


Was wondering if anyone happened to have one -- Preferably based on Guava so that it's more reusable.
Spent some time looking at some online graph related problems but have no luck in finding a java participant that happened to be based on LCT :(
Was wondering if anyone happened to have one -- Preferably based on Guava so that it's more reusable.
Spent some time looking at some online graph related problems but have no luck in finding a java participant that happened to be based on LCT :(
Credit Suisse is conducting an annual hackathon facing to University students as usual, though this year will be virtual due to COVID situation in Hong Kong.
The contest is open to all full-time University students studying in Singapore / Hong Kong graduating in 2021 — 2024, either UG or TPG.
Registration deadline is on 13th September, the entire event will be conducted between 25 afternoon — 27 afternoon -- Make sure you are available for the entire weekend!
Site / 1st / 2nd / 3rd | HKG(HKD) / 12500 / 7800 / 5100 | SGP(SGD) / 2200 / 1400 / 950.
Due to SGP laws, the host cannot giveaway cash prices without being taxed, so prizes are given with items of equivalent market value (2018 prize: iPad 6 x3, 2019 prize: Electronic product vouchers). There are also policies preventing banks from gifting too much to an individual entity so the prizes for individuals have an adjusted weighting, though they will compete for the same pool with teams, i.e. there are only 3 slots of prices, champion / 1st runner-up / 2nd runner-up, the actual payout depends on whether a team or an an individual won the slot. SGP / HKG site has their prize pools separated.
Unlike many other hiring hackathons that devleops applications, Codeit Suisse has a format similar to HackerEarth contests -- You get problem statements with competitive programming syntax stating IO range and format, and also partial credit per test case. Max team size is 3 just like ICPC (Speaking of which many top ICPC members from CUHK / HKU / HKUST has joined).
Third party libraries imports are ALLOWED. The only restriction is that you should not collude with others outside of your team (of course).
For more contest details / careers promotion information, check out the official website here . From past years experiences the application is highly contested so make sure your application is polished enough to get through screening.
There is no official archive of problems, though you may search for unofficial backups (and also mirror stats) made by participants on Github.
Hi CodeForces,
It's been 6 weeks since my last update, asking the same question [here].
The tension here has grown even further, and now we have received hundreds of Hong Kong citizens being detained while crossing the boarder, not only academics from the HKU, but also staff from the UK Embassy (It might sounds unreal, but Google "Free Simon Cheng" for yourself to make sure it's not fake news).
I have a firm reason to believe that I am risking my own life if I travel to mainland for ICPC in the contest season (Oct~Dec). ( Again, it is not the first time that the HKU programming team is rejected by the Chinese authorities hence deined from ICPC contests. )
My chances of participating ICPC is getting slimmer as we get closer to the Chinese National Day on 1 Oct. What could I do to protect myself?
Hi CodeForces,
Disclaimer: This post is somewhat related to an ongoing political crisis in my homeland, but I have no interest in discussing that issue here, to not get people distracted from the actual topic.
I am a student from the University of Hong Kong (HKU), universities in Hong Kong have a somewhat weird rule in participating ICPC regionals -- We are allowed to participate either APAC / Asia East Continent regionals, but we could only earn our ticket from EC, which is enforced somewhere around 2010s from what I have heard from my seniors. While you may have heard complains about corruption / poor problem quality / rigged EC finals policy etc, I am thankful that the mainland ICPC regional organizers have been making kind exemptions for HK and Macau universities (technically Taiwan as their documents claim but ...) and we stay uneffected from most of the grievance happening in the region.
As EC contests are either held in HK or mainland China, our team almost never had troubles with applying for travelling documents. However, thee scenario has been constantly getting worse ever since the Umbrella revolution in 2014, Mong Kong clash in 2016, and the anti-extradition bill protest that is ongoing right now. Many HKU acitivists have either been sentenced to jail 1(https://en.wikipedia.org/wiki/Benny_Tai) 2(https://en.wikipedia.org/wiki/Edward_Leung) 3(https://en.wikipedia.org/wiki/Alex_Chow_Yong-kang) or is forced to fled oversea 4(https://www.scmp.com/news/hong-kong/politics/article/3017530/only-unmasked-protester-hong-kong-legco-takeover-has-fled). While the cases that I have listed are rather extreme, it is not uncommon for students who are found to participate in anti-China protests are rejected from entering the PRC despite of valid travelling documents. In fact, our teams originally planned to participate in the Urumqi regionals in 2017, however, ALL 3 HKU teams were rejected from entering Urumqi and we had to forfeit the contest. We suspect that this is due to the fact that none of our teams contains mainlanders only. Yet, as an international unversity, it is natural and common for HKU teams to be composed of students of different nationality.
