


Spectral::Cup 2026 Round 1 (Codeforces Round 1094, Div. 1 + Div. 2)
27:16:49
Register now »
| # | User | Rating |
|---|---|---|
| 1 | Benq | 3792 |
| 2 | VivaciousAubergine | 3647 |
| 3 | Kevin114514 | 3603 |
| 4 | jiangly | 3583 |
| 5 | turmax | 3559 |
| 6 | tourist | 3541 |
| 7 | strapple | 3515 |
| 8 | ksun48 | 3461 |
| 9 | dXqwq | 3436 |
| 10 | Otomachi_Una | 3413 |
| # | User | Contrib. |
|---|---|---|
| 1 | Qingyu | 157 |
| 2 | adamant | 153 |
| 3 | Um_nik | 146 |
| 3 | Proof_by_QED | 146 |
| 5 | Dominater069 | 145 |
| 6 | errorgorn | 141 |
| 7 | cry | 139 |
| 8 | YuukiS | 135 |
| 9 | TheScrasse | 134 |
| 10 | chromate00 | 133 |
|
+13
See this case: You can see that if you clean the cell in (1, 3) (1-indexed, (row, col)) you will avoid doing some forced cleaning twice near the end. If you are doing DP, probably you just need to add one more transition to take care of this. |

|
0
I see "Form link is expired" when I try to register |
|
0
Could you elaborate a bit more on this part?
i.e. how does finding that there are no contradictions when labeling each edge as odd/even guarantee we can ultimately remove all the edges in some order (in particular, according to the way it's done in the editorial's implementation) |
|
+19
I didn't get Bellman Ford to pass, but alternatively you can do Dijkstra instead by grounding your constraints on 0s instead of 1s, i.e.
The other two constraints must be satisfied as well:
Constructing a constraint graph (see link provided by Lain) and running Dijkstra (OK as there are no negative edges) leads to its distance array $$$dist$$$ being equal to $$$B$$$ (which is now a prefix sum array on the number of 0s) from which is easy to derive an answer. Also, $$$dist$$$ has the property that $$$B[n] - B[0]$$$ is maximized, and so the number of 0s is as big as possible. Apparently this technique is well-known in Japan as 牛ゲー. Also for anyone reading this and wanting to learn more, you can also look up chapter 24.4 in CLRS. My submission: https://atcoder.jp/contests/abc216/submissions/25456483 |
|
0
In problem F, to optimize the solution to $$$O(2^n \cdot n)$$$ using the first way described, how to actually achieve that complexity? Wouldn't updating the products and rolling back (in $$$O(n)$$$) for each possible state of $$$f(i, S)$$$ calculated recursively (for which there are $$$(n + 2) * 2^{(n + 2)}$$$ states) take $$$O(2^n \cdot n^2)$$$ in total? |
|
0
You would need to keep the number of zeros/ones in each node, and then you can find the first prefix s.t. there are >=k zeros/ones. |
|
0
Here are some slides on the exponential formula that are also very useful. |
|
-8
Can you elaborate on what a convexity argument is? |
|
On
askd →
Introducing cp-notes.com — a place for your interesting competitive programming problems!, 5 years ago
0
Could you add yukicoder to the list of platforms? |
|
+5
I will need to go back to this problem again lol. Thanks for writing this down! |
|
+4
Here's an smaller case: If we DFS from 1, and end up visiting in this order: 1 -> 2 -> 3 -> 4, when we are at 4, your solution would count that 4 can only have one color choice (since 1 and 3 have been visited), but since there is no edge between 1 and 3, nothing forbids them from having the same color. If this DFS algorithm worked, then k-coloring would be solvable in polynomial time :) |
|
+4
Do we have an update on this contest? |
|
On
Candidate_Master_2021 →
Whats the difference between ICPC problems and Codeforces Problems?, 5 years ago
+10
There was a discussion here: https://mirror.codeforces.com/blog/entry/88979 |
|
0
Supposing we know $$$a$$$ (we do, these are the initial positions of the tokens) and $$$b$$$ (we don't, these are the final positions of the tokens): if the XOR (symmetric difference) of these two sets is $$$T$$$, then at least we know the answer exists, and $$$b$$$ is one such possibility. The intuition here is the following:
Now, from $$$a$$$ and $$$T$$$ we can recover $$$b$$$. Because:
It should be the case that $$$|a| \geq |b|$$$. Otherwise, we need more final positions than # of initial tokens we had. Note that when we recover $$$b$$$ from $$$a \oplus T$$$, it could be that $$$|b| \leq |a|$$$. Finally, we do the following DP. $$$dp[i][j]$$$: The minimum cost of matching the first $$$i$$$ positions in (sorted) $$$a$$$ with the first $$$j$$$ positions in (sorted) $$$b$$$. For each transition, we might decide to pair $$$(i, j)$$$ or pair $$$(i, i + 1)$$$ (since there are not enough $$$b$$$s). The answer is when everything has been paired ($$$dp[|a|][|b|]$$$). |
|
0
That helps, thanks! |
|
+5
Nice proof! There's two things I would like to ask about:
|
|
0
In problem D (Moving pieces on a line), can anyone provide some intuition/case why the following greedy solution is incorrect?
