 |
И, наконец, поздравляем людей, отправивших первое полное решение по задаче:
| Задача | Участник | Штраф |
|---|---|---|
| A | 300iq | 0:01 |
| B | HIT_Zero | 0:13 |
| C | Dalgerok | 0:07 |
| D | ruhan.habib39 | 0:08 |
| E | Dalgerok | 0:14 |
| F | MrDindows | 0:17 |
| G | chemthan | 1:13 |






Will hacking phase be just 12 hours from now on?
Hope we won't wait till the next morning of the contest to know the result and rating changes :D
We will, hacking lasts 12 hours
But usually we wait for along time after hack phase ends.
i hope we won't wait :(
But I have to wait until the next afternoon (or the next evening, for the poor speed of system testing and rating changing) as a Chinese. I just want to have a good sleep (instead of staying up late) and can see the rating changes as soon as I get up.
What does Codeforces have against Mexicans? That's two rounds at the same time as Mexico's matches in the World Cup :'(.
luckily for you they never make it past the fourth game.
Just like you'll never make it to Candidate Master
Yikes... -1
I guess he'll make it to Candidate Master lol
I guess I will.
I guess he did. Well done.
Hope to see good problems,not just implementations.
1000th contest
yeah,how time flies!
I expected special round for anniversary contest :(
To me, all rounds are special :)
Maybe it is a special round? Maybe there will be fast syste... Oh no, fast systests won't help, there is 12 hours long hacking phase...
can i hack which problem i have not solved?
yes! you can.
And you can copy anyone's solution before you hack others.
Most of the hacking is done in first 2-3 hours. Mininize hacking phase to only 6 hours
I agree. It is annoying to wait 12 hours
still less annoying than ur annyoing comments
Mock him all you want, he is rotavirus
Still less annoying than ur usual comment
But then Chinese will have to not only stay up to participate in contests, but also keep staying up after the contests to hack.
Mmm... I made 16 hacks in the last 4 hours of hacking phase, and only 6 in the first 2 hours. I think 24 hours was too much, but 12 hours is not that bad!
12 hours to hack is toooooooooo long.
I agree with you. The rating changes are always come out at the second day when we have an Educational or Div. 3 round.
What does one mean by hacking problems? This would be my first contest of this type. Can someone please guide regarding the rules and terms ?
After The Contest ended.....everyone Can See your solution and if he found anything wrong he can hack you and the problem won't be Accepted
If my solution gets hacked, it will not be accepted and I will lose points, what will the hacker get ? Thanks for the reply.
nothing
in Educational Contest He Won't Get Any Thing Except if he made a lot of hacks he will became from most hackers of Contest But Also he won't Get any Points.
But in Usual Contests He Can Hack participants in his room in Codeforces after locking his problem and if he hacked any one he will get 100 points and if he make Hack But it was unsuccessful He will lost 50 points
pleasure.
The 12 hour hacking seems to be useless as no one will waste that long time once they comes up with some hacks they tries them and leaves the site.
I can't understand why i am getting this many downvotes
Some people just want to watch the world burn!!
Seems people are agreeing on minimizing the hacking phase...
i thinks educational hacks shoud give some (points) (reduce time)
Educational rounds are created to solve problems and not to hack
so why rating changes .. ?!
now he is dead
how can codeforces community help you?
keep this fb thing there itself :|
Problem A fucked me deep....
The weird thing is you commented this in the middle of the contest!! Man, during the contest you should concentrate only on solving problems.
problem E is not clear at all and explanation for the sample input/output is also missing.
code force is retarded. edu round is dumb. your all dumb
Problem F:
Should the answer to sample 3 and 0?
The test case for the D problem is not clear, 4 1 1 1 1 how can it have 7 good subsegment??
a1,a2,a3,a4 cannot be good subsegment because a1!=k-1 as given in the question?? can any one please explain?
The task is to count subsequences which could consist of one or more consecutive subsequences which obey mentioned rules. [a1, a2, a3, a4] consists of [a1, a2] and [a3, a4] which are valid subsequences, therefore the entire subsequence is valid and should be counted.
TASK F demands wavelet trees i think or persistent segtree
What happened to 300iq ???
