



|
0
You could solve the problem with a greedy: https://mirror.codeforces.com/contest/1987/submission/268268604 I imagine that is why the rating is not as high as you thought. |

|
0
I feel upset that I find G1 is easy for me now .... qwq |

|
+3
I still don't know why there are so many Accepted solutions in the problem D, the dynamic programming is not that so easy, it make my head blow up and many of my candidate master friends didn't solve it. However, according to the clist.by, it is only a 1600 rating problem, I thought it should be at least 1900. |

| Created or updated the text |

|
0
Thank you so much for this detailed explanation for the dp approach. Finally understood it. |

|
0
Hi, may I know why this approach failed when the operation started from the root (not from the leaf)? When I do iterate from node $$$1$$$ to $$$n$$$, it failed. Else, it correct. Same things happens when you reverse the order of the official solution to [0, n-1]. |

|
0
Your explanation is exactly correct. Essentially it's accumulated turns Bob can use to take several indices, so he can block Alice from taking them. The term "allowance" may not really make sense, and if so I'm sorry about that. It's abstract concept (kind of), and I wasn't really sure the right term for it. |
|
0
its important to remove all cakes of same level of taste cause if bob eat some amount of that a certain level and leave the other then alice will eat the remaining and still be gaining points |

|
0
hello |
|
0
Hey, bro does that depth_cnt[i][j] means vertex i which is at depth j and can be used depth_cnt[i][j] no of times. Can you confirm. Pls |

|
+1
It means, Bob can complete his step 1 (allowance) before Alice can take her next step. |

|
0
The "allowance" is defined as the number of moves that Bob hasn't taken yet. If Alice takes the index $$$i$$$, Alice moved but Bob hasn't, so Bob now has an extra move. This means that his "allowance" is increased by $$$1$$$. It's a really abstract idea to me and I personally didn't solve it in the contest (womp womp to me). |
|
0
in case someone gets WA on test 2 in E and so you don't spend an hour to find the test: Testcase 580 in Test-2 in E Wonderful Tree: I was using set, and at some point I had to keep two states with depth 2 and delta 1, but set obviously only kept one copy.. so, use multiset. :) |

|
0
I wonder if the rating changes will get temporarily rolled back and I get to pupil after :') |
|
0
Great |
|
+6
-331 points to CM, i can't wait |

|
0
Thank you for letting me know, I've corrected it. |

|
0
Thank youu so much for the reply! there is one thing i still dont understand tho, when you say "If Alice takes the index i, Bob gains 1 allowance." what exactly do you mean by this? |

|
0
Afterall it's problem E not A or B, so since making $$$n\le 2\times 10^5$$$ isn't actually a big increase in the difficulty (most people who can solve to this problem should know small to large merging, and it had appeared in div2 contests before), why not make it like that? Setting the constraint to $$$5000$$$ would make people like me who are used to this technique doubt why the constraint was so small, and I had to look back really carefully just to make sure that I hadn't misread anything. |

|
0
It's so strong, I simulated it for more than two hours to make it, and you can write this dp in a few minutes |

|
0
"adds more to a problem" not necessarily in a good way, and here i agree there is literally no difference between the 2 except for harder implementation and knowledge of the technique ofc |

|
0
Although The first 2 points are straight forward but can you explain me 3rd point " Bob should only eat a cake if he intends to eat all of those cakes of that level of tastiness" isn't it optimal for bob to pick " largest unique values " because no matter what the frequency is alice can only eat once for each element ? |

