Special thanks to reirugan, weirdflexbutok and Intellegent for helping with editorials.
Without the "after sorting condition", there are only two ways to color the cards.
Without the "after sorting condition", there are only two ways to color the cards. We must have that $$$a$$$ is alternating in color.
Without loss of generality, color the odd indices red and the even indices blue. This uniquely colors every card. Now, let's sort the array $$$a$$$, while also keeping track of the colors; one way to do this is by sorting it as a vector of pairs. Then we simply have to verify that no two adjacent cards are the same color.
Alternatively, you can use the fact that $$$a$$$ is a permutation, so all differences of $$$a_i - i$$$ have to either be odd or even.
#include <bits/stdc++.h>
using namespace std;
void solve() {
int n;
cin >> n;
vector<int> a(n);
for(auto &i : a) {
cin >> i;
}
int cnt = 0;
for(int i = 0; i < n; i++) {
cnt += (a[i] % 2 != (i + 1) % 2);
}
cout << (cnt == 0 || cnt == n? "YES" : "NO") << '\n';
}
signed main() {
ios_base::sync_with_stdio(0); cin.tie(0);
int ttt = 1;
cin >> ttt;
while(ttt--) {
solve();
}
}
If there are no zeros in $$$a$$$, it's impossible. If there's exactly one zero, it's always possible.
If there are at least $$$2$$$ zeros and no ones, there's a split point between the two zeros.
If there are at least $$$2$$$ zeros and a one, you can put all zeros at the end.
Notice that $$$f(l, r) \gt 0$$$ if and only if $$$a[l, r]$$$ contains a zero. Therefore, if $$$a$$$ does not contain any zeros, the answer is $$$\texttt{NO}$$$, because all values of $$$f(l, r)$$$ are zero, so they are all equal.
Conversely, consider the case where there is exactly one zero. Then we can simply place this zero at the very end. Now, for any $$$1 \leq i \leq n-1$$$, we have that $$$f(1, i) = 0$$$, but $$$f(i+1, n) \neq 0$$$, so the answer is $$$\texttt{YES}$$$.
Finally, consider the case where there are at least two zeros. If $$$a$$$ does not contain any ones, then the answer is $$$\texttt{NO}$$$. This is because we can always choose an $$$i$$$ that splits the zeros — that is, $$$a[1, i]$$$ and $$$a[i+1, n]$$$ both contain a zero — then we will have that $$$f(1, i) = f(i+1, n) = 1$$$.
Otherwise, if $$$a$$$ does contain a one, then we can place all of the zeros at the very end. Now, consider any $$$1 \leq i \leq n-1$$$. If $$$a[1, i]$$$ does not contain a zero, then $$$f(1, i) = 0$$$, but $$$f(i+1, n) \neq 0$$$. If $$$a[1, i]$$$ does contain a zero, then it also contains a one (because all ones are before all zeros), so $$$f(1, i) \geq 2$$$. But $$$a[i+1, n]$$$ consists of only zeros, so $$$f(i+1, n) = 1$$$. Therefore, the answer is $$$\texttt{YES}$$$.
#include <bits/stdc++.h>
using namespace std;
void solve() {
int n;
cin >> n;
vector<int> a(n);
for(auto &i : a) {
cin >> i;
}
vector<int> cnt(n + 1);
for(auto i : a) cnt[i]++;
if(cnt[0] == 0) cout << "NO\n";
else if(cnt[1] > 0) cout << "YES\n";
else cout << (cnt[0] == 1? "YES" : "NO") << '\n';
}
signed main() {
ios_base::sync_with_stdio(0); cin.tie(0);
int ttt = 1;
cin >> ttt;
while(ttt--) {
solve();
}
}
Let $$$t$$$ be the sorted version of $$$s$$$. Then if $$$s = t$$$ at any point, the player to move loses, because there is no legal move remaining.
It's possible to sort in one move.
Let $$$t$$$ be the sorted version of $$$s$$$. Then if $$$s = t$$$ at any point, the player to move loses, because there is no legal move remaining.
If $$$s = t$$$ at the start of the game, the answer is $$$\texttt{Bob}$$$. Otherwise, we claim the answer is $$$\texttt{Alice}$$$, and she can win on the first turn by choosing all of the indices at which $$$s$$$ and $$$t$$$ differ.
First, we claim this is non-increasing. Let $$$i$$$ be the number of zeros in $$$s$$$, so $$$t[1, i]$$$ consists of only zeros, and $$$t[i+1, n]$$$ consists of only ones. Then for any $$$j$$$ between $$$1$$$ and $$$i$$$, if $$$s_j$$$ and $$$t_j$$$ differ then $$$s_j = 1$$$. Similarly, for any $$$j$$$ between $$$i+1$$$ and $$$n$$$, if $$$s_j$$$ and $$$t_j$$$ differ then $$$s_j = 0$$$. So out of the chosen indices, the indices between $$$1$$$ and $$$i$$$ satisfy $$$s_j = 1$$$, and the indices between $$$i+1$$$ and $$$n$$$ satisfy $$$s_j = 0$$$, so the sequence is non-increasing.
Next, we claim that this sorts the array; in particular, this implies that it changes the array, so it is legal. Furthermore, this wins immediately since Bob has no subsequent move. Indeed, we see that the number of chosen indices between $$$1$$$ and $$$i$$$ is equal to the number of chosen indices between $$$i+1$$$ and $$$n$$$, because we must have that the number of zeros and ones in $$$s$$$ and $$$t$$$ are equal. So the operation simply exchanges all of the ones in $$$s[1, i]$$$ with all of the zeros in $$$s[i+1, n]$$$, thus making $$$s = t$$$ as desired.
#include <bits/stdc++.h>
using namespace std;
void solve() {
int n;
cin >> n;
string s;
cin >> s;
string sorted = s;
sort(sorted.begin(), sorted.end());
if (s == sorted) {
cout << "Bob\n";
return;
}
vector<int> idx;
for(int i = 0; i < n; ++i) {
if(s[i] != sorted[i]) {
idx.push_back(i + 1);
}
}
cout << "Alice\n";
cout << idx.size() << '\n';
for(auto i : idx) cout << i << " ";
cout << '\n';
}
signed main() {
ios_base::sync_with_stdio(0); cin.tie(0);
int ttt = 1;
cin >> ttt;
while(ttt--) {
solve();
}
}
2190B1 - Sub-RBS (Easy Version)
- Idea: nifeshe
- Solution: nifeshe
- Editorial: weirdflexbutok
Try to fix the first position where the better sequence and string differ in characters.
Greedily delete characters. You will always end up with an RBS if possible it's possible to make the total balance zero.
For a string $$$t$$$ to be better than $$$s$$$, note that some prefix of $$$t$$$ will be identical to prefix of $$$s$$$, then at the position $$$i$$$ where $$$t_i \neq s_i$$$, $$$s_i =$$$ $$$)$$$ and $$$t_i =$$$ $$$($$$.
Consider the following greedy algorithm. We try to fix the first position where $$$t_i \neq s_i$$$ and $$$s_i =$$$ $$$)$$$, therefore we have $$$t[1 : i-1]$$$ = $$$s[1 : i - 1]$$$. Now $$$s_i$$$ must be $$$)$$$. To make $$$t$$$ bigger, we look for the first index $$$j \gt i$$$ such that $$$s_j$$$ = $$$($$$. Since this is the next character we add to the subsequence, we must skip the last $$$j - i$$$ characters, which will all be $$$)$$$. For a sequence to be an RBS, it is necessary for it to have equal number of $$$($$$ and $$$)$$$. Therefore, we must atleast skip $$$j - i$$$ more ( after position $$$j$$$ in $$$t$$$.
We can show that if we can have $$$j - i$$$ $$$($$$ brackets after position $$$j$$$ and we delete them, we will always end up with RBS of size $$$n - 2 \times (j - i)$$$.
Define a balance of a prefix of a bracket string as the number of opening brackets minus the number of closing brackets.
For a string $$$t$$$ to be an RBS, all of its prefix balances must be non-negative. $$$s$$$ is an RBS. We can show that for any index in $$$t$$$, $$$bal_t[i] \geq bal_s[j]$$$, where the $$$j$$$-th character in $$$s$$$ is at the $$$i$$$-th index in $$$t$$$. This is because deleting an $$$)$$$ in $$$s$$$ will increase the balance of every index after the position. Since we only delete $$$($$$ after $$$)$$$, all the indices' balances must be greater or equal to what it was before.
Therefore, we can simple precompute the next position of $$$($$$ for each index, and find the max over $$$n - 2 \times (j - i)$$$ as long as there are sufficient $$$)$$$ to delete after $$$j$$$.
