


Since the 2018-2019 ACM-ICPC Brazil Subregional Contest doesn't have an Official Editorial, I propose that we make an "Community Editorial".
B — Nim
We can think of every position [i, 0], [0, i], [i, i] as "insta-winning" positions. To model so, we can give them a very high Grundy number, so they doesn't conflict with any other possible Grundy number. That way, the cells that can only move you to an "insta-winning" cell, recieve an Grundy number of 0, meaning that they are losing positions.
After that, we can preprocess all possible positions and get it's Grundy number.
The final answer is just the nim-sum of every starting ball.
C — Sweep line
To make things easier, we can think of every cut as an straight line. First, we need to observe two things:
- Every line splits an area into two new areas.
- Every line intersection splits an area into two new areas.
Then, the answer must be h + v lines from the first observation + h * v lines from the second observation (every vertical line intersects with every horizontal line) + the number of intersections of lines in the same orientation.
It's easy to see that lines of the same orientation can only intersects if (starti < startj and endi > endj) or (starti > startj and endi < endj).
One fast way to count how many times the above is true is to use an sweep line (from left to right, bottom to top, etc).
D — Ad hoc
Just count the number of numbers ! = 1
E — String
Just follow the statement.
F — DP
We can model the problem with the following indexes: The stages that we've already seen and the current time.
Since there are at maximum 10 stages, we can store the first index in a bitmask.
Then, we can apply the following recurrence:
dp[0][0] = 0;
for(i : possibleBitmasks)
dp[i][0] = -infinity
for(j : [1, 86400])
for(i : possibleBitmasks)
dp[i][j] = max(dp[i][j], dp[i][j - 1]) // watch nothing
for(k : [0, number of stages - 1])
if(i & (1 << k)) // the bit k is on
for(s : stages[k].shows)
if(s.endTime == j)
dp[i][j] = max(dp[i][j],
max(dp[i][s.initTime] + s.songs, // been on this stage before
dp[i ^ (1 << k)][s.initTime] + s.songs)) // first time on this stage
But it's not fast enought :(
To fix it, "skip" to the relevant moments (aka, the end time or the start time of an show) and calculate only the values of the relevant moments.
I — Ad hoc
We can think of the lights as "bits" in an bitset, and the light switches as xor operations. After that, it's kinda easy to notice that we'll cicle through all possible values after 2 * M operations.
Then, we just simulate what is described in the statement (with an limit of 2 * M operations) and print the result.






G: For a number x, you can check if you can use edges <= x to supply everything needed using max flow. That means that you can use binary search + max flow to solve it.
H: Build the KMP automaton for the pattern. Let's say that for a range you have to[i] (meaning from state == i you pass through the range and end up in state to[i]) and cost[i] (meaning from state == i you pass through the range and find cost[i] occurences of the pattern). You can merge 2 ranges in O(|automaton|). This means you can build a segment tree based on the automaton and use it with HLD to solve the problem. The update works in O(logn * |automaton|) and the path query works in O(log^2n) since you start in state 0 and just need to know the answer to the queries in the current state for the "cover" of the queried segments.
Alternative solution for B: Since for (i, i), (0, i) and (i, 0) the game is over, you can consider it nim 0 and calculate it for the rest. Doing the equivalence to a nim game, the constraint that some game having 0 in it means that the current player wins means that it's equivalent to a nim game with the piles having 1 less stone.
It could be done using hash instead automaton, right?
Maybe, but it would be a completely different solution. What are you thinking about? Something like: on update, you process the substrings that changed and on query you try to slot a prefix with a suffix resulting in O(logn * automaton) per query/update? This might work.
Yes, exactly. Each segtree node has a prefix and suffix rolling hash, and the merge between two nodes could be done in O(2 * |pattern|).
Oh... in that case the query would work in O(log^2 * |pattern|) and it might TLE. In this solution you don't need a segment tree for the hashes, you have a range in the chain that you can have patterns fully in a chain so you can use a seg tree for that but for merging prefix/suffix you can use the prefix/suffix of the range of the chain itself instead of using O(log) ranges from the seg tree.
I used binary search + max flow and got TLE. Then I removed the binary search and instead of using BFS to find the residual path, I used a priority first search and still got TLE. So how do I improve the performance?
Never mind, changing form Ford-Fulkerson to Dinic got me AC.
