



Отборочный раунд Engine VK Cup 2019-2020 пройдет 23.02.2020 19:05 (Московское время). Это соревнование предназначено для людей, прошедших квалификацию ранее. Лучшие 40 человек пройдут в финал, который пройдет 11-12 апреля, а лучшие 64 получат футболки VK Cup. Как обычно, параллельно пройдут два обычных раунда, по одному для каждого дивизиона, для тех, кто не может принять участие в этом этапе VK Cup.
Этот раунд бы не состоялся без lperovskaya, MikeMirzayanov, PavelKunyavskiy, izban, Kurpilyansky, YakutovDmitriy, 300iq.
Все три раунда будут идти 2 часа 30 минут, и все являются рейтинговыми. Раунды VK Cup и первого дивизиона будут иметь шесть задач, одинаковые в обоих раундах. Раунд второго дивизиона будет содержать шесть задач. Стоимости задач будут объявлены перед раундом.






Sounds amazing!
Кажется я знаю, кто выиграет контест.
Финал будет в Питере между двумя турами рои2020...
Please write English version of the blog
I had registered for div1 when i was in div1 and now after I became a div 2 participant, I registered for div2 as well. Now from which one should I participate ? Because I am registered for both div1 and div2 rounds. MikeMirzayanov
Just to be sure, I won't get ratings change from both of them right ?
There is an option to cancel registeration. you can use that
I just realized that after few mins of writing comments, thanks. But avoided deleting comment to know what will happen if I don't cancel it.
if you don't submit you don't get rating changed. And if you submit to both, you should be banned (but probably you won't be)
If problems are intersecting then will it not be counted in both divisions even if I submit from anyone of them ?
I am pretty sure (but can't explain why) it won't be counted as submit in both
Finally the announcement!
OK..You absolutely deserve thanks for this round.#300iq
Thanks for the contest to gain back lost rating from Morning div2. :p
can I participate if I have not participated in previous rounds?
Yeah you can register
02:05 am. nice.
Have someone noticed the blog was posted 22 hours ago!! :o
xiuxian competition
I am not seeing any contest for div2 in contest page. is it only me? https://mirror.codeforces.com/contests/1298,1310,1314,1315,1311
Use this link: https://mirror.codeforces.com/contests/1310,1314,1315
i have registered for the contest but its not showing in registration list..is this contest rated for me??
Go here https://mirror.codeforces.com/contests?complete=true
When submitting I keep getting this error ... you have submitted exactly the same code before
I tried changing browser, cleaning cookies still the same error, I can't ask for clarifications also
MikeMirzayanov is there a problem with my account ?
https://imgur.com/a/zb7tkma
Add a comment and the resubmit
I did just that, same error, I submitted with a file same error.
I also tried submitting through m2.codeforces.com apparently the system thinks i'm in another contest
I had that error in a previous contest, never solve it
For me Div2 was even more unbalanced than the one from this morning. Quickest was C, then A and D, hardest was B, again ;)
How was B hard?
I had to fiddle with indexes for like an hour to get it right. Since A was more than 20 Minutes I did not submit at all.
Then, later, C+D turned out to be simpler, I submitted all four of them after two hours.
Can agree more. Too hard for me. Time taken for solving A,B,C,D for me are 4, 53, 8, 32. Seems like B was trickiest at least for me.
How to solve Div 1 D?
Pick 4 vertices + the vertex 1 as white, color the rest black. We can now calculate, for two white vertices their distance "through a black vertex". Now we can solve the problem with cycle length $$$k / 2$$$ and without the bipartite condition on this small 5-vertex graph.
Isn't the complexity of this algorithm n^5 * c (n^4 to choose 4 vertices, n to calculate distances through black vertices, c to solve a smaller graph problem)?
I precalculated for every pair of vertices (a, b) several "best" vertices v, such that path a->v->b is less or equal than a->u->b for any other vertices u. Since we can't use path a->v->b only if we chose v, and we can't choose more than 4 vertices, we can find the minimal length of the current cycle with O(4 * 4) instead O(n).
Something like that. I had to optimize a bit. First we pick only 3 white vertices + the vertex 1, calculate two best distances between all pairs of the 4 vertices, now iterate over remaining vertices to pick the 5th.
