


Hello, Codeforces community! (Again)
After asking many times, I realized that the central idea of this blog was not being understood, and I’ve finally decided to rewrite it. This time I want to be clearer and provide more details. This is not about the classic centroid decomposition, but I’ll try to keep it self-contained so the concept is understandable within this blog.
What is a Centroid?
In a tree, a centroid is a node that, when removed along with its incident edges, minimizes the size of the largest remaining connected component, see figure 1.
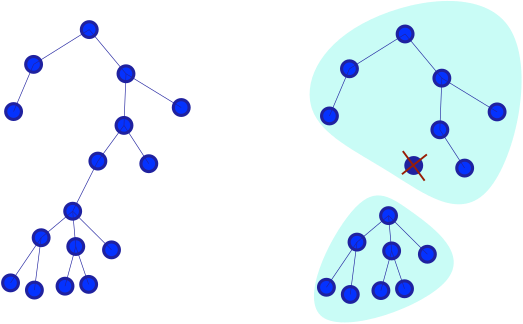
figure 1. Centroid of a tree and remaining components
Claim: Let $$$W(v)$$$ be the size of the largest component after removing node $$$v$$$, and $$$n$$$ be the total number of nodes. If $$$v$$$ is a centroid, then:
Proof: Suppose $$$W(v) \gt \frac{n}{2}$$$, and let $$$w$$$ be a neighbor of $$$v$$$ in a component of size $$$W(v)$$$. Then:
- $$$T - w$$$ has a component of size $$$n - W(v) \le \frac{n}{2}$$$.
- Other components after removing $$$w$$$ are smaller than $$$W(v)$$$.
Thus:
This contradicts the minimality of $$$v$$$. $$$\square$$$
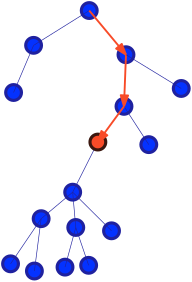
Figure 2. From a random node, the centroid can be found as a gradient descent algorithm.
Centroid Decomposition
Centroid decomposition is a method to cover a tree into (not necessarily disjoint) sets with the following hierarchy:
- The root represents the entire tree.
- Children of a tree represent connected components after removing the centroid.
Each tree is directly linked to its centroid in the decomposition tree, see figure 3.
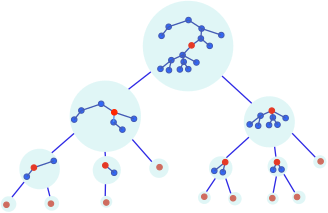
Figure 3. centroid decomposition from a tree.
Algorithm
Input: Tree T with n nodes
Output: Adjacency list of centroid tree
Q ← {(null, T)} ▷ Queue of (parent, component)
r ← {} ▷ Adjacency list
while Q not empty:
(p, cur_T) ← Q.dequeue()
c ← centroid(cur_T)
if p ≠ null:
r[p] ← r[p] ∪ {c}
for each subtree T_i in cur_T - {c}:
Q.push((c, T_i))
return r
note: The height of this tree of sets is logarithmic.
All Path Compression
A key technique in centroid decomposition is compressing all $$$O(n^2)$$$ paths into $$$O(n \log n)$$$ node pairs. This is based on:
Claim: For any two nodes $$$u$$$ and $$$v$$$, the LCA of their corresponding sets in the centroid tree lies on the path between $$$u$$$ and $$$v$$$ in the original tree.
Proof: The first centroid that separates $$$u$$$ and $$$v$$$ will be their LCA in the centroid tree, and this centroid must lie on their path in the original tree. $$$\square$$$
This implies we can classify all paths from $$$u$$$ to other nodes using the pairs $$$(u, u)$$$, $$$(u, p(u))$$$, $$$(u, p(p(u)))$$$, ... where $$$p$$$ denotes parent in the centroid tree.
Information Propagation Technique
This property tells us that if we intersect the paths to the root of two nodes in the centroid tree, only the LCA lies on the path between them; the others are not on the path.
Idea 1.
- Send information to centroid ancestors.
- Receive information from centroid ancestors.
Problem 1
We start with "closed" nodes. Operations:
update: Open a node $$$v$$$.query: Find the nearest open node to $$$u$$$.
Solution
Maintain the closest open node in each centroid:
update: Update all centroid ancestors with $$$v$$$.query: Check all centroid ancestors for $$$\min (\text{distance}(u, \text{ centroid}) + \text{min_stored_value})$$$.
Correctness: If the centroid is on the path to the nearest node, we get the correct answer. Otherwise, the answer might be suboptimal, see Figure 4.
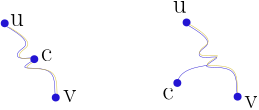
Figure 4. The left image shows the LCA case, the right image shows the other case, which is suboptimal due to the triangle inequality.
Idea 2 (See Figure 5).