|
+10
1,9,5,4,5,2,3,3,5 |

|
+16
Ratings will be calculated differently for new users for the first 6 contests,read this blog for detailed process- https://mirror.codeforces.com/blog/entry/77890 |
|
+10
First, create an array $$$\{c_n\}$$$ that contains the count of each value of $$$a_i$$$, in the order of increasing $$$a_i$$$. For example, if $$$a = \{ 3, 2, 2, 2, 5, 5, 5, 5 \}$$$, then $$$c = \{ 3, 1, 4\}$$$ (the count of $$$2$$$ is $$$3$$$, the count of $$$3$$$ is $$$1$$$, and the count of $$$5$$$ is $$$4$$$). Let's say the length of $$$c$$$ is $$$m$$$. We forget $$$a$$$ for the rest of the tutorial, and we call cakes with the same value of $$$a$$$ using the index of $$$c$$$ (the cakes $$$i$$$ ($$$i = 0, 1, \ldots, m - 1$$$) implies the $$$c_i$$$ cakes with $$$(i+1)$$$-th smallest value of $$$a$$$). Note we use the $$$0$$$-based index for $$$c$$$ below. Alice's optimal strategy is simple: it's always optimal for her to take the smallest index (in terms of $$$c$$$) that's available to her. For Bob, he chooses a set of indices $$$x_1, x_2, \cdots, x_k$$$ ($$$1 \le x_p \le m$$$, $$$1 \le p \le k$$$) and try to eat all of the cakes $$$x_p$$$ before Alice can eat any of them, and he wants to maximize $$$k$$$ (the size of $$$x$$$). Here we want to consider when Bob can take the cakes $$$i$$$. Obviously, he doesn't want to take cakes $$$0$$$ (because Alice takes one of them in her first turn, and it doesn't make sense for him to eat the rest if any). He can take cakes $$$1$$$ if and only if $$$c_1 = 1$$$ (if $$$c_1 \ge 2$$$, then Alice can eat one of cakes $$$1$$$ in her second turn). Similarly, he can take cakes $$$2$$$ if $$$c_2 \le 2$$$, and so on. So we can think of the following algorithm: Bob has $$$0$$$ allowance initially. We look at each $$$i$$$ in the increasing order, and assign Alice or Bob to each index. If Alice takes the index $$$i$$$, Bob gains $$$1$$$ allowance. Let's say Bob has $$$j$$$ allowances so far. Then he can take the index $$$i$$$ if $$$j \ge c_i$$$, and by doing so he loses $$$c_i$$$ allowances. At this point it's relatively straightforward to build a DP. Let's define $$$\mathtt{dp}[i][j]$$$ as the maximum possible number of indices Bob took so far, where $$$i$$$ is the index of cakes we're going to look at next, and $$$j$$$ represents Bob's allowances. The state transition is:
The final answer (the number of Alice's indices) is $$$\displaystyle m - \max_{0 \le j \le m} \mathtt{dp}[m][j]$$$. The table size is $$$(m + 1)^2$$$, and it takes $$$O(1)$$$-time to calculate each cell of $$$\texttt{dp}$$$, so the algorithm requires $$$O(m^2) = O(n^2)$$$ memory and time. Note that the memory limit 256MB is a bit tight for the $$$5001^2$$$ element table, so you might want to avoid allocating the whole table and calculate each row incrementally. |
|
0
Still doesn't make any sense, my other friend has an old account, his prev rating was 1048, he got a rank of 10667 and -36 rating only, So you wanna say that at better rank with lower previous rating you will get -49 and at worse rank and higher prev rating you will get only -36? Where's the logic in this. |
|
+34
Except that it didn't actually prevent most of those worse complexity solutions from passing, and it only made a vague boundary between lower and higher constant solutions. Authors should not only consider their own solution but also whether they would want to allow worse solutions to pass or not, and try to block them if they don't want them to pass. If they didn't want $$$\mathcal{O}(N^2)$$$ memory solutions to pass, then a viable option would be setting $$$N \le 10000$$$ and maybe a bit more TL (and 128 or 64 MB ML is also an option). They should still be fast enough with any $$$\mathcal{O}(N)$$$ memory solution because of high cache hit rate and small I/O. If they had no intention to block $$$\mathcal{O}(N^2)$$$ memory solutions, then the ML should just be higher. It's like setting an $$$\mathcal{O}(N)$$$ problem with $$$N \le 30000$$$ with 1 second TL. If they don't want $$$\mathcal{O}(N^2)$$$ solutions to pass, they should increase the upper limit of $$$N$$$. It's a very poor preparation of a problem if they just go with "we have a $$$\mathcal{O}(N)$$$ solution, so it's up to you if you're gonna try $$$\mathcal{O}(N^2)$$$ solution or not". |
|
+23
Because he is a new account. In his fifth round, he will have extra +100 rating. So it seems like he got +51, but actually he got -49. |

