


Hello Codeforces community, this is my first educational blog on a topic, hopefully some will find it useful despite it not being difficult in nature.
Note: This is not meant to be an introduction to Disjoint Sets Union, if needed, please refer to this tutorial before reading the following.
This is a tutorial based on this article. Here, I'll include some new ideas and implementation details of mine as well. Thanks DavidTan and nickyfoo for proof-reading and also kelzzin2 for exisiting.
DSU Recap
For those who need a quick recap, DSU are meant to support 2 main operations:
- $$$union(a,b)$$$: merge the 2 sets that contain $$$a$$$ and $$$b$$$.
- $$$find(a)$$$: return some identifier that represents the set that $$$a$$$ is in. Note that $$$find(a) = find(b)$$$ iff $$$a$$$ and $$$b$$$ are in the same set.
How this is done is by representing the sets as forests. If the tree that $$$a$$$ belongs to is the same tree that $$$b$$$ belongs to, they are in the same set. We check this if the root of the tree they belong to are the same.
$$$find$$$ then can simply be done by returning the identifier of the root of the tree. $$$union$$$ is done by connecting one of the root to another root (This will be important later).
An example of DSU:
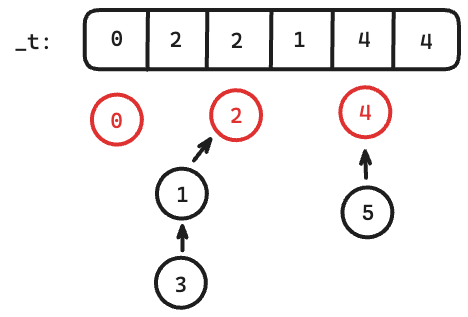
$$$union(1,5)$$$:
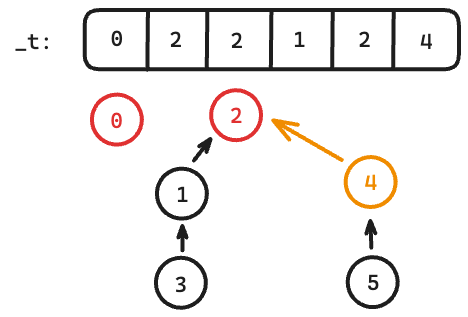
For more details regarding the optimisations (compare set size before $$$union$$$, path compression etc.), please read the other tutorials.
Extra Operation: Move
Suppose we now want to support a new operation:
- $$$move(a,b)$$$: move element $$$a$$$ to the set that contains $$$b$$$
An observation here is that if $$$a$$$ is a leaf, this is simple to do. We can simply just assign $$$t[a] = find(b)$$$. This is because no other elements point to $$$a$$$, therefore no changes are require for all other nodes. If the DSU maintains some other info, we can perform a $$$find(a)$$$ operation and update the required info.
$$$move(3,5)$$$:
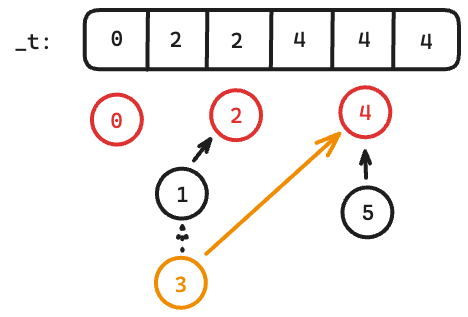
However, the harder case is when $$$a$$$ is not a leaf. This is because everything pointing to $$$a$$$ needs to be modified, leading to a high time complexity. Notice, however, we can ensure this will not happen by doing the following:
- Initialize our DSU with $$$2N$$$ elements instead.
- $$$\forall i = 0,..,N-1$$$, perform $$$union(i,N+i)$$$ with $$$N+i$$$ as the root. In other words, set $$$i$$$ to point to $$$N+i$$$.
Notice, $$$\forall i = 0,..,N-1$$$, $$$i$$$ is a leaf and $$$N+i$$$ is the root. With the previous observation that $$$union(a,b)$$$ only connects one root to another, we ensure that all $$$i = 0,..,N-1$$$ are leaves no matter the operation.
Below is an example (for $$$N$$$ = 4):
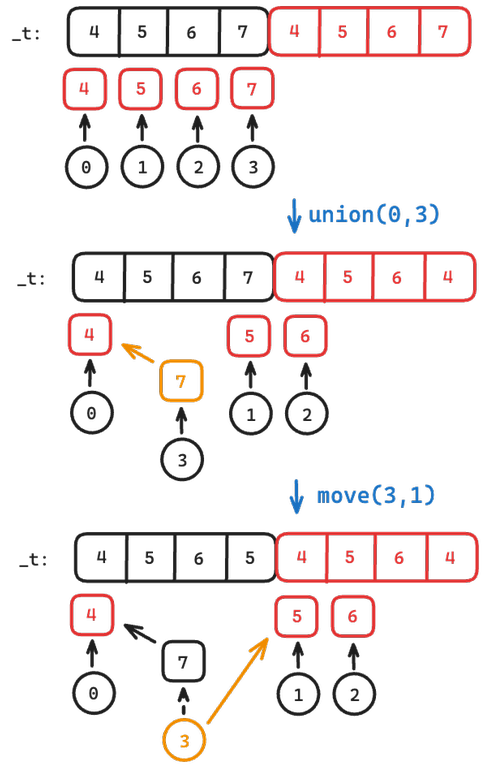
Of course, there are other implementations possible, such as having another vector<int> keep track of $$$move$$$ operations and such, but this implementation requires minimal changes as it only requires a change on how we initialise our DSU.
