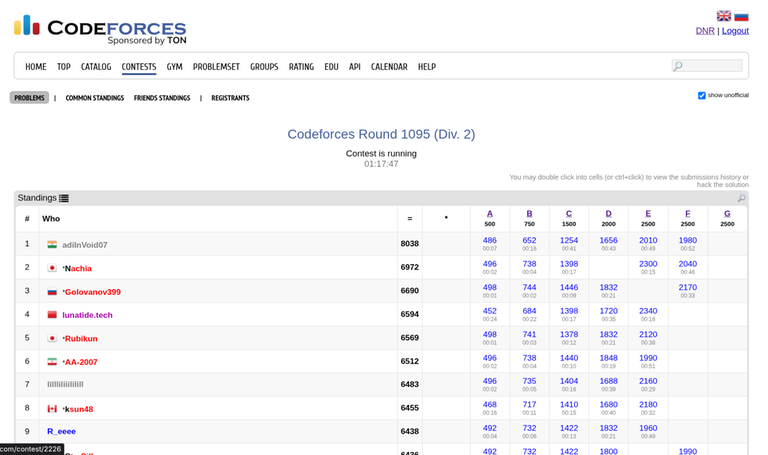
AI solved A, B, C, D, E, F, and H in this round (reference: bugfeature). A cheater that gave the problem statements to GPT quickly would have placed at rank <= 4 in this round. I'm not sure about G, as most cheaters had already been banned by the time I checked, but looking at JohnNash01, it seems plausible that AI might have also solved it (which would imply the first(?) div-1 AK by AI, and also rank 1 for a fast enough cheater).
Tourist has now been defeated by AI cheaters in the two most recent div-1s. GPT has turned out to be the real conqueror_of_tourist we made along the way.
In an entirely unrelated turn of events, Panda_V is the new Indian GOAT, swatting aside Dominater069. We're being ushered into an unprecedented golden age of Indian competitive programming.
I think copes like "just get to 2100, there aren't any cheaters in div-1" are clearly invalid now. Ratings don't have much value any more, and will probably lose the little they still do in the coming months.
Edit: RainRecall has confirmed that AI did indeed solve G, making this the first div-1 AK by a publicly accessible (at least for those who can pay for it) AI model.
Edit 2: Codeforces Round 1095 (Div. 2) has also been AKed by AI (note that several LGMs and IGMs couldn't do the same). Let's see if this AK streak continues for a long time.
ICPC Asia-West Finals took place on 8 March 2026, and while official confirmation will take some time, my team will probably qualify to WF (based on the ranklist, previous year trends, and unofficial hearsay from the organizers).
After the contest, I went back to my home (instead of my uni) for a week, where I only had access to a Macbook. I couldn't play games or do any of the work I usually do on my x86 PC, so I chose to write several thousand words on my experience with ICPC, which included a summary of this contest. The stuff that precedes the summary (prior experience with ICPC, anecdotes with my teammates, etc.) is way too long and personal, so I'm omitting it over here. As such, I'll offer a brief overview of my prior experience:
I'm a filthy tryhard that has been to ICPC regionals 7 times, and AWF thrice.
Excluding this contest, my team has always performed really badly.
The last two times we went to AWF, I was in a team with (redacted names) WellGroomedHair and GeometryDashAddict.
This year, I was in a team with GeometryDashAddict and GrokSponsoredPS5.
The AWF contest is hosted on CodeChef, and there are therefore several references to it.
The blog is REALLY long, because I was trying to preserve everything that happened in my private writing. A lot of the technical details are also overlong and not rigorous for the same reason. You can skip them. Proceed with the knowledge that you might be wasting your time.
It is that time of the year! Many people are trying to summarize all the things that happened during the year. And since I love to hate people, I want to make a vote for the most annoying person on CF in 2025.
I know that I've been in the top contributors list for too long, so to vote for a person you should downvote the comment with this person's handle(s). Due to the nature of voting through comments on CF, you can vote for many people, and you can also upvote comments if you find given person's comments helpful/funny/positive.
If you care for your contribution but want to nominate a candidate, you can DM me their handle(s), then I will write a comment to vote. Note that I will write that it was you who nominated this person, so it saves your contribution but not relationships with the nominee. I will ignore messages from people without rating.