Left a record in the standings of contest 1000 and plunged into problem preparation. (I guess)
Nice contest, thanks, problems B, D and E are really nice. Problem A kinda awful though.
TASK F looks for wavelet tree or persistent segtree's.
You can do F with regular segment tree.
The idea is to sort queries by start-index, and only keep indexes i, such that index i is the first time number V[i] appears in [start-index, n).
For each such number, store where the next same number is.
Now, you just want to find the maximum element in an interval. If it's not large enough, answer is 0. Otherwise, its value is the answer.
When moving to the next query, loop from last-start-index to start-index — 1, deactivate those indexes, and activate indexes of their values's next appearances.
Let's keep pairs in the segment tree to easily get what is the number with maximum index of next appearance.
Say our array is
[1, 2, 1, 3, 2, 2, 3, 1], and we have the queries 1 3, 2 6 and 3 8.Next-array:
[3, 5, 8, 7, 6, 9, 9, 9](one-indexed)Initial state (start-index = 1):
Active-array:
[1, 1, 0, 1, 0, 0, 0, 0]Values in segtree:
[{3, 1}, {5, 2}, {0, 1}, {7, 3}, {0, 2}, {0, 2}, {0, 3}, {0, 1}]To answer query 1 3, we find the maximum in the interval [1, 3]. It is {5, 2}. 5 is larger than the endpoint of the query, so we output 2.
Now we have to move start-index from 1 to 2. To do this, we activate the next appearance of the number at index 1, and deactivate the number at index 1.
State with start-index = 2:
Active-array:
[0, 1, 1, 1, 0, 0, 0, 0]Values in segtree:
[{0, 1}, {5, 2}, {8, 1}, {7, 3}, {0, 2}, {0, 2}, {0, 3}, {0, 1}]To answer query 2 6, we find the maximum in the interval [2, 6]. It is {8, 1}. 8 is larger than the endpoint of the query, so we output 1.
State with start-index = 3:
Active-array:
[0, 0, 1, 1, 1, 0, 0, 0]Values in segtree:
[{0, 1}, {0, 2}, {8, 1}, {7, 3}, {6, 2}, {0, 2}, {0, 3}, {0, 1}]To answer query 3 8, we find the maximum in the interval [3, 8]. It is {8, 1}. But since 8 <= 8, no number appears only once in the interval, and we output 0.
thanks.
A very nice solution!
A & B & C are mostly implementation problems. Is this really Educational round? Educational rounds used to be different.
I think you haven't read D, E, F, G. These problems are just like what you would expect to find in a usual Educational round.
Also, I don't think the implementation in C is too heavy. A has an elegant and short implementation.
How to solve G?
What is the story behind your username mango_lassi? You don't seem Indian to me.
Key idea, in my opinion, is to calculate for each i dpi — maximal profit of 2-path starting at i and finishing at i. If i is a root of tree, then dpi is just pretty standard dp for subtrees. To calculate dp for each vertex as if this vertex is root — it's possible with technique of "rerooting" (actually, I don't know it's real name as I don't know where to find materials to this quite standart technique).
How to solve C?
Classical scanline problem.
Explain pls. I know its easy (got that by seeing the number of solves) but I couldn't figure it out.
What would we do if constraints were small? Use partial sums!
So now we can do similar thing just using map instead of arrays for partial sums.
How to solve D though?
P.S : I think there is even a way of doing it without using maps. I am unaware of that sorry!
Let dp[i] denote number of good subsequences ending at i. So a subsequence will be divided into parts which are good. Now look at the last part of the subsequences which end at i. Let the start of the last part of that subsequence be j. So dp[i] = sum(((pref[j-1]+1)*ncr[i-j-1][a[j]-1])) because we have to choose a[j]-1 elements between i and j to complete that part and the subsequence can be completed by the rest of the parts ending before j.
Why are you adding +1 to pref[j-1] when taking the summation?