While I will be graduating soon, I am in fear that in the soon future HKU students may face more troubles in entering PRC to attend ICPC regionals, and I believe we should act proactively for the landscape in a decade later, to prevent all HK universities from being effectively banned from advancing to WF. Besides contacting the authorities (eg: Golden Bear), are there anything that I could do work against this problem?
Let's jump straight into the problem
Source problem: https://icpcarchive.ecs.baylor.edu/index.php?option=com_onlinejudge&Itemid=8&category=728&page=show_problem&problem=5691 (2016 Beijing ICPC regionals, problem B)
Aim: Support #5, #6, and a cutting operation simultaneously (I have written a piece of code which supports the first four operations)
What I have achieved so far:
Observed that each node's contribution to its parent depends on the amount of right turns taken in the path (Contribution *= -1 per turn)
Use Link Cut Tree to maintain the amount of nodes which have positive/negative contribution to a node (which I call "sign"), and the values of all nodes if there is no subtree updates in the queries, as all these queries could be reduced to updating the sign/value of a node and propagate the effects to the root (which is just a path update between a node and the root, supported by the LCT)
And I am lost with the subtree update operation, my prototyped method was to update keep a lazy marker on the designated node, so that when I do queries on ...
Nodes in this subtree: I query the path from the queried node to the root, and accumulate the markers along the way. The markers from the ancestors represents the total range update performed on this subtree, and multiplying it by the "sign" of this node computes the effects of such updates.
Ancestors: When the update comes, I will fire a range value update from the updated node's parent to the root, with the net contribution on the updated node due to this range update operation. Then, when I query the ancestors, the effect of this range update is already stored in the values without considering the lazy markers. (*)
All others node will not be affected by such update mechanic.
However, I have came to the solution (I am glad to be told wrong) that I cannot support cutting operations with such update method. In particular, the update on ancestors (*) relies on firing an one time update operation on its ancestors based on its current contribution, yet, when a cutting operation occurs in the subtree, the sign of the updated node changes and the net contribution on the updated node due to the range update is modified thus the update operation ought to be fired again, which could mean non-constant amount of re-updates need to be performed to push the updates for each cutting operation.
I am interested in learning alternative ways in dealing with this problem. I tried to keep this blog short to attract more interest, if you find that I should be clarifying about something in more details in this post, please let me know.
Thanks in advance.
Edit: Just got AC on the problem. As many have suggested, Euler Tour related dynamic structures instead is the way to go!
Hi CodeForces!
Recently I have been trying to set some problems on my own, but soon I find out that it's hard to evaluate the exact difficulty of the harder problems. I setted up five problems and endeavoured most of my effort into the hardest one, after testing it with my testers I made the problem even harder. Originally I was aiming for a div2E problem, but after raising the difficulty me and my tester decided that it should never be a div2E problem, and we aren't too sure whether it should be div1D or div1E (partially due to our lack of experience in solving them).
To all the problem setters out there, especially the ones who have setted div1 contest before, what's the difference between div1D and 1E problems to you in terms of difficulty? Or do you just set problems and sort them in terms of difficulty without considering "it should fit the difficulty of XXX" at the first place?
I know maybe I should follow my feelings and make my own decision since I am the one who know the best about my own mysterious problem, but I really don't want to have a terrible debut on problem setting, so I would really appreciate some foresights from the community. =]
I am keenly interested knowing the solution for a problem that our team didn't found a solution even when we are reviewing the questions, would like to hear from others thoughts on this question. :)
Problem E — Naomi with the graph
Time limit: 1~3s, I forgot the exact time limit. Memory Limit: 512 MB
As we know, Naomi is poor at math. But she practices math problems every day. The following problem is one which she met.
Naomi has a non-directed connected graph with n nodes, labeled from 1 to n, and m edges. The length of each edge is exactly 1. Each node in the graph has a special value and the value of the i-th node is denoted by A[i]. She defines dist[i] as the length of the shortest path bewteen the i-th node and the first node and especially dist[1] = 0.
