


It seems that some parts of Latex refuse to render. I will update them later
Problem A. Sherlock and Parentheses
Category: Ad-Hoc, Math, Greedy
Let's define n = min(L,R). Then the claim is that the sequence ()()...() consisting of n pairs of "()" will give us the maximum answer n*(n+1) / 2
Proof:
Let's look at some sequence T = (S) where S is also a balanced parenthesis sequence of length m. Let's denote by X(S), the number of sub-strings of S that are also balanced and by X'(S) the number of balanced parenthesis sub-strings that include the first and last characters of S (In fact this will be just 1). Then X(T) = X(S) + X'(S).
It should be easy to prove that X'(S) <= X(S) (simply because X'(S) is a constrained version of X(S))
If we rearrange our sequence T to make another sequence T' = "S()", then X(T') >= X(S) + X'(S). The greater than equal to sign comes because we might have balanced sub-strings consisting of a suffix of S and the final pair of brackets.
Thus, we have that X(T') >= X(S) + X'(S) = X(T). Thus by rearranging the sequence in this manner, we will never perform worse. If we keep applying this operation on each string, we will finally end up with a sequence of the form "()()...()" possibly followed by non-zero number of "(" or ")"
Problem B. Sherlock and Watson Gym Secrets
Category: Math, DP
Let's look at all valid pairs (i,j) in which i is fixed. Then, if i^a mod k = r then j^b mod k = (k-r) mod k.
There are only k possible values of the remainder after division. Since k is small enough, if we can quickly determine how many numbers i exist such that i^a mod k = r and j^b mod k = (k-r) mod k then we can simply multiply these quantities and get our answer. Thus the reduced problem statement is —
Find the number of numbers i <= N such that i ^ a mod k = r for all r = 0 to k-1.
Let's denote by dp1[r] = number of i <= N such that i ^ a mod k = r. We will try to compute dp1 from r = 0 to k-1 in time O(K log a)
Let's make another observation —
i ^ a mod k = (i + k) ^ a mod k = (i + 2k) ^ a mod k = (i + x*k) ^ a mod k.
Proof:
(i + x*k) ^ a mod k = (i mod k + (x * k) mod k) ^ a mod k
= (i + 0) ^ a mod k = i ^ a mod k
Now i + x * k <= n. This implies that x <= (n-i) / k.
Thus if we know that for some i <= K, i ^ a mod k is r then there are x + 1 such numbers which also have the same remainder.
This gives us a quick way to compute dp1
for i = 1 to k:
r = pow(i, a) mod k
x = (n-i) / k
dp1[r] += x + 1Similarly, we can compute dp2[r] which denotes the number j <= N such that j ^ b mod k = r
Now our final answer is the sum of dp1[i] * dp2[(k-i) mod k] for i = 0 to k.
ans = 0
for i = 0 to k-1:
ans += dp1[i] * dp2[(k-i)%k]But we need to exclude the cases when i = j.
To handle this we can simply iterate one last time from i = 1 to k and find all the cases when (i ^ a + i ^ b) mod k = 0. and subtract (1 + (n-i)/k) from the answer for all such i
for i = 1 to k
if pow(i,a) + pow(i,b) mod k == 0:
ans -= ((n-i)/k + 1)Problem C. Watson and Intervals
Category: Greedy, Line Sweep
Refer to this comment
Problem D. Sherlock and Permutation Sorting
Category: DP, Math
Since N is too large to enumerate all permutations, we need to come up with a clever way to compute the final answer. There are several hints in the problem that we can pick up on. Firstly there can be at most N distinct values of f(p). But there are N! different permutations. This means that a lot of permutations are going to have the same value of f(p). Thus it seems reasonable to try and find some way to compute the number of permutations which have the same value f(p) seems more reasonable than enumerating the permutations.
Our second hint comes from the statement "all elements in a chunk are smaller than all elements in any later chunk". Trying some permutations out on pen and paper gives us the following claim -
If there is a valid way to divide a permutation into chunks, then there must exists a right most chunk. Moreover, if the size of the right most chunk is X, then it must consist of the largest X elements of the permutation.
The first part of the above statement is trivial. The second part can be proven by way of contradiction by trying to partition the permutation in a way where at least one element in the rightmost chunk is not one of the largest X elements. Let this smallest element in the right most chunk be i. If i is in the right most chunk, then one of the largest X elements j is to the left. Since j > i, this means that this is not a valid way to partition the permutation into chunks.