If you hate someone already nominated so much that you want them to know, you can also PM me so I'll add you to list of people who nominated given person.
Obviously, you can nominate someone with your own comment, but watch out for downvotes. Also, you can try to increase your contribution by nominating some very nice people unanimously loved by community. In that case I will nominate you right after that.
I know that I'm an obvious candidate, especially after writing this post. But I don't annoy me, so go on and show me your hatred :)
You’re given a set of jobs and integers $$$x$$$ and $$$y$$$. Each job is represented by a time interval $$$[l, r]$$$ (integral endpoints, $$$0 \leq l \lt r \leq y$$$). The goal is to find an assignment of jobs to machines (assume that we have an infinite number of identical machines) which minimizes the number of machines used, while also satisfying the following:
Each job is assigned to some machine.
No two jobs assigned to the same machine intersect (but their endpoints can touch, so $$$[a, b]$$$ and $$$[b, c]$$$ can be assigned to the same machine).
Every used machine has some contiguous “break interval” of length $$$x$$$, which doesn’t intersect with any job assigned to that machine (once again, endpoints can touch). In other words, there is some contiguous time period of length $$$x$$$ where no job is being executed on it.
I’m pretty sure there isn’t an exact solution in P, so I’m looking for decent approximation algorithms.
I could only think of a simple approximation algorithm with a bad approximation factor that's heavily dependent on the input data (although I'm pretty sure I could make a cursed div-2 D out of it).
The idea
Let $$$s$$$ be the maximum length of a job interval.
The algorithm has an approximation factor of about $$$(1 + \frac{x + 2 \cdot s}{y})$$$ (so it’s only helpful when we have $$$\max(x, s) \lll y$$$), and it works in the following manner:
Let’s first find an optimal assignment for $$$x=0$$$ (this is the standard machine assignment problem and can be solved in sub-quadratic time using a simple greedy algorithm).
You then run the following procedure:
m = number of machines required by optimal assignment for x = 0
v[m] = vector of assigned jobs for x = 0 (v[i] stores all intervals assigned to machine i)
i = 1 #index of the old machine we’re currently processing
p = 0 #pointer that we will use as the start of the break on the next machine
g = m #number of machines used till now
while i <= m:
if p == 0:
g = g + 1
we rent a new machine indexed g, initially assigned no jobs
if some there exists some job [l, r] in v[i] such that l <= p < r, set p = r
let J be the set of jobs in v[i] which intersect with [p, p + x]
let Q be max(p + x, maximum rightbound in J (0 if J is empty))
if y - Q < x:
we assign a break interval [p, p + x] on machine g
p = 0
else
on machine i, reserve interval [p, p + x] for a break
move all intervals in J from machine i to machine g
p = Q
i = i + 1
finally, if we havent assigned a break interval on the last machine, its alright as its guaranteed that [y - x, y] will be free on this machine
the required number of machines is g
That would be kind of awkward to explain in plain english (and there might be a few off-by-oneish bugs in the pseudo code, ignore them), so I hope the idea is self-evident. We're creating new machines so that we can freely assign breaks to the old ones in a cyclical manner, and are then able to transfer the displaced jobs to the new ones (while of course ensuring that the new machines also get break intervals).
What is the approximation factor? Notice that $$$p$$$ is only set back to $$$0$$$ after at least $$$\lfloor \frac{y}{x + 2 \cdot s} \rfloor - 1$$$ increments to $$$i$$$. In other words, we create a new machine for every $$$\lfloor \frac{y}{x + 2 \cdot s} \rfloor - 1$$$ old ones. So we use at most $$$\approx m \cdot (1 + \frac{1}{\lfloor \frac{y}{x + 2 \cdot s} \rfloor - 1}) \approx m \cdot (1 + \frac{x + 2 \cdot s}{y})$$$ machines (forgive my egregious use of $$$\approx$$$).
Since $$$m$$$ (required number of machines with $$$x = 0$$$) cannot be larger than the number of machines in the optimal assignment with whatever value of $$$x$$$ we're given, the approximation factor is at least as good as $$$(1 + \frac{x + 2 \cdot s}{y})$$$.