- Send information to centroid ancestors (their neighbors), ignoring the component that contain the query node.
- Receive information from centroid ancestors, for components containing the query node,
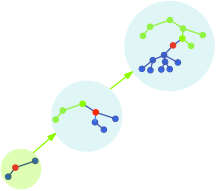
Figure 5. Updating while excluding the queried node’s component.
Problem 2
update: Open a node $$$v$$$.query: Find the farthest open node from $$$u$$$.
Solution
Maintain the farthest open node per component in each centroid:
update: Update centroid ancestors, excluding components containing $$$v$$$.query: Check centroid ancestors for $$$\max(\text{distance}(u,\text{ centroid}) + \text{ max_stored_value})$$$ in compatible components.
Correctness: Prevents information duplication by ensuring centroids aren't outside the relevant paths.
Information Propagation Technique — Subtree Version
Notice that the trick lies in the fact that, even though there may be other centroids along the path, for any two nodes, there is only one centroid on the path in the ancestor set intersection. What would happen if we additionally restrict these centroids to lie only on the path from the sender to the receiver? In that case, we would achieve a perfect information propagation.
Uniqueness theorem:
If I send information to the centroid ancestors in the centroid tree that are, at the same time, descendants in the original tree, and I receive information from the centroid ancestors in the centroid tree that are, at the same time, ancestors in the original tree, see Figure 6, then the information will not be duplicated.
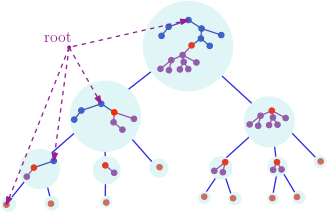
Figure 6. It is colored purple for each centroid tree node (component), indicating the subtree where it sends information (intersection with descendants).
Intuition:
The intuition behind this is the “secret” of the technique, so let’s understand how it works. If I intersect the set of descendants with the set associated in the centroid tree of a node, this will be a subtree with root equal to the centroid.
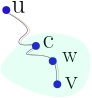
Figure 7. Every node $$$w$$$ on the path from $$$c$$$ to $$$v$$$ also receives information from $$$u$$$ through $$$c$$$.
From the perspective of how information is transmitted, imagine I send information to a centroid that is a descendant, and it is received by a node such that this centroid is its ancestor. Since this centroid is the first separator (with smallest depth) that separates the sender and the receiver, it also separates from sender all nodes on the path from that centroid to the receiver, see Figure 7. Thus, that centroid receives information and distributes it in a subtree.
But then, isn’t that information repeated? Let’s imagine there are two centroids that update a node and that both receive information from the same node $$$v$$$. If neither of them is ancestor of the other, see Figure 8a, the only consequence would be that it is no longer a tree, which is a contradiction. Now, the other option is that one of them is a descendant of the other. First, is it possible that one of the subtrees does not contain the other, see Figure 8b? This is impossible, because of how the centroid tree is constructed: there are no two nodes in the centroid tree that are partially overlapping. But this means that the smaller centroid component lies in of the larger centroid component, see Figure 8c, and cannot contain the sender node; therefore, it cannot be an ancestor of the sender node. Hence, the information is not repeated.
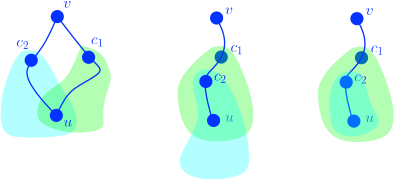
Figure 8. (a) None of the intermediate centroids is an ancestor of the other; (b) one is an ancestor of the other, but their emission sets partially overlap; (c) one is an ancestor of the other, and one emission set is contained within the other.
Finally, this means that the ancestor centroids in the centroid tree of a node that are also its descendants partition the subtree into at most $$$\log(n)$$$ sets.
Query and Update methods
void update(int x, int add) {
for (int ll=lo[x], rr=hi[x];~x; x=pi[x]) //for to iterate over the "Centroid Path"
if (ll <= lo[x] && hi[x] <= rr) {
//send descendants \cap centroid ancestors
}
}
void query(int x) {
for (int ll=lo[x], rr=hi[x]; ~x; x=pi[x])
if (lo[x] <= ll && rr <= hi[x]) {
//receive ancestors \cap centroid ancestors
}
}
The name
Why did I call it a Fenwick tree generalization? Is it really a generalization? I suppose so. For example, consider a path graph with $$$n = 2^k - 1$$$ nodes, with the nodes numbered from $$$1$$$ to $$$n$$$, and node $$$1$$$ as the root. Then: the first higher ancestor (descendant along the path) of each node $$$v$$$ is $$$v + (v \text{ & } -v)$$$, and the first lower ancestor (ancestor along the path) of $$$v$$$ is $$$v - (v \text{ & } -v)$$$. Thus, all the ancestors that a node has, both higher and lower, are the same as those you would encounter when updating a Fenwick tree.