Then she defines the cost of the graph as Sum( (A[i] — dist[i])^2 | for all 1 <= i <= n ).
Naomi wants to MINIMIZE the cost of the graphby inserting some new edges (the lengths of which should be 1 as well) into the graph. She could insert nothing or insert any number of new edges in her mind.
Can you help her?
Input
The input contains several test cases which is no more than 10.
In each test case, the first line contains two integers n and m ( 1 <= n <= 40, 0 <= m <= 1600).
Each of the following m lines contains two integers x and y ( 1 <= x, y <= n ) indicating an edge between the x-th node and the y-th node.
The last line of the test case contains n integers describing the array A and each element A[i] satisfies 0 <= A{i] <= 1000.
Output
For each test case, print the minimum cost of the graph in a single line.
Sample input
4 3
1 2
2 3
3 4
0 3 3 3
Sample Output
5
So far the best algorithm our team have came up with is a min-cut algorithm with nodes (a[i], dist[i]), but we are worried that having O(V^2) nodes will result in O(V^6) runtime per test case thus a brutal TLE.
I am grateful if someone could shed some light on this problem, I wonder if we are on a completely wrong path — It seems to be impossible to solve the problem with flow related algorithms without constructing O(V^2) nodes.
Recently I am trying to solve 702F — T-shirts based on FatalEagle's approach described here. Somehow the runtime somehow blows up in some seemingly random cases, even after switching between different random priority genreation methods.
Here is my submission. As you can see the runtime of #12 and #16 suddenly blows up while other large cases only has a runtime less than 1second (Not to mention I barely passed #12 after switching from cin to scanf). I wonder if one of my helper functions have a larger time complexity than I anticipated (I think every treap function except pushres() is around O(lgn) ), or am I messing with pointers to much that it takes too much time to allocate space for my treap?
Given (x+a1) * (x+a2) * (x+a3) * ... * (x+an), find the coefficient of the term x^k.
In the case of n, k <= 10^5, one way to approach the problem is to use FFT to convolute the terms layer by layer, by eventually raising the maximum power of the terms. (i.e. evaluate the terms grouped in two, four, eight etc. terms) The time complexity of this approach is around O(N*log^2(N)).
In another case where k << n, where k is way smaller than n, or in this case of: (a1*x^k + a2* x^(k-1) + .... + ak) * (b1*x^k + .... + bk) * (c1*x^k + ... + ck) * ..... (n polymials of x^k)
Where O((n*k)log^2(n*k)) is on the verge of risking TLE
I wonder if it is possible to trim the terms so that we don't have to evaluate beyond k <= 2^i terms as if we are convoluting the polynomials with brute force.
As all the original terms have effect on all values after FFT, I assume that one could not naively extract the least significant 2^i terms from the FFT array, so inverse FFT should be applied before trimming (And O(nlogn) isn't too expensive anyways). Yet, I would like to know if there exist an approach which works around this step.
Inspired by: https://www.hackerrank.com/challenges/permutation-equations
There exists a solution which involves finding the coefficient of (x+n-2) * (x+n-1) * ... (x+2) where k <= 60.
Recently I have been practicing Haskell on CSAcademy, and I was implementing this problem : https://csacademy.com/contest/interview-archive/#task/array-intersection/
Intuitively I tried to use the predefined intersection function to solve the task, yet it does not fit the problem's requirement as it only considers the frequency of the elements showing up in the first list. After googling for a while I found the replacement using xs \ (xs \ ys), yet O(N^2) is not good enough to solve the problem. While the problem could be solved in O(N) by hashing as suggested in the statement, I wonder if there is a predefined way to cope with this task in a Haskell function way? (Dear Haskell god, please spare me from implementing some of the functions)
Recently I have came across thinking about this question, and this is the formal version of the problem:
Given a tree, with some of the nodes labelled with a group number. If we start from the root of the tree, what is the minimum amount of edge that we have to come across to visit at least one node from each group? In case if you are traversing an edge more than once, it must be counted multiplely.