We can improve the constant factor(s) in the $$$(O(x) + O(s))/O(y)$$$ term through some cheap tryhard methods, but the general $$$(x + s)/y$$$ nature will still remain.
There are also some pretty easy exact solutions which are exponential in the number of machines (which, unlike those exponential in the number of jobs, can occasionally be practical to run), but they're not interesting.
Are there any assumptions on the input data that would make this problem solvable in an interesting manner?
I would also be grateful if someone could direct me towards existing work on related problems if they know of it.
Second, if you haven't immediately updated your HLD template to support subtree queries, do so.
The problem trivially reduces to finding the number of nodes with value $$$1$$$ that have no other node with value $$$1$$$ in their subtree. Further, an update on node $$$u$$$ clearly corresponds to xoring the values for all nodes in the subtree of $$$u$$$ with $$$1$$$.
Now, let's think of a slow solution for this problem. We define the following terms:
A node $$$u$$$ is "good" if no other node in its subtree has the value $$$a_u$$$.
$$$f_u(x)$$$ is the number of good nodes in the subtree of $$$u$$$, with value $$$x$$$.
$$$c_{u}(x)$$$ is the number of nodes in the subtree of $$$u$$$, with value $$$x$$$.
Then the answer is clearly $$$f_{1}(1)$$$, and all values of $$$f$$$ and $$$c$$$ can be computed in $$$O(n)$$$ in the following manner:
dfs(u):
c[u][a[u]] = 1
for v in adj[u]:
dfs(v)
for x in [0, 1]:
f[u][x] += f[v][x]
c[u][x] += c[v][x]
#if u is a good node
if c[u][a[u]] == 1:
++ f[u][a[u]]
dfs(1)
How are $$$f$$$ and $$$c$$$ affected by a single update on node $$$u$$$? Let $$$g$$$ and $$$d$$$ be their new versions after the update.
For every node $$$v$$$ in the subtree of $$$u$$$, we notice that $$$g_{v}(x) = f_{v}(x \oplus 1)$$$ and $$$d_{v}(x) = c_{v}(x \oplus 1)$$$ (in simple terms, we swap $$$f_{v}(0)$$$ and $$$f_{v}(1)$$$, and also swap $$$c_{v}(0)$$$ and $$$c_{v}(1)$$$).
For every node $$$v$$$ that is an ancestor of $$$u$$$:
The contribution of $$$u$$$ to $$$f_{v}(x)$$$ would have been $$$f_{u}(x)$$$ before the update, and will become $$$f_u(x \oplus 1)$$$ after the update, so we must add a delta of $$$f_u(x \oplus 1) - f_{u}(x)$$$ to $$$f_{v}(x)$$$ to account for this update.
Similarly, we must add $$$c_u(x \oplus 1) - c_{u}(x)$$$ to $$$c_{v}(x)$$$ to account for this update.
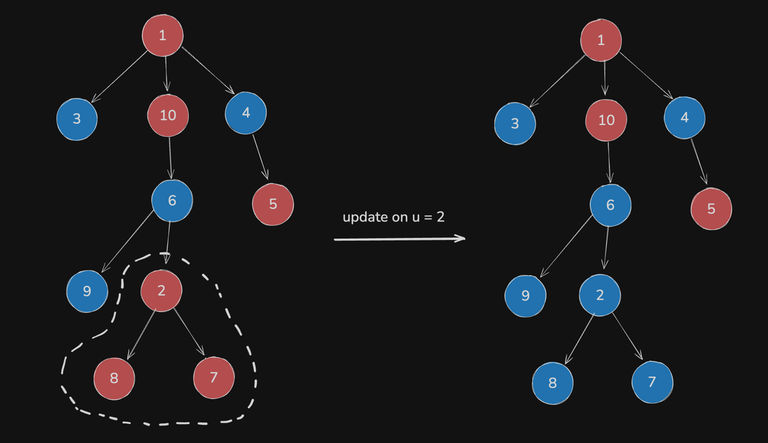
Now, a less attentive reader might have overlooked a pesky little detail: It could be the case that xoring the subtree of $$$u$$$ with $$$1$$$ results in the status of some good nodes outside our subtree being toggled, and this isn't being captured by the updates described above.
