


Idea: wakanda-forever Preparation: wakanda-forever
Let's say we have a sequence of numbers with an average equal to $$$k$$$.
Adding a number greater than $$$k$$$ increases the average, while adding a smaller one decreases it.
Therefore, the maximum average subarray is formed by taking the maximum element, since including anything smaller would only lower the average.
Hence, the final answer is the maximum element of the given array.
Time Complexity: $$$O(n)$$$ per testcase.
#include<bits/stdc++.h>
using namespace std;
#define ll long long
int main(){
int t;
cin >> t;
while(t--){
int n;
cin >> n;
vector<int> a(n);
for(int i = 0; i < n; i++) cin >> a[i];
cout << *max_element(a.begin(), a.end()) << endl;
}
return 0;
}
Idea: wakanda-forever Preparation: tridipta2806
We need to find a non-decreasing subsequence $$$p$$$ such that, after removing its characters from the string $$$s$$$, the remaining string $$$x$$$ becomes a palindrome.
Observe that if we choose $$$p$$$ to consist of all the $$$0$$$'s in $$$s$$$, then $$$x$$$ will contain only $$$1$$$'s, which always forms a palindrome. Similarly, if we take $$$p$$$ as all the $$$1$$$'s, then $$$x$$$ will contain only $$$0$$$'s, which is also a palindrome.
In both cases, $$$p$$$ is clearly a non-decreasing subsequence (since all its elements are equal).
Therefore, a valid solution always exists — we can simply output the indices of either all $$$0$$$'s or all $$$1$$$'s in the string.
Time Complexity: $$$O(n)$$$ per testcase.
#include<bits/stdc++.h>
using namespace std;
#define ll long long
int main(){
int t;
cin >> t;
while(t--){
int n;
cin >> n;
string s;
cin >> s;
vector<int> pos;
for(int i = 0; i < n; i++) if(s[i] == '0') pos.push_back(i + 1);
cout << (int)pos.size() << '\n';
for(auto& z : pos) cout << z << ' ';
cout << '\n';
}
return 0;
}
Idea: wakanda-forever Preparation: wakanda-forever
We are allowed to choose any $$$x$$$ such that $$$0 \le x \le a$$$ and set $$$a := a \oplus x$$$. Our goal is to make $$$a$$$ equal to $$$b$$$.
Let's think of the binary representation of $$$a$$$. Consider the highest set bit (most significant bit) of $$$a$$$ and let's assume its position is $$$\operatorname{msb}(a)$$$.
At each operation, we are choosing $$$x \le a$$$, which implies that $$$\operatorname{msb}(x) \le \operatorname{msb}(a)$$$ (otherwise, we have $$$x \gt a$$$).
Now, we can surely say that $$$\operatorname{msb}(a \oplus x) \le \operatorname{msb}(a)$$$.
Thus, by performing the given operation, $$$\operatorname{msb}(a)$$$ will never increase. So, if $$$\operatorname{msb}(b) \gt \operatorname{msb}(a)$$$, the answer is $$$-1$$$.
Otherwise, we can always transform $$$a$$$ into $$$b$$$ in a constructive manner.
First, we set all bits below $$$\operatorname{msb}(a)$$$ one by one to ensure that every required bit can be manipulated. Then, for each bit that is $$$0$$$ in $$$b$$$, we unset it using an appropriate XOR operation.
By following this process, we can reach $$$b$$$ from $$$a$$$ in less than $$$60$$$ operations.
Time Complexity: $$$O(\log_2(a))$$$ per testcase.
#include<bits/stdc++.h>
using namespace std;
int main(){
int t;
cin >> t;
while(t--){
int a, b;
cin >> a >> b;
if(__builtin_clz(a) > __builtin_clz(b)) cout << "-1\n";
else if(a == b) cout << "0\n";
else{
vector<int> val;
for(int i = 0; i < 31; i++){
int x = (1 << i);
if(x <= a && (a & x) == 0) a += x, val.push_back(x);
}
for(int i = 0; i < 31; i++){
int x = (1 << i);
if(x <= a && (b & x) == 0) val.push_back(x);
}
cout << val.size() << '\n';
for(auto z : val) cout << z << ' ';
cout << '\n';
}
}
}
Idea: wakanda-forever Preparation: wakanda-forever
We denote
Now, let us try to find $$$l$$$ first.