Not sure how much it helped. But my program should always take the same amount of time (I add virtual vertices until we have 80), so "Pretests passed" should mean that it gets accepted.
Randomized approach is much nicer indeed.
Can you suggest some problems for practice that use a similar randomized approach?
You'll visit at most $$$10$$$ vertices (including $$$1$$$) on your way. No odd cycles -> you can assign each vertex a color, black or white, such that no two vertices connected on your path via an edge have the same color. For optimal path, there exists some coloring, so we can try to guess it. Assign the colors randomly and run a simple dp. Repeat as many times as you have time.
To guarantee no odd cycles, every vertex must be visited with the same parity of number of moves every time. Notice that we don't need more than 5 vertices of every color. Starting vertex is always even, iterate over the remaining 4.
How to solve D ?
How guys solve D ?
Why is Div1D so much easier compared to Div1B and C?
Edit: I suspect that the writer of Div1D intended that it be solved using a randomized algorithm, but incorrectly chose the constraints, leading to it being solvable using a much simpler method.
I don't know is it true, but it's reason can be they don't want to put no more easy tasks to div.2
IMO Div1B is easier than Div1D (to solve, not to understand :Dd), but I do agree that Div1D is a very standard problem.
I didn't know div1D at all and it took me much less time to figure it out than div1B. B has a simple solution, but there are so many ways to try something wrong.
What is the simple solution to B?
DP: "when the sub-tournament for people $$$[a \cdot 2^b, (a+1) \cdot 2^b)$$$ is finished, there's one person remaining in the upper bracket and one in the lower; if we choose which of them are among the initial $$$k$$$, what's the max. number of games?". Basically, the tournament structure is sufficiently tree-like, but it doesn't seem so at first.
How to solve Div2 D?
At first let's find out what will be the final size of all means find a set of size such that any pair are not eqaul.You can find it by a simple dp.iterate by sorting given array. Then next size should be max(cnt+1,a[i]) where cnt is size of the last index.
Then greedily give size to all. To minimize the cost the element of maximal cost should be increase minimum number of times.
You can put list of categories by size into a map.
Then for every size remove the most expensive category of that size, and buy for all others one more instance, so they "move up" one size.
To do this eficiently maintain a set of categories, sorted by cost of categories. Then per "move up" add the costs for the whole set. see https://mirror.codeforces.com/contest/1315/submission/71724533
I did exactly what you described and still TLE on test 15. TLE code
Group categories with same number of publications. Starting from the group with smallest publications, ignore the one with maximum time and increment all the others by 1. If the next category has same count, add it to the group and repeat the same thing.
My submission 71721239
Thank you, I solve the Div.2 D finally according your explanation. It stuck me for one day!
How to do Div2 D?
Thanks for the contest <3 I have learnt many things
How to solve Div 1 B....is there any greedy solution exists like to take any team in upper side or lower side ??
The statements were pretty bad. There are some really basic mistakes like "looses" (I'm sure you've seen this word a million times so write it correctly), the statement of B overloads $$$k$$$ and doesn't mention how the teams are paired ("see the images below" isn't an explanation) and they're overall just clumsy, kinda tough to read.
Was D some improved bruteforce?
D is a traditional FPT problem. Partition the vertices into two disjoint sets randomly, then find a best path in bipartite graph. Repeat. The probability of success is exponentially small of $$$k$$$ (I guess $$$2^{-k}$$$), so overall complexity is $$$2^k poly(n)$$$.
This TLEd for me — choosing the vertices for the bipartite graph takes $$$n\choose k/2$$$ iterations, right?
You get the wrong idea. I am not bruteforcing the partition. I'm selecting a partition randomly (there are $$$2^n$$$ partitions in total), and repeat the whole stuff $$$2^{k} * const$$$ times (well, actually as many times as it fits in TL).
Do you assume that everybody knows, what fixed-parameter tractable is?
Nah, just kidding :)
In the end, I figured out the deterministic solution by MrDindows below by myself easily. Too bad I didn't check D before getting brutalised by B (instead of 5 minutes before the end), I would've just swapped these two problems if it was up to me.
