


Here is the contest link.
A. Escaping Prison
Idea and preparation: nahubn1123
Since we can only utilize either the length or width of all the blankets, the best choice for creating the longest possible rope is to first utilize all the blankets and use the longest side (length or width) of each blanket.
- Time Complexity: $$$O(n)$$$
- Space Complexity: $$$O(1)$$$
import sys
input = lambda : sys.stdin.readline().strip()
for _ in range(int(input())):
n, h = map(int, input().split())
rope = 0
for i in range(n):
l, w = map(int, input().split())
rope += max(l, w)
if rope >= h:
print('YES')
else:
print('NO')
B. Empress Taytu and The Water Source
Idea and preparation: birsnot
Output binary search.
The key insight is that if we have a wagon size greater than or equal to $$$\max(d_1, d_2, \dots, d_n)$$$, we only need to go once for every village. Hence, the sum of all $$$a_i$$$ is the minimum achievable time to deliver the water with any size.
If $$$\sum_{i=1}^{n} a_i$$$ is already greater than $$$k$$$, we can't make Empress Taytu happy with any size. If not, starting from 1 (left) up to $$$\max(d_1, d_2, \dots, d_n)$$$ (right), we can perform a binary search by checking whether it's achievable with a given size within $$$k$$$ hours.
For a single village, we can calculate the number of trips the wagon has to make by ceil dividing its demand by the wagon size. Then, we can calculate the total time needed for one village by multiplying the number of trips with the time it takes for one trip ($$$a_i$$$). After adding the total time for all villages, we will check if it is less than or equal to $$$k$$$. Overall, the complexity of the checker is $$$O(n)$$$.
The complexity of the binary search algorithm used in this solution is $$$O(\log(\max(d_1, d_2, \dots, d_n)))$$$. Since we need to check for each possible size of the wagon, the overall complexity of the algorithm is $$$O(n \log m)$$$, where $$$m = \max(d_1, d_2, \dots, d_n)$$$.
- Space Complexity: $$$O(1)$$$
from math import ceil
from sys import stdin
def input(): return stdin.readline().strip()
T = int(input())
for _ in range(T):
N, K = map(int, input().split())
d = list(map(int, input().split()))
a = list(map(int, input().split()))
if sum(a) > K:
print(-1)
continue
def checker(size):
time = 0
for i in range(N):
time += ceil(d[i]/size)*a[i]
return time <= K
left = 1
right = max(d)
while left <= right:
mid = left + (right - left)//2
if checker(mid):
right = mid - 1
else:
left = mid + 1
print(left)
C. Ras Alula and The Decrypted Messages
Idea and preparation: birsnot
Observation: After an increment operation, there is always a corresponding decrement operation.
Let's represent the characters with numerical values, such as their ASCII values. During an increment operation, the ASCII value of that character increases by $$$1$$$, and during a decrement operation, it decreases by $$$1$$$. Importantly, after an increment operation, the total sum of ASCII values of the word decreases by $$$1$$$, and after a decrement operation, the total sum increases by $$$1$$$. However, since one operation combines both increment and decrement, the total ASCII sum remains unchanged.
Therefore, to decrypt the message, we only need to check if there exists a substring with a size equal to the size of the sensitive word (let's denote it as $$$m$$$) and the sum of ASCII values of its characters is equal to that of the sensitive word. For this, we can employ a fixed-size sliding window approach with size $$$m$$$.
- Time Complexity: $$$O(n)$$$ where $$$n$$$ is the size of the decrypted message.
- Space Complexity: $$$O(1)$$$
from sys import stdin
def input(): return stdin.readline().strip()
T = int(input())
for _ in range(T):
N, M = map(int, input().split())
s = input()
w = input()
target = 0
window_sum = 0
for i in range(M):
target += ord(w[i])
window_sum += ord(s[i])
found = False
for i in range(M, N):
if window_sum == target:
found = True
break
window_sum += ord(s[i])
window_sum -= ord(s[i - M])
if window_sum == target or found:
print("YES")
else:
print("NO")
D. Final Strength
Idea and preparation: Tikursew
In the first round, each group consists of two teams. Then, in the second round, every two consecutive groups are merged, and so on. This problem resembles a typical divide and conquer approach. Now, the question is, given the left group and the right group, how can we merge them and calculate the number of wins for every team efficiently?