Figure
For instance, in the above image (where colors indicate values), node $$$10$$$ isn't "good" before the update, but does become so afterwards.
We make the following observations:
Only the "goodness" of ancestors of $$$u$$$ can be affected by an update at $$$u$$$.
Define $$$p_x$$$ to be the lowest (strict) ancestor of $$$u$$$ with value $$$x$$$ (it might not exist, and we just ignore this in that case). Then only the goodness status of $$$p_0$$$ and $$$p_1$$$ can be affected by this update.
For any $$$p_x$$$:
If $$$p_x$$$ was good before the update, then we can easily prove that it is not good after the update (since $$$u$$$ will have the same value as $$$p_x$$$). So we subtract $$$1$$$ from $$$f_v(x)$$$ for every ancestor $$$v$$$ of $$$p_x$$$ (including $$$p_x$$$).
If it wasn't good before the update, then we simply check if $$$c_{p_x}(x) = 1$$$ after performing the earlier described update for $$$c$$$ (which doesn't depend on anything else), and if so, we add $$$1$$$ to $$$f_v(x)$$$ for every ancestor $$$v$$$ of $$$p_x$$$.
Now, reducing the updates/queries that this solution requires us to perform to a more general form, we want some data structure that can do the following on a static rooted tree:
Update the subtree of a node (the swap updates).
Update the path from the root to an arbitrary node (adding arbitrary deltas for $$$f$$$ and $$$c$$$).
Finding the value(s) at a certain node.
Finding the lowest node on the path from the root to an arbitrary node that satisfies some criterion (finding $$$p_x$$$).
Luckily, HLD can do all of these things in $$$O(\log{n})$$$ / $$$O(\log^2{n})$$$ when augmented with lazy segment trees.
Lazy propagation here might be slightly non-trivial for some readers, so I'll try to explain the operations in appropriate detail below.
More details
In the leaf nodes of the underlying segment tree (which corresponds to some node $$$u$$$ in the original tree), we store the following data:
We have two different kinds of updates ((a) swapping {f[0], f[1]}, {c[0], c[1]} and (b) performing independent increments to each of the four values) that will both be performed on potentially intersecting ranges, and will therefore need to be "combined" quickly in the composition of our lazy tags. These two operations luckily mesh together well.
We store the following information in each lazy tag:
swap_flag
fadd[0], fadd[1]
cadd[0], cadd[1]
swap_flag indicates whether we must swap a node's relevant elements before adding the values stored in fadd and cadd.
We apply tag $$$t_2$$$ to tag $$$t_1$$$ in the following manner:
if t_2.swap_flag == 1:
swap(t_1.fadd[0], t_1.fadd[1])
swap(t_1.cadd[0], t_1.cadd[1])
t_1.swap_flag ^= 1
for p in [0, 1]:
t_1.fadd[p] += t_2.fadd[p]
t_1.cadd[p] += t_2.cadd[p]
If you do not understand why this works, I recommend working out a few concrete operation sequences first.
To apply a tag $$$t$$$ to a monoid element:
if t.swap_flag:
swap(f[0], f[1])
swap(c[0], c[1])
for p in [0, 1]:
f[p] += t.fadd[p]
c[p] += t.cadd[p]
And... that's it?
We can now perform:
Swap updates on subtrees -> Simply push an update with a tag where swap_flag = 1 and all the addenda are set to $$$0$$$.
Add updates on paths -> Simply push an update with a tag with the appropriate addenda.
Finding the value at a certain node -> Duh.
Finding $$$p_x$$$ for some $$$u$$$ -> We can't do this yet.
Let's store some additional info in every node of the segment tree:
mx_dep[0] # -> lex. maximum pair of the form {dep[u], u} where a[u] = 0, under the range of this node
mx_dep[1] # analogously defined
Recall that we didn't really need a monoid combination function for our segment tree earlier (as we were only performing point queries), but we'll need one wherein we maximise these pairs. And oh, remember to swap these pairs when applying a lazy tag with swap_flag = 1 to a node.
To find $$$p_x$$$ for a certain node $$$u$$$, you now simply query the path $$$1 \rightarrow \text{parent}(u)$$$ and read mx_dep[x].