For a better understanding, this is the scenario that I have came acrossed IRL. During a physics experiment related to centripetal force, I have to place a different amount of mass (which is guaranteed to be a combination of some weight provided by the lab, but the combination is not guaranteed to be unique) in order to test the relation between mass and force. Since I am a clumsy person and adjusting the amount of mass may affect the radius of the circular motion and induce more errors to the experiment result, I want to reduce the amount of times that I have to replace the weights to minimize the error while still able to get all required combination of mass for my lab report. In particular, the mass holder holds mass in a stack style, so I can't just reach a state and then just jump back to the root state.
I know this problem could be solved by bitmask dp, but the exponential time complexity is rather disgusting, so I am thinking if using tree algorithms could help improve it (Though generating the tree also has a poor time complexity — but at least now solving how to reach at least one node from each group sounds engaging and useful). I've been thinking about LCA but it doesn't seem to get too much better. Would someone share some thoughts on how to solve the problem in a "faster" way?
I am also thinking about variations about this question such as not requiring to go back the root node (heck, I will just leave the mass on the holder for the lab workers to pack them), or starting from an arbitary root node (The last group may just be as lazy as me and decides to leave the mass on the holder, but now I am just considering that I am starting with the zero state). In case if someone solved the original version of the problem in polynomial time complexity, I would also like to learn how to solve the problem for these variations of the problem.
I was practising FFT with some problems, but I found out that my implementation of FFT seems to take longer than what it takes to fit into the TL.
For the problem 528D. Fuzzy Search (I understand that the problem also has a bitmask solution, but I'd like to practise FFT), I implemented the FFT algorithm (code here) for the string comparison, yet it takes more than 3 seconds to compute 12 FFT(and inverse) of a vector with a size of (2^18).
I wonder how I can improve my implementation's runtime?
Merry Christmas everyone
As the editorials of Technocup rounds usually comes later than expected, I hope that this problem analysis could help out whose wants the questions immediately.
Div2A: Santa Claus and a Place in a Class
This is a trivial implementation question, by a bit math we could derive that:
Number of row: (k-1) // (2*m)
Number of desk: ((k-1) mod (2*m)) // 2
( x // y means the integral part of x/y )
And the side of the desk solely depends on the parity of k, as each row has even number of desks.
Div2B: Santa Claus and Keyboard Check
We could solve the question by saving the status of the keys, i.e. not pressed, swapped in pairs, or confirmed in original position, initially all keys have the not pressed status.
When iterating through the pattern, if we’ve found out that the matching of line1[i] and line2[i] different from the current status, we output -1. Finally, we output whose has the swapped status.
One of the hack cases that have gained a lot of points is by exploiting some codes which does not keep the “confirmed in original position” status, which conflicts against the “swapped in pairs’ status.
Div2C: Santa Claus and Robot
Intuitively, we can tell that if the robot changes the vertical / horizontal direction, then the current position of the robot may lie one of the point.
One of the way to approach this question is by keeping whether the robot is free to change it’s vertical or horizontal direction without declaring an extra point. Obviously, when a new point is reached, the robot is allowed to change it’s horizontal and vertical direction for once. By greedy we will make use of this “free to change” status and add points only when we must, thus reaching the minimized amount of points.
Div2D: Santa Claus and a Palindrome
A key observation is that all strings have the same length, therefore if a string: “111 222 333 444 555” is a palindrome, so is “222 111 333 555 444”.
In order to effectively process the strings, we group the strings and sort their beautiful value (In C++, use std::map<string, vector > does the job.)
Next, we class each string into one of the following conditions:
The string itself is not a palindrome We will reverse the string to find it’s “counterpart” (i.e. concatenating the two strings would produce a palindrome). We greedily select the largest pair available from the two groups until it is not profitable.
The string itself is a palindrome This implies that the string could be used alone (to be placed right at the middle of the final string), or be used twice just as the other case. As the alone string case could only occur once, we shall greedily update the beautiful value of the alone string. This is left as an exercise to the reader.
Div2E: Santa Claus and Tangerines
Note that if we don’t have enough tangerine to spare, we would always to divide the largest ones first.
Using this fact, we would iterate the joy from 1e7 to 1. If there is enough tangerine, we immediate print that as the answer, the question now reduces to maintaining the amount of tangerines.
We could maintain it by keeping track of all tangerines that we have already counted, to avoid duplicated calculation of the partial parts of the larger ones, we could use another array to make a mark at (Size+1) / 2, as we the amount of tangerines collected effectively increases only when we also include the tangerines of Size/2.