One possible solution is to perform a binary search on the right team for each team in the left group, determining the number of players with strength strictly less than the current player's strength. Repeat this process for all players in the right group. Then, combine the two arrays using two pointers. The time complexity for this solution is $$$O(2^n * log^2(2^n))$$$, where $$$2^n$$$ is the size of the array.
Another approach is to use two pointers to calculate the wins. After calculating and updating both arrays, we can merge them together. This approach has a time complexity of $$$O(2^n*log(2^n)))$$$.
- Space Complexity: $$$O(2^n)$$$
def mergeSort(arr,l,r):
if l == r:
return
# get the mid point of the current array and merge sort it
mid = (l + r)//2
mergeSort(arr,l,mid)
mergeSort(arr,mid + 1, r)
# merge the two halves after sorting them and calculating the answer
merge(arr,l,mid,r)
def merge(arr,l,mid, r):
# wins array to hold the number of wins each team have
wins = [0]*(r - l + 1)
# array to hold merged list
merged = []
# calculate the wins for the first group
ptr = mid + 1
# for every element of the first group
for i in range(l,mid + 1):
# move the second groups point to an element which is greater or equal to it
while ptr <= r and arr[ptr][1] < arr[i][1]:
ptr += 1
# the total numbe of wins for the current element
#is the nubmer of element in the second group
#that is lower than it
wins[i - l] = ptr - (mid + 1)
# same thing for the second group
ptr = l
for i in range(mid + 1,r+1):
while ptr <= mid and arr[ptr][1] < arr[i][1]:
ptr += 1
wins[i - l] = ptr - l
# merge the two groups based on the new value
pt1 = l
pt2 = mid + 1
while pt1 <= mid or pt2 <= r:
if (pt2 > r) or (pt1 <= mid and arr[pt1][1] + wins[pt1 - l] < arr[pt2][1] + wins[pt2 - l]):
arr[pt1][1] += wins[pt1 - l]
merged.append(arr[pt1])
pt1 += 1
else:
arr[pt2][1] += wins[pt2 - l]
merged.append(arr[pt2])
pt2 += 1
arr[l:r + 1] = merged
def solve():
n = int(input())
arr = list(map(int, input().split()))
arr = [[i,j] for i,j in enumerate(arr)]
mergeSort(arr,0,2**n - 1)
ans = [i[1] for i in sorted(arr,key = lambda x: x[0])]
print(*ans)
t = int(input())
for _ in range(t):
solve()
E. Machine Testing
Idea and preparation: nahubn1123
Find the time each gun explodes then you can take the maximum one.
Use monotonic stack to track the damage a gun receives for a gun behind him.
To determine the time it takes for each gun to explode, we can employ a monotonic stack approach. Starting from the first gun, which we know for sure will explode at infinity, we can represent each gun as a tuple $$$(t_i, p_i)$$$, where $$$t_i$$$ is the life of the $$$i$$$-th gun and $$$p_i$$$ is its power. These tuples are then pushed onto the stack.
For each gun $$$i$$$, we can understand that it receives a hit from the last gun on the stack. The damage it receives can be calculated as stack[-1][-1] * (stack[-1][0] - d), where stack[-1][0] and stack[-1][-1] represent the life and power of the gun at the end of the stack, respectively. Here, $$$d$$$ represents the duration of gun $$$i$$$ before it encounters the gun at the end of the stack. If the gun at the end of the stack cannot reduce the health of gun $$$i$$$ to zero, we decrement the received damage with the gun's health and pop from the stack.
- Time Complexity: $$$O(n)$$$
- Space Complexity: $$$O(n)$$$
import sys
from math import ceil, inf
input = lambda : sys.stdin.readline().strip()
for t in range(int(input())):
n = int(input())
health = list(map(int, input().split()))
power = list(map(int, input().split()))
stack = [(inf, power[0])]
ans = 0
for i in range(1, n):
duration = 0
while health[i] - (stack[-1][0] - duration)*stack[-1][-1] > 0:
t, p = stack.pop()
health[i] -= (t-duration)*p
duration += (t-duration)
duration += ceil(health[i]/stack[-1][-1])
stack.append((duration, power[i]))
ans = max(ans, duration)
print(ans)
F. The Triumphant Empress
Idea and preparation: Ermi_007
What if we have every sorted prefix.
