


I was trying to add yesterday Google Code Jam qualification round to the gym and decided this time to avoid typing in statements myself and print them from website to PDF and attach to the contest. I thought that I'll be able to create a contest with statements in attachments easily and get contest like 2009-2010 Petrozavodsk Winter Training Camp, Moscow SU Unpredictable + SE + old ST Contest for example. It turned out that I have no idea how do that.
What I did:
- Created regular contest in Polygon with checkers, tests, solutions, etc but with no statements.
- Created a gym contest and added polygon contest's descriptor through FTP.
This creates a contest but there are two issues about it:
First of all I had no idea how to attach PDF statements. Eventually I was able to do that using Codeforces Contest Wizard in update mode using a link in gym contest. This Java tool is not that intuitive to use but I was able to upload my PDF document eventually and specify that this is English statements. Is there easier/better/other way to do that?
Secondly, my problems in gym have no name, usually I specify the names as part of the statement in the Polygon but since I had no statements in Polygon I had no names as well. I tried using Contest Wizard to solve this issue as well but the only way I think I found to do that requires uploading all problem data (checker/tests/etc) which I'm not going to change and don't want to bother getting that again assuming that Polygon already created everything.
If somebody wants to help me with that I can give an access to the gym contest, but I would be grateful for an advice as well.






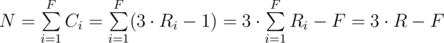
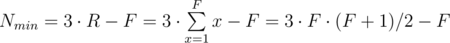
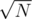 numbers. This gives
numbers. This gives 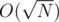 time complexity and fits nicely in the given time limit.
time complexity and fits nicely in the given time limit.


{kind=link}