Suppose you have m queries with l and r.(Array of size n)
Now you can traverse the array 10 times incrementing values between l and r.It take Time Complexity O(n*m). OR u can put +1 on l position and -1 on r+1 position.After inserting u can just traverse the array a single time to get the final array.O(m+n)
No i got how to solve C. I was talking about D and T1duS's method as to why we are adding +1 to pref[j-1]. I got it though. It's because one of the subsequences would be starting at j and ending at i and we ignore the subsequences before that. Add those many subsequences to the number of subsequences starting at j and ending at i multiplied to the number of ways of ending subsequences at j-1. That will be the ans for dp[i].
You can read about it here.
For a given segment say [x y] mark x with +1 and y+1 with -1 and store it. Now just visit these points and check the running sum,and update the running sum on a array with the number of coordinates in between,i.e a[running sum]+=numberofcoordinates,print this array from 1 to n as given.
Thanks
What I did was create a map with the # of the segments that started and ended at a certain point. Then I traversed the points in order, keeping a variable that kept track of the current number of segments. I treated the intervals (spaces between points) and the endpoints separately. Make sure to use long longs.
keep a map of indices of segments and use it as partial sum. Though it struck me a little late. Solution(Easy to understand)->http://mirror.codeforces.com/contest/1000/submission/39725149
Wanna ask a question:
What should a person do after finishing problems he can do in an Educational Round?
(As for me, only problem G left, and I have about 20 minute, then I know how to solve G but I know I can't finish in 20 minutes.
Then I have nothing to do in these 20 minutes: sitting there pushing F5 and seeing my rank falling.
So guys, how do you handle these time ? :) (One may hack in a normal round)
I would do nothing, but enjoy looking at standings (because you solved 6 problems).
But you didn't...... Edit: Oh I see what you mean, never mind
Well bro, I didn't find you in the standing ???
I don't know, maybe you are an accurate one, so waiting won't be a bad choice.
But almost every contest I participated, I "die from" penalties(wrong submition). So even if I finished early, many who finished after me will have a higher rank than me.
How should I deal with that? (Yeah, yeah, yeah, control my hands)
Here I meant you solved 6 problems.
But almost every contest I participated, I "die from" penalties(wrong submition). So even if I finished early, many who finished after me will have a higher rank than me.Yeah, you're right, but if they add feature that allows to hack solutions during the contest there is no need to hold special educational rounds, so I still recommend you to enjoy from your results XD
Sorry I misunderstood you.
And feel guilty that I downvoted you yesterday. :(
Please forgive me.
P.S.: But still, I didn't solve 6 problems... :(
But still, I didn't solve 6 problemsI'm sorry for that :(
try to find bugs in your own solutions so they don't get hacked
You are right!
For E does this work?
1) Find all cycles, and mark each edge in a cycle with 0 (and keep all other edges marked 1)
2) Start at a random node, and find the farthest node from it through a DFS, but by "farthest" i mean weighted distance where the markings denote weight. Denote this farthest node X
3) Similarly find the farthest node from X (with weighted distance, where edges in cycles are distance 0 and edges not in cycles are distance 1), denote this node Y.
Y is the answer
Yes. Though an easier way to think about it is diameter of bridge tree.
Never thought an E problem could be explained in a single line, beautiful!
Never mind, it is indeed diameter
Hacking page is not loading..!!
Can Problem C be solved using Mo's algorithm?
C? I don't think so. Doesn't even look like a Mo problem.
Though F definitely has a Mo solution :D Our model implementation works a bit over TL (like 3.4 seconds) but couple of participants actually squeezed it.
Can you please explain how to keep answer? I used unordered set, but I still getting TL
You can store not the hashset but the whole array of number counts. Then you do sqrt decomposition over this array, you make updates in O(1) and then ask in . I believe, the code is pretty much self-explainatory.
. I believe, the code is pretty much self-explainatory.
Isn't this Mo's Algorithm?
There are both Mo's algorithm and sqrt decomposition)
What is the time complexity of such a solution, wouldn't using a set reduce it (despite large constants)?
It's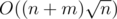 , I believe. No idea how to make a good use of set in that case.
, I believe. No idea how to make a good use of set in that case.
More precisely, In this task, using Mo's Algorithm, you will need to move left and right borders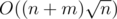 times, but asking for any element you will make no more than m times, so using sqrt-decomposition gives you slow asking operation (
times, but asking for any element you will make no more than m times, so using sqrt-decomposition gives you slow asking operation ( ), but fast move operation (O(1)). In result you will get
), but fast move operation (O(1)). In result you will get 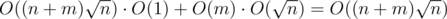 .