Consider two additional arrays representing the prefix sums of the arrays $$$p$$$ and $$$a$$$, defined as follows:
Analysing these, we can say that $$$\text{pref_sum_a}[i] \ge \text{pref_sum_p}[i]$$$ for all $$$i$$$. In fact, the inequality holds true only when $$$l \le i \le n$$$.
Thus, we can binary search for $$$l$$$.
At each stage, we make $$$2$$$ queries $$$\operatorname{query}(1, 1, \text{mid})$$$ and $$$\operatorname{query}(2, 1, \text{mid})$$$, and by comparing these, we can adjust $$$\text{left}$$$ and $$$\text{right}$$$ in binary search.
We can also find $$$r$$$ by querying suffixes in a similar way, but that would take a total of $$$4 \cdot \lceil \log_2(n) \rceil$$$ queries. This exceeds the query limit.
Instead, we can query the whole array once and find $$$r$$$. In other words,
So, after finding $$$l$$$, we can find $$$r$$$ in $$$2$$$ queries. Total queries will be equal to $$$2 \cdot \lceil \log_2(n) \rceil + 2$$$ ($$$ \lt 40$$$).
Time Complexity: $$$O(\log_2(n))$$$ per testcase.
#include<bits/stdc++.h>
using namespace std;
#define ll long long
ll query(int type, int l, int r){
ll x;
cout << type << ' ' << l << ' ' << r << flush << endl;
cin >> x;
return x;
}
int main(){
int t;
cin >> t;
while(t--){
int n;
cin >> n;
ll sum = query(2, 1, n);
sum -= ((n * (n + 1)) / 2);
ll diff = sum - 1;
int l = 1, r = n;
while(l < r){
int md = (l + r) / 2;
ll val1 = query(1, 1, md);
ll val2 = query(2, 1, md);
if(val1 < val2) r = md;
else l = md + 1;
}
cout << "!" << ' ' << l << ' ' << diff + l << flush << endl;
}
}
Idea: wuhudsm Preparation: wakanda-forever
Instead of carefully choosing all $$$k$$$ elements individually, it is sufficient to pick three distinct integers $$$x$$$, $$$y$$$, and $$$z$$$ and repeat them cyclically — that is, append
until we perform $$$k$$$ operations. For $$$n \ge 3$$$, we can always find such $$$x$$$, $$$y$$$, $$$z$$$ that add no extra palindromic subarrays.
Now let's try to find such integers $$$x$$$, $$$y$$$, $$$z$$$. There will be two cases.
Case 1: $$$a$$$ is a permutation of $$${1,2,3, \dots ,n}$$$.
If the array $$$a$$$ is a permutation, we can simply choose the first three elements of $$$a$$$ for the construction. That is, let $$$x = a_1$$$, $$$y = a_2$$$, and $$$z = a_3$$$. Since all elements in a permutation are distinct, these choices guarantee that $$$x$$$, $$$y$$$, and $$$z$$$ are distinct and add no extra palindromic subarrays.
Case 2: $$$a$$$ is not a permutation of $$${1,2,3, \dots ,n}$$$.
If the array $$$a$$$ is not a permutation, we can choose $$$x$$$ to be any integer that does not appear in $$$a$$$. Let $$$z$$$ be the last element of the array, and choose $$$y$$$ as any integer different from both $$$x$$$ and $$$z$$$. These three numbers will always be distinct and add no extra palindromic subarrays.
Time Complexity: $$$O(n + k)$$$ per testcase.
#include<bits/stdc++.h>
using namespace std;
int main(){
int t;
cin >> t;
while(t--){
int n, k;
cin >> n >> k;
vector<int> a(n), cnt(n + 1, 0);
for(int i = 0; i < n; i++) cin >> a[i], cnt[a[i]]++;
int x = -1;
for(int i = 1; i <= n; i++) if(cnt[i] == 0){
x = i;
break;
}
if(x == -1){
for(int i = 0; i < k; i++) cout << a[n - 3 + (i % 3)] << ' ';
cout << '\n';
}
else{
int y = -1;
for(int i = 1; i <= n; i++) if(i != x && i != a[n - 1]){
y = i;
break;
}
vector<int> v = {x, y, a[n - 1]};
for(int i = 0; i < k; i++) cout << v[i % 3] << ' ';
cout << '\n';
}
}
}
Idea: frostcat, wuhudsm, wakanda-forever Preparation: wakanda-forever
Note that if $$$[0,2,1]$$$ is a subsequence of permutation $$$p$$$, any interval that includes $$$0$$$ and $$$1$$$ must also include $$$2$$$. This implies that $$$\operatorname{mex}$$$ of any interval will not be equal to $$$2$$$. So, $$$2 \notin M$$$. Hence, $$$\operatorname{mex}(M) \le 2$$$.