D. Go over all possible vertices on even positions (2, 4, 6 and 8) in the path. For the odd positions choose greedily from unused vertices. $$$O(N^{K/2 - 1}K^2)$$$, or just $$$O(N^4)$$$ assuming k is constant.
Agree. Grammar and spelling was bad. Also trying to explain B with a weird drawing was a terrible idea. Yet, I think the biggest problem with the statements was ambiguity. Here are some of the most embarrassing examples:
-Div1A:
Why not:
-Div1B
Why not:
It's a longer statement but it's good to clear out exactly how the matching happens, even if you have a drawing.
Div1D
Why not something like
You could've also not include that sentence, just leaving
Which is actually less confusing.
Authors: please refer to the picture for better understanding
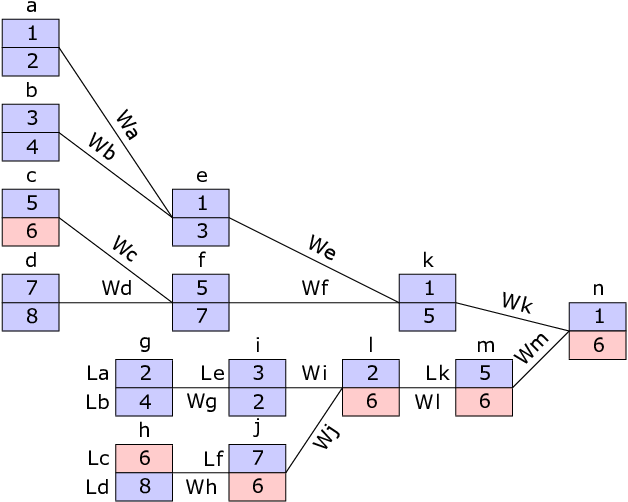
Picture:
It would be much better if they grouped each level of upper brackets and lower brackets.
How to solve Div2 D ?
Generate optimal final value set and start matching from highest time to lowest one to this set using lower bound function.
Let's say $$$p_i$$$ is the value which $$$a_i$$$ gets, this has cost $$$t_ip_i - t_iai$$$. We have to minimize $$$\sum_{i=1}^nt_ip_i - \sum_{i=1}^nt_ia_i$$$. Last part is constant, so me must minimize first part. We can use a greedy algorithm to do that.
Can you guys have me on D
My algo like this
[Deleted]
Hit like if you think Div2 B has weak Pretests !
omg the total value can go to long long and I failed the tests :(
Try to put long long int instead of int in almost all integer numbers. That has saved me a lot of times.
#define int long long // peace
Day of terrible B's... B's statement is like...
well, is it ok if bus stops near tram station? what is crossroad and why the word "crossroad" was used? My imagination was totally broken here.
And more than that B was much more complicated than C again!
And weak pretests :)
Объясните как в задаче B. Дорога домой в строке
Получили ответ 3?
По всей логике должен же быть ответ 7. Ибо денег хватает только на последние 3 поездки. А до 7 перекрёстка Петя будет идти пешком. Или я всё-таки ошибаюсь?
Заранее благодарю!
У вас буква в тесте потерялась:
AABBBBAABB
По условиям задачи, стоимость проезда не зависит от расстояния, а трамвайные пути (троллейбусные провода?) не нужны в конечной остановке ¯\_(ツ)_/¯
Очень плохо прописано условие.
в тестах не AABBBBAAB, а -> AABBBBAABB
A A B B B B A A B B0 0 0 2 2 2 5 5 7 7where did i went wrong in div2 d? https://mirror.codeforces.com/contest/1315/my
The feeling when you finish debugging your code 3 minutes after the contest :(
The answer is some substring of the string. Let's binary search it.
To do this, first order the substrings, which can be done recursively in $$$\mathcal{O}(n^2 c)$$$.
