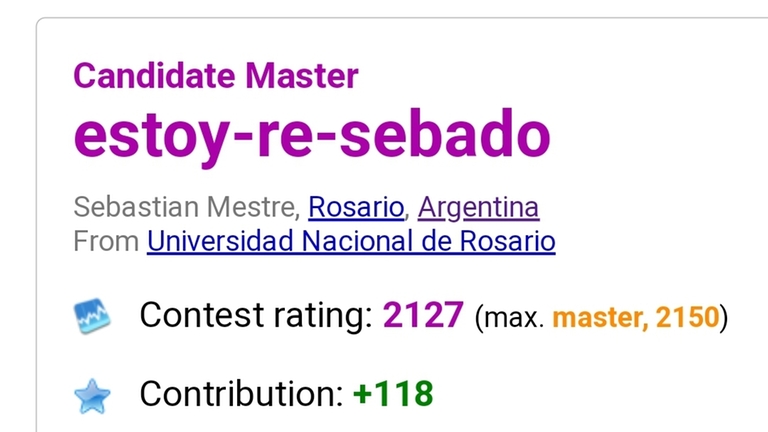
Several months ago I came across an online judge, IIRC called Mathforces, that let you submit [Lean](https://en.wikipedia.org/wiki/Lean_(proof_assistant)) proofs for math problems.
The problem is I can't seem to find it anymore. Does anyone know what came of it? And if it's still online, what the current URL is? Or if you know who created it, how to get in contact with them?