L: For each query (a, b, c, d), set 1 throught the path (a, b), and after that, sum all nodes values on the path between (c, d). It can be done with a Segment Tree + HLD. The solution complexity is O(nlog(n) + qlog2(n))
Did you manage to make log^2(n) queries pass? I know quite a few teams that didn't pass using that exact same solution but they used recurvise seg trees, maybe the iterative one passes?
Yep, i got AC using standard recursive segment tree with lazy propagation. I didn't make any optimization in the code. Actually, I didn't see the timelimits, because if I had seen, probably i never had coded it.
My implementation use just one segtree to take care about all chains. I don't know if use this method is better than use one segtree for each heavy chain.
That's not the difference since I know multiple teams that used that same method. Log^2(N) queries seem to depend on the constant of the seg tree implementation. That being said there's a way to eliminate a log from it.
In a chain, index the vertices starting from 0. In each chain you visit in the first path, you have a range [l, r] that you visit. In the second path, you visit the chains and have other [l, r] that you can use to make the intersection in each chain in O(1). This also eliminates the need for coding a seg tree.
We also managed to pass HLD without even a single optimization. But will u please explain the intended solution , we thought a lot but could not come up. I think it will involve lot of if else statements , i am curious if a cleaner solution is available or not.
Nvm, thought this chain was about problem H
In cf gym the min TLE is 0.5s, the TL in the competition was like 0.1s or 0.2s so keep that in mind...
To solve in O(logN): if you use the smart hld, you query on ranges. So a path query is a set of ranges. If you have those sets ordered, you want the intersection of those sets that can be done in a similar way to merge from merge sort (some kind of sweep line maybe)
Yaa my solution passed in 0.3s which is obviously too slow for this TL.
Ohhhh cool!! Merging using merge sort can help for sure.
Thanks a lot.
Another (maybe easier) solution that works in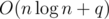 (possibly even O(n + q), but that's not relevant), is the following 2-step reduction using inclusion-exclusion:
(possibly even O(n + q), but that's not relevant), is the following 2-step reduction using inclusion-exclusion:
Say A = (a1, b1) and B = (a2, b2) and you have a function Solve(A, B).
Some nodes will be counted twice, but that can easily be fixed in the implementation.
This problem has many solutions. That's how I've solved during the contest:
For each query(a, b, c, d).
How did you pass the time limit with that method? It is supposed that I do the same :/
https://pastebin.com/Qs05zWRr
Using LCA, it's possible to get the distance between any two nodes of a tree in O(logN). So, final complexity will be only O(Q*logN), pretty fast for the problem constraints.
Your solution runs in O(Q*N).
The solution looks really elegant. Could you please give a brief explanation as to how this works?
Problem C can be interpreted as an Inversion Count problem, since you want to count intersection of Horizontal and Vertical lines.
Horizontal lines cross if and only if they switch positions (I mean, their order from ascending Y position, for example) from the left to the right side. This argument follows to Vertical lines also.
You can implement the Inversion Count using Fenwick Tree or Merge Sort. I'm not sure if the TL fits to use map implementation for Fenwick, since it's kinda tight (0.5s). If you get TLE in this case, just make a coordinate compression.
where can i try submit? any link.
http://mirror.codeforces.com/gym/101908
Keep in mind that the TL during contest might be stricter/looser. Not sure.
M: essentially, every clause must have an odd number of true literals. That means that if the literals of a clause are l1, ..., lk (k ≤ 3), then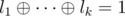 . We can rewrite that in terms of the variables by taking care of negations. For each negation, the right side of the equation flips, so we have
. We can rewrite that in terms of the variables by taking care of negations. For each negation, the right side of the equation flips, so we have 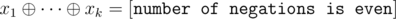 . So we have a system of m equations in
. So we have a system of m equations in  . This can be solved with Gaussian elimination in O(n3) and bitsets can be used to speed it up. We still need to print the max lex solution, though. We can ensure that by reversing the variable indices before applying the elimination, and then assigning true greedily to free variables when doing the backward phase.
. This can be solved with Gaussian elimination in O(n3) and bitsets can be used to speed it up. We still need to print the max lex solution, though. We can ensure that by reversing the variable indices before applying the elimination, and then assigning true greedily to free variables when doing the backward phase.
Implementation for G using dinic's algorithm and binary search
https://pastebin.com/raw/7AjLjCZN
Could somebody test if the problem G have a solution in JAVA? I submitted two times, the first with Edmonds-Karp+Binary Search and the second with Dinic+Binary Search, both give me TLE.