Time complexity : $$$O(n)$$$
#include <bits/stdc++.h>
using namespace std;
int main(){
std::ios_base::sync_with_stdio(0);
std::cin.tie(0);
int T;
cin >> T;
while(T--){
int n;
string s;
cin >> n >> s;
vector<int> nx(n + 1, n + 1);
vector<int> suf(n + 1, 0);
for(int i = n - 1; i >= 0; i--){
if(s[i] == '(') nx[i] = i;
else nx[i] = nx[i + 1];
if(s[i] == '(') suf[i] += 1;
suf[i] += suf[i + 1];
}
int ans = -1;
for(int i = 0; i < n; i++){
if(s[i] == ')' and nx[i] <= n){
int ig = nx[i] - i;
if(suf[nx[i] + 1] >= ig){
ans = max(ans, n - 2 * ig);
}
}
}
cout << ans << '\n';
}
}
2190B2 - Sub-RBS (Hard Version)
- Idea: nifeshe
- Solution: nifeshe
- Editorial: weirdflexbutok
What values can $$$f(t)$$$ take if length of $$$t$$$ is fixed?
$$$0$$$ or $$$|t| - 2$$$
What is a simple condition the string must satisfy for $$$f(t)$$$ to be $$$|t| - 2$$$?
$$$t$$$ must be an RBS, and $$$)(($$$ must be a subsequence of $$$t$$$.
Use dynamic programming.
First, read the solution to D1.
We can further observe that if our answer is $$$n - 2 \times k$$$, we must have had $$$((($$$ $$$\cdots$$$ $$$()$$$ followed by $$$k$$$ $$$)$$$ s. If we instead follow the same greedy algorithm at the index of the final $$$($$$, we end up getting $$$k = 1$$$. Therefore, if a good subsequence exists, we can always get a subsequence of length $$$n - 2$$$.
Therefore, a string has a better subsequence of length $$$n - 2$$$ iff it has a "$$$)($$$" followed by "$$$($$$". We can further relax this condition to $$$s$$$ is good if $$$s$$$ is a RBS and it has "$$$)(($$$" as a subsequence.
Suppose $$$s$$$ has $$$)(($$$ at position $$$i \lt j \lt k$$$. If $$$s[i + 1] =$$$ $$$($$$, we can choose $$$(i,i+1,k)$$$ and we are done. Else, $$$(i+1,j,k)$$$ is the same subsequence. Repeating this, we will always end up with $$$(l, l + 1, k)$$$ eventually for some $$$l$$$.
Now, we can simply count the number of subsequences of different lengths that are an RBS and have a subsequence "$$$)(($$$". This can be done by dynamic programming similar to counting number of subsequences that are RBS.
We define the following DP state:
$$$dp[i][b][l][k]$$$ = number of bracket sequences using first $$$i$$$ characters, with balance $$$b$$$, having length $$$l$$$ and $$$k$$$ indicates how many characters of "$$$)(($$$" occur as a subsequence in the strings.
We obtain the following cases:
If $$$s[i] =$$$ $$$($$$ and $$$k =$$$ {$$$1, 2$$$}, $$$dp[i][b + 1][l + 1][k + 1]$$$ $$$+= dp[i - 1][b][l][k]$$$
If $$$s[i] =$$$ $$$($$$ and $$$k =$$$ {$$$0, 3$$$}, $$$dp[i][b + 1][l + 1][k]$$$ $$$+= dp[i - 1][b][l][k]$$$
If $$$s[i] =$$$ $$$)$$$ and $$$k =$$$ {$$$0$$$} and $$$b \geq 1$$$, $$$dp[i][b - 1][l + 1][k + 1]$$$ $$$+= dp[i - 1][b][l][k]$$$
If $$$s[i] =$$$ $$$)$$$ and $$$k =$$$ {$$$1, 2, 3$$$} and $$$b \geq 1$$$, $$$dp[i][b - 1][l + 1][k]$$$ $$$+= dp[i - 1][b][l][k]$$$
We finally output answer as the sum over $$$dp[n][0][l][3] \times (l - 2)$$$ over all $$$l$$$.
Time Complexity: $$$O(n^3)$$$. This can also be implemented in $$$O(n^2)$$$ by not storing the length but the sum of lengths and the count separately.
#include <bits/stdc++.h>
using namespace std;
// Mint template omitted for readability
constexpr int md = 998244353;
using Mint = Modular<std::integral_constant<decay<decltype(md)>::type, md>>;
vector<Mint> fact(1, 1);
vector<Mint> inv_fact(1, 1);
Mint C(int n, int k) {
if (k < 0 || k > n) {
return 0;
}
while ((int) fact.size() < n + 1) {
fact.push_back(fact.back() * (int) fact.size());
inv_fact.push_back(1 / fact.back());
}
return fact[n] * inv_fact[k] * inv_fact[n - k];
}
int main(){
std::ios_base::sync_with_stdio(0);
std::cin.tie(0);
int T;
cin >> T;
while(T--){
int n;
cin >> n;
string s;
cin >> s;
string t = ")((";
vector<vector<vector<Mint>>> dp(4, vector(n + 1, vector(n + 1, Mint(0)))); // balance, length
dp[0][0][0] = 1;
for(int i = 0; i < n; i++){
auto ndp = dp;
int add = s[i] == '(' ? 1 : -1;
for(int bal = 0; bal < n; bal++){
for(int len = 0; len < n; len++){
if(bal + add < 0) continue;
for(int ii = 0; ii < 4; ii++){
int ni = ii;
if(ii == 0 and s[i] == ')') ni++;
if((ii == 1 or ii == 2) and s[i] == '(') ni++;
ndp[ni][bal + add][len + 1] += dp[ii][bal][len];
}
}
}
swap(dp, ndp);
}
Mint ans = 0;
for(int i = 0; i <= n; i++){
ans += dp[3][0][i] * (i - 2);
}
cout << ans << '\n';
}
}
2190C - Comparable Permutations
$$$q \gt p$$$ and $$$\mathbb{rev}(q) \gt \mathbb{rev}(p)$$$ is equivalent to the following condition: let $$$i$$$ be the first index at which $$$p$$$ and $$$q$$$ differ, and let $$$j$$$ be the last index at which $$$p$$$ and $$$q$$$ differ. Then we must have $$$q_i \gt p_i$$$ and $$$q_j \gt p_j$$$.
Fix some $$$i \lt j$$$, and consider the subarray $$$p[i, j]$$$. We can rearrange these elements however we want, as long as we increase both endpoints. It is easy to see that this is impossible if $$$p_i$$$ or $$$p_j$$$ is the maximum of the subarray. Otherwise, we want to choose the lexicographically smallest such option. Set $$$q_i$$$ to be the smallest element in $$$p[i, j]$$$ that is larger than $$$p_i$$$. Then, we place the rest of the elements in ascending order to fill $$$q[i+1, j]$$$.
Optimal $$$i = k - 1$$$, where $$$k$$$ is the largest index where $$$p_k \gt p_{k - 1}$$$ and $$$p_k \gt p_{k + 1}$$$.
$$$[k, n]$$$ is first decreasing, then increasing.
We require that $$$q \gt p$$$ and $$$\mathbb{rev}(q) \gt \mathbb{rev}(p)$$$. By definition, this is equivalent to the following condition: let $$$i$$$ be the first index at which $$$p$$$ and $$$q$$$ differ, and let $$$j$$$ be the last index at which $$$p$$$ and $$$q$$$ differ. Then we must have that $$$q_i \gt p_i$$$ and $$$q_j \gt p_j$$$.
Now, fix some $$$i \lt j$$$, and consider the subarray $$$p[i, j]$$$. We can rearrange these elements however we want, as long as we increase both endpoints. It is easy to see that this is impossible if $$$p_i$$$ or $$$p_j$$$ is the maximum of the subarray. Otherwise, we want to choose the lexicographically smallest such option. To do so, we set $$$q_i$$$ to be the smallest element in $$$p[i, j]$$$ that is larger than $$$p_i$$$. Then, we place the rest of the elements in ascending order to fill $$$q[i+1, j]$$$.
Let's verify that this is valid. Clearly, $$$q_i \gt p_i$$$ by construction. Now, $$$q_j$$$ is the maximum of $$$q[i+1, j]$$$, so either $$$q_j$$$ or $$$q_i$$$ is the maximum of $$$p[i, j]$$$. If $$$q_j$$$ is the maximum, then it must be larger than $$$p_j$$$ because $$$p_j$$$ is not the maximum. Otherwise, if $$$q_i$$$ is the maximum, then $$$p_i$$$ is the second maximum by construction, so $$$q_j = p_i$$$. Thus, $$$q_j$$$ is larger than $$$p_j$$$ because $$$p_j$$$ is not the maximum or the second maximum.
We conclude that any choice of $$$i \lt j$$$ such that $$$p_i$$$ and $$$p_j$$$ are not the maximum of $$$p[i, j]$$$ yields a valid choice of $$$q$$$, and the optimal one is the one produced by the above construction.
Now, we want to find the choice of $$$i$$$ and $$$j$$$ that yield the lexicographically smallest option. It is easy to see that we want to use the largest possible value of $$$i$$$, because we are going to keep everything before index $$$i$$$ the same, and increase the value at index $$$i$$$. Let $$$1 \lt k \lt n$$$ denote the index of the last local maximum; that is, $$$k$$$ is the largest integer satisfying $$$p_k \gt p_{k-1}, p_{k+1}$$$. Then we claim that $$$i=k-1$$$ is optimal.