.
On the other hand, using set will give you same complexity for asking and move operation, so result complexity will be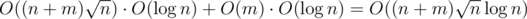 .
.
I tried to implement this idea but I got TLE, it seems that the comparator you used is the key to get Accepted, the solution passed in under 2 seconds after I tried it, can you explain how it works ?
Update: I figured it out, this is a very clever trick :D The parity thing makes a block continue working from the index that the previous block finished working. This means that inside some block, the right index of mo's algorithm will keep increasing until it reaches the end, for the next block, it will keep decreasing while answering queries in the opposite direction instead of removing all the elements then increasing the right index from the beginning.
in problem C it happened for the first time that PYPY gave TLE and python 2 passed in 2345ms. When I saw the accepted solutions in pypy, there were only three and their time was also quite borderline. How can pypy be slower than python 2
I would like to know the same. My submission got TLE during contest: 39712202. Fearing that the time limit is too strict I switched to C++. And here's my practice submission with an AC: 39725290
cases are too harsh I guess. I guess during main test cases after the 12 hours hacking period python solutions might also fail
Our python3 implementation of it works in 2137ms, we dicided that about 1 second off TL is fine for this.
yeah even python 2 solution worked well within TL. It's just that how come pypy gave a slower output than python. This rarely happens.
Yeah, we didn't really expect that. Unfortunately, we had no way to test it as polygon doesn't support pypy.
I thought implementation for A is too heavy (for usual A in educational) until I see this submission...
This is better, http://mirror.codeforces.com/contest/1000/submission/39704314
if only the round would be extended for 1 minute, I would solve Е :(
Напомните, пожалуйста, зачем решили сделать образовательные раунды рейтинговыми???
Чтобы после них у части участников менялся рейтинг.
Две ключевые задачи раунда были у нас на Московских сборах в явном виде
Е — https://informatics.msk.ru/mod/statements/view3.php?chapterid=113280
F — https://informatics.msk.ru/mod/statements/view3.php?chapterid=113873
Точно ли стоит делать такие раунды рейтинговыми?
А много ли участников раунда бывали на этих Московских сборах или могли встретить эти задачи? (авторы придумали эти задачи независимо) Да, возможно таски не такие оригинальные, но конкретно этот пример мне не кажется показательным.
Да, я согласен, что небольшое количество людей видело эти задачи, и тем не менее это не то, что я лично хотел бы видеть "рейтинговым раундом на Codeforces". Отнюдь не в обиду авторам, just my opinion.
И я совершенно не против таких раундов с баянами\полу-баянами. Меня смущает только, что они влияют на рейтинг.
Ок, значит наши критерии немного расходятся. Может даже и интересно получилось, что и мы, и составители задач на сборы посчитали данные задачи достаточно учебными для контеста)
Не вижу проблем с рейтингом. Мне кажется, вероятность встретить на едуке задачу, которую уже решал, не настолько больше вероятности встретить такую на див2 раунде, чтобы совсем шаффлить ранклист.
Не знаю насчет E, но F мало того что встречалась везде, так еще и должна была присутствовать в раунде 489 для заранее известного k вместо единички (по счастью, там нашлась задача лучше). Собственно, вот авторское решение той задачи 39709495 с k = 1.
Так что да, баян, можно было найти что-то пооригинальнее
А, ну да, точно, как мы могли забыть про это. В следующий раз будем осторожнее проверять всевозможные чаты с обсуждениями идей, чтобы ни с кем не пересечься.
У нас была мысль дать её в онлайне, но как-то решили, что и так достаточно полезно для едука.
E is about finding the diameter of the tree of cycles, right?
But how do you find and isolate each cycle? Tarjan's algorithm only works in directed graphs and I couldn't figure out how to apply it on undirected ones..
You can find the bridges of a graph with Tarjan's like this. With them, you will then be able to combine all the nodes that share some cycle. And you will end up with a tree.
maybe i should be saying sorry for this question , but can someone please explain to me A and why n — (all the sizes that are the same in old and new t-shirts sizes) is an logical answer ?