At the end you check if every edge is marked with 0. If they are, there's a solution, otherwise there isn't. The cost of your solution is defined by how you decided to greedily move the tokens (as described above). |
|
0
It's never possible to have a set of odd size of odd vertices. Why: Think about including an edge. An edge is always incident to two vertices. When the edge is included, the parity of both is changed, so the size of your "odd degree" set of vertices changed in size by +2, 0, or -2. Size = 0 is always possible (don't include any edge), and from then you can only move (+2,0,-2) as I described. |
|
0
Heh, I feel like problem E from ARC 115 (contest that took place ~2 hours before this one) is very similar to problem E here. |
|
+29
Sorry for reviving this. But in case anyone is interested, I drafted this compilation on the AND, OR and XOR convolutions sometime back in 2018: link (maybe chapter 3 and 4 could be interesting to someone). |
|
+3
$$$C = 2.5⋅10^6$$$ is the maximum value an element can take. |
|
+5
+1 I would also appreciate if someone could write down an additional solution sketch too. |
|
+8
You can think of the pigeonhole principle. Remember that there are always four distinct indices $$$x, y, z, w$$$ such that $$$a_x + a_y = a_z + a_w$$$ ($$$ = S$$$) when there are at least four distinct pairs of indices $$$(x_1, y_1), (x_2, y_2), (x_3, y_3), (x_4, y_4)$$$ (indices may be repeated across them) such that $$$a_{x_1} + a_{y_1} = a_{x_2} + a_{y_2} = a_{x_3} + a_{y_3} = a_{x_4} + a_{y_4} = S$$$. Let's imagine we are running our $$$\mathcal{O}(n^2)$$$ bruteforce and trying every pair; for every pair $$$(i, j)$$$ we compute its sum $$$a_i + a_j = S$$$ and increment the count on how many times we have seen the sum $$$S$$$. Given that the maximum sum of any pair is $$$2*C$$$, the "longest" it would take the bruteforce to see one sum $$$S$$$ occurring four times is around ~$$$3 * (2 * C) = \mathcal{O}(C)$$$. Therefore, if a solution exists, it will be found in time $$$\mathcal{O}(C)$$$. If there's no solution (we tried all pairs), it was the case that (roughly) $$$n^2 \le 3 * (2 * C)$$$ (or something close to this). |
|
0
Turns out I wrote the wrong thing then ): |
|
On
P_Nyagolov →
[Tutorial] Nearest Neighbor Search: Locality-Sensitive Hashing, K-Dimensional Tree, Vantage-Point Tree, 5 years ago
+2
I think there's a typo in this line: "And here you go, the average-case complexity for a k-d tree query is actually $$$O(3^d * N)$$$." Shouldn't it be $$$O(3^d * logN)$$$? |
|
0
I thought we had all of February 5th (until 23:59 UTC) at least to register... ): |
|
0
You might also consider that accidental/intentional participants who are subject to rating changes who decided not to solve anything/quitted the contest will result in rating inflation for those who did solve something. |
|
0
Change |
|
+9
A few typos in the first line of the solution explanation for problem D. It should be: Since sequence $$$b$$$ is non-decreasing and sequence $$$c$$$ is non-increasing, we need to find $$$max(c_1, b_n)$$$. |
|
+2
Replace bool[] arrays with vector |
|
+24
It's happening :D |
|
+11
|
|
On
Magolor →
Codeforces Round #502 (in memory of Leopoldo Taravilse, Div. 1 + Div. 2) —— Editorial, 8 years ago
+43
|
|
+3
Because we are assuming that b is the maximum distance to a corner cell, which is equal to the maximum number in the list. |
|
0
I received an e-mail claiming the round was to be held at 15:05 UTC. To my surprise, one contest hour had already passed when I was getting ready to participate :( |
|
0
|
|
0
I have a question regarding your definition on what a extreme point is and how it behaves in the code. For the polygon stabbing function, you find both the right and left extreme points. Let's say we have the following polygon (I have labeled the vertices starting from 0 in counterclockwise order) and the following line:
Since the line vector is horizontal pointing in the x-axis positive direction, I would expect the extreme point in this direction to be point at index 2 (coordinates: (7,3)), as there is no vertex in the polygon further to the right (or as they define it equivalently in geomalgorithms, no other point in the polygon protected onto the line is further in the direction of the line vector). For the same vector in the opposite direction, I would expect the extreme point to be point at index 0 (coordinates: (1,1)). I tried running such example using the polygon stabbing function presented here but I get index 3 for extreme point when the line vector is pointing in the x-axis positive direction, and index 0 when the line vector is pointing in the x-axis negative direction. Could you enlighten me on what I'm misunderstanding? Also, could we use dot product instead of cross product to check whether some vertex i is above some vertex j? (particularly in the case when the direction is fixed) |