First, we show that it is valid. Indeed, the subarray $$$p[i, i+2] = p[k-1, k+1]$$$ is clearly valid. Next, we show that there is no larger valid choice of $$$i$$$. Notice that $$$p[k, n]$$$ is first decreasing, then increasing (possibly over an empty subarray). If we choose $$$i \lt j$$$ contained in the decreasing portion, then $$$p_i$$$ will be the maximum of $$$p[i, j]$$$. If we choose $$$i \lt j$$$ in the increasing portion, then $$$p_j$$$ will be the maximum of $$$p[i, j]$$$. Finally, if we choose $$$i \lt j$$$ that crosses from the decreasing to the increasing portion, then $$$\max(p_i, p_j)$$$ is the maximum of $$$p[i, j]$$$. Therefore, no subarray that uses $$$i \geq k$$$ can possibly be valid.
We conclude that we must choose $$$i = k-1$$$. Notice that identical reasoning to the above proof shows that if there is no local maximum, then no valid $$$q$$$ exists, so we may output $$$-1$$$. We further observe that the value of $$$k$$$, if it exists, can be determined in $$$n-1$$$ queries of adjacent values.
Now, we want to choose the value of $$$j$$$. It is easy to see that we want to choose the largest possible value of $$$j$$$, because it gives us strictly more options of how to rearrange the subarray. Since $$$p[k, n]$$$ is decreasing then (possibly) increasing, it suffices to find the first value larger than $$$p_k$$$, then we will choose the subarray to end right before that value. If no such value exists, we can choose $$$j = n$$$.
However, we do not have to explicitly find the value of $$$j$$$. In fact, it suffices to pretend that $$$j = n$$$, and then using the construction from earlier, it will naturally follow that everything larger than the actual value of $$$j$$$ will remain untouched, since that portion of $$$p$$$ is already increasing. So now, we simply have to sort the values in $$$p[i, n]$$$, then move the one that comes directly after $$$p_i$$$ to the front.
Notice that we can split this subarray into three monotonic sections; furthermore, we know where the cutoffs for these sections are, since we have queried all adjacent values before. We can sort by finding the next minimum of the subarray one by one. We know that the next minimum must be the next minimum of one of the three sections, and since they are monotonic, we can track these with three pointers. We can find which of these three values is the smallest using two queries. In total, we sort the subarray using at most $$$2(n-1)$$$ queries. We can then move the value directly after $$$p_i$$$ to the spot $$$q_i$$$ without any additional queries.
This solves the problem using at most $$$3n$$$ queries, as desired.
#include <bits/stdc++.h>
using namespace std;
void solve() {
int n;
cin >> n;
auto ask = [&](int i, int j) {
cout << "? " << i << " " << j << endl;
int ans;
cin >> ans;
return ans;
};
int j = -1;
vector<int> val(n + 2); val[n] = 1;
for(int i = n - 1; i; i--) {
val[i] = ask(i, i + 1);
if(val[i] && !val[i + 1]) {
j = i;
break;
}
}
if(j == -1) {
cout << "! " << -1 << endl;
return;
}
// Need to sort [j + 1, n]
int k = j + 1;
while(!val[k + 1]) k++;
// [j + 1, k] - decreasing
// [k + 1, n] - increasing
vector<int> order;
int l = k, r = k + 1;
while(l > j && r <= n) {
if(ask(l, r)) order.push_back(l--);
else order.push_back(r++);
}
while(l > j) order.push_back(l--);
while(r <= n) order.push_back(r++);
l = 0, r = order.size() - 1;
while(l <= r) {
int m = l + r >> 1;
if(ask(j, order[m])) r = m - 1;
else l = m + 1;
}
assert(l < order.size());
vector<int> res(n + 1);
iota(res.begin(), res.end(), 0);
res[j] = order[l];
order[l] = j;
for(int i = j + 1; i <= n; i++) {
res[i] = order[i - j - 1];
}
res.erase(res.begin());
cout << "! "; for(auto i : res) cout << i << " "; cout << endl;
}
signed main() {
int ttt = 1;
cin >> ttt;
while(ttt--) {
solve();
}
}
- Idea: nifeshe
- Solution: nifeshe
- Editorial: Intellegent, nifeshe
Why isn't $$$P(v)$$$ always $$$n - 1$$$? Specifically, when can we delete vertex $$$n - 1$$$?
Since each tree (with $$$n \ge 2$$$) has at least two leaves, $$$n - 1$$$ can be deleted only if $$$n - 1$$$ and $$$n$$$ are the only leaves. How to find $$$P(v)$$$ using this fact?
This means that there's just a single path from $$$n$$$ to $$$n - 1$$$. In this case it's obvious that the second vertex on the path will be left at the end. Therefore, $$$P(v)$$$ is always the second vertex on the path from $$$n$$$ to $$$n - 1$$$.
To count this you really only need to consider the case when $$$v$$$ and $$$n$$$ are adjacent.
All vertices in a component are indistinguishable.
Why isn't $$$P(v)$$$ always $$$n - 1$$$? Specifically, when can we delete vertex $$$n - 1$$$?
Since each tree (with $$$n \ge 2$$$) has at least two leaves, $$$n - 1$$$ can be deleted only if $$$n - 1$$$ and $$$n$$$ are the only leaves. This means that there's just a single path from $$$n$$$ to $$$n - 1$$$. In this case it's obvious that the second vertex on the path will be left at the end. Therefore, $$$P(v)$$$ is always the second vertex on the path from $$$n$$$ to $$$n - 1$$$.
So now we just have to count the number of ways to connect the tree satisfying these conditions. The easiest case is when $$$n$$$ and $$$n - 1$$$ are in the same component, then the Prufer vertex is fixed, so making the forest a tree doesn't change it.
Let's assume that $$$n$$$ and $$$v$$$ are already connected, because if not, we have to connect them with an edge, and we can update all the needed values dynamically.
We have to connect the tree so that $$$n - 1$$$ is in the subtree of $$$v$$$ (when rooted at $$$n$$$).
Let $$$C$$$ be the set of vertices in the component of $$$n$$$. Notice that since all vertices in $$$C$$$ are indistinguishable, the component with $$$n - 1$$$ will be attached to the component of $$$n$$$ to each vertex in $$$C$$$ in the same number of final trees.
Let $$$k$$$ be the size of the subtree of $$$v$$$. Then in $$$\dfrac{k}{|C|}$$$ of all trees $$$n - 1$$$ will be connected to $$$n$$$ through a subtree of $$$v$$$.
Therefore, we just need to maintain the total number of ways to complete the tree and after adding edges from $$$n$$$ to $$$v$$$, and multiply that value by $$$\dfrac{k}{|C|}$$$ to solve the problem.
Time complexity: $$$O(n)$$$ or $$$O(n \log n)$$$.
#include <bits/stdc++.h>
using namespace std;
const int mod = 998244353;
// Removed Mint template for better readability
vector<Mint> get(vector<vector<int>> g) {
int n = g.size() - 1;
vector<int> comp(n + 1, -1), dp(n + 1, 1), parent(n + 1), sizes(n);
int k = 0;
function<void(int, int)> dfs = [&](int v, int p) {
comp[v] = k; sizes[k]++;
for(auto to : g[v]) {
if(to == p) continue;
parent[to] = v;
dfs(to, v);
dp[v] += dp[to];
}
};
for(int v = n; v; v--) {
if(comp[v] == -1) {
dfs(v, 0);
k++;
}
}
vector<int> sz(n + 1);
for(int v = 1; v <= n; v++) sz[v] = sizes[comp[v]];
vector<Mint> inv(n + 1); inv[1] = 1;
for(int i = 2; i <= n; i++) {
inv[i] = mod - inv[mod % i] * (mod / i);
}
vector<Mint> ans(n);
Mint p = 1;
for(int i = 0; i < k; i++) p *= sizes[i];
vector<Mint> n_power(n + 1);
n_power[0] = 1; for(int i = 1; i <= n; i++) n_power[i] = n_power[i - 1] * n;
auto n_pow = [&](int k) {
if(k >= 0) return n_power[k];
else if(k == -1) return inv[n];
else assert(0);
};
if(comp[n] == comp[n - 1]) {
// If n and n - 1 are already in one component P(T) is determined
int v = n - 1;
while(parent[v] != n) v = parent[v];
ans[v] = p * n_pow(k - 2);
}
else {
for(int v = 1; v <= n - 1; v++) {
if(comp[v] == comp[n]) {
// v and n have to be connected
if(parent[v] != n) continue;
ans[v] = dp[v] * p * inv[sz[n]] * n_pow(k - 2);
}
else if(comp[v] == comp[n - 1]) {
// Just connect v and n
ans[v] = p * inv[sz[n]] * inv[sz[n - 1]] * (sz[n] + sz[n - 1]) * n_pow(k - 3);
}
else {
// Connect v and n and same as first case
ans[v] = sz[v] * p * inv[sz[n]] * inv[sz[v]] * n_pow(k - 3);
}
}
}
return ans;
}
void solve() {
int n, m;
cin >> n >> m;
vector<vector<int>> g(n + 1);
for(int i = 0; i < m; i++) {
int u, v;
cin >> u >> v;
g[u].push_back(v); g[v].push_back(u);
}
vector<Mint> ans = get(g);
for(int v = 1; v < n; v++) cout << ans[v] << ' '; cout << endl;
}
signed main() {
ios_base::sync_with_stdio(0); cin.tie(0);
int ttt = 1;
cin >> ttt;
while(ttt--) {
solve();
}
}
Special thanks to Sana for showing me how to go from $$$O(n^2)$$$ to $$$O(n)$$$.