Thus, we can always ensure that $$$\operatorname{mex}(M) \le 2$$$. Now, we only need to check when $$$\operatorname{mex}(M) = 0$$$ and $$$\operatorname{mex}(M) = 1$$$ are possible.
For $$$\operatorname{mex}(M)$$$ to be equal to $$$0$$$, $$$\operatorname{mex}$$$ of every interval must be positive. So, every interval must include $$$0$$$. This is possible only when all intervals intersect at a common point — that is, there exists at least one point that lies within every interval. Then we place $$$0$$$ at some common point and fill the remaining permutation.
Otherwise, for $$$\operatorname{mex}(M)$$$ to be equal to $$$1$$$, $$$\operatorname{mex}$$$ of each interval must not be equal to $$$1$$$. To ensure this, we have to place $$$0$$$ and $$$1$$$ in such a way that if an interval includes $$$0$$$, it must also include $$$1$$$. This is possible if there exists a point that is not simultaneously the starting point of one interval and the ending point of another. In other words, we should be able to find a position that does not act as both a left and a right boundary. Then we place $$$0$$$ at such a point and $$$1$$$ adjacent to it.
Else, we place $$$[0,2,1]$$$ as a subsequence first and then build the remaining permutation.
Time Complexity: $$$O(n + m)$$$ per testcase.
#include <bits/stdc++.h>
using namespace std;
#define int long long
#define INF (int)1e18
void Solve()
{
int n, m; cin >> n >> m;
vector <int> l(m), r(m), f(n + 1), st(n + 1, 0), en(n + 1);
for (int i = 0; i < m; i++){
cin >> l[i] >> r[i];
st[l[i]] = 1;
en[r[i]] = 1;
for (int j = l[i]; j <= r[i]; j++){
f[j]++;
}
}
vector <int> ans(n + 1, -1);
auto fill = [&](){
vector <bool> used(n, false);
for (int i = 1; i <= n; i++) if (ans[i] != -1) used[ans[i]] = true;
int p = 0;
for (int i = 1; i <= n; i++){
if (ans[i] == -1){
while (used[p]) p++;
ans[i] = p;
used[p] = true;
}
}
for (int i = 1; i <= n; i++){
cout << ans[i] << " \n"[i == n];
}
};
for (int i = 1; i <= n; i++){
if (f[i] == m){
int ptr = 1;
ans[i] = 0;
fill();
return;
}
}
for (int i = 1; i < n; i++){
if (en[i] == 0){
ans[i] = 0;
ans[i + 1] = 1;
fill();
return;
}
if (st[i + 1] == 0){
ans[i] = 1;
ans[i + 1] = 0;
fill();
return;
}
}
assert(n >= 3);
ans[1] = 0;
ans[2] = 2;
ans[3] = 1;
fill();
}
int32_t main()
{
ios_base::sync_with_stdio(0);
cin.tie(0);
int t = 1;
cin >> t;
for(int i = 1; i <= t; i++)
{
Solve();
}
return 0;
}
Idea: wakanda-forever Preparation: wakanda-forever
We have to construct a tree with $$$n$$$ vertices such that $$$S = \sum_{{u, v} \in E} (u \cdot v)$$$ is a perfect square.
Instead of making it any random perfect square, let's try to make $$$S = (f(n))^2$$$ where $$$f(n)$$$ is an integer function of $$$n$$$.
Now, let's check if we can make $$$f(n) = n$$$. For $$$n = 5$$$, we can consider the following tree
where $$$S = 25 = (5)^2$$$.
Now that we know we have a tree $$$T$$$ with $$$n$$$ ($$$=5$$$) vertices having $$$S = n^2$$$. Using this, let's try to make a tree $$$T'$$$ with $$$n + 1$$$ vertices such that $$$S' = (n + 1)^2$$$. Note that $$$S' - S = 2n + 1$$$. So, while constructing $$$T'$$$, we have to add a new vertex $$$(n + 1)$$$ and also adjust this extra sum $$$2n + 1$$$.