If there is no solution even for joy = 1, print joy = -1.
Div2F: Santa Clauses and a Soccer Championship
http://mirror.codeforces.com/problemset/problem/700/B
This is an easier version of Div2F. The main idea is to make use of the fact that the most expensive solution will have all its’ path going through the centroid of the tree. Yes, that is exactly what we needed, we could therefore conclude we only need one city to accommodate all teams, don’t be fooled.
Read this editorial, and the discussions in the blog to learn how to find the centroid of the tree for this question.
http://mirror.codeforces.com/blog/entry/46283
The rest to do is grouping, we can do that keeping track of the dfs traversal order, which is relatively easy compared to the main dish.
I wonder if anyone here managed to solve Problem D Small in the recent Google APAC Test. I implemented my approach yet it somehow failed to cope with the small test case.
Link to problem: https://code.google.com/codejam/contest/5264487/dashboard#s=p3
My approach:
Assume P=0, solve the problem for no swapping by keeping the minimum and maximum value of first n values. Divide the array into non-overlapping segments.
Iterate through each segment, check the leftmost and rightmost position that could be used for dividing the segment into two. Say the segment [seg] = [a] + [b], check for all [a] and [b] where min(a[]) > max(b[]).
Check for positions between the leftmost and rightmost. Say [seg] = [a] + [mid] + [b], solve [mid] for [P] = 0 for P = 0.
Find the best segment to be used for further dividing for swapping. This should be the answer... Except it isn't according to judge. =[
Link to my code: http://pastebin.com/Sa5m7hVE
Any help is appreciated. =]
The problem D Large seems interesting with P = 3, and only two contestants solved it during the contest.
Since the official editorial is yet to be released and people are starting to ask for editorial, I decide to write this problem analysis and hopefully this may help the situation. =]
Sorry for my bad English if I made some grammatical mistakes.
We could simulate the buying process — just buy until you can buy without change.
As the problem statement have already stated, you can always buy 10 shovels without change, so there is at most 10 iterations.
Iterate the days from left to right, and increase the days greedily on the right to fulfill the requirement. Take a look at this figure if you don't understand why this doesn't know why this works.
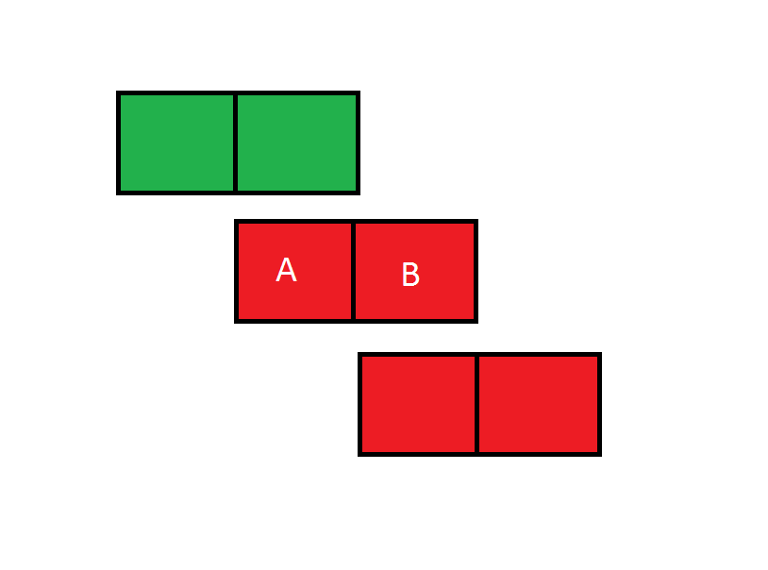
Let's say we are deciding to whether increase the days on A or B to make the total walks on those days become >= k. As we are iterating from left to right the blocks to the left are guaranteed to have already fulfilled the requirement. You can see that placing extra walks on day A will be less beneficial, as placing extra walks on day B could possibly help out the block day B and day B+1.
Time complexity: O(N)
Let's start from scratch, assume that we start and end our vacation before, what is the solution? Let MAX be the most ate meal throughout the vacation, we have to stay at least MAX days to eat enough meals, so the answer is 3*MAX — (sum of meals).
Now we come back to our question — how about if can start and end at anytime? With a little bit of imagination you can see that we could have an extra (or have one less) meal of any combination. As we have discovered before, the solution is 3*MAX — (sum of meals), so we have to greedily reduce the number of MAX to find out the minimal solution.
