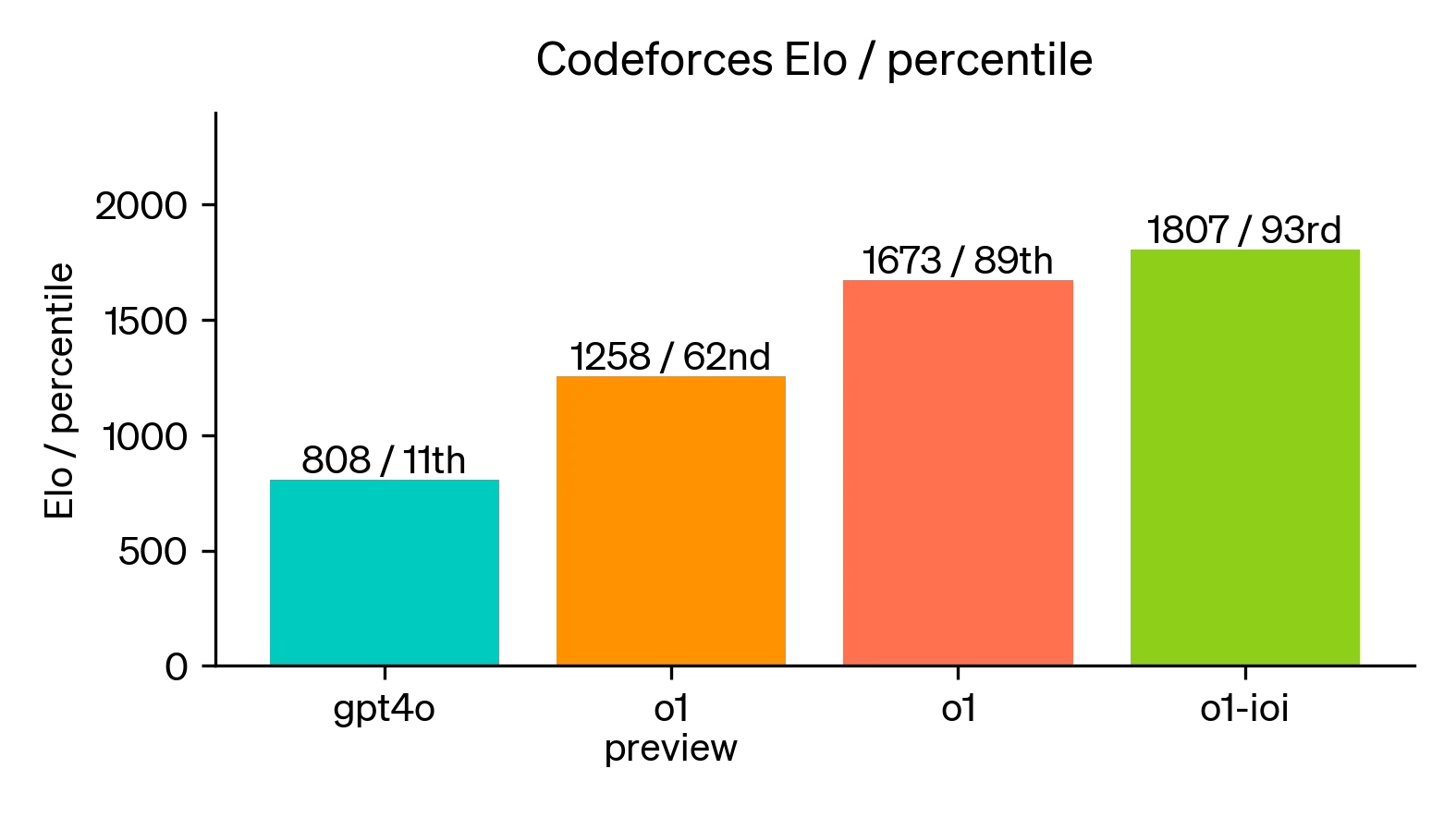From https://openai.com/index/learning-to-reason-with-llms/:
We trained a model that scored 213 points and ranked in the 49th percentile in the 2024 International Olympiad in Informatics (IOI), by initializing from o1 and training to further improve programming skills. This model competed in the 2024 IOI under the same conditions as the human contestants. It had ten hours to solve six challenging algorithmic problems and was allowed 50 submissions per problem.
For each problem, our system sampled many candidate submissions and submitted 50 of them based on a test-time selection strategy. Submissions were selected based on performance on the IOI public test cases, model-generated test cases, and a learned scoring function. If we had instead submitted at random, we would have only scored 156 points on average, suggesting that this strategy was worth nearly 60 points under competition constraints.
With a relaxed submission constraint, we found that model performance improved significantly. When allowed 10,000 submissions per problem, the model achieved a score of 362.14 – above the gold medal threshold – even without any test-time selection strategy.
Finally, we simulated competitive programming contests hosted by Codeforces to demonstrate this model’s coding skill. Our evaluations closely matched competition rules and allowed for 10 submissions. GPT-4o achieved an Elo rating3 of 808, which is in the 11th percentile of human competitors. This model far exceeded both GPT-4o and o1—it achieved an Elo rating of 1807, performing better than 93% of competitors.