|
-22
I liked this problem (and contest) but this type of setter takes are so dumb. Optimizing to a completely new complexity class always adds more to a problem... Isn't the cool part seeing what's the limit possible? |

|
0
If author solutions have better O complexity of memory, why should they have to help worse complexity pass? You can still get lucky but I don't get why memory should be treated as so variable and only time complexity is more strict. |
|
0
Hello everyone, I am a newbie in competitive programming. I am looking for a friend ranked preferably higher than me to ask doubts and discuss problems. If anyone can help me out that would be great |

|
-8
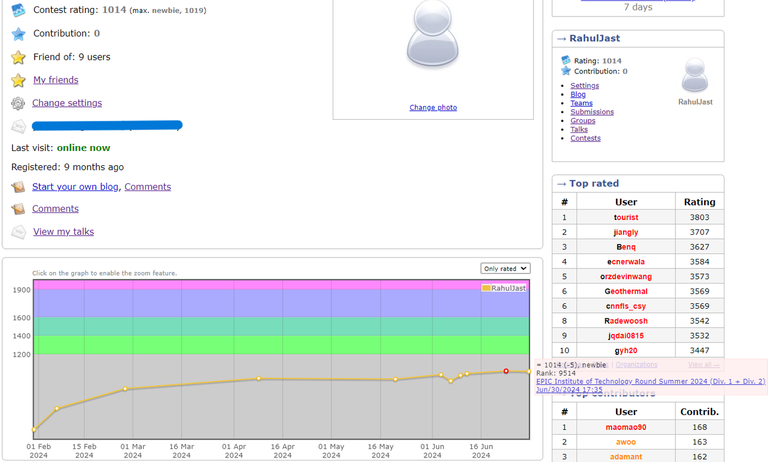
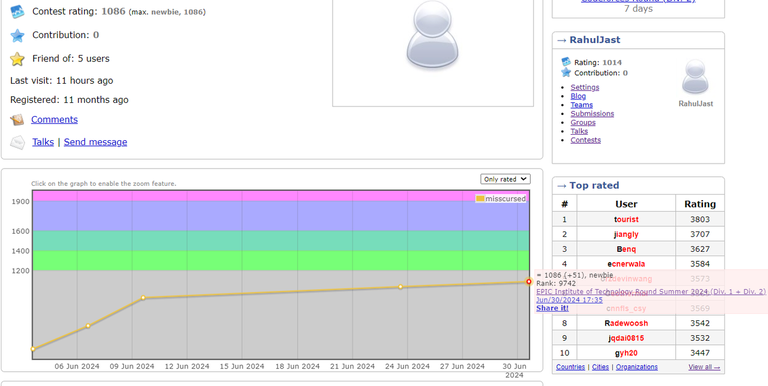
How does the rating even work here? My prev rating was 1019, and my friend's was 1035, We both solved 2 problems, A and B, but I did it faster and got a better rank than him, still I got a -5 and my friend got a +51 rating, why is that tho? Both of our solutions got accepted, The screenshots are evident of it, Anyone can explain? this doesn't make any sense
|
|
+10
I'm not first solve for A, sstrong submitted 2 seconds earlier: https://mirror.codeforces.com/contest/1987/standings/participant/185369380#p185369380 Found them by sorting by submission time. |

|
0
man the rating change in this round is so harsh :( |

|
0
Please explain the approach for D in little detail??? saw other comments but they seemed kinda vague, ppl have just given the transitions they used in dp without any/proper explanation... |
|
0
yes, it would be |