Time complexity: O(1)
The major observation is that the solution is monotonic — if we can complete all the exam on day X, then we can always complete it using more than X days.
That means we can use binary search to search for the answer. The problem reduces to how to check if one can pass all the exam by day X. We can solve this problem by greedy — Sort all the subjects by the latest date you can take the exam, since we are only checking if you can pass all exams by day X, therefore it is always "safer" to take a late examination instead of an early one. Then, we check if there are enough days for revisioning and taking the examination.
If there is no solution in the range [1,n], print -1.
Time Complexity: O(N*logN*logM)
Define S{X} be the power achievable by adding adapters on a socket that has a power X. One could observe that if power Y is in the set S{X}, then S{Y} is a subset by S{X}. Secondly, you are going to use less or equal adapters if you use socket Y instead of socket X.
Using these observations, we can solve this problem by greedy (you should be familiar with it by now). Sort the power of the sockets from small to large, and add adapters on the sockets until you find a suitable computer. This guarantees we are using the least amount of adapters while plugging in the most amount of computers.
Time complexity: O(NlogN)
We are going to break down the problem with these observations:
Each connecting components should be considered individually — It is obvious that cities that are not connected (directly or indirectly) are not going to affect each other's Ri value.
Each biconnected components could be grouped together — we won't have problem with reaching from city U to V and back to U if we create a cycle by the biconnected components.
Each biconnected components will also have other edges linked with it, and they will either become pointing inwards or outwards. As the biconnected components are not biconnected with other components (or else we will just group it), it is guaranteed that one of the biconnected components will have all it edges connecting to others pointing inwards.
The last observation is significant as it tells out that the solution for each connected component is the size of the largest biconnected component, as it is without doubt the best candidate to have all the edges pointing inwards to it. This also means that the solution is the minimum among all the connected components.
In order to find out the biconnected components you can use the Tarjan algorithm. I strongly recommend you to learn it if you haven't, and practice it on this question. 652E. Pursuit For Artifacts
The problem now reduces to how to allocate the direction of edges, from our observations we should allocate them in such way:
Build cycles in each biconnected components.
Make sure the largest biconnected components is the only one who has all edges pointing towards it in each connected components.
A simple way to complete the task is to initialize dfs from each largest biconnected components, and order the edges in revrese (i.e. from child to their parents).
Time complexity: O(N+M), O(N+MlogM) if you use maps to store the ID of each edge.
Link to problem: http://mirror.codeforces.com/problemset/problem/505/D
My submission: http://mirror.codeforces.com/contest/505/submission/18861557
My idea is to count the amount of sub-trees of the graph that doesn't contain a cycle, and the answer would be n-(amount of sub-trees without a cycle). However my code fails on the test case 6 and I have no idea how did the test case got me... Can anyone point out the flaw of my code or even my approach on solving this problem?
Link to the problem: http://mirror.codeforces.com/problemset/problem/607/A
Latest submission: http://mirror.codeforces.com/contest/607/submission/18781430
Code with comments: http://ideone.com/qlKrkI
I am trying an approach which uses DP to find the maximum number of previously activated beacon at position i, and finding the first out of range beacon by using binary search.
It seems that I am over-counting the activatable beacon in test 11, any thoughts why it went wrong? :/
Thanks for any help in advance.
| # | User | Rating |
|---|---|---|
| 1 | Benq | 3792 |
| 2 | VivaciousAubergine | 3647 |
| 3 | Kevin114514 | 3611 |
| 4 | jiangly | 3583 |
| 5 | strapple | 3515 |
| 6 | tourist | 3470 |
| 7 | dXqwq | 3436 |
| 8 | Radewoosh | 3415 |
| 9 | Otomachi_Una | 3413 |
| 10 | Um_nik | 3376 |
| # | User | Contrib. |
|---|---|---|
| 1 | Qingyu | 163 |
| 2 | adamant | 149 |
| 3 | Um_nik | 146 |
| 4 | Dominater069 | 143 |
| 5 | errorgorn | 141 |
| 6 | cry | 138 |
| 7 | Proof_by_QED | 135 |
| 7 | YuukiS | 135 |
| 9 | chromate00 | 134 |
| 10 | soullless | 132 |