For the sake of completeness, here's how we handle a single update on node u:
#toggle previously good nodes to bad
for x in [0, 1]:
p[x] = hld.query_path(1, par[u]).mx_dep[x].second #set null values to -1
if p[x] != -1:
same_cnt = hld.get_node(p[x]).c[x]
if same_cnt == 1: #p[x] is a good node before this update
hld.update_path(1, p[x], {fadd[x] = -1})
#handle subtree
hld.update_subtree(u, {swap_flag = 1})
#handle ancestors
compute f and c deltas from hld.get_node(u)
hld.update_path(1, par[u], {deltas})
#toggle previously bad ancestors to good
for x in [0, 1]:
p[x] = hld.query_path(1, par[u]).mx_dep[x].second
if p[x] != -1:
same_cnt = hld.get_node(p[x]).c[x]
if same_cnt == 1:
hld.update_path(1, p[x], {fadd[x] = 1})
In hindsight, it's a simple application of a simple technique, but cool DS problems like these definitely induce more happiness in me than most ad-hoc problems, so I hope we'll see more of them in the future, and orz to the author.
The following code takes $$$O(n \cdot x)$$$ memory (NOT $$$O(x)$$$!!!):
vector<vector<int>> a(n);
for(int i = 0; i < n; i ++)
{
a[i].assign(x, 0);
a[i].clear();
}
You must call a[i].shrink_to_fit() after a[i].clear() to actually free the reserved memory, and cap memory usage to $$$O(x)$$$. I unfortunately didn't know this and was consequently traumatized by seemingly inexplicable MLEs in today's d2D.
Now that I think about it, all of those tens of times where I called .clear() on smaller vectors after merging them into larger vectors (small-to-large merging) have been pointless.
Simply put, RSHF offers the ability for users to form groups that have their own self-contained rating, report and moderation systems. Deeper visual integration with the Codeforces website is offered through a browser extension. More details on each of these components follow:
Groups
Group members are partitioned into three tiers:
Admins
Moderators
Members
Their roles and responsibilities closely match what you might think they do: Admins and Moderators process reports and take appropriate actions in response. Admins have additional powers (being able to modify group settings).
A group can be either public (any person who hasn't been kicked from it can freely join) or restricted (your join request must be approved by admins/mods for you to join). In addition, there are several ways to configure groups, which are described ahead.
Memberships
A user can be a member of several groups. Membership within a group serves as a weak proxy for the probability of the user participating fairly in contests. Similarly, being kicked from a group is indicative of the user likely being untrustworthy.
Rating System
Every group has a corresponding "in-group" rating for its members.
The [registration] -> [rating update] flow goes through in the following manner:
A member $$$M$$$ of a certain group $$$G$$$ registers for the contest $$$C$$$ with respect to that group on the RSHF website ($$$M$$$ may choose to register with respect to only a subset of groups that he belongs to).
$$$M$$$ participates in the contest on Codeforces.
Once the contest ends, we run the following algorithm:
"""
pull in the standings S of C from codeforces
for group G:
S' = subsequence of S containing all members of G that registered for C
compute rating deltas using S'
for every M in S':
apply rating delta to M's group rating in G
"""
Some additional thoughts:
As this process is platform-agnostic (all that we need is a [rshf username -> cp platform username] mapping and the contest standings), we can add support for more platforms too (atcoder soon), resulting in ratings being unified across platforms.
You may have noticed that I didn't mention taking initial ratings into account when deciding which members are rated (this would result in an LGM having his rating updated for a div-3). We plan to allow groups to choose their own ranges for initial ratings that would be considered rated for different classes of contests (these are currently hardcoded in and are the same as cf rating ranges (div3 <1600, div2 < 2100, etc.)). Once support for atcoder is added, ABC, ARC, and AGC will also have their rated participation eligibility be configurable in this manner.
The actual rating algorithm used for updates is also hot-swappable (we currently use the default cf algorithm), so groups may choose to use different rating algorithms (for instance the atcoder algorithm).
Report System
Groups have their own self-contained report systems. Within a group, any member can make a report against any other member for offenses ranging from inappropriate conduct in contests to possessing a generally dislikable nature.
Admins/moderators process these reports and then take appropriate action (for example, kicking the person being reported or kicking the reporter for spamming low-quality reports). All reports (and their reviewal outcomes) are publicly visible to keep things transparent.