I guess that the official time limit to JAVA in this problem is 2.0 seconds, maybe TL need some adjustment here in codeforces.
You can try submit the same problem here, with the correct time limit to JAVA: https://www.urionlinejudge.com.br/judge/pt/problems/view/2882
You can see the official time limits to JAVA in this problemset here: http://maratona.ime.usp.br/prim-fase18/info_maratona.pdf
K: First observe that R is not less than 1 and the X,Y is not greater than 25 in absolute value. That means that there can only be around 200 circles pair-wise non-intersecting of similar radii (the bound is actually very loose and gets smaller with for larger radius).
We know that two circles are intersecting (with the constraints of the problem) if and only if R ≤ r + d (for R ≥ r), where d is the distance between the two circles. And we know that the maximum distance is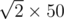 . So if we sort the circles by the radius and kept two pointers representing a range degined by i (the current circle index) and j (the index of the circle with the minimum radius such that
. So if we sort the circles by the radius and kept two pointers representing a range degined by i (the current circle index) and j (the index of the circle with the minimum radius such that 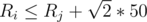 ), we can check circle i with other circles in this range. Because of the observation in the first paragraph we know that the number of misses in this range is very small, and we can break when we pass the 2N intersections limit.
), we can check circle i with other circles in this range. Because of the observation in the first paragraph we know that the number of misses in this range is very small, and we can break when we pass the 2N intersections limit.
Submission: 43245038
How do you deal with ̶1̶5̶0̶0̶0̶0̶ 25000 concentric circles with very similar radii? If I'm understanding correctly then the pointers i and j will be very far apart and checking each circle will take O(N).
Or does that case not show up?
Edit: Oh and there are actually zero circles pair-wise non-intersecting with the same radius since all of them are orbits around the origin, which I forgot about halfway through reading the problem.
Edit 2:
I just submitted the solution described which AC'd and indeed it seems like the tests are weak and just didn't include the concentric circle case at all. The case generated by:
easily TLE's lol
So, can you please share the solution which could pass this test case?
I spent a lot of time thinking about how to solve E, just to realize it had many accepted submissions and it was obviously a simulation problem.
When I started competitive programming, a solution with O(n2) complexity wouldn't be accepted for problems with n ≤ 104.
Good thing the problem is actually easily solvable in a better complexity (or constant).
O(n^2 / 32) solution: use bitsets
O(alphabet * n * logn) solution: use FFT for each letter to count the number of matches in every position.
I knew it was solvable using FFT, but I had only one accepted problem (C) and I thought that convolutions was too overkill, given that it had many accepted submissions.
How to solve A and J?
A: Let dx=abs(x1-x2) and dy=abs(y1-y2). First count answer for pairs where dx>0 and dy>0, dx and dy must be coprime, iterate by dx from 1 to N-1. For a fixed dx we need to know the range [ly, ry], of possibe dy, so the distance between points is in range [L, R], we can find ly, ry using binary search or just moving pointers. Then let's count the number of integers in range [ly, ry] coprime with dx, using inclusion-exclusion in O(2 ^ number of distinct prime divisors of dx) and also count their sum. Now add to the answer (N-dx) * (M * count — sum) * 2. When dx=0 or dy=0 the other one can only be 1. It is possible when L=1, then you have to add to answer (N-1) * M + (M-1) * N and you are done.
The J problem is calculating the Steiner Tree in graph. This problem is NP-complete (that's a reason to have such small constants).
The solution is basically explained on this tutorial: https://www.youtube.com/watch?v=BG4vAoV5kWw
The idea is to build a dynamic programming DP[i][m], where i is which vertex you're at and m is a bitmask of which capitals you joined. You can preprocess the APSP (Floyd-Warshall, or many Dijkstras because of the small constants) and calculate DP[i][m] like this: DP[i][m] = min(DP[i][s] + DP[j][m - s] + dist[i][j]), with s being a submask of m. In the end the complexity is O(3k * n2). (The tutorial says you can have O(3k * n) complexity, but I don't know exactly how yet).
To get O(3^k * n) complexity, you do 2 transitions.
O(3^k * n) transition using submasks
O(2^k * n^2) transition, that is, O(n^2) transition for each mask.
can u help me??! my code getting wrong on test 13.
or if u can send me your code