Do we need every sorted prefix? and is there a fast way to compute it?
If we had every sorted prefix of the array, answering queries would be trivial, we could simply use binary search to count elements less than $$$X$$$ in the first $$$K$$$ elements. However, storing all sorted prefixes would require:
- $$$O(n² log n)$$$ time to preprocess
- $$$O(n²)$$$ space to store
This is clearly very inefficient.
An observation that will help us is that any positive integer $$$K$$$ can be represented as a sum of distinct powers of 2. This is essentially the binary representation of $$$K$$$. For example:
- $$$K = 5 = 4 + 1 (2² + 2⁰)$$$
- $$$K = 7 = 4 + 2 + 1 (2² + 2¹ + 2⁰)$$$
- $$$K = 10 = 8 + 2 (2³ + 2¹)$$$
This property allows us to decompose any prefix of length $$$K$$$ into $$$log K$$$ segments, each being a power of 2 in length,So we don't need every sorted prefix. Okay so now we only need to make these segments sorted.
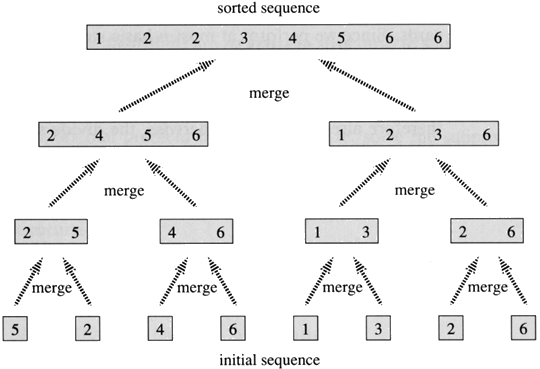
If we can save this structure we will be able to calculate on each segment that makes up $$$K$$$, how many elements are less than $$$X$$$.
Complexity Analysis
Preprocessing
- Time: $$$O(N log N)$$$ — Each element appears in $$$O(log N)$$$ sorted segments
- Space: $$$O(N log N)$$$ — Storing all sorted segments
Queries
- Time: $$$O(log² N)$$$ per query ($$$O(log N)$$$ segments × $$$O(log N)$$$ binary search)
- Total for Q queries: $$$O(Q log² N)$$$
from bisect import bisect_left
for _ in range(int(input())):
n, Q = map(int, input().split())
soldiers = list(map(int, input().split()))
'''
calculate size as the smallest power of 2
greater than or equal to n
'''
size = 1
level = 0
while size * 2 < n:
size *= 2
level += 1
size *= 2
level += 2
# lets extend the given array's size to a power of 2
while len(soldiers) < size:
soldiers.append(float('inf'))
n = len(soldiers) # Update n
tree = [[] for _ in range(level)]
tree[0].append(sorted(soldiers)) # the first leve(0) is the whole sorted array
def merge(left, right):
# standard merge of two sorted lists
# we can do other things here if needed :)
return sorted(left + right)
def mergeSort(left, right, arr, level):
if left == right:
return [arr[left]]
mid = (left + right) // 2
left_half = mergeSort(left, mid, arr, level + 1)
right_half = mergeSort(mid + 1, right, arr, level + 1)
# save each sorted segment at its corresponding level
tree[level].append(left_half)
tree[level].append(right_half)
return merge(left_half, right_half)
'''
query function takes:
k - number of elements to consider
level - current level in the tree
node - current node/segment index
x - warriors strength value
Each level contains segments of length 2^level
We recursively find which segments make up the prefix of length k
For each segment, we use binary search to count elements < x
'''
def query(k, level, node, x):
# base case: no more elements or exceeded tree levels
if level >= len(tree) or not k:
return 0
# calculate segment length at current level
length = n
for _ in range(level):
length //= 2
if length <= k:
#count elements < x in this segment
lesser_elements = bisect_left(tree[level][node-1], x)
#recurse for remaining elements
return lesser_elements + query(k - length, level + 1, (node*2) + 1, x)
# if segment is larger than needed, go deeper
return query(k, level + 1, 2*node - 1, x)
# build the merge sort tree starting from level 1
mergeSort(0, n-1, soldiers, 1)
#Finally now we can process queries
for _ in range(Q):
k, x = map(int, input().split())
print(query(k, 0, 1, x))
For each query, we need to count how many elements in a prefix A[0..K-1] are strictly less than $$$X$$$. Naively, for each query, iterating through the prefix would cost $$$O(K)$$$ per query, which is too slow when $$$Q$$$ and $$$K$$$ are large. We need something faster, ideally logarithmic time per query.