If you bruteforce and oeis, you'll find out that the total number of valid permutations is $$$n \cdot 2^{n - 2}$$$. You should forget about this, trying to prove this directly is not gonna work.
Consider the case where $$$p_1 = 1$$$ and $$$p_n = n$$$.
Look at even and odd indices separately.
When $$$p_1 = 1$$$ and $$$p_n = n$$$, the condition is that $$$p_{i - 2} \lt p_i$$$ must hold for all $$$i$$$. Try to generalize this condition for other cases.
If $$$p_{i - 2} \lt p_i \gt p_{i + 2}$$$, we must have $$$p_i = n$$$, so even and odd indices are almost monotonic.
Consider a case where $$$p_1 \lt p_3$$$ and $$$p_2 \gt p_4$$$ and the restrictions this puts on the problem.
The two cases above are sufficient, try to make them easier two count.
There are $$$2$$$ chains of increasing values.
Notice that $$$1$$$ and $$$n$$$ can never be medians, so $$$f(p)$$$ has to be a permutation of $$${ 2, \ldots, n }$$$.
Suppose that we have 5 consecutive elements $$$[p_1, p_2, p_3, p_4, p_5]$$$, and $$$p_1 \lt p_3 \gt p_5$$$. WLOG, assume that $$$p_2 \lt p_4$$$. It turns out there's a very tight condition for this case to not have duplicates. Mainly, $$$p_3$$$ has to be the largest element.
Suppose $$$p_4$$$ is the largest element instead. Median of $$$[3, 5]$$$ is $$$p_3$$$. For $$$[2, 4]$$$ to not have $$$p_3$$$ as the median, we must have $$$p_3 \lt p_2 \lt p_4$$$, and the median of $$$[2, 4]$$$ is $$$p_2$$$. But then in $$$[1, 3]$$$ we have $$$p_1 \lt p_3 \lt p_2$$$, so $$$p_3$$$ is the median again, which is a contradiction.
Notice that since $$$p_3$$$ is the largest element among all $$$3$$$ subarrays in which it takes part in, $$$p_3$$$ cannot appear in $$$f(p)$$$. Therefore, an important observation is: if $$$p_{i - 2} \lt p_i \gt p_{i + 2}$$$, then $$$p_i = n$$$. Similarly, if $$$p_{i - 2} \gt p_i \lt p_{i + 2}$$$, then $$$p_i = 1$$$.
From this we can see that all indices with the same parity are almost monotonic. But how do even and odd indices interact with each other?
Let's consider another case: $$$[p_1, p_2, p_3, p_4]$$$, $$$p_1 \lt p_3$$$ and $$$p_2 \gt p_4$$$ (odd is increasing, even is decreasing). We can see that this case also has a simple structure. Mainly, if we bruteforce (to not consider a lot of cases) all valid permutations of size $$$4$$$ that satisfy the two inequalities above, we'll get only two solutions: $$$[1, 4, 2, 3]$$$ and $$$[3, 2, 4, 1]$$$. This means that either all even indices have values greater than all odd indices, or vice versa.
The two conditions we found are actually already sufficient, and it's very easy to prove this.
Suppose $$$f(p)_i = f(p)_j$$$ with $$$i \lt j$$$, so $$$p$$$ is invalid. Notice that for this to happen $$$[i, i + 2]$$$ and $$$[j, j + 2]$$$ have to both include the same value in $$$p$$$, so $$$[i, i + 2]$$$ and $$$[j, j + 2]$$$ have to intersect, so $$$i + 2 \ge j$$$, or $$$j - i \le 2$$$. Therefore, it is sufficient to check that there are no "bad" subarrays $$$[i, i + 4]$$$, and if all subarrays of size $$$5$$$ are valid in $$$p$$$, $$$p$$$ is valid as well.
Using this and our two conditions above we can just check all permutations of size $$$5$$$ and verify that they are sufficient.
So now we only have to understand how to count. The conditions we have are actually pretty restrictive.
WLOG, assume that $$$1$$$ is located earlier than $$$n$$$.
First consider the case where $$$pos_1$$$ and $$$pos_n$$$ have the different parity.
Consider the picture below. Each arrow denotes that the element should be smaller than the element arrow points to. Let's see how even and odd indices compare to each other.
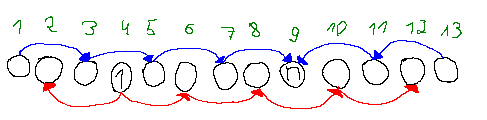
Look at $$$i = 2$$$. We have $$$p_2 \gt p_4$$$ and $$$p_3 \lt p_5$$$, which is the second condition we had. Since $$$p_4 = 1$$$, we must have $$$p_4 \lt p_2 \lt p_3 \lt p_5$$$. For $$$i = 1$$$ the same thing holds, and since we already know that $$$p_3 \gt p_2$$$ (and all odd indices in this case must have a larger element than even indices), we must have $$$p_4 \lt p_2 \lt p_1 \lt p_3 \lt p_5$$$.
The same thing happens after $$$n$$$ on the right side, we must have: $$$p_{10} \lt p_{12} \lt p_{13} \lt p_{11} \lt p_9$$$, so essentially can add two new (purple) arrows to the picture:
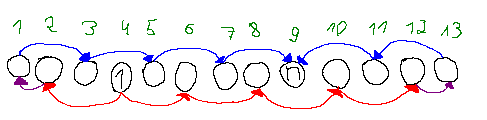
And after some recoloring, we can see that the when $$$1$$$ and $$$n$$$ are located on different parities, there must be two chains of values:
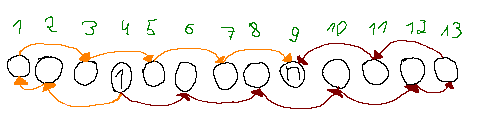
After applying the same logic, we get a similar situation when $$$1$$$ and $$$n$$$ are located on the same parity:
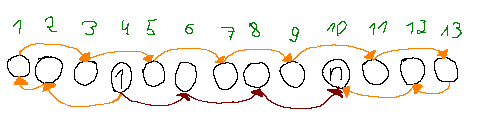
From this we can see that in all cases there are at most two increasing chains (dark-red and orange on the two pictures above).
Since we know the positions of $$$1$$$ and $$$n$$$, the problem now transformed into: given two chains of increasing values, we have to count the number of ways to put all values $$$1, 2, \ldots, n$$$ into the chains with some values already being placed.
Suppose we have two chains $$$a$$$ and $$$b$$$ with sizes $$$k$$$ and $$$l$$$, and we know that some $$$a_i = x$$$. Notice that this means that $$$i - 1$$$ of the $$$x - 1$$$ elements before $$$x$$$ have to be in $$$a$$$, and all the others must be in $$$b$$$. This means that we can go through all placed elements and count the number of ways to position the unplaced ones using binomial coefficients. You can read the code for better understanding.
Time complexity: $$$O(n)$$$.
