


I am attaching a picture about the question. Kindly refer to the picture. 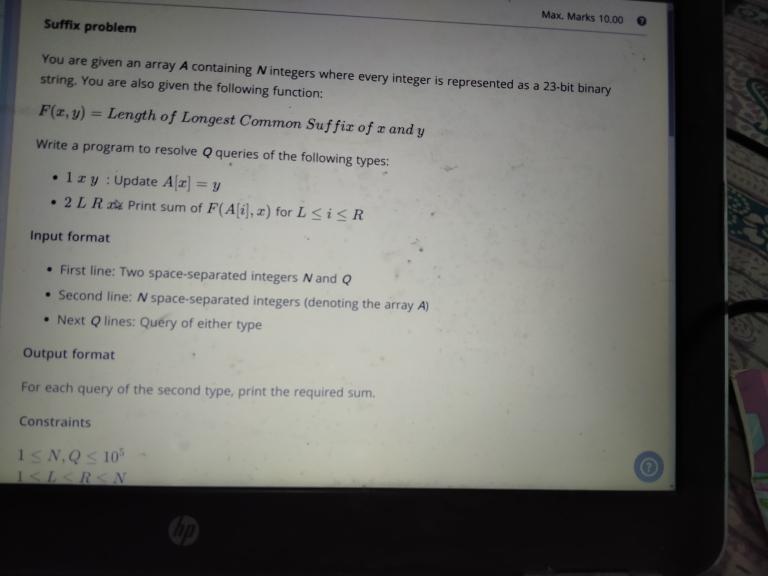
→ Pay attention
→ Streams
→ Top rated
| # | User | Rating |
|---|---|---|
| 1 | tourist | 3985 |
| 2 | jiangly | 3814 |
| 3 | jqdai0815 | 3682 |
| 4 | Benq | 3529 |
| 5 | orzdevinwang | 3526 |
| 6 | ksun48 | 3517 |
| 7 | Radewoosh | 3410 |
| 8 | hos.lyric | 3399 |
| 9 | ecnerwala | 3392 |
| 9 | Um_nik | 3392 |
→ Top contributors
| # | User | Contrib. |
|---|---|---|
| 1 | cry | 169 |
| 2 | maomao90 | 162 |
| 2 | Um_nik | 162 |
| 4 | atcoder_official | 161 |
| 5 | djm03178 | 158 |
| 6 | -is-this-fft- | 157 |
| 7 | adamant | 155 |
| 8 | awoo | 154 |
| 8 | Dominater069 | 154 |
| 10 | luogu_official | 150 |
→ Find user
→ Recent actions





Codeforces (c) Copyright 2010-2024 Mike Mirzayanov
The only programming contests Web 2.0 platform
Server time: Dec/22/2024 10:31:11 (i1).
Desktop version, switch to mobile version.
Supported by

Sample test cases?
You didn't tell us whether the test is finished or not. We shouldn't help you if the test is not finished yet.
It's finished bro.
Reverse all strings, so task becomes about prefix instead of suffix. Create segment tree, where each node have a trie that contains all strings from this node's corresponding segment (each string will be in $$$log~n$$$ tries, so memory will be $$$23 \cdot n~log~n$$$). With trie it's easy to count necessary sum of all string nested in this trie in $$$O(23)$$$, so overall query's complexity will be $$$O(23 \cdot log~n)$$$.
You can do it with a single trie
can you please explain
Basically what you and lemelisk said in the comment below, I'm not sure if it's better, just seems slightly easier to implement
create a trie with reversed strings and store indices of strings in each node in sorted order then query for reversed string, you can find out for each each prefix of reversed string how many strings from given range match this prefix
For updates you will need to store indices in BSTs that supports query "how many elements is smaller than given value". But that a nice alternative to segment tree's solution and it even has lower memory consumption complexity.
I solved it using map and policy based data structure My solution