


| № | Пользователь | Рейтинг |
|---|---|---|
| 1 | Benq | 3792 |
| 2 | VivaciousAubergine | 3647 |
| 3 | Kevin114514 | 3603 |
| 4 | jiangly | 3583 |
| 5 | strapple | 3515 |
| 6 | tourist | 3470 |
| 7 | dXqwq | 3436 |
| 8 | Radewoosh | 3415 |
| 9 | Otomachi_Una | 3413 |
| 10 | Um_nik | 3376 |
| Страны | Города | Организации | Всё → |
| № | Пользователь | Вклад |
|---|---|---|
| 1 | Qingyu | 157 |
| 2 | adamant | 153 |
| 3 | Um_nik | 146 |
| 3 | Proof_by_QED | 146 |
| 5 | Dominater069 | 145 |
| 6 | errorgorn | 141 |
| 7 | cry | 139 |
| 8 | YuukiS | 135 |
| 9 | TheScrasse | 134 |
| 10 | chromate00 | 133 |
|
На
project2400 →
How long should implementation take after you come up with a solution?, 3 недели назад
0
Maybe you really can’t, but you should try nevertheless. Saying or thinking "while A times B greater than C" is faster and easier than whatever you do with "human-readable" (as if programming languages are not human-readable already). Long names are good for slow-paced work in a big team. You don’t need it, when you solely want to make a computer run your idea and then forget about it. |
|
На
Anthony_Smith →
Why is the Aho-Corasick Automaton necessary when Suffix Arrays exist?, 4 года назад
+3
Your suffix array solution requires $$$O(|T|)$$$ memory, whereas Aho-Corasick automaton uses $$$O(|P|)$$$. Memory footprint is important for the running time as well, since working with smaller collocated regions of memory is usually faster. |
|
-18
It is appalling that many high-rated coders don't know how to debug a program on a large test case. Hint: debugging has nothing to do with "Debug" button in your IDE. |
|
На
nika-skybytska →
Why you may want to use two-layer dp not only to decrease the memory usage, 5 лет назад
+3
So, the biggest offenders are not the page faults per se, but the initializations of new pages? |
|
На
nika-skybytska →
Why you may want to use two-layer dp not only to decrease the memory usage, 5 лет назад
+31
C++ As for difference in time, it is simply due to difference in number of active memory pages. The more pages your process touches, the more frequently page fault happens. Allocating huge unused array is fast because actual page allocation happens lazily. |
|
+3
Despite being written on the page you linked, the technique of comparing arbitrary substrings via preserving all the levels in a table is neither required to build SA, nor really known widely. Let alone the observation that you can use the technique in isolation without wasting anything on suffix sorting. The really well-known technique of comparing substrings is via quickly computing LCP of the two suffixes, which is a significantly different approach. By the way, this classification-via-doubling technique is not even inherent to suffix arrays. The same is used in fast DFA minimization (1971) and finding repeated patterns in 2D arrays and trees ("Rapid Identification of Repeated Patterns in Strings, Trees and Arrays" (1972) by Karp, Miller and Rosenberg — referenced by Manber and Myers 1993 paper on suffix arrays). |
|
На
Radewoosh →
My own algorithm — offline incremental strongly connected components in O(m*log(m)), 5 лет назад
+13
Recently, I dipped into computer graphics and was surprised to learn that prefix sums are known there by confusing names like "SAT" and "integral images" and sometimes even assumed to be discovered by Franklin Crow. This gave me two things to reflect on:
(Not sure about LCS algorithm you mentioned, though.) |
|
+10
By the way, I'm not saying that the technique is useless. It's just that we shouldn't call it "lazy propagation". |
|
0
It is specific in the way you've described: it works for $$$M(x, y) \leftarrow max(M(x, y), v)$$$, but doesn't seem to work for $$$M(x, y) \leftarrow v$$$. The former updates are monotone, the latter are not. |
|
0
Understood. Hopefully, I’m not the only one who sees implied universal quantification there. |
|
+10
There are easy problems that you can turn into NP-complete ones via “small variation”, so no, that’s not what those people really mean. Informal “knapsack is NP-hard” is a shorthand for “solving knapsack is as hard as solving arbitrary problems from NP”, which is formalized as “any solver for knapsack can be turned into a solver of any NP problem with only polynomial overhead”. |
|
+10
If you can reduce any problem from NP, not every NP-Hard problem. (You don’t want halting problem be reducible to TSP.) |
|
+62
I guess a little explanation is required.