#include <bits/stdc++.h>
using namespace std;
const long long mod = 998244353;
const int MAX = 2e5 + 42;
// Mint template omitted for readability
Mint fact[MAX], inv[MAX];
Mint C(int n, int k) {
if(n < k || k < 0) return 0;
return fact[n] * inv[k] * inv[n - k];
}
Mint get(vector<int> p) {
int n = p.size();
int pos_1 = -1, pos_n = -1;
for(int i = 0; i < n; i++) {
if(p[i] == 1) pos_1 = i;
if(p[i] == n) pos_n = i;
}
assert(pos_1 != -1);
assert(pos_n != -1);
if(pos_1 > pos_n) {
reverse(p.begin(), p.end());
pos_1 = n - 1 - pos_1;
pos_n = n - 1 - pos_n;
}
vector<vector<int>> g(n + 1);
if(pos_1 % 2 == pos_n % 2) {
for(int i = (pos_1 & 1 ^ 1); i < n; i += 2) {
if(i >= 2) g[i - 2].push_back(i);
}
for(int i = pos_1 - 2; i >= 0; i -= 2) {
g[i + 2].push_back(i);
}
for(int i = pos_1 + 2; i <= pos_n; i += 2) {
g[i - 2].push_back(i);
}
for(int i = pos_n + 2; i < n; i += 2) {
g[i].push_back(i - 2);
}
}
else {
for(int i = pos_1 - 2; i >= 0; i -= 2) {
g[i + 2].push_back(i);
}
for(int i = pos_1 + 2; i < n; i += 2) {
g[i - 2].push_back(i);
}
for(int i = pos_n - 2; i >= 0; i -= 2) {
g[i].push_back(i + 2);
}
for(int i = pos_n + 2; i < n; i += 2) {
g[i].push_back(i - 2);
}
}
if(pos_1 != 0) {
if(pos_1 % 2 == 0) g[0].push_back(1);
if(pos_1 % 2 == 1) g[1].push_back(0);
}
if(pos_n != 0) {
if(pos_n % 2 == (n - 1) % 2) g[n - 2].push_back(n - 1);
if(pos_n % 2 != (n - 1) % 2) g[n - 1].push_back(n - 2);
}
g[pos_1].clear();
for(int i = 0; i < n; i++) {
if(i == pos_1 || i == pos_n) continue;
assert(g[i].size() == 1);
if(g[i][0] == pos_n) g[i].clear();
}
vector<int> in_degree(n);
for(int v = 0; v < n; v++) {
for(auto to : g[v]) in_degree[to]++;
}
vector<pair<int, int>> pos(n + 1);
int t = 0, cnt = 0;
for(int i = 0; i < n; i++) {
if(i == pos_1 || i == pos_n || in_degree[i] > 0) continue;
t++;
cnt = 0;
if(t == 1) pos[1] = {t, cnt++};
int j = i;
while(1) {
pos[p[j]] = {t, cnt++};
if(g[j].empty()) break;
j = g[j][0];
}
}
pos[n] = {t, cnt};
Mint ans = 1;
for(int i = 1; i < n; i++) {
int j = i + 1;
while(pos[j].first == 0) j++;
auto [ti, ci] = pos[i]; ci++;
auto [tj, cj] = pos[j];
if(ti == 2) ci = i - ci;
if(tj == 2) cj = j - 1 - cj;
// At i we have ci in first, at j - 1 we have cj
// Choose cj - ci from j - i - 1
ans *= C(j - i - 1, cj - ci);
i = j - 1;
}
return ans;
}
void solve() {
int n;
cin >> n;
vector<int> p(n);
for(auto &i : p) {
cin >> i;
}
Mint ans = get(p);
cout << ans << '\n';
}
signed main() {
fact[0] = 1; for(int i = 1; i < MAX; i++) fact[i] = fact[i - 1] * i;
inv[MAX - 1] = 1 / fact[MAX - 1];
for(int i = MAX - 1; i; i--) inv[i - 1] = inv[i] * i; assert(inv[0] == 1);
ios_base::sync_with_stdio(0); cin.tie(0);
int ttt = 1;
cin >> ttt;
while(ttt--) {
solve();
}
}
- Idea: nika-skybytska
- Solution: nifeshe
- Editorial: nifeshe
Find a formula for $$$S(0, 0, k)$$$
Find a formula for $$$S(x, x, k)$$$
You can assume that $$$x$$$ and $$$x + k - 1$$$ have no non-zero common prefix. Let $$$p$$$ be the most significant bit $$$2$$$ of $$$x + k - 1$$$, $$$a = P - 1 - x$$$ and $$$b = x + k - 1 - P$$$. Then $$$S(x, x, k) = S(0, 0, \max(a + 1,\ b + 1)) \ \cup\ [2^{p + 1} - 1 - f(a, b),\ 2^{p + 1} - 1]$$$.
Find a formula for $$$S(x, y, k)$$$
You can't assume that $$$x$$$ and $$$x + k - 1$$$ have no common prefix, but try to solve when they don't for now
Denote $$$P_x$$$, $$$a$$$ and $$$b$$$ as in Hint 3, and similarly $$$P_y$$$, $$$c$$$ and $$$d$$$ for $$$y$$$. When $$$P_x = P_y = P$$$, the formula is $$$S(x, y, k) = [0, \max(f(b, d), f(a, c)] \cup [2P - 1 - \max(f(a, d), f(b, c), 2P - 1]$$$. Solve when $$$P_x \neq P_y$$$.
Assume $$$P_x \lt P_y$$$. $$$S(x, y, k) = [Py - Px - 1 - \min(f(b, c), Px - 1), Py - Px + \min(f(a, c), Px - 1)] \cup $$$ $$$[Py + Px - 1 - \min(f(a, d), Px - 1), Py + Px + \min(f(b, d), Px - 1)]$$$.
Common non-zero prefix doesn't change the size of $$$S$$$, so in general the formula for size is $$$|S(x, y, k)| = \min\left(f(a, c) + f(b, c) + 2,\ 2P_x\right)\ +\ \min\left(f(a, d) + f(b, d) + 2,\ 2P_x\right)$$$. Use digit dp to solve the problem.
A few notations:
- $$$S(x, y, k) = {(x + i) \oplus (y + j) \mid 0 \le i \lt k,\ 0 \le j \lt k}$$$.
- $$$S(x, y, k, l) = {(x + i) \oplus (y + j) \mid 0 \le i \lt k,\ 0 \le j \lt l}$$$.
- $$$[l, r] \oplus x = {i \oplus x \mid l \le i \le r}$$$.
- $$$[l_1, r_1] * [l_2, r_2] = {i \oplus j \mid l_1 \le i \le r_1,\ l_2 \le j \le r_2}$$$ (We'll call this the XOR Cartesian product).
Let's try to find a formula for a general $$$S(x, y, k)$$$. Consider the simplified case $$$x = y$$$.
If $$$x = y = 0$$$, we can achieve every XOR value up to the maximum possible XOR. Let $$$p$$$ be the smallest integer such that $$$2^p \ge k$$$. Then $$$S(0, 0, k) = [0,\ 2^p - 1]$$$.
When $$$x \neq y$$$, notice that $$$x$$$ and $$$x + k - 1$$$ share some common prefix of bits. Let its length be $$$L$$$. That prefix is present in all $$$x + i$$$ and $$$x + j$$$, so it cancels out in XOR. Therefore, we can zero out the top $$$L$$$ bits and assume $$$\lfloor \log_2 x \rfloor \neq \lfloor \log_2 (x + k - 1) \rfloor$$$.
Let $$$p = \lfloor \log_2 (x + k - 1)\rfloor$$$ and $$$P = 2^p$$$. Then $$$x$$$ does not have the bit $$$P$$$ set, and we can split: - $$$[x,\ P - 1]$$$ - $$$[P,\ x + k - 1]$$$
Now write $$$S(x, x, k)$$$ as the union of XOR-products of these two ranges (there are 3 distinct ones, since cross terms are symmetric).
Define $$$a = (P - 1) - x, \quad b = (x + k - 1) - P$$$.
Product A: $$$[P,\ x + k - 1] * [P,\ x + k - 1]$$$. All numbers in $$$[P,\ x + k - 1]$$$ have the bit $$$P$$$ set, so it cancels in XOR. After removing that bit: $$$ [P,\ x + k - 1] * [P,\ x + k - 1] = S(0, 0, b + 1)$$$. (Here $$$b + 1 = (x + k - 1) - P + 1 = x + k - P$$$.)
Product B: $$$[x,\ P - 1] * [x,\ P - 1]$$$. This is similar to the $$$S(0, 0, \cdot)$$$ case but taken from the other side. Replace each $$$t \in [x,\ P - 1]$$$ with $$$t \oplus (P - 1)$$$, which equals to $$$(P - 1) - t$$$. Since we XOR both sides, the set of XORs does not change, and we get: $$$[x,\ P - 1] * [x,\ P - 1] = S(0, 0, a + 1)$$$ (here $$$a + 1 = (P - 1 - x) + 1 = P - x$$$).
Product C, the hardest case: $$$[x,\ P - 1] * [P,\ x + k - 1]$$$ Apply the same transforms:
$$$[x,\ P - 1] \to [0,\ a]$$$
$$$[P,\ x + k - 1] \to [0,\ b]$$$
But now the “removed masks” do not cancel out, so at the end we must XOR by $$$(P - 1) \oplus P = 2^{p + 1} - 1$$$.
So: $$$[x,\ P - 1] * [P,\ x + k - 1] = S(0, 0, a + 1, b + 1)\ \oplus\ (2^{p + 1} - 1)$$$.
Let's understand how to find $$$S(0, 0, k, l)$$$. Claim: $$$S(0, 0, k, l)$$$ is a single interval, or $$$S(0, 0, k, l) = [0, f(k - 1, l - 1)]$$$, where $$$f(n, m)$$$ is the largest XOR of $$$0 \le i \le n$$$ and $$$0 \le j \le m$$$.
The claim is that the interval is $$$[0, M]$$$, where $$$M = f(k - 1,\ l - 1) = \max_{0 \le i \lt k,\ 0 \le j \lt l} (i \oplus j)$$$.
This is true because if we can obtain XOR value $$$C$$$, we can also obtain $$$C - 1$$$. Take the most significant bit where $$$C$$$ and $$$C - 1$$$ differ and flip that bit by adjusting either $$$i$$$ or $$$j$$$ (whichever has that bit set), then adjust lower bits as needed. This does not increase $$$i$$$ or $$$j$$$, so it stays within bounds.
It's not hard to compute $$$f(n, m)$$$ in general.
Let $$$p$$$ be the index of the most significant set bit in $$$(n & m)$$$. Then $$$f(n, m) = n\ \vert\ m\ \vert\ (2^p - 1)$$$.
Using this, Product C becomes an interval: $$$S(0,0,a + 1,b + 1)\oplus (2^{p + 1} - 1) = [0,\ f(a, b)]\ \oplus\ (2^{p + 1} - 1) = [2^{p + 1} - 1 - f(a, b),\ 2^{p + 1} - 1]$$$.
So, combine the three parts: $$$S(x, x, k) = S(0, 0, a + 1)\ \cup\ S(0, 0, b + 1)\ \cup\ [2^{p + 1} - 1 - f(a, b),\ 2^{p + 1} - 1]$$$.