|
0
What is the counterexample for that? I wasn't able to come up with or generate a counterexample and I still don't know why it isn't working :P |

|
+6
DP Forces |
|
0
Baradar English sohbat mikone |

|
0
div1+2 is generally harmful for low division < +1900, it's not my opinion but statistics. |
|
0
Great job, congrats |


|
0
i dunno bad tasks today or i'm dumb, but i'm able solve only A, somehow have 1300 on another acc. Div2 always roulette |

|
0
I was struggling greatly with ML in E, but once I switched from a pbds UPD: I realized that by looking up different depths in a loop I was implicitly adding more and more keys to my hashmaps, leading to MLE. Also even my in-contest solution gets TLE now, well played. |

|
+4
Lets take frequency array F = {4, 4, 4, 3, 5, 5, 2} Now, according to your approach :
now no matter what Bob does, Alice can choose 3 more cakes. So total 6 cakes. But, if Bob started with 4th cake type then he can also complete last cake type before Alice reach there. So, Alice only can take 5 cakes. |

|
0
this contest was literal nightmare for me. slow solve ABC + unable to solve D (too incompetent) feel worthless. |
|
0
Take a look now, it was close and not impossible |

|
+1
I did use small to large merging Although couldn't ac E because of a stupid silly mistake (Forgot to clear the global priority queues) -_- But it turns out that the setters allowed O(n^2 log(n)) solution to pass. |
|
+28
ExplodingFreeze Isn't the answer at nost $$$n\cdot \max(a)$$$ because you can just increase everything to be equal to $$$\max(a)$$$? |

|
+32
Is there a reason for the lower problems to have 256 MB limit? Especially for problem D and E, it's easy to come up with various solutions that use $$$\mathcal{O}(n^2)$$$ memory, and a single Apparently, in problem E, it seems like an overlook that many solutions that use $$$\mathcal{O}(n^2)$$$ memory with very high constant passed, including mine. It's kinda lucky for me that the tests didn't have this simple test with a straight tree with no operations required. I knew that my solution can easily fail on this test, but I just believed that the tests are weak :) There are dozens of uphacks already (https://mirror.codeforces.com/contest/1987/hacks?verdictName=CHALLENGE_SUCCESSFUL ), but there could be more of them that can be hacked with other patterns. I personally see no reason to use a tight ML like 256 MB nowadays, unless there is a solution that has to fail with that exact limit and not any more lenient. |
|
-8
for _ in range(int(input())): n=int(input()) l=list(map(int,input().split())) op=0 def f(l,op): t=False if len(l)<=1:
return op
for i in range(len(l)-2,-1,-1):
if l[i] ==i+1 and len(l)>=2:
l.pop(i)
t=True
l.pop(i)
op+=1
print(l,i)
break
if t==False:
return op
return f(l,op)
print(f(l,op))can someone please explain me why this is incorrect? |

|
0
Random algorithms are random no matter the test. So one could submit several random solutions and the chance of all of them failing would be significantly smaller. |

|
0
can anyone plz tell what is wrong with my logic for B. here is my code-268197602 |
|
+1
yes (at least the way I solved it) |
|
0
started 50 min late,great contest tho |

|
+18
For me, the number of cases was the same for G1 and G2. For G2 all I needed to add was if statements before some of the cases from the G1 solution. |
|
0
Yeah I started with greedy too. The correct approach requires dp. The tutorial is out now. |
|
-28
Still, it is assumed that the pretests are good enough |

|
0
Because it will be abused by solutions which pass with certain probability? |

|
0
I also tried assigning cakes to bob greedily(minimum frequency first) but I got wa2 |

|
+10
Thank you for the contest! In particular, most of the problems get away from the common pattern of "solve me much faster than O(input^2)", which is nice and refreshing. |
|
0
Why can't system tests just test solutions in order? |
|
+3
many problems are easy... once you know the solution |
|
0
When a contestant realizes there is a bug in their submission, and have not yet locked it, they should be able to resubmit. Naturally, the last such attempt will be tested. If you want to submit an optimized version that shouldn't affect the standings, you can do it after the contest. |
|
+23
|
|
+10
orz |