Overall, I thought I was giving an honest advice. I understand that it probably was unwelcome. What I don't understand though is why you decided to respond to me like that. |
|
-48
It means that we need to rise the bar. Namely, ignore those claims having an attitude of “here’s my huge convoluted proof, I myself am not sure about it, please check, for I am not an expert”. |
|
На
Radewoosh →
Asking for help with problems from running contests - what's wrong with people?, 6 лет назад
+8
Just wait for folks who use "doubt" instead of "question". They also never put a question mark. Perhaps, because doubt is not a question. |
|
+52
|
|
0
Also, it might mean that the samples are screwed up or old version of statements was accidentally posted. It is OK to be wary of things that look broken. |
|
+1
Try musician's advice. If I ask you to hit "G" once, can you do it reliably? I hope, the answer is yes. The trick then is to make sure you know which key (and which finger) is next before you start to move your fingers. This is super-slow, but eventually you'll learn to do this for entire complex sequences. Also, you'll probably start to notice mistakes before you actually do them, because the ultimate source of mishits is you having wrong ideas about your hands movement. Though beware that all I've written is from my piano playing experience. Typing words doesn't have as immediate feedback loop as musical performance does. And of course, none of this will protect you from random hard-to-spot bugs (which is more about using well-known and reliable snippets and techniques in your code). |
|
+31
In functional programming this is called a zipper. If you implement it in a pure functional style, you’ll get a persistent data structure. That is, not only you can move the root around, you can also store and have all the rerootings at the same time once you finish your DFS. |
|
0
Apparently, this is not true for red-black trees. Note that sorting lower bound doesn’t apply here as everything is already sorted and the node is already found. |
|
+3
I guess there are different kinds of people, and I will never understand why everyone can't just base their binary searches on maintaining proper invariants. The |
|
0
Что мешает считать $$$O(n)$$$ перебор за «долгий предподсчет»? Вообще, эта задача решается префикс-функцией. |
|
+8
But there's not so much of encouragement to use it blindly, I believe. Mine impression is that people usually learn both techniques, avoiding (and under-practicing) lazy-prop exactly because it is comparatively cumbersome. |
|
0
I don’t, 3XOR oracle does that for us. We only strip the numbers to their first most significant bits before asking. |
|
+10
“Regarding as the same” and claiming equality are different things. As long as I’m fine with logarithmic slowdown (the OP seems to be fine too), I would read everything about 3XOR as if it were written about the original problem, instead of thinking that there was no such research. |
|
+31
I guess so. My point is that since the reduction is simple, you can safely regard the problems as the same. |
|
+29
"a ^ b = c" is the same as "a ^ b ^ c = 0", which is the same as "(a ^ X) ^ (b ^ X) ^ (c ^ X) = X". That is, by xoring everything with X, you can ask the same 3XOR oracle, whether there is a triple that xors to a given number X. Now, thanks to bitwise independency of XOR, you can find the maximal xor bit by bit:
And so on. |
|
+13
The problem is known as 3XOR in the literature, by the way. |
|
-7
Задачи с затейливым вводом-выводом все еще не вымерли? |
|
0
Well, yes. I was talking about (and praising) straight indexing only. |
|
0
Well, surely you can’t modify the shape of the tree. That’s why I called it static.
So does this static version:
Range queries rely on these properties. |
|
+10
This is just a static balanced binary search tree, not a specialized range-query data structure. Omitting the pointers, which you can efficiently compute on the fly, doesn’t really make something new. Though, I agree with you that this should get more attention, at least for educational purposes:
|
|
+18
But have you ever made a bug that crashed your OS? The one you described just caused slow or exhausted swap (maybe it was zero-size?). The OS didn’t crash until you hard reset it. |
|
0
Обычно этот текст записывают короче:
Теперь немного комментарев к тексту:
Это опасное заблуждение. Если долбить одну задачу в ее исходном виде, ничего нового не обнаружится. Основная деятельность ученого — задаваться интересными вопросами. Иногда на них удается ответить, иногда на них отвечает кто-то другой. А иногда решение не предвидится, но это не повод все бросать. Как с P vs NP, благодаря которому мы пришли к таким невероятным вещам, как доказательства с нулевым разглашением и PCP-теореме.
