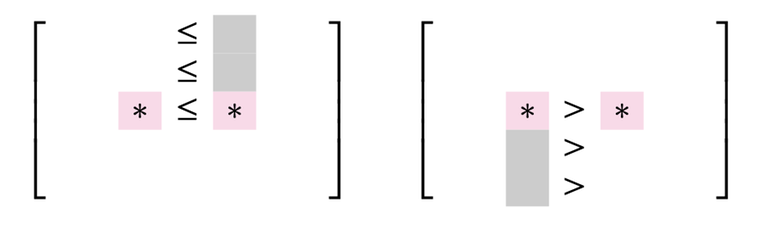Baekjoon Online Judge will cease its operation in April 28, 16 years after its beginning.
Hello,
BOJ, which began in March 2010, will be shutting down its service as of April 28, 2026.
We sincerely thank all of our users who have been with us over the past 16 years.
We made many efforts to continue operating the service, but due to various changes in circumstances, we have unfortunately decided to close it.
Personally, it pains me deeply to shut down a site that has been with me through most of my 20s and 30s. Over these 16 years of running it alone, I have also built many fond memories.
Some users joined as elementary school students and continued using the site all the way into their careers. It was a small dream of mine to one day see them using this site together with their own children. Sadly, the time has now come to let go of that dream.
Rather than disappearing completely, I am considering ways to bring it back at least in a form where the problems can still be viewed. If circumstances change in the future, I will also keep open the possibility of restarting the service. However, at the time of shutdown, all data except for problems, submission records, and contest information will be deleted.
All account deletion requests submitted after today will be processed in bulk immediately after the service ends. You will be able to use the service normally until shutdown, though features such as creating problem sets and groups may be restricted.
Once again, thank you sincerely for your support and love for BOJ.
Sincerely, Baekjoon Choi









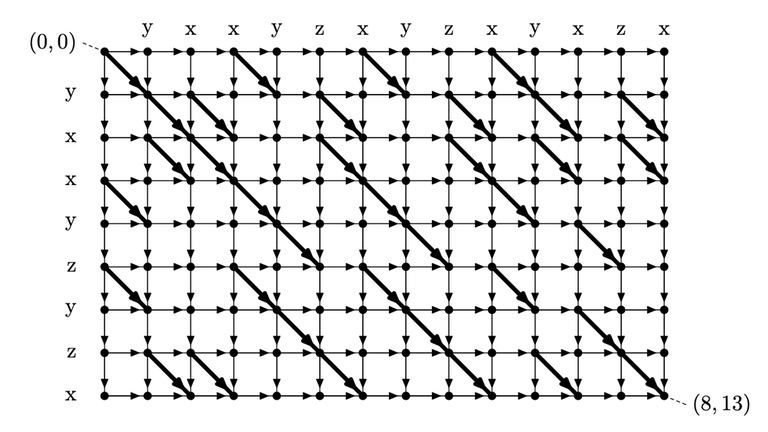
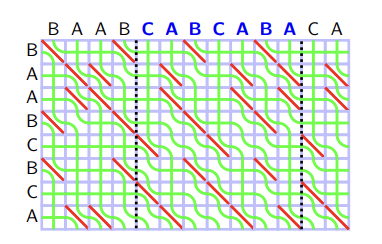
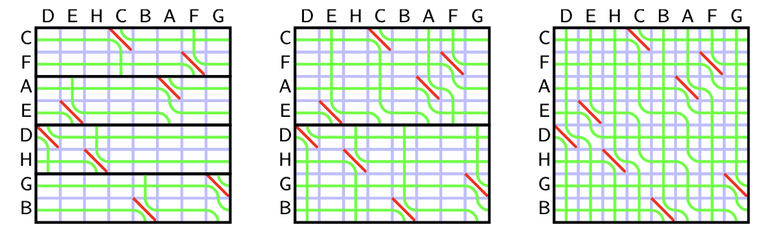 Recall the rules of seaweed: If two seaweeds never met before, then they cross. From this rule, we can easily find the destination for missing columns: The seaweeds will just go downward. Therefore, the permutation for $$$A_{lo}$$$ and $$$A_{hi}$$$ can both be scaled to a larger one by filling the missing columns and missing rows (which are just identity). Then we can simply return the unit-Monge multiplication of them.
Recall the rules of seaweed: If two seaweeds never met before, then they cross. From this rule, we can easily find the destination for missing columns: The seaweeds will just go downward. Therefore, the permutation for $$$A_{lo}$$$ and $$$A_{hi}$$$ can both be scaled to a larger one by filling the missing columns and missing rows (which are just identity). Then we can simply return the unit-Monge multiplication of them.