To check if there are at least $$$k$$$ ordered strings lexicographically at least some string $$$tar$$$, first find for any position $$$i$$$ in the string the first position $$$r[i]$$$ in the string such that the string $$$str[i, r[i])$$$ is lexicographically at least $$$tar$$$. Then count the number of ways to partition the array such that every partition is lexicographically at least $$$tar$$$ by the recurrence
\begin{equation*} DP[i][k] = \sum_{j = r[i]}^{n} DP[j][k-1] \end{equation*}
which can be computed in $$$\mathcal{O}(n^{2})$$$. Since we only make additions, we can at every point take maximum with the target value $$$k$$$ to ensure no overflows happen.
Total complexity: $$$\mathcal{O}(n^{2} (c + \log n))$$$.
71731373
Can anyone help me in solving Div2-D ? I was getting TLE in testcase 15.
My solution — [submission:71720686]https://mirror.codeforces.com/contest/1315/submission/71720686
Thanks, in advance.
I failed once at 15, too. For me it was int overflow on sum of costs. Fixed by defining it long long.
but mine was a TLE.
Solution- https://mirror.codeforces.com/contest/1315/submission/71720686
I came out with an O(nlogn) solution for div2D
sort by pair (a[i], -t[i])
each round add 1 to the min values if there are multiple of them
there are O(n) round (correct me if this is wrong)
each round take O(logn) to add sum(l,r)-max(l,r) to the answer
where l r can be determined easily(hard to code, though)
then set the max in max(l,r) query to 0
but its too complicated to implement for me in 2.a.m. :(
Also, wondering if there are good segment tree templates or other templates.
Hope somebody can provide, thx!
For templates/pre-coded algorithms, see the Implementations section.
Personally, I recommend KACTL.
A great list
can't thank you more for sharing :)
I had a really hard time trying to understand what Div2B statement was trying to say and wasted a lot of time on that. What a shame.
So, what's the most efficient way to multiply two nimbers? I kind of know the solution in 7kk multiplications, but calculating nimber product in $$$64^2$$$ takes too long. Any suggestions?
Check editorial to Radewoosh&mnbvmar contest. If you want to keep multiplying by the same number, you can do a preprocesing on this number.
Do you have it published anywhere?
https://mirror.codeforces.com/blog/entry/69792 Task L
Editorial
Awesome contest 300iq!
How are the points scored for a problem decided? I read long time ago in one of the blogs that points are reduced per minute (2, 4, 6, 8, 10 for A, B, C, D, E). If so, my solution C which was submitted at 10:09, should have gotten 1500-60=1440, ( or 1434 if you consider that 11th minute). However, it got 1452. Same story for other problems as well. I am guessing this is so because the contest was of 2 hours 30 minutes, but what is the formula then?
Contest duration was 2:30, so drain is adjusted to this duration
When will the ratings change?
i also want to ask and can't wait to become expert
I literally devoted 1 hr in B,just later to have it fail on the system test. :(
верните dynamic score, ироды!
It is the first time in a long while that I am participating again, a bit confused though if it was a rated contest. I cannot see it in the list of participated contests on my profile, Does it take a while to appear?
Yeah it does. In past contests it always took some time, at least a few hours.
I have successfully hacked some solutions in D (tourist, for example) with this test:
Will you do something with this?
UPD: about 10 solutions from top40 have failed on this test
Would be great if somebody could provide a testcase that helps to identify testcase 4 of Div2 D
Thanks!
I don't know why this submission 71710714 by Um_nik worked only 15ms on test 37. So currently, it is under investigation. I'll try to understand why it happened and I'll rejudge it if needed. In this case, ratings and places will be recalculated (only in VK Cup 2019-2020 - Отборочный раунд (Engine)).
Well, I guess that many contestants know that $$$clock()$$$ is very dangerous and kind of unstable on CodeForces, so it might be a bigger investigation.
What should we use instead?
Don't know, I'm not an expert, it just an observation :P I usually check $$$clock()$$$ not so ofter, for example after every $$$500$$$ iterations, but I don't know if it is a good idea.
On marathon matches I use this:
Maybe on CF it also works well.
Your code measures wall time, not CPU time. I'm not sure (I'm not sure about anything after that WA 37 tbh), but I think that it is not good for algorithmic competitions, because testing system can pause execution or something.
Doesn't look safe for me, but ofc I don't guarantee that get_time() is.
