


Thank you to everyone who attended this year's Harker Programming Invitational (HPI)! Novice and Advanced problems have been uploaded to the Gym for upsolving.
Harker
Pretty straightforward: most languages have a standard library function for finding a given substring in a string, so you can just use that.
def solution(s):
if "harker" in s:
return 1
return 0
T = int(input())
for _ in range(T):
s = input()
print(solution(s))
String Runs
Observe that when concatening strings $$$a$$$ and $$$b$$$, $$$|f(a + b)| = |f(a)| + |f(b)|$$$ unless the last character of $$$a$$$ equals the first character of $$$b$$$, in which case $$$|f(a + b)| = |f(a)| + |f(b)| - 1$$$. Therefore, for each string $$$w_i$$$, we only need to maintain three values: its first character, last character, and $$$|f(w_i)|$$$.
mod = int(1e9+7)
t = int(input())
for _ in range(t):
ans = []
n = int(input())
w = []
for i in range(n):
a = input().split()
if a[0] == "1":
s = a[1]
count = 1
for j in range(1, len(s)):
if s[j] != s[j-1]:
count += 1
count %= mod
w.append([count, s[0], s[-1]])
ans.append(count)
else:
for j in range(len(a)): a[j] = int(a[j])
cur = w[a[2]-1][0]
if a[1] == 1:
ans.append(w[a[2]-1][0])
else:
for j in range(3, len(a)):
cur += w[a[j]-1][0]
if w[a[j-1]-1][2] == w[a[j]-1][1]: cur -= 1
cur %= mod
ans.append(cur)
w.append([cur, w[a[2]-1][1], w[a[-1]-1][-1]])
print(' '.join(map(str, ans)))
Reverse Suffix
How can we get the first character of $$$a$$$ to match the first character of $$$b$$$ in 2 operations?
Can we apply this to the remaining indices?
If we want to make $$$a_1$$$ match $$$b_1$$$, we can use the following procedure:
- Find an $$$i$$$ such that $$$a_i = b_1$$$. After operating on index $$$i$$$, $$$a_n$$$ will equal $$$b_1$$$.
- Operate on index $$$1$$$, which reverses the entire string. Now, we have that $$$a_1 = b_1$$$.
Similar logic follows for the other indices. In particular, if we already have $$$a_j = b_j$$$ for all $$$j \lt i$$$ and we want to get $$$a_i = b_i$$$, we do the following:
- Find a $$$j \geq i$$$ such that $$$a_j = b_i$$$. Operate on index $$$j$$$.
- Operate on index $$$i$$$.
We perform these pairs of operations at most $$$n$$$ times, so we use at most $$$2n$$$ operations in total, which is sufficient to solve the problem. Note that this also means that the transformation is possible iff the multisets of characters in $$$a$$$ and $$$b$$$ are equal.
def solution(N, a, b):
sequences = []
for i in range(N):
found = -1
for j in range(i, N):
if a[j] == b[i]:
sequences.append(j + 1)
sequences.append(i + 1)
a = a[0:j] + "".join(reversed(a[j:]))
a = a[0:i] + "".join(reversed(a[i:]))
found = j
break
if found == -1:
return -1
return sequences
N = int(input())
a = input()
b = input()
ans = solution(N, a, b)
if ans == -1:
print(-1)
else:
l = len(ans)
print(l)
for i in range(l):
print(ans[i])
Regina's Task
With $$$b$$$ and $$$c$$$ fixed, how many $$$(a, d)$$$ pairs do you really have to check?
Let's fix $$$(b, c)$$$. If there are no options for $$$a$$$ or $$$d$$$, it's clearly impossible. Otherwise, if there are at least two options for either $$$a$$$ or $$$d$$$, it's always possible. If not, there is exactly one option for both $$$a$$$ and $$$d$$$, so we can just check this manually. Therefore, we do a constant amount of work for each $$$(b, c)$$$ pair, and the number of $$$(b, c)$$$ pairs is bounded by the number of edges. Therefore, the problem is solved in $$$\cal{O}(n + m)$$$.
Note: For ease of implementation, we can just find up to two candidates for both $$$a$$$ and $$$b$$$, then brute force all pairs.
import itertools
n, m = map(int, input().split())
g = [[] for _ in range(n + 1)]
edges = []
for _ in range(m):
u, v = map(int, input().split())
g[u].append(v)
g[v].append(u)
edges.append((u, v))
for (b, c) in edges:
opt_a, opt_d = [], []
for u in g[b]:
if len(opt_a) > 1: break
if u != c: opt_a.append(u)
for u in g[c]:
if len(opt_d) > 1: break
if u != b: opt_d.append(u)
for (a, d) in itertools.product(opt_a, opt_d):
if a != d:
print(a, b, c, d, sep="\n")
quit()
print(-1)
Tung Tung String
Consider splitting the process into two phases:
- Making the multiset of the first $$$n$$$ characters equal to the multiset of the last $$$n$$$ characters.
- Permuting the two halves to equal each other.
First, familiarize yourself with the concept of inversions, which are used to solve the following problem:
Given a permutation $$$p$$$ of length $$$n$$$, find the minimum number of adjacent swaps to sort it.
The important result from the above problem is that the minimum number of swaps is precisely the number of pairs of indices $$$(i, j)$$$ such that $$$i \lt j$$$ and $$$p_i \gt p_j$$$: in other words, the number of indices whose paths must "cross".
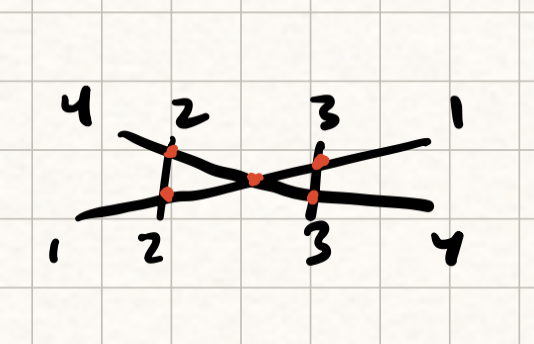
Here, the five inversions of $$$p = [4, 2, 3, 1]$$$ are marked in red.
Now, consider a relaxation of the above problem in which elements of $$$p$$$ are allowed to be equal, and instead of sorting we want to transform $$$p$$$ to some target array $$$t$$$. In this case, the ending position of each element is not necessarily fixed, therefore we have some choices to make about which elements move where. For instance, if $$$1$$$ occurs at indices $$$2, 3, 4$$$ in $$$p$$$ and at indices $$$1, 4, 5$$$ in $$$t$$$, we could:
- Send index $$$2$$$ to index $$$1$$$, index $$$3$$$ to index $$$4$$$, and index $$$4$$$ to index $$$5$$$.
- Send index $$$2$$$ to index $$$4$$$, index $$$3$$$ to index $$$5$$$, and index $$$4$$$ to index $$$1$$$.
- etc...