Because you need only 1 second to change one size to another if they have equal length. The answer can't be less because you need to change at least this number of strings.
and if there a test case where input is
1
XS
XXXL
how can a code like the one i described be good ?
((sorry if i just misread or didn't understand the problem))
this one is invalid test case .
1) You can only change letters, not add or remove
2) It is guaranteed that you can get one list from another
So this test is incorrect
Thanks Numb and anno
sorry if i wasted your time with my -3 IQ.
lets take all the t-shirt name of lenght 3 that is xx_ so in old t-shirt either it will be present or absent so if it is absent so we only need to change the last character but if it is present we can use that and we cannot reduce or increase the length of the names so we will only consider length 3 similarly for all.
can anyone help me to understand the problem statement of E problem and the output of the given test cases?
You need to find two vertices s and t such that the number of bridges on the way from s to t is maximized.
how the answer of first test case is 2 ?
pick s = 4 and t = 5, then you have two bridges (4, 1) and (5, 2) on the way from s to t.
Thank You @numb , @jakube
May someone please tell me why my solution for A 39724005 is wrong?
Consider this test case:
2
M
S
L
M
Your output = 2; Answer = 1;
your code is failing for this 6 L L L M M M L L M M M S output should be 1
try this testcase:
I have also done same mistake in my code Now understood flaw. Thanks for the test cases.
٧_٧
Thank you all IIIIIIIIIIIIIIIIIIIII, anno and lazyc97, now I get it.
I worked during the contest on coming up with such tests, but failed with it :(.
Can anyone explain the approach to B? Thanks!
Basically you should notice that the best is to insert the new number just next to some a[i] or just before it.
So you can try all possibilites. To do that, could be a good idea to have an accmuluate array that tells how many time is on from number i to the end. Then you can go from left to right and get the answer for every possible insertion and take maximun.
Can Anyone please explain D and E.
Let's denote with
dp[i]the number of good subsequences of the arraya[i...n-1], and definedp[n] = 0.The good subsequences of
dp[i]either use the elementa[i]or they don't. There aredp[i+1]good subsequences that don't containa[i]. So we only need to count those that do.These subsequences might contain multiple good arrays. Let's focus on the first one. Its size is exactly
a[i] + 1. Ifa[i] <= 0then there are obviously no good array starting witha[i]. So assume thata[i] > 0iterate over the last element in this good array. It can be any elementa[j]withi + a[i] <= j <= n-1, and there arenCr(j - i - 1, a[i] - 1)possibilities to pick the middle elements of this good array. We count this sequence alone, and we can also combine it with each good subsequence indp[j+1].Therefore we get the recursion:
And the solution to the problem is
dp[0].Hi, I followed your solution, however the recurrence relation gave me 1 more than the answer and I don't quite understand why. Could you explain this?
Do you mean my implementation? I used a slightly different definition. I defined the empty array as a good subsequence, so at the end I have to subtract this one.
This is a submission that corresponds directly to the explanation: 39734194
Btw, there was a little error my comment above. I forgot the + 1. But now it is fixed.
Why you added +1 to dp[j+1] before multiplying to that nCr formulae. I didn't got that.
Look 2/3 comments below.
Ohh got that thanks .
That was a very pretty solution. Thanks a ton. I got that
Why have you added 1 in your formlula? I know that simply dp[j+1] won't give the right answer but (dp[j+1]+1) will give but I am not able to get the idea behind adding 1. Sorry for such a silly question
You can either combine the good array starting at i and ending at j with any of the good subsequences in a[j+1...n-1] => multiply by dp[j+1]
Or you can only use the subsequence alone (without combining it with other subsequences) => + 1
Any one solved F using MO's Algo within TL ? UPD: 39735901
After contest:39725241 Hacked :D
Rofl Was unrolling these loops really necessary?
One unrolling helped to pass the time limit.
Too close TL,resubmission may get TLE!!
See this submission 39747523
Can someone please help out with Problem C?
Thanks! I don't see a way to start. The tag said "SORTING," but I am not sure how to even apply it here.
The keyword is "Sweep line algorithm".