We can achieve this in the following manner:
- add an edge between $$$1$$$ and $$$n + 1$$$,
- remove the edge between $$$1$$$ and $$$n$$$,
- add an edge between $$$2$$$ and $$$n$$$.
This analogy can be extended for all $$$n \ge 5$$$. Such trees have the following structure:
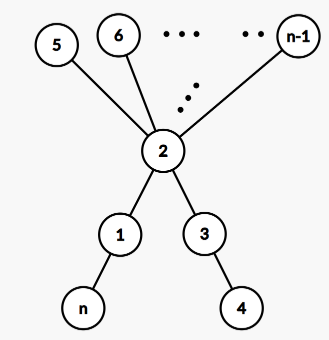
So, we can always make $$$S = n^2$$$ for all $$$n \ge 5$$$. For $$$n \lt 5$$$, we can just print sample outputs.
One can also assume $$$f(n) = n + 1$$$ and construct a similar solution with $$$S = (n + 1)^2$$$.
Time Complexity: $$$O(n)$$$ per testcase.
#include<bits/stdc++.h>
using namespace std;
int main(){
int t;
cin >> t;
while(t--){
int n;
cin >> n;
if(n == 2){
cout << -1 << '\n';
continue;
}
if(n == 3){
cout << "1 3\n2 3\n";
continue;
}
if(n == 4){
cout << "1 2\n3 1\n4 1\n";
continue;
}
cout << "1 2\n";
cout << "2 3\n";
cout << "3 4\n";
cout << "1 " << n << '\n';
for(int i = 5; i < n; i++) cout << 2 << ' ' << i << '\n';
}
}
Idea: wuhudsm Preparation: wuhudsm

When the value of $$$f$$$ is 1 for $$$[l_i, r_i]$$$, all numbers in $$$[l_i, r_i]$$$ are either $$$\leq x$$$ or $$$\geq x$$$.
We observe that for each interval, we need to divide the intervals into S-intervals (smaller) and B-intervals (bigger). S-intervals can only contain numbers $$$\leq x$$$, and B-intervals can only contain numbers $$$\geq x$$$.
Assuming we have fixed the S-intervals and B-intervals. For each index $$$i$$$, there are 4 types:
- Type 1: $$$i$$$ is covered only by S-intervals;
- Type 2: $$$i$$$ is covered only by B-intervals;
- Type 3: $$$i$$$ is covered by both S-intervals and B-intervals;
- Type 4: $$$i$$$ is covered by neither S-intervals nor B-intervals.
Let $$$cnt_s$$$ be the number of values $$$ \lt x$$$, and $$$cnt_b$$$ be the number of values $$$ \gt x$$$.
When there are no type 4 indices, we only need to check whether:
$$$cnt_s \leq$$$ (total number of type 1 indices)
$$$cnt_b \leq$$$ (total number of type 2 indices)
When type 4 indices exist, we only need to make a slight modification to the condition (this modification is left to the reader).
Consider a simpler case: all intervals are non-overlapping. In this case, the problem reduces to a classic knapsack problem, where each interval becomes an independent item. We consider extending the idea of DP to the original problem.
We find that intervals that are contained within others are useless and can be removed. Then, the intervals can be sorted by their left endpoints. This way, for $$$i \lt j$$$, we can ensure $$$l_i \lt l_j$$$ and $$$r_i \lt r_j$$$. Then, we perform DP based on the order of the intervals.
We define:
$$$dp[i][j][k = 0 \text{ or } 1]$$$: For the first $$$i$$$ intervals, the total number of type 1 indices is $$$j$$$, and the last interval is an S-interval ($$$k = 0$$$) or a B-interval ($$$k = 1$$$), the maximum total number of type 2 indices obtained.
Let $$$inslen[i]$$$ be the length of the intersection between the $$$i$$$-th interval and the $$$(i-1)$$$-th interval.
