


| # | User | Rating |
|---|---|---|
| 1 | Benq | 3792 |
| 2 | VivaciousAubergine | 3647 |
| 3 | Kevin114514 | 3603 |
| 4 | jiangly | 3583 |
| 5 | strapple | 3515 |
| 6 | tourist | 3470 |
| 7 | dXqwq | 3436 |
| 8 | Radewoosh | 3415 |
| 9 | Otomachi_Una | 3413 |
| 10 | Um_nik | 3376 |
| # | User | Contrib. |
|---|---|---|
| 1 | Qingyu | 157 |
| 2 | adamant | 153 |
| 3 | Um_nik | 146 |
| 3 | Proof_by_QED | 146 |
| 5 | Dominater069 | 145 |
| 6 | errorgorn | 141 |
| 7 | cry | 139 |
| 8 | YuukiS | 135 |
| 9 | TheScrasse | 134 |
| 10 | chromate00 | 133 |
|
+60
I don't understand what's the point of creating a blog to ask people to solve an open problem for you and respond comments with "obvious", "extremely ambiguous". Dude... CP community is sometimes the worst. |

|
On
seo →
Just what!? Standart rand() in C++ or undeniable proof of the existence of magic!, 7 years ago
+23
You also shouldn't really expect any differences between CODE and CODE3. You are simply doing a loop that doesn't change the state of the PRNG. |
|
+11
M: essentially, every clause must have an odd number of true literals. That means that if the literals of a clause are l1, ..., lk (k ≤ 3), then |
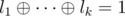 . We can rewrite that in terms of the variables by taking care of negations. For each negation, the right side of the equation flips, so we have
. We can rewrite that in terms of the variables by taking care of negations. For each negation, the right side of the equation flips, so we have 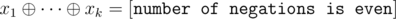 . So we have a system of
. So we have a system of  . This can be solved with Gaussian elimination in
. This can be solved with Gaussian elimination in |
+8
By the way, nice idea of iterating through the smallest side to avoid the math work :) |
|
+8
His code would have got AC if he used >= C++14, probably because of the compiler version. I always used cin.tie(0); but I used to think that it made difference only when reading/writing alternately. Omitting it seems to hurt his solution's performance by no more than 100ms on >= C++14, but it hurts just enough on C++11. |
|
+10
Not sure about the Reeds-Sloane, but the BM has a weird bug when a0 is zero, since it tries to find its inverse and divide it by zero. It's different from what is described in the paper. The later deals with trailing zeroes just fine. |
|
+10
As long as I can tell the worst case behavior of this solution can be easily forced by De Bruijn sequences for example, so I may even assume that the tests are weak. |
|
+18
Fun linear solution for D: 30688152 |
|
+14
I'll guess that you are considering self-loops as potential roots for your trees when you shouldn't. |
|
+3
That made think this solution was totally different from my solution, when it's actually pretty much the same. Anyway, really cool problem. |
|
+10
The permanent of an adjacency matrix counts the number of perfect matchings in bipartite graph of rows-columns. Since the determinant is something like a - b and permanent is a + b, they have the same parity. The number of perfect matchings in bipartite graph rows-columns is the number of vertex-disjoint covers of cycles in the original graph (every vertex will have one incoming edge and one outgoing edge). This is basically the number of valid permutations when you look at them as cycles. |
|
+10
Problems were opened for submission: https://www.urionlinejudge.com.br/judge/pt/problems/origin/136 |
|
+1
https://www.urionlinejudge.com.br/judge/en/problems/origin/125 You can read and submit them here if you have an account with language set to English. |
|
+20
http://uoj.ac/submission/61485 This code shows quite well how it actually works, for a moment I thought it was completely different from Mo's. Thanks (: |
|
+16
Imagine the product of a0x0, a1x1, ..., an - 1xn - 1 and b0x0, b1x - 1, ..., bn - 1x - n + 1. If ai is 1 if s[i] is A and bi is 1 if s[i] is B, then the coefficients of xi would be the answer for i-inversions. You can shift the second expression to get a valid polynomial (get non-negative exponents multiplying it by xj). Then you can solve it by FFT. If you shifted by j, then answer for k-inversion will be coefficient of xj + k. |
|
+3
I'll try to explain my solution. Let's forget about the |x| ≤ k restriction at first, where x is our answer. Consider that every binary string used in this explanation is written from left to right from the least significant digit to the most significant one. You are given a such that a020 + a121 + ... + an2n ≠ 0. One possibility to solve this problem is to find, for each coefficient, if it's possible to zero out the expression changing its value (this new value will be unique for each coefficient). Let's try to write down an equation which reflects that. Let c be the new value of the coefficient you will change and i be its index. a020 + ... + c2i + ... + an2n = 0
So first of all our expression should be divisible by 2i, where i is the index of the coefficient we are changing. Of course all terms with index j ≥ i are divisible by 2i (that's because they are in the form ai + p2i + p, p ≥ 0). So if the sum of the first i terms of our expression is divisible by 2i, then we can change this coefficient and zero it out and, more over, our answer is c in the given equation. Well.. but |c| may be large enough to exceed k. It turns out that we can implement the whole thing in such a way that it will be very easy to overcome this. Let's change our expression so |ai| ≤ 1 for every i. I.e, we will get some sequence of -1s, 0s and 1s. You can check it won't grow too much. We can do that by adding and carrying each coefficient (similar to the sum of binary numbers). Since we are allowing -1s, we lose some properties from binary representation, but we still have one very important: there's only one way to represent the zero. Well.. how do we know that a number is divisible by 2i looking at its binary representation? Count