This can be simplified to: $$$S(x, x, k) = S(0, 0, \max(a + 1,\ b + 1)) \ \cup\ [2^{p + 1} - 1 - f(a, b),\ 2^{p + 1} - 1]$$$.
Now handle $$$x \ne y$$$ similarly. First assume that: $$$x$$$ and $$$x + k - 1$$$ have no common non-zero prefix bits (after stripping common prefix as before, though in this case it's not obvious that this will not change the set, but we'll handle this later), and similarly for $$$y$$$.
Let: $$$p_x = \lfloor \log_2(x + k - 1)\rfloor,\quad P_x = 2^{p_x}$$$, $$$p_y = \lfloor \log_2(y + k - 1)\rfloor,\quad P_y = 2^{p_y}$$$.
Split into four intervals: - $$$[x,\ P_x - 1]$$$, $$$[P_x,\ x + k - 1]$$$ - $$$[y,\ P_y - 1]$$$, $$$[P_y,\ y + k - 1]$$$
Define $$$a = (P_x - 1) - x,\quad b=(x + k - 1) - P_x$$$, $$$c = (P_y - 1) - y,\quad d=(y + k - 1) - P_y$$$.
Now consider the four products:
$$$I_1 = [x, P_x - 1] * [y, P_y - 1] = [0, f(a, c)] \oplus (P_x - 1) \oplus (P_y - 1)$$$
$$$I_2 = [P_x, x + k - 1] * [P_y, y + k - 1] = [0, f(b, d)] \oplus P_x \oplus P_y$$$
$$$I_3 = [x, P_x - 1] * [P_y, y + k - 1] = [0, f(a, d)] \oplus (P_x - 1) \oplus P_y$$$
$$$I_4 = [P_x, x + k - 1] * [y, P_y - 1] = [0, f(b, c)] \oplus P_x \oplus (P_y - 1)$$$
Notice that the $$$P_x = P_y = P$$$ case is trivial, we already almost solved it, and by the same reasoning $$$S(x, y, k) = [0, \max(f(b, d), f(a, c)] \cup [2P - 1 - max(f(a, d), f(b, c), 2P - 1]$$$ in this case.
Now WLOG assume $$$P_x \lt P_y$$$. We have $$$a + b = c + d = k - 2$$$. Notice that $$$a, b \lt P_x$$$ (since $$$a = P_x - 1 - x$$$ and $$$P_x + b \lt 2P_x$$$). Also notice that $$$c, d \lt 2P_x$$$, since $$$\max(a, b) \le \dfrac{k}{2} \lt P_x$$$, so $$$k \lt 2P_x$$$ and $$$c + d = k - 2$$$.
Consider $$$I_2 = [0, f(b, d)] \oplus P_x \oplus P_y$$$. Since $$$P_x \lt P_y$$$, write $$$P_x \oplus P_y = P_x + P_y$$$. Also $$$f(b, d) \lt 2P_x$$$.
If $$$f(b, d) \lt P_x$$$, then $$$I_2 = [P_x + P_y,\ P_x + P_y + f(b, d)]$$$
If $$$f(b, d) \ge P_x$$$, then $$$[0, f(b, d)]$$$ contains $$$P_x$$$, and we get: $$$I_2 = [P_y,\ P_y + (f(b, d) - P_x)]\ \cup\ [P_x + P_y,\ P_y + 2P_x - 1]$$$.
Now consider $$$I_3 = [0, f(a, d)] \oplus (P_x - 1) \oplus P_y$$$. XORing by $$$(P_x - 1)$$$ is just a reversal inside $$$[0, P_x - 1]$$$ and separately inside $$$[P_x, 2P_x - 1]$$$.
If $$$f(a, d) \lt P_x$$$, then $$$I_3 = [P_y + (P_x - 1 - f(a, d)),\ P_y + (P_x - 1)]$$$
If $$$f(a, d) \ge P_x$$$, then $$$I_3 = [P_y,\ P_y + (P_x - 1)]\ \cup\ [P_y + (2P_x - 1 - f(a, d)),\ P_y + (2P_x - 1)]$$$
An important observation is that if $$$d \ge P_x$$$, then $$$f(a, d), f(b, d) \ge P_x$$$, and $$$f(a, d), f(b, d) \lt P_x$$$ otherwise, since $$$a, b \lt P_x$$$. So:
If $$$d \ge P_x$$$, then $$$I_2 \cup I_3 = [P_y,\ P_y + 2P_x - 1]$$$
If $$$d \lt P_x$$$, then $$$I_2 \cup I_3 = [P_y + P_x - 1 - f(a, d),\ P_y + P_x + f(b, d)]$$$
So in all cases, $$$I_2 \cup I_3$$$ is exactly one interval, and its length is: $$$|I_2 \cup I_3| = \min\left( f(a, d) + f(b, d) + 2,\ 2P_x \right)$$$.
The other two intervals are similar, except now we XOR by $$$(P_y - 1)$$$ instead of $$$P_y$$$. We can rewrite this as $$$(P_x - 1) \oplus (P_y - 1) = (P_x \oplus P_y) \oplus (P_x - 1) \oplus (P_y - 1) = (P_y - 2P_x) \oplus P_x$$$.
From this we can get a similar result:
If $$$c \ge P_x$$$, $$$I_1 \cup I_4 = [P_y - 2P_x,\ P_y - 1]$$$
If $$$c \lt P_x$$$, $$$I_1 \cup I_4 = [P_y - P_x - 1 - f(b, c),\ P_y - P_x + f(a, c)]$$$
So again we get exactly one interval, and $$$|I_1 \cup I_4| = \min\left( f(a, c) + f(b, c) + 2,\ 2P_x \right)$$$.
Notice that the two cases never intersect:
$$$I_1 \cup I_4$$$ is inside $$$[P_y - 2P_x,\ P_y - 1]$$$.
$$$I_2 \cup I_3$$$ is inside $$$[P_y,\ P_y + 2P_x - 1]$$$.
Therefore $$$|S(x, y, k)| = |I_1 \cup I_4| + |I_2 \cup I_3| = \min\left(f(a, c) + f(b, c) + 2,\ 2P_x\right)\ +\ \min\left(f(a, d) + f(b, d) + 2,\ 2P_x\right)$$$
Remember that we had assumed that $$$x$$$ and $$$x + k - 1$$$ had no common non-zero prefix bits (and same for $$$y$$$). If they do, let $$$X$$$ be that common prefix value for $$$x$$$ and $$$Y$$$ for $$$y$$$. Then every element of $$$S(x, y, k)$$$ is XORed by $$$X \oplus Y$$$.
However, notice that $$$X, Y \ge 2P_x$$$, since $$$P_x$$$ is the first bit that differs in $$$x$$$ and $$$x + k - 1$$$, and if we XOR by a bit after $$$P_x$$$ the values will just shift, but the size won't change. So when $$$x$$$ and $$$x + k - 1$$$ have a common prefix, we can just get rid of it without changing the size of $$$S$$$.
Now we can solve the original problem, where $$$x$$$ is fixed. If $$$P_x = P_y$$$ the size of always smaller than when not, so we only have to consider the case when $$$P_x \neq P_y$$$. In fact, it is always optimal to have $$$P_y \gt P_x$$$, because having a smaller $$$P_y$$$ will trigger the $$$2P_x$$$ part of the formula.
We have $$$a$$$ and $$$b$$$ fixed from $$$x$$$, so the formula we need to optimize is: $$$\min\left(f(a, c) + f(b, c) + 2,\ 2P_x\right)\ +\ \min\left(f(a, k - 2 - c) + f(b, k - 2 - c) + 2,\ 2P_x\right)$$$ over all $$$0 \le c \le k - 2$$$. We can easily do that with digit dp in $$$O(\log k)$$$ with a constant factor of around $$$100$$$, which solves the problem.