|
+1
For D: Observation 1: Order does not matter, so move things around however we want Observation 2: It is always optimal for Alice to eat the smallest cake, so we should sort the cakes Observation 3: Bob should only eat a cake if he intends to eat all of those cakes of that level of tastiness So with that, we can reduce this problem down to: for each type of cake (so we aggregate into tastiness, frequency pairs) in sorted order of tastiness, will Bob eat all of this type of cake or will Alice eat one of the cakes? Let's think about the consequences of each action Alice eats the cake: +1 to Alice's score, but Bob can eat 1 more cake Bob eats the cake: Bob can eat $$$count[cake]$$$ fewer cakes, but Alice's score does not change. Let $$$dp[i, j]$$$ represent the minimum number of cakes Alice can eat, starting with the $$$i^{th}$$$ least tastiest cake with Bob being able to eat $$$j$$$ cakes. This leads to recurrences: |

|
0
What are u reading ? Please don't |

|
+34
lol |

|
-39
In this contest, I definitely reached the expert and at the end of the competition I decided to resubmit problem D with optimization (just like that, I understood that my first solution worked). But I didn’t know that only the last attempt is counted, where is it even said about this? And why some people have multiple parcels tested (in system tests). Because of this stupid rule, I will not reach the expert, thanks for this, any desire for programming is gone. |
|
+3
Sorry this might be dumb but what is random stress tester, is it different from stress testing we do? |
|
+2
The second reason is correct, I didn't feel like it added much to the problem) |
|
0
wouldn't it be the minimum $$$j$$$? |

|
0
solved D using simple memoization (just think if bob has to remove any element then he should have to remove all occurrences of that element and just do dp[submission:268191223] |

|
0
also curious if it is possible to implement G2 quickly and clean |
|
0
I'm a little confused why G2 is separated from G1, the feeling of having to add many cases and pre-calculations into the code is really frustrating. (And I failed to debug it in time) Using G1 only will make the problem more clean. Discard G1 and use G2 only will make the thinking process less interrupted and will prevent coding from being tedious in my opinion. Anyway, the problems are good. |
|
0
I suspect its to prevent irritating issues with overflows. Like, you need a leaf to contribute at least $$$n \cdot \max(a)$$$, but a node can sum to upto $$$n \cdot n \cdot max(a)$$$ which will overflow int64 for $$$n = 2 \cdot 10^5$$$ and $$$a_i \leq 10^9$$$. This is fairly easy to fix by capping the sum to $$$n \cdot \max(a)$$$ but its also irritating for no real reason. Also, I personally feel that adding small to large merging doesn't make the problem any better, its a bog standard implementation of it. |

|
0
solved using memoization (dp) ,logic is if bob has to remove any number than he remove all occurences of the number, calculate frequency of all element then store in a vector and do o(n^2) memoization (knapsack) you can see the memoization dp solution 268191223 |
|
0
seems i wasn't even close to the proper solutions. and thx. |

|
0
I actually was convinced the greedy idea was wrong but it passed ~500 rounds / 2 mins of stress testing at $$$N = 16$$$ so I submitted the code, only for it to find a countercase 2 seconds after submission T_T |
|
-8
FST — fail system tests (apparently pretests were actual system tests xdd) In short in my solution I was pulling negative sum nodes to their ancestors |
|
0
merge what? And what is FST thank you so much |
|
0
Since h>0, it is enough with: for (int j=0;j<n;j++) m=max(m,h[j]+j); (find the height which is the most costly) |
|
0
ahh got it, thanks |
|
0
Try to find how the answer increase from [i+1....n] to [i....n]. If a_i is smaller than a_i+1, it means there must be some point where a_i equals a_i+1, and when a_i+1 becomes 0, the work is done between[i+1....n], and more importantly a_i is now 1.so ans++. If equal, ans++. If bigger, it depends on what the current answer is. If current answer is bigger or equal than a_i, it still means there must be some point where a_i equals a_i+1, thus ans++. And if current answer is less, ans+=a_i-ans,which i guessed out. |
|
0
if |
|
0
I once read somewhere.. |

