


contest.standings documentation
Currently server returns error response with comment contestId: You have to be authenticated to use this method.
But if I use authorization with secret key it returns another error contestId: Only gym and mashup contests are available to non-admin users in this method.
Is it temporarily blocked or it is bugged?
P. S. Admins, I am not using Carrot! Please bring to live at least method that accepts single handle.






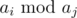 , then iterate all integer
, then iterate all integer 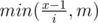 . Total complexity is
. Total complexity is 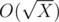 complexity. How to calculate divisors of divisors? Need to know that for the given constrains for
complexity. How to calculate divisors of divisors? Need to know that for the given constrains for 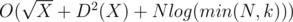 .
.