Here, we have a practice problem for implementation purposes.
Extra Operation: Erase
Suppose we now want to support another operation:
- $$$erase(a)$$$: Remove element $$$a$$$ from its current set. (Future operations will not be performed if one of the arguments include an $$$erased$$$ element)
Doing this is fairly simple, as we can have a vector<bool> keep track of deleted nodes, and update the size info accordingly when deleted. However, if we already have to support the $$$move$$$ operation, we can use the same array to represent $$$delete$$$, this is done by setting node $$$i$$$ to point to itself. Notice, with how we initialise the DSU, $$$\forall i = 0,..,N-1$$$, node $$$i$$$ can never point to itself, unless done through the delete operation.
Notice another easy way to implement $$$erase$$$ is just to have $$$2N+1$$$ nodes instead. We can have the $$$2N$$$-th node represent the set of $$$erased$$$ nodes, then move the nodes to the $$$erased$$$ set when they are $$$erased$$$. This also allows $$$erased$$$ elements to be moved back into a set. (Thanks to nickyfoo for pointing this out)
What if we allow an element to be reused for future operations? (i.e. after $$$erase(a)$$$, it will be removed from the current set and become a set that only contains $$$a$$$)
Implementation Detail
Finally, let's try to also keep track of the size of the set using the same vector. This is a somewhat popular implementation, but for those who do not know, I'll mention it here. In the regular implementation, we have the root point to itself. However, we can signify the root by using negative numbers instead. (i.e $$$t[i] < 0$$$ iff $$$t[i]$$$ is the root). Notice, this lets us keep track of the size of the set by using $$$-size$$$ at the root.
Below is another example (using the new implementation) with the same operations as the previous example: 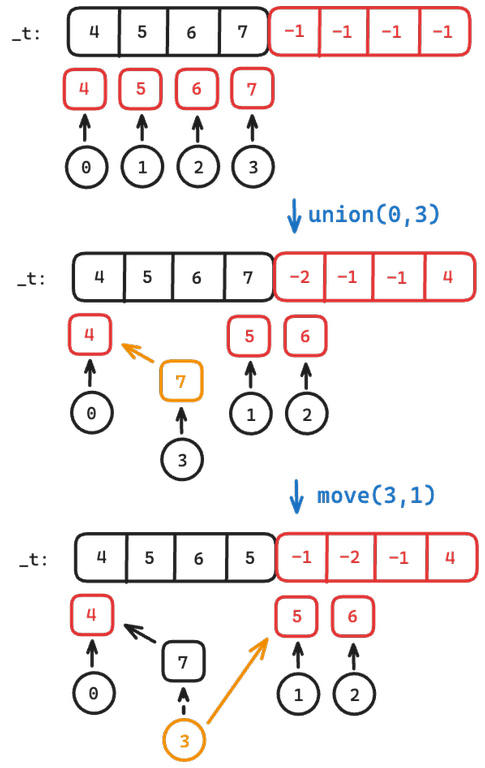
Notice there is a possibility of some root having a size of 0 (assuming that we don't keep track of the size of the extra nodes). However, those nodes that may have this issue always range from $$$N$$$ to $$$2N-1$$$, so they would just no longer be reachable anymore (nothing points to it).
TLDR Sample Implementation
struct DSU {
std::vector<int> _t;
DSU(int N): _t(2*N,-1) {
std::iota(_t.begin(),_t.begin()+N, N);
}
int find(int x) { return _t[x] < 0 ? x : _t[x] = find(_t[x]); }
bool join(int x, int y) {
auto fx = find(x), fy = find(y);
if (is_del(x) || is_del(y) || fx == fy) return false;
if (_t[fx] > _t[fy]) std::swap(fx,fy);
_t[fx] += _t[fy]; _t[fy] = fx; // Ensure we do not count the extra nodes
return true;
}
bool move(int x, int y) {
// this uses the point to itself method.
auto fx = find(x), fy = find(y);
if (is_del(x) || is_del(y) || fx == fy) return false;
_t[fx]++; _t[fy]--; // Note fx, fy cannot be from [0..N-1]
_t[x] = fy;
return true;
}
bool erase(int x) {
auto fx = find(x);
if (is_del(x)) return false;
_t[fx]++; _t[x] = -1;
return true;
}
bool is_del(int x) { return _t[x] == -1; }
int sz(int x) { return -_t[find(x)]; }
};






