


Meta HackerCup is unique, as it is the only place as far as I know that allows anyone to compete their AI models against top human competitors live! Without a lot of introductory blogs on how to get started competing in AI track, it becomes daunting to start & hence this blog. Received a dozen messages asking how we built a winning solution to last year's Meta Hacker Cup, will write separate post on that maybe.
A lot has changed from last year to this, thinking models are already very good at competitive programming model out of the box. This is good because it lowers bar of entry participation while pushing bar for creating a differentiated top solution.
Goal of contest is to build an automated system that generates solution to competitive programming problems WITHOUT any human intervention. That is you cannot nudge/hint your AI system leveraging your human intuitions.
Anatomy of a typical solution
A lot of the solutions/ideas can be dissected into three different parts that you can independently optimize:-
[A] Improve Zero-shot Code Generation
This includes elaborate improvised prompts (simple but effective, though it was more impactful for non-reasoning models but occasionally very helpful), or Reinforcement Fine-tuning of top models. RL Fine tuning is a winning idea, yields very strong improvements on base model but requires a budget and a coding dataset. Another idea is to search for similar problem or sub-ideas from dataset of past problems on web. Traditional way to do was RAG, but providing websearch agent/tool is simpler & promising alternative to this.
Last year, my team took efforts to build a private coding dataset called TJO-Bench of 1000 problems, a portion of which were original problems with few million code solutions. It's still unpublished and we couldn't fully leverage it to the best as we hit budget constraints due to lack of sponsorship. It was still instrumental north-star metric for us to run experiments on which ideas are working and which aren't as most online problems are already exposed to LLMs making it hard to truly test on unseen problems. Massively improved ELO of top non-reasoning models last year using this to become first div 1 Elo model.
Have a love/hate relation with RL since my research days but truth is any task where you can effectively create verifiable test environment, you can smoke that benchmark with RL. Coding & Math both fit very nicely in this context. Last year we had to write code, but thanks to OpenAI you can actually RL finetune top OpenAI models easily. For reasons I do not understand, this still less known but was one of best highlights from OpenAI's announcements last year. Top teams from OpenAI, AlphaCode in all likelihood do this step very well. Again google to learn more about Reinforcement learning, it is out of scope for this introductory blog.
Papers: https://arxiv.org/pdf/2502.06807 | https://www.science.org/doi/abs/10.1126/science.abq1158 | https://link.springer.com/chapter/10.1007/978-3-031-88714-7_21
blog if you are curious about RL in general.
[B] Scaling Generations
You can generate multiple solutions and pick the best to improve your odds to solve a problem. Original AlphaCode, OpenAI ioi-o1 approaches deployed this to hundreds of thousands generations. You are likely constrained by budget but it should be a good idea to generate 10s of solution to improve your odds. You can also provide basic meta data like providing compiler feedbacks, eliminating codes that do not pass sample test case, etc.
Papers: https://storage.googleapis.com/deepmind-media/AlphaCode2/AlphaCode2_Tech_Report.pdf
[C] Re-ranking top solution
You can use a test case generator (either deterministically or using LLMs) to create test data for problems and eliminate generations that failed, took too long to produce output, etc. to choose best generation or use LLM to pick the best. We implemented a novel idea to eliminate branching of thoughts using a RL tuned discriminator and packaged it as Guided Reasoning Chain Framework, and it yielded us massive increase in ELO of our model within our budget and allowed us to outperform top closed source models consistently over hard problems. I gave a talk on it last NeurIPS'24 but mostly removed majority of technical component as we were given very small time slot. Can write separate blog if enough people are interested to read.
Again, there are a lot more promising ideas to try out but these are few easier ones to get you started. Below is sample baseline idea for concrete understanding.
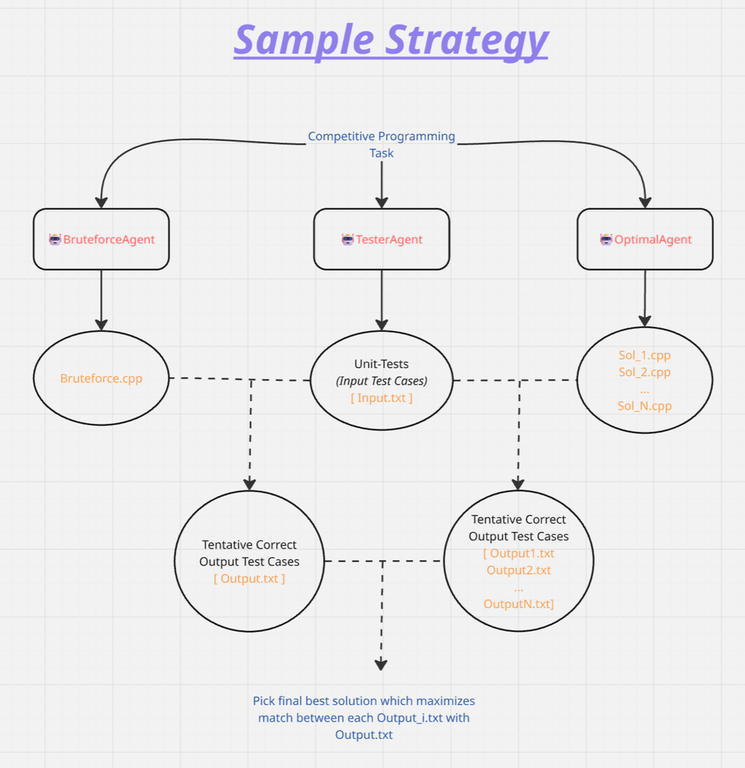
[Sample Strategy]
Build a simple multi-agent system: OptimalAgent (that is prompted to produce optimal solution), BruteforceAgent (that is prompted to produce bruteforce but correct solution redacting constraints) and TesterAgent (that is prompted to create simple low constrained unit-test cases for given problem). So for a given problem TesterAgent produces unit-test cases with low constraints and OptimalAgent produces say 20 code-solutions and BruteforceAgent produces say 1 solution-code. Run solution code generated by BruteforceAgent to produce output for unit-test cases and treat this as official correct output. Now run all 20 code-solutions generated by OptimalAgent on same unit-test and see which code matches the unit-test cases the most, pick that as the best solution.
This is a good baseline to get started with, and essentially exploits a very simple pattern that "usually" odds of generating a dumb bruteforce solution correctly is a lot higher than generating the optimal correct solution. Again you can handcraft a lot of hand-made heuristics/strategies and improve your scores, especially if you aren't applying RL-tuning.
....
Lastly there are a lot of interesting work in domain, if you find it interesting feel free to reach out to me for casual chat /discussions over DM. Best of luck if you are participating! I am open to adding a teammate for HackerCup, I will likely not be able to spend time and will be helpful if someone can help test out some of ideas.
Or wish to contribute to my side project FlamesBlue.com (lovable but more beautiful code gen for UI).


