


What Mo's algorithm essentially does is this:
Given a set of q points in the plane, where the i-th point is (xi, yi) and 1 ≤ xi ≤ yi ≤ n, find a permutation of those points such that 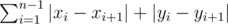 is minimized. So, the first question is this:
is minimized. So, the first question is this:
Does Mo's algorithm give us the optimal solution for this problem, or just an approximation of the optimal solution? The first problem is somewhat similar to the rectilinear (Manhattan distance) travelling salesman problem.
The second question is this: If Mo's algorithm actually gives us an approximation of the optimal solution (which seems to be the case), how much better is the optimal solution? (i.e. let's assume that the total distance in Mo's algorithm is x, and the total distance in the optimal solution for some set of points is y. What is the greatest value of y - x or  ?) Also, what are some interesting observations about the optimal solution?
?) Also, what are some interesting observations about the optimal solution?
Question 3: What's the best algorithm that gives an exact solution to the first problem?





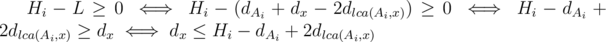
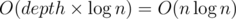 time.
time.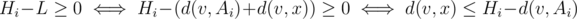 , where
, where 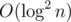 time per query. (
time per query. (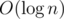 times per query, and every
times per query, and every 