#include <bits/stdc++.h>
using namespace std;
template <typename T> inline bool umax(T &a, const T &b) { if(a < b) { a = b; return 1; } return 0; }
const long long inf = 4.1e18;
const int LG = 61;
long long get_different(long long power, long long k, long long A) {
long long B = k - A;
vector<vector<long long>> dp(2, vector<long long>(16, -inf));
dp[0][0] = 0;
int cnt_states = 0;
for(int L = LG - 1; ~L; L--) {
vector<vector<long long>> ndp(2, vector<long long>(16, -inf));
for(int C = 0; C < 2; C++) {
for(int cd = 0; cd < 4; cd++) {
int a = A >> L & 1;
int b = B >> L & 1;
int c = cd >> 1;
int d = cd & 1;
int new_C = (k >> L & 1) ^ c ^ d;
if((new_C + c + d >= 2) != C) continue;
for(int mask = 0; mask < 16; mask++) {
if(dp[C][mask] < 0) continue;
// ac - 0, ad - 1, bc - 2, bd - 3
int new_mask = mask;
long long add = 0;
if((1ll << L) >= power && c) add += (2ll << L) - 2, new_mask |= (1 << 0) | (1 << 2);
if((1ll << L) >= power && d) add += (2ll << L) - 2, new_mask |= (1 << 1) | (1 << 3);
if((new_mask >> 0 & 1 ^ 1) && (a & c)) add += (1ll << L + 1) - 1, new_mask |= 1 << 0;
if((new_mask >> 1 & 1 ^ 1) && (a & d)) add += (1ll << L + 1) - 1, new_mask |= 1 << 1;
if((new_mask >> 2 & 1 ^ 1) && (b & c)) add += (1ll << L + 1) - 1, new_mask |= 1 << 2;
if((new_mask >> 3 & 1 ^ 1) && (b & d)) add += (1ll << L + 1) - 1, new_mask |= 1 << 3;
if(new_mask >> 0 & 1 ^ 1) add += ((long long) (a | c)) << L;
if(new_mask >> 1 & 1 ^ 1) add += ((long long) (a | d)) << L;
if(new_mask >> 2 & 1 ^ 1) add += ((long long) (b | c)) << L;
if(new_mask >> 3 & 1 ^ 1) add += ((long long) (b | d)) << L;
cnt_states++;
long long cand = dp[C][mask] + add;
umax(ndp[new_C][new_mask], cand);
}
}
}
dp = ndp;
}
long long best = -inf;
for(int mask = 0; mask < 16; mask++) {
umax(best, dp[0][mask]);
}
return best + 4;
}
long long get(long long x, long long k) {
if(k == 1) return 1;
int px = __lg(x ^ x + k - 1);
long long Px = 1ll << px;
x &= Px * 2 - 1;
long long a = Px - 1 - x;
return get_different(Px, k - 2, a);
}
void solve() {
long long k, x;
cin >> x >> k;
cout << get(x, k) << '\n';
}
signed main() {
ios_base::sync_with_stdio(0); cin.tie(0);
int ttt = 1;
cin >> ttt;
while(ttt--) {
solve();
}
}
$$$|\operatorname{det}(A)| \le 1$$$ for all $$$A$$$ and $$$X = 1$$$ for all $$$n$$$. Find an easy way to calculate the determinant.
Try to determine when the determinant is $$$0$$$. Try to calculate it $$$\operatorname{mod} 2$$$.
Add an extra column to the matrix and look at the difference array for each row.
Since each row has exactly $$$2$$$ ones now, the determinant is $$$0$$$ iff there's a cycle in a graph with $$$n + 1$$$ vertices and edges $$$(l_i, r_i + 1)$$$. In other words, the determinant is non-zero when the graph is a tree.
Determine if the determinant is $$$-1$$$ or $$$1$$$. When $$$l_i = r_i$$$ for all $$$i$$$, the determinant is a parity of a permutation, so try to transform it into that form.
Root the tree at $$$n + 1$$$, let $$$p_v$$$ be the parent of vertex $$$v$$$, and $$$f(v)$$$ be the index of the edge $$$(v, p_v)$$$.
Let $$$k$$$ be the number of $$$v$$$ that $$$p_v \lt v$$$, and let $$$q$$$ be the permutation with $$$q_{f(v)} = v$$$. Then $$$\operatorname{det}(A) = (-1)^k \cdot \operatorname{sgn}(q)$$$.
For the original problem, first solve when $$$\operatorname{det}(A) = -1$$$. If you change two edges, you can always swap them to negate the sign of the determinant, so it's sufficient to determine for each edge if we can negate the sign by editing it.
Try to change edge $$$v \rightarrow p_v$$$ to $$$u \rightarrow p_v$$$, where $$$u$$$ is a direct child of $$$v$$$.
If we replace $$$v \rightarrow p_v$$$ with $$$x \rightarrow y$$$, where $$$x$$$ is in the subtree of $$$v$$$ and $$$y$$$ is outside of subtree of $$$v$$$, the determinant is simply multiplied by $$$-1^{[v \gt p_v] + [x \gt y]}$$$. It is sufficient to check two extreme cases there.
If $$$\operatorname{det}(A) = 0$$$ and there are at least $$$3$$$ components, the answer is the weight of a transformed MST.
If there are exactly $$$2$$$ components, apply the same logic as in the solution for $$$-1$$$. In particular, there's a cycle and we have to change an edge in it to connect two components.
First let's find an easy way to calculate the determinant of a fixed $$$A$$$. We can easily see that $$$\operatorname{det}(A) \in [-1, 0, 1]$$$ for any $$$A$$$.
If there's no ones in the first column, the determinant is $$$0$$$. Otherwise, let $$$i$$$ be the row with $$$l_i = 1$$$ and $$$r_i$$$ being as small as possible. We can subtract this row from all others, and then expand on that row using the Cramer's rule. This multiplies the determinant by $$$-1$$$ or $$$1$$$ and get rids of one row and one column, so we can apply induction.
Let's first of all understand when it is $$$0$$$, so in other words we need to find if the determinant is even.
Notice that replacing each row with its difference array is a linear transformation, because we can set $$$a_{i, j} = a_{i, j} - a_{i, j - 1}$$$ for all $$$j$$$ simultaneously, and do that for all $$$i$$$ from the end.
Therefore, let's add an extra column so that the matrix is $$$n$$$ by $$$n + 1$$$ now, and replace each row with its difference array. Now every row has exactly one $$$1$$$ and exactly one $$$-1$$$, or exactly two $$$1$$$'s when looked at $$$\operatorname{mod} 2$$$.
So we have $$$n$$$ binary strings of size $$$n + 1$$$ with two $$$1$$$'s in each string and we want to determine if they are linearly independent.
The solution to this is known, and the strings are linearly independent iff there are no cycles in a graph with $$$n + 1$$$ vertices and $$$n$$$ edges $$$(x_i, y_i)$$$.
Therefore, the determinant is $$$0$$$ iff there is a cycle in a graph with $$$n + 1$$$ vertices and $$$n$$$ edges $$$(l_i, r_i + 1$$$) (since each row got replaced with a difference array, so the last $$$1$$$ shifted to a $$$-1$$$ in the next index).
If the graph is a tree, the determinant is $$$1$$$ or $$$-1$$$. Let's learn to determine which one it is.
Notice that if $$$l_i = r_i$$$ for all $$$i$$$, the determinant is the parity of a permutation, so it clearly can't be simplified beyond that, so let's try to get it down to that.
Let's try to transform the matrix into a permutation. Consider the following matrix:
The tree of this matrix looks like this:
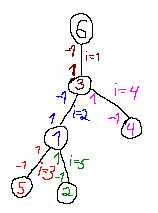
Denote $$$p_v$$$ as the parent of vertex $$$v$$$, $$$f(v)$$$ as the index of a row with $$$v$$$ and $$$p_v$$$. If $$$p_v = n + 1$$$ holds for all $$$v$$$, $$$p_v$$$ has a $$$-1$$$ and $$$v$$$ has $$$1$$$ at $$$f(v)$$$-th row, we are simply in a case of a permutation that was discussed earlier, so let's transform the matrix into that.
Let's make it so $$$p_v$$$ has a $$$-1$$$ and $$$v$$$ has $$$1$$$, so multiply $$$f(v)$$$-th row by $$$-1$$$ if $$$p_v \lt v$$$:
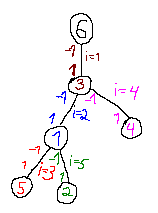
Now we can iteratively move $$$p_v \neq n + 1$$$ to $$$p_{p_v}$$$ by adding $$$f(p_v)$$$ to $$$f(v)$$$. For example, in the picture above for $$$v = 4$$$ we add $$$i = 1$$$ to $$$i = 4$$$ and get a new tree:
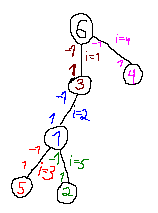
This way we can transform the matrix to have $$$p_v = n + 1$$$:
\xrightarrow{v = 4,\ r_4 \leftarrow r_4 + r_1} $$$
\xrightarrow{v = 2,\ r_5 \leftarrow r_5 + r_2} $$$
\xrightarrow{v = 5,\ r_3 \leftarrow r_3 + r_2} $$$
\xrightarrow{v = 1,\ r_2 \leftarrow r_2 + r_1} $$$
\xrightarrow{v = 3,\ r_3 \leftarrow r_3 + r_1} $$$
\xrightarrow{v = 5,\ r_5 \leftarrow r_5 + r_1} $$$
At the end we end up with a $$$p_v = n + 1$$$ for all $$$v$$$, and since the last column doesn't actually exist in the matrix, the matrix is just a permutation, and we can find its sign.
Notice an imporant fact: during our operations $$$f(v)$$$ didn't change, only $$$p_v$$$ did, so at the end we will always end up with the permutation $$$q$$$ of size $$$n$$$ with $$$q_{f(v)} = v$$$.
To sum it up, to find the sign of $$$A$$$:
Let $$$k$$$ be the number of $$$v$$$ that $$$p_v \lt v$$$, and let $$$q$$$ be the permutation with $$$q_{f(v)} = v$$$. Then $$$\operatorname{det}(A) = (-1)^k \cdot \operatorname{sgn}(q)$$$.
Now let's use this formula to solve the original problem. We have to make $$$A$$$ has a determinant of $$$1$$$. Obviously, if it's already $$$1$$$, the answer is $$$0$$$.
Let's first solve the case when it's $$$-1$$$. Notice an important fact: if we modify two rows, we can simply swap them, and that negates the determinant.
So the upperbound on the answer is the sum of two smallest values of $$$a_i$$$. We now simply have to determine the smallest cost of an edge that can negate the determinant on it's own.