Transitions:
- $$$dp[i][j][0] = \max(dp[i-1][j - inslen[i]][0], dp[i-1][j - inslen[i]][1] - inslen[i])$$$
- $$$dp[i][j][1] = \max(dp[i-1][j][1] + inslen[i], dp[i-1][j + inslen[i]][1] + inslen[i])$$$
Note: For intervals $$$(i-2)$$$, $$$(i-1)$$$, $$$i$$$, if the type of interval $$$(i-1)$$$ is different from both $$$(i-2)$$$ and $$$i$$$, and $$$r[i-2] \geq l[i]$$$, some overlapping parts may be subtracted repeatedly. However, we find that this does not affect the final answer because it is not better than the answer when all three intervals are of the same type. Here, a common DP idea is applied: if "incorrect" states are recorded but they cannot be optimal, the DP transitions can remain unchanged (a similar idea is used in: https://mirror.codeforces.com/contest/1859/problem/E).
| State 1 | State 2 |
|---|---|
 ) ) |  |
| Some overlapping parts (in the middle) are subtracted repeatedly. | Better because the value range of the middle positions is strictly larger. |
Afterward, answering queries using the DP array is trivial. The time complexity is $$$O(n^2)$$$.
There is another DP approach. Let $$$b[i]$$$ be the smallest $$$j \leq i$$$ such that $$$j$$$ and $$$i$$$ are covered by the same interval. Then, if position $$$i$$$ is filled with a number $$$ \lt x$$$, we can deduce that all numbers in $$$a'[b[i], \ldots, i]$$$ must be $$$ \lt x$$$, and so on. This way, we can write a DP that transitions position by position, without pre-processing each interval.
For details, refer to Dominater069 's code.
#include <map>
#include <set>
#include <cmath>
#include <ctime>
#include <queue>
#include <stack>
#include <cstdio>
#include <cstdlib>
#include <vector>
#include <cstring>
#include <algorithm>
#include <iostream>
#include <bitset>
#include <unordered_map>
#define fastio ios_base::sync_with_stdio(false);cin.tie(0);cout.tie(0);
using namespace std;
typedef double db;
typedef long long ll;
typedef unsigned long long ull;
const int N=3010;
const int LOGN=28;
const ll TMD=0;
const ll INF=100000000;
int T,n,m;
int a[N],cnt[N],mxr[N];
int dp[N][N][2];
/*
* stuff you should look for
* [Before Submission]
* array bounds, initialization, int overflow, special cases (like n=1), typo
* [Still WA]
* check typo carefully
* casework mistake
* special bug
* stress test
*/
//--------------------------------------------------------------------------
struct seg
{
int l,r;
seg() {}
seg(int l,int r):l(l),r(r){}
int len()
{
return r-l+1;
}
};
seg getins(seg x,seg y)
{
if(x.l>y.l) swap(x,y);
if(x.r<y.l) return seg(INF,INF);
if(x.r<y.r) return seg(y.l,x.r);
else return seg(y.l,y.r);
}
//--------------------------------------------------------------------------
void init()
{
cin>>n>>m;
for(int i=0;i<=n;i++)
mxr[i]=0;
for(int i=1;i<=n;i++)
cin>>a[i];
for(int i=1;i<=m;i++)
{
int l,r;
cin>>l>>r;
mxr[l]=max(mxr[l],r);
}
for(int i=0;i<=n+4;i++)
for(int j=0;j<=n+4;j++)
dp[i][j][0]=dp[i][j][1]=-INF;
}
void solve()
{
int sz,cfree=0;
vector<int> tag(n+4);
vector<seg> vs;
for(int i=1;i<=n;i++)
{
if(!mxr[i]) continue;
if(vs.empty()||vs.back().r<mxr[i])
vs.push_back(seg(i,mxr[i]));
}
sz=vs.size();
dp[1][0][0]=vs[0].len();
dp[1][vs[0].len()][1]=0;
for(int i=2;i<=sz;i++)
{
seg cur=vs[i-1],ins=getins(vs[i-2],vs[i-1]);
int len_ins=(ins.l==INF?0:ins.len());
for(int j=0;j<=n;j++)
{
dp[i][j][0]=max(dp[i][j][0],dp[i-1][j][0]+cur.len()-len_ins);
if(j+len_ins<=n)
dp[i][j][0]=max(dp[i][j][0],dp[i-1][j+len_ins][1]+cur.len()-len_ins);