Это вина рецензентов, пропустивших такое. Есть неплохие шансы, что авторы статьи тоже не смогут. |
|
+33
|
|
+2
Does Codeforces have a written policy about what user-generated content will go public forever? |
|
На
KarimElSheikh →
Is it possible to extend Manacher's algorithm to include information about the longest palindromic substring that starts at every position?, 8 лет назад
0
This blogpost mentions (and gives link to implementation for) online version of the algorithm due to Mikhail Rubinchik: http://mirror.codeforces.com/blog/entry/12143 “Online” means that this algorithm knows the longest palindromic substring ending at any given position. For starting positions simply reverse the input string. |
|
0
Seems like one could say that these data structures are transposed versions of each other. |
|
0
Not sure what you mean, but probably not. Haven't you mixed up "values" and "positions"? Wavelet tree was designed to overcome binary alphabet size limitation of succinct bit-vectors with constant-time rank and select queries. Thus the essence of wavelet trees is splitting the sequence over alphabet into series of bit-vectors in a balanced way. It certainly doesn't merge nor sorts anything. |
|
+6
Wikipedia: The name derives from an analogy with the wavelet transform for signals, which recursively decomposes a signal into low-frequency and high-frequency components. |
|
0
But what exactly is wrong with nested BSTs solution? Its space requirement would be |
 .
.|
+18
I've inspected your code:
|
|
+8
«Разделяй и властвуй» плюс Фурье дает |
 , если игнорировать необходимость вычислять обратные по модулю, для которых субквадратичные алгоритмы тоже вроде как существуют:
, если игнорировать необходимость вычислять обратные по модулю, для которых субквадратичные алгоритмы тоже вроде как существуют: |
0
Set of prefixes should have the same effect. Every |Vk| is Ω(|Sk|2) then, right? |
|
0
What prevents |Vk| from being always Θ(|Sk|) for suffix trees? |
|
0
Allow to hack out-of-room solutions, but don't tell out-of-room participants that their solution has been hacked? |
|
0
That's correct. The only difference is that Z values for P#T are bounded by |P|, whereas for PT they are bounded by |PT|. It matters if either P is small enough to store Z values in a few bits, or T is an infinite stream, for example. |
|
+4
Problem C. For those who don't like formulae: let |
|
На
Urbanowicz →
Non-recursive Implementation of Range Queries and Modifications over Array, 10 лет назад
0
If indices range from 0 to 5 then you have six elements and therefore should use 6 as an offset. Power of two works because it is larger than 6. |
|
На
Urbanowicz →
Non-recursive Implementation of Range Queries and Modifications over Array, 10 лет назад
0
Implementation described in this post uses inclusive bounds for queries. So, if you have 5 elements, then allowed queries are of form [L, R], where 0 ≤ L ≤ R ≤ 4. |
|
На
Urbanowicz →
Non-recursive Implementation of Range Queries and Modifications over Array, 10 лет назад
0
10 is out of bounds, The last of five elements has index 9, not 10. |
|
0
Так для этого публичные строгие (а не справедливые) наказания и существуют: донести сообщение, что нарушать не стоит, даже если шансы быть пойманным за руку низкие. Иначе люди перестанут бояться, зная что последствия ничтожны в любом случае. Смысл состоит в экономии ресурсов исполнительной власти (раз уж заговорили про государственную власть), а не в воспитании конкретной жертвы наказания. |
|
+6
What should be the answer for this input? I'd try to output only unique strings. |
|
0
Draw two intersecting lines and then draw another one well above them. |
|
+6
Due to Mihai Patrascu, dynamic partial sums (with point updates) require |
 memory probes, thus making balanced trees an optimal solution. Take a look at his thesis for more lower bounds.
memory probes, thus making balanced trees an optimal solution. Take a look at his thesis for more lower bounds.|
На
EnumerativeCombinatorics →
What is the good way for competitive programmers to practice English?, 11 лет назад
+18
Did you try to talk with yourself? I do not mean imagining some contrived conversation but rather suggest to think routinely in English. Judging by the quality of the text you've written, you have a really good understanding of how proper English should look and sound. So you should be able to check your own thoughts without disadvantageous embarrassment of speaking aloud. If you never practiced that before, start with simple thoughts like naming objects around you or describing what happens/what you're doing in a few words. I did this for myself and found out the following:
|
|
0
There's O(depth) nodes along the insertion path. For each subtree of such a node there's O(2k) ancestors of grand-children of depth k. We rearrange the ancestors entirely from scratch. |
|
+14
Мне тоже опции кажутся странными. Если хочется сохранить историю графика, то почему просто не сохранить его в виде статического снимка, как предлагает TEK_14? История должна быть в музеях (то есть, отдельно).