Root the tree at $$$n + 1$$$ again, we delete the $$$i$$$-th edge $$$v \rightarrow p_v$$$, and replace it with an edge $$$x \rightarrow y$$$, where $$$x$$$ is a direct child of $$$v$$$. Assume that $$$f(x) = j$$$. How does the determinant change?
Notice that besides $$$i$$$, only the direction of edge $$$j$$$ changes. In particular, the edge $$$x \rightarrow v$$$ changes to $$$v \rightarrow x$$$, and $$$i$$$-th edge is now $$$x \rightarrow y$$$.
How does $$$q$$$ change? Before the operation, $$$q_i = v$$$ and $$$q_j = x$$$, now $$$q_i = x$$$ and $$$q_j = v$$$, so it swaps $$$q_i$$$ and $$$q_j$$$, which negates the sign. Additionally, since $$$j$$$-th edge was reversed, the value of $$$-1^{[x \gt v]}$$$ changed to $$$-1^{[v \gt x]}$$$, so this part was negated as well.
Therefore, the only change in determinant is: $$$-1^{[v \gt p_v] + [x \gt y]}$$$. We can iteratively apply this to get the same result for when $$$x$$$ is not a child of $$$v$$$.
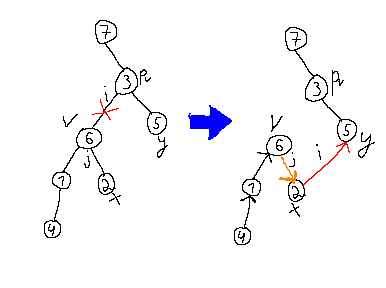
Therefore, if we replace $$$v \rightarrow p_v$$$ with $$$x \rightarrow y$$$, where $$$x$$$ is in the subtree of $$$v$$$ and $$$y$$$ is outside of subtree of $$$v$$$, the determinant is multiplied by $$$-1^{[v \gt p_v] + [x \gt y]}$$$.
This means that we can change the sign of determinant if the values of $$$[v \gt p_v]$$$ and $$$[x \gt y]$$$ are different.
Let $$$\max_v$$$ be the largest value in the subtree of $$$v$$$, and $$$\min_v$$$ the smallest value outside of the subtree of $$$v$$$. Then we can use the edge $$$v \rightarrow p_v$$$ to change the sign iff $$$\max_v \gt \min_v$$$, because if we choose $$$x = v$$$, $$$y = n + 1$$$, the sign is going to be different compared to when we choose $$$x = \max_v$$$, $$$y = \min_v$$$.
We can use this to determine if we can change the sign with an edge $$$i$$$ and find the smallest cost of one which we can use. This solves the case when the determinant is $$$-1$$$.
Now the only thing left is to solve when the determinant is $$$0$$$. Our graph is not a tree now.
Notice that if there are at least $$$3$$$ components, we have to change at at least $$$2$$$ edges, so we don't have to worry about the sign, since we can swap two edges if needed like we did in the previous case.
So we simply have to make the graph a tree while changing a subset of edges with the smallest total cost, which is precisly the MST problem (slightly modified).
The only case left is when the graph consists of two components. We can actually use the exact same observations as in the $$$\operatorname{det}(A) = -1$$$. There's a cycle, we have to remove one edge from it and connect the components. We can also change two edges, but at least one of them has to be in the cycle.
In the first case we have to check if the smallest value in the component with $$$n + 1$$$ is smaller than the largest value in the other component, and if so, we can choose any edge on the cycle. Otherwise, we have to apply the same logic as we did earlier.
Final time complexity: $$$O(n \log n)$$$ due to sorting for finding MST.
#include <bits/stdc++.h>
using namespace std;
const long long inf = 1e18;
struct DSU {
int n;
vector<int> p, siz;
int comp;
DSU(int N) {
n = N - 1;
comp = 0;
p = vector<int>(n + 1);
siz = vector<int>(n + 1);
};
void create(int x) {
p[x] = x;
siz[x] = 1;
comp++;
}
void init() {
comp = 0;
for(int v = 1; v <= n; v++) create(v);
}
int get(int x) {
return p[x] = (p[x] == x? x : get(p[x]));
}
bool unite(int x, int y) {
x = get(x), y = get(y);
if(x == y) return 0;
if(siz[x] < siz[y]) swap(x, y);
comp--;
siz[x] += siz[y];
p[y] = x;
return 1;
}
};
int get_cycles(vector<int> p) {
int n = p.size();
vector<int> used(n);
int cnt = 0;
for(int i = 0; i < n; i++) {
if(used[i]) continue;
int j = i;
while(!used[j]) {
used[j] = 1;
j = p[j];
}
cnt++;
}
return cnt;
}
long long solve_zero(vector<array<int, 3>> a) {
int n = (int) a.size();
int N = n + 1;
vector<vector<array<int, 3>>> g(N + 1);
for(int i = 0; i < n; i++) {
auto [u, v, w] = a[i];
g[u].push_back({v, w, i});
g[v].push_back({u, w, i});
}
vector<pair<int, int>> parent(N + 1);
vector<int> used(N + 1), d(N + 1);
int extra_edge = -1;
function<void(int, int)> dfs = [&](int v, int p) {
used[v] = 1;
for(auto [to, w, idx] : g[v]) {
if(to == p) continue;
if(used[to]) {
extra_edge = idx;
continue;
}
parent[to] = {v, idx};
d[to] = d[v] + 1;
dfs(to, v);
}
};
dfs(N, 0); dfs(1, 0);
assert(extra_edge != -1);
parent[1] = {N, extra_edge};
int sign = 1;
vector<int> p(n);
for(int v = 1; v <= n; v++) {
auto [u, idx] = parent[v];
p[idx] = v - 1;
if(v > u) sign *= -1;
}
int cnt_cycles = get_cycles(p);
if((n - cnt_cycles) & 1) sign = -sign;
long long ans = inf;
int best_idx = extra_edge;
if(sign == 1) ans = min(ans, (long long) a[extra_edge][2]);
int v = a[extra_edge][0];
int u = a[extra_edge][1];
if(d[v] < d[u]) swap(u, v);
int prev = u;
while(v != u) {
auto [par, idx] = parent[v];
// Delete (v, p)
// Add (v, prev)
sign *= -1;
if(v > par) sign *= -1;
if(v > prev) sign *= -1;
if(sign == 1) ans = min(ans, (long long) a[idx][2]);
if(a[idx][2] < a[best_idx][2]) best_idx = idx;
prev = v;
v = par;
}
long long two_operations = inf;
for(int i = 0; i < n; i++) {
if(i != best_idx) two_operations = min(two_operations, (long long) a[i][2]);
}
two_operations += a[best_idx][2];
ans = min(ans, two_operations);
return ans;
}
long long get(vector<array<int, 3>> a) {
int n = (int) a.size();
int N = n + 1;
for(auto &[l, r, w] : a) r++;
auto edges = a;
for(auto &[u, v, w] : edges) {
swap(u, w);
}
sort(edges.rbegin(), edges.rend());
DSU dsu(N + 1);
dsu.init();
long long ans = 0;
for(auto [w, u, v] : edges) {
if(!dsu.unite(u, v)) ans += w;
}
if(dsu.comp > 1) {
if(dsu.comp > 2) return ans;
else {
int cnt_other = 0, max_other = 0;
for(int v = 1; v <= N; v++) {
if(dsu.get(N) != dsu.get(v)) {
cnt_other++;
max_other = max(max_other, v);
}
}
if(cnt_other < max_other) return ans;
return solve_zero(a);
}
}
vector<vector<array<int, 3>>> g(N + 1);
for(int i = 0; i < n; i++) {
auto [u, v, w] = a[i];
g[u].push_back({v, w, i});
g[v].push_back({u, w, i});
}
vector<pair<int, int>> parent(N + 1);
vector<int> sz(N + 1, 1), max_dp(N + 1), weight(N + 1);
function<void(int, int)> dfs = [&](int v, int p) {
max_dp[v] = v;
for(auto [to, w, idx] : g[v]) {
if(to == p) continue;
parent[to] = {v, idx};
weight[to] = w;
dfs(to, v);
sz[v] += sz[to];
max_dp[v] = max(max_dp[v], max_dp[to]);
}
};
dfs(N, 0);
int sign = 1;
vector<int> p(n);
for(int v = 1; v <= n; v++) {
auto [u, idx] = parent[v];
p[idx] = v - 1;
if(v > u) sign *= -1;
}
int cnt_cycles = get_cycles(p);
if((n - cnt_cycles) & 1) sign = -sign;
ans = inf;
if(sign == 1) ans = 0;
else {
reverse(edges.begin(), edges.end());
ans = edges[0][0] + edges[1][0];
for(int v = 1; v < N; v++) {
if(sz[v] < max_dp[v]) ans = min(ans, (long long) weight[v]);
}
}
return ans;
}
void solve() {
int n;
cin >> n;
vector<array<int, 3>> a(n);
for(auto &[l, r, w] : a) {
cin >> l >> r >> w;
}
long long ans = get(a);
cout << ans << '\n';
}
signed main() {
ios_base::sync_with_stdio(0); cin.tie(0);
int ttt = 1;
cin >> ttt;
while(ttt--) {
solve();
}
}