|
On
MikeMirzayanov →
2017-2018 ACM-ICPC, NEERC, Southern Subregional Contest, qualification stage (Online Mirror, ACM-ICPC Rules, Teams Preferred), 9 years ago
0
Why is it allowed to wait in the start point? The statement says: "After the show starts the dog immediately begins to run to the right to the first bowl." Am I missing something? |
|
0
Yes, I omitted that detail. Let's say you initialize left = width, right = 0. For every column of interest, update them accordingly if column c ended up having an unenlightened cell: |
|
+1
First, let's enumerate the columns of interest, because we believe that we may find a cell that has not been enlightened in them. Let's call this set of columns C = [c1, c2, ..., ck + 1] Notice that c1 = 1, since it's the leftmost column in the grid and there's a chance there is at least one empty cell. As for the rest of the columns of interest, we cannot try every single other because the width of the grid can be up to 109, so we should reason about which columns we should pick. Notice that if, when we are doing our binary search and we are evaluating if it's possible to enlighten the whole grid at a time t, the leftmost position an initially enlightened cell at (r, c) will be able to reach is (r, c - t). Therefore, column c - t - 1 may have one unenlightened cell. So we check for that column if that is the case. Let's do this for the remaining k initially enlightened cells (c2, c3, ..., ck + 1), so we have a total of k + 1 columns to try for the leftmost one. The same way idea can be applied to the rightmost column, top and bottom rows. How to check for a column c if it has one unenlightened cell? Let's iterate over every initialized enlightened cell (there are k of them). For each of them, at a time t, you want to know the range of cells from column c it is responsible for enlightening. Let's say that initialized enlightened cell is at (r', c'). The leftmost cell it's going to be able to enlighten is c' - t. If c' - t is at or left to c, it's obviously going to reach it, and what vertical range does it cover in this column? It's going to be [r' - t, r' + t], because as fire propagates in one direction, it's going to be propagating in the rest of the directions, so if it propagated t units to the left, every of those t columns covered will also cover t cells up and down. Store the range [l, r] this initialized enlightened cell spanned for column c in a list. Repeat for the rest of the k - 1 enlightened cells. Now the only remaining step is, sort the list by l, in case of tie, by r. Calculate the total range it covers by keeping track of the last endpoint covered so as to avoid counting some segment more than once, and check if cellscovered < heightgrid. If that is the case, there was at least one unenlightened cell in that column. |
|
+1
We don't iterate from i = 1 to |
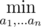 , instead it's up to
, instead it's up to 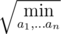 . When you want to divide some
. When you want to divide some 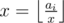 . Therefore
. Therefore 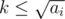 or
or 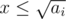 . Thus, it's possible to check every case by checking up to the root. Since on each iteration we iterate over our array of size
. Thus, it's possible to check every case by checking up to the root. Since on each iteration we iterate over our array of size 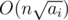
|
0
Can someone elaborate on the following from problem E's editorial?
|
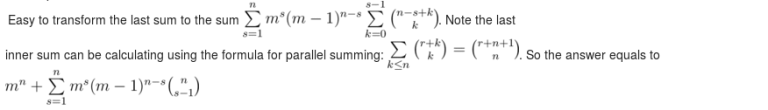
|
+13
Countries as dangos. Nice! |
|
-14
Nevermind what I wrote, I thought you were referring to problem A. |
|
+6
Sigh, I was solving the wrong problem A the whole time. I was solving "change at most one letter" instead of "exactly one letter", even if that was in bold in the problem statement :( |
|
0
Just a moment after I posted, I realized sorting was enough to assign contiguous mice to a hole. As for the hole capacities, yep, I meant that (and I missed it's as simple as that!) Thank you :) |
|
0
How do you deal with hole capacities and the fact that contiguous mice are not necessary assigned to the same hole? |
|
-9
Xellos, could you reupload the image you used to explain the solution for problem A? |
|
On
RedNextCentury →
[Gym Contest Editorial] Damascus Collegiate Programming Contest (DCPC 2015), 9 years ago
0
This is my solution: http://pastebin.com/ei4w5zRU |
|
0
Thank you! |
|
0
Can you elaborate a bit more on setting dp[x][0] = 1 and dp[x][k+1] = 1? |
|
0
Problems can be found here: https://www.urionlinejudge.com.br/judge/en/challenges/contest/211 How to solve C? |
|
+4
I am having the same problem. |