Basically you convert each segment [l, r] into two events (l, begin), (r, end), sort all those events and compute the answer by iterating over the events. At each event point you can compute the answer for the last interval [last_event + 1, current_event - 1] in constant time, since the number of segments doesn't change in this interval.
This is actually a classic geometry concept, which is called "Line Sweep". It's called that because we can imagine a vertical line moving from left to right, covering all the points lying on the x-axis one-by-one. What we do is, store all the segments(x, y) separated in an array, with each element being (val, isStart), where val is either x or y, and isStart is 1 if it's an x value, and 0 if it's a y value.
After storing all the segments this way in an array, we sort them according to their value. Then, we perform the sweep while keeping a counter
openfor the number of segments that are currently open. When we come across a value where isStart is true, that means that a segment is starting at this point, so we increase our counteropen. And when we come across a value whose isStart is false, we decrease the counteropen.This way at any point we know exactly how many segments are covering it, and using this we can find how many points have
opennumber of segments covering them.Here is a tutorial blog about the line sweep technique: link
And, here is my code for this question: link
If you need any more explanation, do let me know!
That moment when your script hacks your own solution
Can I get the code for the script? Is it open source?
Could he use it in an non-educational round?
No, you cant copy solutions, and it is forbidden by rules.
And it is the first test I tried to use for hacking. If only I checked this corner case during the contest...
Ironic. He could save others from hacks, but not himself.
Do all hacks run against all submissions at the end of hacking phase?
of course
I was doubtful because I checked the contest page after 5 minutes of end of hacking phase and it said 'Final standings'. I wonder how they managed to run all the codes on all the hacks so quickly!
We need to wait for final testing. 'Final standing' is not final standing yet.
Yeah it is not the true 'Final Standing'。Maybe System will rejudge soon
Come on ! Rating changes ?
Time taken to update rating is directly proportional to the amount of rating you are going to gain xD
For problem E this is an excellent link by IIIT Hyderabad threads on quora: https://threads-iiith.quora.com/The-Bridge-Tree-of-a-graph
truly a hacker...
I'm scared about systests now :(
Yes, by this time I think they should've been updated the ratings no? Or educational rounds take this much time usually?
when can I get the solution and the rating changes?
urge..
I found two pairs of people, which have one solution — 39722722 and 39716743; 39723479 and 39714675.
i think first one from practice another from official contest
One of the best educational round I could see on codeforces, in terms of quality problems. Though I couldn't participate in the round.
The systest is really fast, but the rating changing is too slow... Maybe make it faster?
Systests were faster because they only need to check for the hack tests.
When will you publish the Editorial ?
Eagerly waiting for the editorials..when will they come?
Can F be solved with a mergesort tree? ( By keeping all the elements which occur once in the nodes. Also, merging is easy. )
Why is this code for problem C giving run time error on testcase 4?
You compare operator doesn't make any sense.
sortexpects that the compare operatorcmp(p, q)returnstrue, ifpshould appear beforeqin the sorted order.But with you implementation, and using two element
p = {1, 'l'}andq = {1, 'l'}, bothcmp(p, q) == trueandcmp(q, p) == true. So of course C++ is confused. How can an elementpappear beforeqand behindqat the same time?Thanks, finally got it accepted :)
But why did it work for testcase 1, 2, 3?
Probably because there are not identical elements in those cases.
When will you publish the editorial? I'm eager to read it :-)
Why for this graph answer is 1?
Please, someone, explain for problem E.
5 6 1 5 2 3 3 5 2 1 2 5 2 4
The editorial is published.
I tried to do problem E by compressing the cycles to a single node.My solution is running on my computer compiled with command
g++ -std=c++14but on submitting it is giving an error.Here is my solution. Any help ?
I have a strange behavior for my solution for Problem 1000G - Два-пути. If I read integers with cin my solution (39859090) is Accepted. If I use scanf (39859098) or getchar (39859106) I receive "Wrong answer on test 9". How is that possible? In getchar-version I even checked whether input is fine, which seems to be the case (otherwise I would have received a Runtime Error). Can somebody figure out the reason?
Update: Found a small bug (using index outside of range of vector) and now it works (39861715). But the question remains: How can it make a difference whether I read with cin or scanf??