if(j-(cur.len()-len_ins)>=0)
{
dp[i][j][1]=max(dp[i][j][1],dp[i-1][j-(cur.len()-len_ins)][1]);
dp[i][j][1]=max(dp[i][j][1],dp[i-1][j-(cur.len()-len_ins)][0]-len_ins);
}
}
}
for(int i=0;i<vs.size();i++)
for(int j=vs[i].l;j<=vs[i].r;j++)
tag[j]=1;
for(int i=1;i<=n;i++)
if(!tag[i]) cfree++;
for(int i=1;i<=n;i++)
{
int s=0,b=0;
for(int j=1;j<=n;j++)
{
if(a[j]<i) s++;
else if(a[j]>i) b++;
}
int flg=0;
for(int j=0;j<=n;j++)
{
int need1=max(0,s-j),need2=max(0,b-max(dp[sz][j][0],dp[sz][j][1]));
flg|=(cfree>=need1+need2);
}
cout<<flg;
}
cout<<"\n";
}
//-------------------------------------------------------
void gen_data()
{
srand(time(NULL));
}
int bruteforce()
{
return 0;
}
//-------------------------------------------------------
int main()
{
fastio;
cin>>T;
while(T--)
{
init();
solve();
/*
//Stress Test
gen_data();
auto ans1=solve(),ans2=bruteforce();
if(ans1==ans2) printf("OK!\n");
else
{
//Output Data
}
*/
}
return 0;
}
#include <bits/stdc++.h>
using namespace std;
#define INF (int)1e9
mt19937_64 RNG(chrono::steady_clock::now().time_since_epoch().count());
void Solve()
{
// x <= min or x >= max
// min < x < max is bad
// => in range if both smaller and larger exists, cooked
// just spam smaller at one end, and larger at other end?
// i <-> j if there exists interval covering both
// if i <-> j, cannot have diff type on i and j
// dp[i][number of 0s] = max number of 1s, but also need to know what is the last 0 / 1 position
// we can extend last character always
// we can extend other character only after some gap
// prefmax?
int n, m; cin >> n >> m;
vector <int> a(n + 1), f(n + 1);
for (int i = 1; i <= n; i++){
cin >> a[i];
f[a[i]]++;
}
vector <int> b(n + 1), c(n + 1);
for (int i = 1; i <= n; i++){
b[i] = c[i] = i;
}
for (int i = 1; i <= m; i++){
int l, r; cin >> l >> r;
for (int j = l; j <= r; j++){
b[j] = min(b[j], l);
c[j] = max(c[j], r);
}
}
// vector dp(n + 1, vector(n + 1, vector <int>(2, -INF)));
// vector pref(n + 1, vector(n + 1, vector <int>(2, -INF)));
int dp[n + 1][n + 1][2];
int pref[n + 1][n + 1][2];
for (int i = 0; i <= n; i++){
for (int j = 0; j <= n; j++){
for (int k = 0; k < 2; k++){
dp[i][j][k] = -INF;
pref[i][j][k] = -INF;
}
}
}
dp[0][0][0] = dp[0][0][1] = 0;
pref[0][0][0] = pref[0][0][1] = 0;
for (int i = 1; i <= n; i++){
for (int x = 0; x <= n; x++){
for (int y = 0; y < 2; y++){
for (int z = 0; z < 2; z++){
if (y == z){
int px = x - (y == 0);
if (px >= 0){
dp[i][x][y] = max(dp[i][x][y], pref[i - 1][px][z] + (y == 1));
}
} else {
int px = x - (y == 0);
int lim = b[i] - 1;
if (px >= 0){
dp[i][x][y] = max(dp[i][x][y], pref[lim][px][z] + (y == 1));
}
}
}
pref[i][x][y] = max(pref[i - 1][x][y], dp[i][x][y]);
}
}
}
for (int i = 1; i <= n; i++){
int lower = 0;
int upper = 0;
for (int j = 1; j < i; j++) lower += f[j];
for (int j = i + 1; j <= n; j++) upper += f[j];
if (pref[n][lower][0] >= upper || pref[n][lower][1] >= upper){
cout << "1";
} else {
cout << "0";
}
}
cout << "\n";
}
int32_t main()
{
auto begin = std::chrono::high_resolution_clock::now();
ios_base::sync_with_stdio(0);
cin.tie(0);
int t = 1;
// freopen("in", "r", stdin);
// freopen("out", "w", stdout);
cin >> t;
for(int i = 1; i <= t; i++)
{
//cout << "Case #" << i << ": ";
Solve();
}
auto end = std::chrono::high_resolution_clock::now();
auto elapsed = std::chrono::duration_cast<std::chrono::nanoseconds>(end - begin);
cerr << "Time measured: " << elapsed.count() * 1e-9 << " seconds.\n";
return 0;
}