Difference between 6.9 and 7.1 is not that significant :)
I guess
high_precision_clock<>or whatshisface, I don't remember how all thesechronoclocks are called.I think the issue could be that you assumed
clock()starts from 0.According to https://en.cppreference.com/w/cpp/chrono/c/clock, "Only the difference between two values returned by different calls to std::clock is meaningful, as the beginning of the std::clock era does not have to coincide with the start of the program."
Yes, but other sources say that it is "implementation-defined" which means that it shouldn’t be different between runs on the same compiler?
Also, can you please provide a way to get the same behaviour with probability higher than that of "testing machine went crazy"?
I understand that the quote from reference is enough to not rejudge my solution. But I still think that there may be a problem.
Even difference in std::clock() is not safe. Case 72364466 ran for only 1s. Same submitted again runs for 2s and gets an AC. @dorijanlendvaj stress tested it a lot of times for finding counter test case during testing of Today's rounds and found clock() works incorrectly about 4/100 times.
Right now only possible soln I see is —
About div1B: "Second input line has k distinct integers" Well apparently there was no second input line if k = 0, got RTE by doing input() in Python 71711503. Why would you even have case k = 0 in the first place???
When will the editiorial be published?
Very weak pretests on B. Counter overflow passed pretests and failed on test 56
But still, thank you very much for the round.
I thought that B was pretty straight forward?
He is talking about div1 B.
Ah ok my bad
Hacking div1A solutions with test200000 1 1 1 ... 1 1000000000 ... 1000000000How to calculate the probability in 1D if randomized algorithm is used?
Assume there is only one optimal cycle. We have probability $$$p = \frac{1}{2^{k-1}}$$$ of assign colors in the correct way because the color of vertice 1 is fixed.
To compute the probability of finding the solution in the first $$$T$$$ iterations, we actually compute the complement of not find the solution in the first $$$T$$$ iterations.
So the randomized solution works with probability $$$1 - (1 - p)^T$$$, for $$$k = 10$$$ and $$$T = 5000$$$ that's 0.999943155.
One more thing... there are 129 test cases, so you'd better calculate the $$$(1 - (1 - p) ^ T) ^ N$$$ where $$$N$$$ is the number of test cases. So the answer for $$$T = 5000, k = 10, N = 129$$$ should be $$$0.9927$$$.
In fact I implemented with $$$T = 3000$$$, where the probability is about $$$0.69$$$. My hands didn't stop shaking after realising the fact at the end of the contest until the solution was accepted with fairly good luck.
Maybe it's better to put the problem like "You are given a field, implement Pohlig-hellman algorithm on it" to an educational round.
I've never heard about this algorithm before, and coming up with it from the basics (the fact that all finite commutative groups are products of Z/nZ) was quite enjoyable, even though I needed about 15 more minutes after the end of the contest to finish my code.
Who can help me calculate the time complexity of my program?I just can't figure out. ~~~~~
include<bits/stdc++.h>
using namespace std; const int N = 2e5+9; typedef long long ll; struct node{ int a,b; friend bool operator <(node a,node b){ if(a.a==b.a)return a.b<b.b; return a.a<b.a; } }a[N]; ll ans; int b[N]; int m,n; priority_queue<int,vector,greater >q[N]; void discrete(){ sort(a+1,a+n+1);m=0; for(int i=1;i<=n;i++){ if(i==1||a[i].a!=a[i-1].a){ q[++m].push(a[i].b); b[m]=a[i].a; } else{ q[m].push(a[i].b); } } }
int main(){ while(Scanf("%d",&n)){ ans=0; for(int i=1;i<=n;i++){ while(q[i].size())q[i].pop(); } for(int i=1;i<=n;i++){ scanf("%d",&a[i].a); } for(int i=1;i<=n;i++){ scanf("%d",&a[i].b); } discrete(); for(int i=1;i<=m-1;i++){ if(q[i].size()>1){ int s1=b[i],s2=b[i+1]; int h=q[i].size()-1; int ct1,ct2; if(s2-s1-1<h){ ct1=h-(s2-s1-1); ct2=s2-s1-1; } else{ ct1=0; ct2=h; }
while(q[i].size()>1){ int x=q[i].top();q[i].pop(); if(ct1){ ans+=(ll)x*(s2-s1); q[i+1].push(x); ct1--;continue; } if(ct2){ ans+=(ll)x*ct2; ct2--; } } } } int ct=q[m].size()-1; while(q[m].size()>1){ int x=q[m].top();q[m].pop(); ans+=(ll)ct*x; ct--; } printf("%lld\n",ans); }}
~~~~~
Who can help me calculate the time complexity of my program?I just can't figure out. It's the code of problem D.