|
-7
Everybody at cloudflare needs to be locked up |
|
0
Traverse $$$a$$$ in reverse order. It is easy to see that the whole process will be terminated when $$$a_1 = 0$$$. Then, we only need to care about some positions $$$i$$$ such that $$$a_{i - 1} <= a_i$$$ because it will cause the process "delay". We will add $$$a_{i - 1} - a_i + 1$$$ to our result in this case because it is the required time to make $$$a_{i - 1} > a_i$$$. In the case that $$$a_{i - 1} > a_i$$$, we need to subtract $$$a_{i - 1}$$$ with the time that has passed, i.e our current result. The answer will be result added by the current $$$a_1$$$. Submission: 268158682 |

|
0
Random stress tester for F save me from penalty for F1 (Wrong greedy (take from back if possible) passes all quite small cases, so I should try larger tests, but happily in random case the number of possible state is not so large) |
|
0
Oh, I understand now. Thank you for your explanation and the clean code. |

|
0
i thought about finding increasing order from backward(N , N-1...) and currTime will the index where this break + 1( if there if atleast 1 more value than maxValue of sequence) and making this segments and taking maximum time |

|
+18
Problems are clean and organized overall, but the samples are a bit weak, especially for problem F. Literally any code could pass it (even if the dp was completely nonsense). BTW, E could be solved easily in $$$O(n\log n)$$$ with small to large merging, just curious why was the constraint $$$5000$$$? |
|
0
Thanks for the contest! Problems were quite good! Enjoyed today! |

|
+6
Another Cheatforces round...thank u indian students...submissions on C is crazy(bcoz code is small and easy to copy) |
|
0
I just bashed it with brute force until it passed pretests (still can FST tho). I also considered small-to-large merging, but at the time I thought it was not going to work. |
|
+1
Was C really easy or am I just stupid? |

|
+8
If $$$a_v \gt \sum a_{child}$$$, then we clearly need to increment $$$a_{child}$$$ for some child. Notice that incrementing a node $$$v$$$ by $$$1$$$ means that we will need to increment some chain of nodes $$$x_1, x_2, \cdots x_k$$$ where $$$x_1 = v$$$, $$$x_i$$$ is a child of $$$x_{i - 1}$$$ and one of the following conditions is satisfied for $$$x_k$$$:
Also observe that a given node can be used as $$$x_k$$$ by the first condition at most $$$\sum a_{child} - a_{x_K}$$$ times, while a leaf node can be used an unlimited number of times. Moreover, such a chain results in a cost of $$$k$$$. So at any instant, we want to pick the shortest chain possible, i.e, pick a node least depth first among nodes in the subtree of $$$v$$$ which satisfy the above condition. So we can just store the number of possible contributions at each depth for the subtree of each $$$v$$$ while iterating using dfs and use the above approach to fix cases where $$$a_v \gt \sum a_{child}$$$. Code — 268172990 |
|
+13
I have a solution for problem D with a complexity of $$$O(nlogn)$$$ 268173518. It's observed that Alice always picks the cake with the lowest tastiness from those remaining, and Bob will use some of his turns to take all cakes with the same tastiness. Therefore, we can solve this problem greedily. Specifically, when considering cakes sorted in increasing order of tastiness, if Bob can take all cakes with the same tastiness as the current cake being considered, we let Bob take them all. Otherwise, Bob will discard the maximum number of cakes he would have taken before and replace them with the current cake's value (provided there are fewer cakes of that value than the previous ones). Therefore, it's straightforward to use a priority queue to solve it. |
|
0
Spoiler |
|
+3
Place your bets, gentlemens: will my F1 randomized solution with time cutoff FST or not? |