Зато сломает мозг тем, кто видит упоминания одного и того же пользователя в разных цветах. А потом пройдет по ссылке и увидит в профиле вообще другой цвет. И каким образом такие комментарии могут быть сломаны? Ясно же написано, что произошло. А если у кого-то возникли сомнения в словах, тот может провести свое расследование, если захочет. |
|
0
No, it shouldn't be 0.000, because there's notion of signed zero in the doubles standard. |
|
+8
Go science then, you'll watch them permanently (as well as their advancement). The most difficult to understand algorithm is the most poorly explained one. It holds for almost any fresh result in CS. Luckily, there are people who constantly try to improve explanations, which sometimes even yields to more simple and practical algorithms. And here's the quote from “Twenty Questions for Donald Knuth”, which shows these “most difficult algorithms” are up to no good:
|
|
0
Row echelon form won't help. You need, as has been said, reduced row echelon form, and each row must have MSB as a leading coefficient. It gives maximal XOR sum because of this:
|
|
+5
But it works with N = 3·106 + 5... 12484538 |
|
+5
As said in this post:
Not sure, where exactly that fails for you, but I guess it's here: Seems like you intend to take left child of |
|
+11
http://mirror.codeforces.com/blog/entry/2154 UPD: seems like I mixed the letters up as well |
|
0
Exactly. Nobody at Codeforces got time to implement direct download links for every large test case (are they bigger than the average blogpost with comments?). Instead they seem to favor a ridiculous excuse and a load caused by such extraction submissions. If they think that getting full test case is useless, why do they bother showing it at all? |
|
+20
Maybe the original title was "An alternative to 1000000007 modulo", but... Niklaus Wirth had much better suggestion. |
|
+84
Once, in a hurry, I used a combination of two: |
|
+45
I guess you are interested in your last submission 12190150, which fails 19th test case. Here's how you can abuse the system:
And here's extracted test case itself: http://pastebin.com/JxkE7pDV |
|
+10
Sorry, didn't notice that. In this case the problem is that last positions are filled with zeros, not '0' characters. |
|
0
This test case asks you to count numbers below 264 but you stop at 260 (or so). |
|
0
I've got one more personal rule: never use constants without MOD inside modular arithmetics code. |
|
0
Given typical Snickers commercial, sounds like a placebo as well) |
|
+3
For each row, except the last one you need to ensure that there's no way to place the ship. |
|
0
... and since you know there's 8L period, you could reduce X in the same way but with eights instead of fours. I just said, that absence of idea about fourth powers doesn't justify the approach. |
|
+10
So, you just decided to ignore the large case? You still need some good bounds on the lengths of prefix and suffix, otherwise you'll be looking for entire string on this input: |
|
0
Ну написано так в предположении, дальше-то это никак не используется. |
|
0
Доказательство в своей последней части нигде на минимальность не опирается. |
|
0
Ну да, в этом и состоит смысл доказательства от противного) Мы же не теорему опровергаем, а просто указываем на ошибку в доказательстве на e-maxx и отвечаем на ваш вопрос из поста: не всегда из того, что n не делится на k следует, что все буквы блока совпадают. |
|
0
Можно абстрагироваться так: воспринимайте цифры в строке не как символы, а как s1, s2, ..., s8. Мы пользуемся повторяющейся нумерацией, потому что нам известна длина строки (20) и значение префикс-функции для последней позиции (12), откуда следует, что si = si + 8. Тогда предположив, что p является периодом строки, мы получаем, что еще и si = si + 2 (по картинке). Но мы не получаем si = si + 1, как написано на e-maxx. |
|
+8
Это следует из каких-то заблуждений. Вот пример строки из 20 символов: В обозначениях e-maxx: k = 8 и пусть p = 10, тогда si = si + 2. |
|
+3
Somewhat classical survey on persistent data structures is Purely Functional Data Structures by Chris Okasaki: http://www.cs.cmu.edu/~rwh/theses/okasaki.pdf |
|
+3