Instead of using a min-heap, why not using a max-heap, you can easily calculate the delta for answer and forward in each iteration by pop the maximum element.
Thanks a lot.When the round ends,I was trapped in my thoughts and not aware of the right solution.So that's it.Thanks again for answer my question.
There are so many downvotes in my comments.Maybe because my code occupied so much space.Sorry for that.
for Div2D, if the problem condition changes: we can delete one publication for one category using the same cost as adding
How to solve this problem?
It looks like Slope Trick.
Finally negative!
Why so many downvotes?
Hi if anyone wants solution of div2 D. I have added comments in my solution. I copied the solution from someone as i was not able to solve it. But i have added comments if anyone else wanna understand.
https://mirror.codeforces.com/contest/1315/submission/71753055
Original Submission
https://mirror.codeforces.com/contest/1315/submission/71721239
This contest didn't deserve downvotes, feels like something is wrong with intent of contestants. Div2 E was hard to understand tough, but my Iq < 80 so I understand.
When the editorials will be available?
ying ying ying I wonder when the tutorial will be available? I struggled with div.2E and gave it up finally.
I don't think so the contest was unbalanced or there were grammatical errors. The contest was although great. Still Waiting for the tutorial.
How to solve E div 1?
Suppose we are given a multiset $$$a'_1 \geq a'_2 \geq ...$$$ and wish to know if $$$f^K(a) = a'$$$ for some $$$a$$$ containing no more than $$$N$$$ elements. In general the preimage of any multiset under $$$f$$$ contains multiple options, but the most efficient way to "undo" $$$f$$$ is to select the multiset containing $$$a'_1$$$ 1's, $$$a'_2$$$ 2's, and so on. Define $$$f^{-1}(a)$$$ to be that multiset. We can compute the size of $$$f^{-K}(a')$$$ for any particular $$$a'$$$ through straightforward simulation.
A key observation is that the number of possibilities for $$$f^K(a)$$$ shrinks very quickly as $$$K$$$ grows. One way to observe it is to notice that if $$$f^2(a)$$$ contains $$$x$$$ elements, the sum of the elements in $$$f(a)$$$ is at least $$$1 + 2 + \dots + x$$$, which means that $$$a$$$ contains at least $$$\frac{x \cdot (x + 1)}{2}$$$ elements. The size and sum of $$$f^K(a)$$$ both shrink exponentially as $$$K$$$ grows.
In fact, the final answer for the input $$$N = 2020, K = 3$$$ is only $$$451945$$$. So for $$$K \geq 3$$$ we can do an exponential search on $$$a'$$$ for which $$$|f^{-K}(a')| \leq N$$$.
To handle the $$$K = 1$$$ and $$$K = 2$$$ cases, notice $$$|f^{-1}(a')| = \sum a'$$$ and $$$|f^{-2}(a')| = \sum_{i} ia'_i$$$. In both cases we can count $$$a'$$$ for a given $$$N$$$ with some straightforward DPs.
when is the editorial ?
Editorial is here https://mirror.codeforces.com/blog/entry/74214
Many years ago I added a purple (or even blue) user SoMuchDrama to the friends just because of his funny nickname — I believe that people often dramatize too much. For a long time this user was the only in my friends list didn't know in the real life. It seems that one day I deleted him from the friends list accidentally, but I always remembered him and told about him to my students when they complain instead of training.
When the VK Cup elimination round finished I have found SoMuchDrama in the final standings — several positions above me. Now he has red color and have advanced to the finals! SoMuchDrama, I'm proud of you!
https://mirror.codeforces.com/blog/entry/74214
This is the editorial of this contest.
I think there are some bad translations in the statements and tutorial. I nearly cant read it fluently, which gives me a bad experience. Problems will be nicer with good translation!