A powerful way to handle such queries efficiently is to use divide and conquer, or specifically merge sort logic. We are going to apply a modified merge sort on the array. The main idea is to group queries based on their indices (that is, the prefix limit $$$K$$$). For each index $$$i$$$, collect all the different values $$$X$$$ that will be queried against the prefix up to $$$i$$$.
A standard merge sort is used to both, sort the array, and merge and count how many left-side elements are less than $$$X$$$ for every query on the right side. This allows for efficiently processing all queries offline. We can store the answer for every possible ($$$K$$$, $$$X$$$) pairs. And then we will iterate through all the queries and then print the answer.
For the time complexity of this approach the operations is similar to regular merge sort, in the sense that we have $$$O(\log N)$$$ layers, and on each layer we will have $$$O(N + Q)$$$ operations per layer. Therefore, the overall time complexity will be $$$O((N + Q) \log N)$$$.
For the space complexity, since merge sort is not in-place, we will have $$$O(N)$$$ memory consumption for sorting. And there is also $$$O(Q)$$$ memory for storing the queries, and the dictionary that stores the $$$X$$$s. Therefore, the overall space complexity will be $$$O(N + Q)$$$.
from collections import Counter
import sys
def input():
return sys.stdin.readline().strip()
# Utility to read list of integers
def readList():
return list(map(int, input().split()))
def solve():
array_length, query_count = readList()
array = readList()
queries = []
for _ in range(query_count):
index, value = readList()
queries.append((index - 1, value)) # 0-based indexing
# Track required query values per index
query_values_at_index = [set() for _ in range(array_length)]
for index, value in queries:
query_values_at_index[index].add(value)
# Sort required values for each index for binary search/merge purposes
for index in range(array_length):
query_values_at_index[index] = sorted(query_values_at_index[index])
# Dictionary to store the result of each (index, value) query
query_results = Counter()
def merge_sort_count(start, end):
"""
Recursive divide and conquer function that returns:
- a sorted list of elements in array[start:end+1]
- a sorted list of (value, index) query pairs for that segment
Also populates query_results with counts of elements less than 'value' to the left of 'index'.
"""
if start == end:
current_elements = [array[start]]
current_queries = [(value, start) for value in query_values_at_index[start]]
for value, idx in current_queries:
if array[start] < value:
query_results[(idx, value)] += 1
return current_elements, current_queries
mid = (start + end) // 2
left_elements, left_queries = merge_sort_count(start, mid)
right_elements, right_queries = merge_sort_count(mid + 1, end)
merged_elements = []
merged_queries = []
# Count how many left_elements are < each right query's value
i = j = count = 0
while i < len(left_elements) and j < len(right_queries):
value, idx = right_queries[j]
if left_elements[i] < value:
count += 1
i += 1
else:
query_results[(idx, value)] += count
j += 1
# For remaining right queries
while j < len(right_queries):
value, idx = right_queries[j]
query_results[(idx, value)] += count
j += 1
# Merge the sorted arrays
i = j = 0
while i < len(left_elements) and j < len(right_elements):
if left_elements[i] <= right_elements[j]:
merged_elements.append(left_elements[i])
i += 1
else:
merged_elements.append(right_elements[j])
j += 1
merged_elements.extend(left_elements[i:])
merged_elements.extend(right_elements[j:])
# Merge the sorted query lists
i = j = 0
while i < len(left_queries) and j < len(right_queries):
if left_queries[i] <= right_queries[j]:
merged_queries.append(left_queries[i])
i += 1
else:
merged_queries.append(right_queries[j])
j += 1
merged_queries.extend(left_queries[i:])
merged_queries.extend(right_queries[j:])
return merged_elements, merged_queries
# Run the divide and conquer process
merge_sort_count(0, array_length - 1)
# Print the answers in the order of input queries
for index, value in queries:
print(query_results[(index, value)])
t = int(input())
for _ in range(t):
solve()