И мне, например, присылали. Я очень смеялся с моих "excellent academic background at Udmurt coupled with experience in a variety of ACM/ICPC's" (я член команды-финалистки). Я ответил в духе, что не стоит терять на мне время, а они в свою очередь все равно уболтали назначить дату для беседы. Вот такие странные вещи делает гугл. |
|
0
"Adequate" here means "conforming to known facts". The caveat is that you will know very few of them if you refuse to study the subject. Originally, I just wanted to express how I didn't like your invitation to ignore all the psychology research experience (and to make all the mistakes in the field, that already have been recognized years ago). Sorry for off topic. |
|
+1
The point is that your argumentation is faulty. Having something doesn't automatically allow you to get adequate knowledge about it. For example, trying to study etymology by only "coming in contact with a language" and nothing else, you can easily end up being a paraetymologist. |
|
+12
There's no such thing as "not knowing anything about linguistics". Linguistics is about studying human languages; you speak one, so feel free to do it. A degree doesn't make an expert. There's no such thing as "not knowing anything about cardiac surgery". Cardiac surgery is about repairing human heart; you have one, so feel free to do it. A degree doesn't make an expert. |
|
0
Бывает. Мне известны только две такие штуки: одна строит неполное суффиксное дерево, добавляя буквы в конце строки, другая — предназначена только для поиска всех вхождений. Обе с ограниченными приложениями. А для вариантов алгоритма Вайнера вроде как действительно нет. |
|
0
Там просто обычное дерево на алфавите константного размера. Алгоритм Вайнера в таких условиях сам по себе работает быстрее — за линию, обрабатывая очередной суффикс за амортизированную O(1). А в этой работе показано, как превратить амортизированную O(1) в |
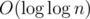 в худшем случае.
в худшем случае.|
0
Только это не является построением суффиксного массива, по крайней мере прямым. |
|
0
Когда писалась эта статья, я был плохо знаком с публикациями по теме. На самом деле в 2005 году было показано, как это делать за |
|
0
Да, надо бы поинтересоваться, что имеют ввиду авторы, говоря, что |
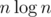 — "trivial lower bound") Алгоритмы, требующие целочисленный алфавит, тоже ведь сформулированы для RAM-модели. Может быть это нижняя граница для онлайновой задачи сортировки?
— "trivial lower bound") Алгоритмы, требующие целочисленный алфавит, тоже ведь сформулированы для RAM-модели. Может быть это нижняя граница для онлайновой задачи сортировки?|
-8
Алгоритм Укконена использует факт про алфавит константного размера :) Для произвольных алфавитов у него |
|
0
Нет, алгоритм Фараха не онлайновый. |
|
-8
Если алфавит произвольный, то задачу сортировки можно свести к построению суффиксного дерева или массива. То есть |
|
0
Только для так называемых целочисленных алфавитов: когда буквы являются целыми числами из отрезка [1, n]. Алгоритм Фараха (1997) для построения суффиксного дерева тоже работает за O(n) для целочисленных алфавитов. |
|
+5
I believe these spam blogs are created only to exploit search engines indexing and nothing else. So, forbidding indexing for Recent Actions panel and for newly created (several days) posts will make such a blog post pointless for spammers at least. Hopefully, this will force them to stop putting efforts in overcoming other anti-spam obstacles (if CF has any). |
|
0
По умолчанию включен автоматический сброс, который реализован вот так: |
|
+8
Только не на CF. |
|
+29
1956 года, когда никому не пришло бы в голову использовать подобные слова. «Мешап» — по-моему, плохой вариант, потому что тот, кто наткнется на это слово впервые, скорее всего произнесет его по аналогии со словом «мешанина», что совсем не похоже на английский вариант. И так лишится последней возможности самостоятельно догадаться, что это за слово вообще. Кстати, подозреваю, что в слове «мэр» из приведенных правил используется буква «э» по той же причине. |
|
+9
Извиняюсь за некропост, просто хотел заметить, что для Codeforces не проблема делать это автоматически при отправке текста — детектить имя домена в ссылках и превращать их в относительные. |
|
+5
Here's some claims about original problem statement: http://mirror.codeforces.com/blog/entry/220?locale=en#comment-2429 |