But we don't just want to partition the permutation into chunks but we want the maximum number of chunks. To take this into consideration, let's define the notion of a primitive right most chunk. The right most chunk of size X of some partition of the permutation is said to be primitive, if it does not contain a proper suffix of length Y < X which also consists of the Y largest elements i.e. if any suffix of a right most chunk C is not a primitive chunk, then C is said to be a primitive chunk.
Why have we defined such a complex notation? This is motivated by the fact that if a right most chunk contains a suffix of size Y which contains the largest Y elements of the permutation, then we can split the current chunks into two chunks of size X - Y and Y such that this will also be a valid partition and the number of chunks in our partition will increase by 1.
Thus we have another lemma —
If a permutation p is divided into f(p) number of chunks, then the right most chunk in this partition must necessarily be a primitive chunk!
Now, let's use the tools at hand to make our third observation to crack this problem.
Let's assume that the size of the primitive chunk in a maximum partition of a permutation p of size N has size X. We know that this consists of the largest X elements of the permutation of size N. We should notice that all the chunks on the left are just the maximum way to partition a permutation p' where p' is the suffix of length N - X of the permutation p.
So what does this mean? We have a recursive way to partition a given permutation into the maximum number of chunks! Start from the right and find the right most index i such that p[i ... N] contains the largest N-i+1 elements of the permutation. This must necessarily be the primitive chunk of the permutation p. Thus we can recursively compute the chunks for p[1 ... i-1] and append p[i ... N] to get the maximum way to partition p! Great, but we can make an even more powerful observation. You don't necessarily have to append p[i ... N] to the chunks of p[1 ... i-1]. In fact any primitive chunk of size N-i+1 can be appended to p[1 ... i-1] and the value of f(p) for each of these permutations will be the same!
Let's have a look at these statements using some more formal notation.
Define prim(n) to be the number of primitive chunks of size n. Observe that value of prim(n) is independent of the actual values of set but only depends on the size of the set i.e. number of primitive chunks consisting of {1,2,3} is the same as number of primitive chunks consisting of {100, 101, 102}.
Define sum_f(n) to be the sum of f(p) of all permutations p of size n. Using our observations from above, we can create a recurrence relation for sum_f(n) in terms of prim()
sum_f(n) = (sum_f(i) + factorial(i)) * prim(n-i) for all i from 0 to n
How did we get this recurrence? Let the size of the primitive chunk in optimal partition be n-i. There are prim(n-i) ways to choose such a primitive chunk consisting of the n-i largest elements. If we choose any permutation p' of size i, it can be a prefix of permutations with primitive chunks of size n-i. For each such permutation p', we have the relation f(p) = f(p') + 1.
Thus sum_f(n) += (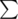 (over all p' of size size i) f(p') + 1) * prim(n-i)
(over all p' of size size i) f(p') + 1) * prim(n-i)
There are factorial(i) number of permutations of size i and each of them can be append with one of prim(n-i) primitive chunks. Thus sum over all p' f(p') + 1 = sum_f(i) + factorial(i)
If we can compute prim(n) for all possible values of n, we can compute the sum of all values of f(p) for permutations of size n in O(n^2) time.
Prim(n) can be computed by the following recurrence relation
Prim(0) = 0 Prim(n) = factorial(n) — (i = 0 to n) factorial(i) * Prim(n-i)
This also takes O(n^2) time. But the question is asking us to compute the sum of the squares of all f(p)! We will take care of this by using some math to build a third and final recurrence :)
Now it is time to make the final observation and make a final notation.
Let sqrsum(n) denote the sum of squares of f(p) over all permutations p of size n
We know that f(p) = f(p') + 1 where p' is the prefix of p after the primitive chunk of size (n-i) is removed. Squaring both sides, we get
f(p)^2 = f(p')^2 + 2 * f(p') + 1
If we fix the primitive chunk C of the permutation p and take the sum of over all valid p', we would get
sum (over all p with prim chunk C) f(p)^2 = sqrsum(i) + 2 * sum_f(i) + factorial(i)
For any primitive chunk of size n-i, the RHS of the above equation remains that sum.
Thus
sum (over all p with prim chunk size n-i) f(p)^2 = (sqrsum(i) + 2 * sum_f(i) + factorial(i)) * prim(n-i)
If we take the sum over all possible primitive chunk sizes we will get sqrsum(n)
Thus sqrsum(n) = sum (over all i)(sqrsum(i) + 2 * sum_f(i) + factorial(i)) * prim(n-i)
Thus we have our final recurrence relation.
This can also be computed in O(n^2).
Thus our final answer is sqrsum(N).