if the size of the largest prefix which contains only zeroes is greater or equal than i! The same holds here, because our remainder of the division by 2i is still represented by the first i digits, like in usual binary representation (ofc, it may be negative and we need to fix, but in this problem we don't really need to care about this case). So if we have 001001, then this number is divisible by 20, 21, 22. Ok, now from the new representation we can answer the easier problem with no restriction in the coefficients: it's simply the size of the prefix. But let's finally take into account the k constraint. If the remainder of our division is represented by the first i digits, guess where is the quocient? Yeah, the digits that are left! So if we do a shift of size i, like in usual binary representation, we get the quocient of the division by 2i. In 001001, if we divide by 22, then the quocient is 1001 as you may already know. (although i'm not writing down numbers with negative digits, they may exist) That shift we got is a suffix of our string. One smart way to pick the quocients is going backwards in this string and stop as soon as it gets bigger than 232 in absolute value. Since this text is getting really huge, I invite you to check that it never goes below k again. After getting the quocient q, we just need to check if the complementary prefix is divisible by 2i. Then c = q - ai and answer should be incremented if |c| ≤ k. You can check my code to see how to implement this last piece: 17089440 |
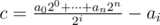
|
0
Or if a bridge itself in this path is a "good" edge. |
|
+5
If you want to add all the problems at once you should create a Gym contest instead, then follow the instructions to set up a contest from a Polygon contest descriptor. But I think you must have coach mode enabled or something similar for that. I'm not sure if there's another way to do that. |
|
+6
I use a trie on my solution. Suppose queries are in the form 1..R instead of L..R. You can answer queries by increasing R mantaining a trie with all the bitstrings from a[1..R]. Bitstrings will be added as usual, starting from most significant bits (you should make all the strings the same length. 20 is enough in this case). When you a got a bitstring X, you can find a bitstring Y in that trie that gives maximum
Problem here is that you are given L..R queries. To avoid ending up with a Y that does not lie on this segment, you can mantain a maxidx value on every node of the trie. maxidx of a node is the maximum index (on the original array) of a bitstring which ends on the subtree of this node. Given this, you can always take transitions which guarantees you that you will end up with a valid Y.
Time Complexity: O(nlogmax(Ai)) |
 in the following way:
in the following way:|
0
Binary search on a[i+1]-a[i]. http://mirror.codeforces.com/blog/entry/11497 |
|
0
If you can't find some valid partition ending at i - 1, you are simply considering you can start a new partition from i, ignoring all previous elements. For example, in the countertest above you are ignoring briefcase 1 in your optimal solution, when you have to use it. That's because your default value of dpp=0 and dp[2][_] will be 0 (1-indexed), which is not correct, since there's no valid partition to it's left. Then when you get to dp[3][], you will make a invalid 1-partition using previous value of dp[2][]. |
|
+3
int -> long long Initialize dpp to - ∞. With dpp=0 you might be considering partitions of some subarray of the original array, like [2..3], [4..5] for the subarray [2..5], when you really have to partition the whole array. Counter test: |
|
+12
You should remove patients from the queue when they cry, because then the crying from the cabinet can affect someone behind him, which was not affected before his removal. |
|
+17
They are probably trying to detect how much the messed up pretests affected the whole competition to make a decision. Don't worry about those pretests, just wait for systest. |
|
+3
Centroid decomposition of a tree. You can find discussion about this problem (342E - Xenia and Tree) in the link given above. |
|
+7
Search about minimum vertex cover on bipartite, König's theorem. Interesting part of this problem is that you shouldn't output the cardinality of MVC, but you should be able to recover the solution as well. Proof of König's theorem on Wikipedia already provides an efficient algorithm for retrieving that. |
|
+3
This solution refers to baodog's observation (Prufer sequences) that all sequences of n - 2 elements in [1, n] (possibly repeated) form a bijection with the set of all spanning trees of complete graph Kn. Moreover, v appears k - 1 times in those sequences iff node v has degree k in correspondent tree. So we can count number of valid sequences using the given DP. If we have sequences of m elements using only elements labeled in range [1, n], we can add 0 ≤ x < K elements labeled n + 1 to it so we will have a new sequence of m + x elements using elements labeled in range [1, n + 1]. We should be able to add these new x elements between any of the elements of the former sequence. It's equivalent to the problem of interpolating two strings without changing their original orders. There are |
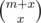 ways to do that. From that you can derivate
ways to do that. From that you can derivate |
+3
Constraints are small, so |
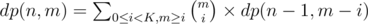 , where
, where |
0
It's consequence of Euler's theorem but I think it's not applicable in this problem because gcd(a, n) ≠ 1 might be true for some testcase. I don't know if, for this problem, there's a simple trick to deal with this particular case, but I guess that's why we had so many hacks. |
|
0
I think |
 when
when |
0
I think I overkilled, but... Since i2k = (i2k - 1)2 (1), we could compute Further optimizing it, we can decompose terms in such way that we need to compute i2k - 1 only for prime i:
We can use a sieve and compute i2k - 1 for each prime in O(k). For composite numbers we can just multiply what we have just computed for it's prime factors. We will have something like O((n + k)logn). |
 (2) in
(2) in  , where
, where |
0
You can notice that any signed letter ^4 equals to 1. So we may have periodicity when X > 4. Maybe we can use that to do less processing. If X <= 4 we can just solve it as if we were dealing with small case: one approach is to find first occurrence of i, a later occurrence of i*j and check if the whole multiplication is i*j*k. Lets split the given string |S| = L in pieces by its periods. If X > 4 we have to consider that even if ij occurs before i in the first piece, it may occur in the second piece after i. We could process 'til 4*L and check if i and ij occurs somewhere. But it does not guarantee us that there will be a i before a ij in the given multiplication. We could have X = 6 with ij occuring in the last part of S and i occuring right after it. Then we would not have i before ij even if the string is periodic, because it wasn't periodic at all (we had a single complete period and an incomplete period). But if we assume we have two complete periods, this logic will work. So we process as if we were dealing with small cases for X <= 8 (at most two complete periods) and process splitting string in pieces for X > 8. |
|
0
The smartest solution I saw someone using was using DSU. You could solve the problem backwards by merging X-axis and Y-axis intervals and updating the largest intervals if the merged interval is larger than the current one. The algorithm itself is O(nα), isn't it? |
|
0
Some general explanation: http://community.topcoder.com/tc?module=Static&d1=features&d2=010408 Interesting blog: http://fusharblog.com/solving-linear-recurrence-for-programming-contest/ |
|
0
Edited. "Proof" added. It is.. weird. |
|
0
|
|
0
Really nice approach. After thinking a little bit I came to an O(n) solution for the first part of the problem. We can impose all the needed restrictions with at most 2n operations, with one normal scan and one reverse scan. In the first scan, we will process, from left to right, every pair of height-restricted buildings (i - 1, i) such that i and i - 1 are valid height-restricted buildings and hi - 1 < hi. Then we will impose the restriction to the i-th. Let d be the distance between these buildings. h'i = min(hi, hi - 1 + d * k), then we set this as the new restricted height of building i. Now we move to the second scan, going backwards this time. We will process every pair of restricted buildings (i, i + 1) such that i and i + 1 are valid and hi + 1 < hi. Then we will impose the restriction to the i-th building in a similar way to the first scan. With this process ordering the heights stabilize after one single iteration. I'm having a hard time to prove it formally so I will leave this way for now. This does not change the overall solution complexity because of the binary search, but it was interesting to think of since it can be useful in a problem we might stumble upon in the future. ( Code ) EDIT: We can actually prove it. Let (i, j) be a pair of "adjacent" restricted buildings. If this pair was not processed in the scans or it was processed in only of them, we are okay. We de not have any dependency cycle for it. But if the given pair was processed in both scans, we have to be careful. We know that if (k, i), such that k ≠ j, was processed in the first scan, it was certainly processed before (i, j) (since we process from left to right). So, if (k, i) processing imposed any modification to the i-th building, it was certainly taken into account when processing (i, j). Now let's analyze the second scan. If (j, l), such that l ≠ i, was processed in the second scan, it was certainly processed before (i, j) (since we are now going from right to left). So we can think in a similar way of the previous paragraph. If (i, j) was processed at both scans, it means that some building b such that b ≠ i modified j in such a way that its height became lesser than i's height and, certainly, this building was already restricted (if needed) at both scans. So we just want to prove that we will not need to execute the first scan again. We can see that hi will become, at least, (hi, hj + k) so the pairs will not need to be processed again. So, after all, the order that the buildings are processed is the important thing here. |
|
+3
Writing editorials seems to be a really motivating way of getting ideas right. Awesome work. By the way, in the hard problem, in the process of redefining the maximum heights of the buildings, you loop over the array checking whether heights are reachable and decreasing the height multiple times until them stabilize? I was wondering if number of restricted buildings(size of x) was huge this solution would be feasible, just out of curiosity. |
|
0
Let v be the given array. Initially, you should push to a stack all the elements of v that you have processed. But the main idea is that the stack should have the following invariant: for every element k in the stack, the element k-1 (right below it, if it exists) should necessarily be strictly greater in value than it. Let len_i be the longest sub-array starting from i+1. This way you can be sure that the elements v[i] and v[i+1+len_i] (first element that is not in the sub-array) will never be in the stack at the same time. So before you push an element v[x] to the stack, you have to pop all the elements from the top of the stack which are lesser or equals in value to the element v[x]. Let v[j], j < x, be an element that was popped from the stack at this step. You can notice that v[x] is the first element which is not in the longest subarray starting from j+1, so you can easily get the longest subarray starting from j+1 by subtracting the positions x and j+1. So we have |