Problems
Infoarena — Disconnect
Statement: You have a tree and two types of operations:
- Remove an edge.
- Query if two nodes are connected.
We can see this problem as updating values in subtrees: In the beginning, all the values start with $$$0$$$ and every time we update increment by $$$1$$$ all the nodes of the subtree, to answer we must know $$$value(a) + value(b) - 2 * value(LCA(a, b))$$$ and check if it's equal to $$$0$$$.
How does this work? We mantain a counter of deleted edges for each node. This counter will store the number of deleted edges from the root of the tree to the given node. Thus, adding $$$1$$$ to all the nodes in the subtree of $$$x$$$ will be equivalent to deleting the edge between $$$x$$$ and its parent.
Codeforces — Propagation Tree
Statement: You have a tree and have two types of operations:
Given $$$val$$$ and $$$x$$$, update the nodes with the following rule: $$${-1}^{dist(x, u)} val$$$, for every node $$$u$$$ in the subtree of $$$x$$$.
Query the current value of a node.
Just consider the distance to the intermediate centroid which we are going to update to calculate the value.
Online DSU on a tree
Statement: Given a tree with $$$n$$$ nodes rooted at node 1, and edges labeled with letters from the English alphabet, answer online queries of the form:
- $$$u, s$$$: Given a node $$$u$$$ and a string $$$s$$$, determine how many paths from $$$u$$$ to any node in its subtree spell the string $$$s$$$.
The constraints are:
- $$$1 \le n \le 3 \cdot 10^5$$$
- The sum of the lengths of all strings $$$s$$$ across all queries is at most $$$3 \cdot 10^5$$$
Solution: We can maintain a trie at each intersection of the subtree with the node's component in the centroid tree; note that this requires $$$O(n \log n)$$$ memory and allows each query to be answered in $$$O(|s_i| \log n)$$$ time.
Note: We can also maintain, online, the number of nodes of a given color in a subtree. Similarly, we can perform queries based on distance to nodes—for example: for a distance $$$r$$$, how many nodes are active, the XOR basis of values in the nodes, etc.
GP of Nanjing: Data Structure
Statement: Given $$$T$$$ cases, you have a tree with $$$n$$$ nodes rooted in node $$$1$$$, initially, each node has weight $$$0$$$ and you need to make $$$m$$$ queries of two possible types:
Given $$$a$$$, $$$x$$$, $$$y$$$, $$$z$$$, add $$$z$$$ to the weights of all descendants $$$v$$$ of $$$a$$$ such that $$$d(a, v) \mod x$$$ is $$$y$$$.
Given a node $$$a$$$, return its weight.
The constraints are:
- $$$1 \le T \le 4$$$
- $$$1 \le n, m \le 3\cdot 10^{5}$$$
- $$$1 \le a, x \le n$$$
- $$$0 \le y \lt x$$$, $$$0 \le z \le 500$$$.
Solution: We can maintain for each node $$$v$$$ an array of length equal to the maximum distance from $$$v$$$ to the nodes in the tree whose centroid equal to $$$v$$$, where we save the updates to be queried by their descendants, this would give us a performance per query equal to $$$O(\log (n))$$$ (traversing the $$$O(\log{n}$$$) ancestors and getting their propagated value in $$$O(1)$$$), and a performance per update equal to $$$O(\frac{n}{x})$$$, notice that it is not $$$O(\frac{n}{x} \log n)$$$ because can be seen as the sum:
As this is not optimal for updates, we can save for each node $$$v$$$ a matrix of size $$$t(v) \times t(v)$$$, where we would store for $$$x \le t(v)$$$, the accumulated queries that have come, this allows us to make queries in $$$O(\log{n} + t(v) + t(\pi(v)) + \ldots + t(root))$$$ and updates in $$$O\left(\log{n} + \frac{len(v)}{t(v)} + \frac{len(\pi(v))}{t(\pi(v))} + \cdots + \frac{n}{t(root)}\right)$$$
Note: Recall that $$$\pi(u)$$$ is the parent of the node $$$u$$$ and $$$len(v)$$$ is the maximum distance from $$$v$$$ to any of its descendants.
We can see these sums in another way, since the parent centroids have at least twice as many nodes as their corresponding child centroid:
For updates, we must :
,
For queries:
We can ignore the $$$O(\log{n})$$$ when assigning $$$t_{i}$$$ because it's not affected by it, so if we set $$$t_{i} = \frac{2^{i}}{t_{i}}$$$, which would be $$$t_{i} = \sqrt{len(v_{i})}$$$, which would give us a complexity.
therefore our final complexity would be $$$O(m \sqrt{n} + n \log{n})$$$ per test case.
I am very grateful to racsosabe for helping me with the revision of this first blog and for sharing ideas to improve it.







Auto comment: topic has been updated by Bashca (previous revision, new revision, compare).
What reminded you of this after 5 years