Further, all the reports that a user has been involved with (as the reporter, respondent, or reviewer) are visible on his profile.
Now, a question that arises is — "Why would an actual cheater even register and join a group, when he could simply not register on RSHF and maintain plausible deniability?". To account for this, we have the following solution:
There is a primary group, "main", which is intended to be used by all users. Everyone is added to it when they do register.
After pulling the standings from a completed codeforces contest, we register unregistered users to RSHF as "ghost accounts", and automatically add them to main (if you haven't registered on rshf and your account is registered as a ghost account, manually registering will result in it becoming a regular account).
Reports can be made against ghost accounts, and action can be taken upon these reports. Therefore, a cheater can get kicked, with the report data being stored on RSHF, without him ever even visiting the website.
A visual demonstration for the less textually inclined:
Browser Extension
The browser extension allows for deeper visual integration with the Codeforces website, along with some ad-hoc bells and whistles. Note that you don't need an account on RSHF to use the extension.
Rating/Username color injection
I find cf ratings and subsequently username colors really helpful for mentally filtering out content in cf blogs/comments that is likely low-quality, and I suspect many other people do too. This feature is the primary reason for the existence of this extension and aims to allow you to be able to similarly mentally filter content using RSHF ratings.
You choose a "display group", and all users on Codeforces then get partitioned into three groups with respect to the chosen group —
Group members.
Non-members.
Non-members who were kicked from the group.
You may choose to render the usernames of each class of users from a variety of display styles (rshf group ratings, regular codeforces ratings, luogu-esque brown for cheaters, etc.).
This allows you to benefit from a group's report data even if you don't want to bother engaging with RSHF — You simply:
Install the extension
Choose a group
Set rendering style to brown for kicked users and default to regular cf ratings for the other two categories.
This results in the usernames of cheaters being visually distinguished while other elements remain unchanged.
Blog/Comment Filtering
You can set rating lowerbounds (either RSHF or CF) and the extension will then filter away content by users below that rating threshold. You don't have to worry about accidentally missing important blogs by troll setters like tibinyte, as no content is deleted (filtered comments just get minimized, and filtered blogs are moved to a separate box).
Some QoL Stuff
Not worth making the blog longer than it has to be.
The current situation
Things are far from complete right now, and we expect there to be some undiscovered bugs. Further — some functionality, while being implemented on the backend, hasn't been exposed to the end user yet. For instance, we currently don't offer the ability to create groups to arbitrary users, and instead have one group — "main". The rationale behind this is partly to be able to accrue enough users in one group for it to reach critical mass (dilemma: people would only really want to join a group if its ratings actually mean anything, and conversely, a group's ratings would only mean anything if enough people joined it).
We intend to run RSHF in beta for a month or so, to iron out unexpected bugs and make everything resistant to malicious use. I'm not going to have much time to spend upon it after a few weeks, so I would also appreciate people contributing/taking over development.
I think I'm going to make a browser extension that displays a frozen (from just before the release of o1) rating/rank/color for every user (this would extend to their profiles, the color of their names in ranklists/comments/blogs/mentions, etc).
There seems to be a general trend of problem-setters going out of their way to ensure that their problems aren't solvable by AI. This obviously restricts the meta to the kinds of problems that AI is bad at: which, in practice seem to primarily be ad-hoc problems that require multiple observations. This approach doesn't always (and in my opinion, rarely) yield the most enjoyable/natural problems to humans.
The only motivation for this tendency is to ensure that CF ratings and leaderboards in contests retain some meaning.
What I want to express from this blog:
I think we should stop intentionally making anti-GPT problems and optimize problem-setting for human enjoyment, with a complete disregard for how AI models (and people using said models to cheat) perform on these problems.
I will try to explain why I think so below.
There are only two ways (distinct in their relevance to CP) in which AI gets better in the future:
It becomes smarter than humans and creating problems which are unnaturally hard (with respect to other kinds of problems) for it becomes infeasible because it doesn't have any weaknesses which humans are good at. This seems like a very probable outcome based on how quickly it has improved in the last few years (I can recall discussions in which people made fun of GPT's incompetence and how it would never be able to solve even slightly non-trivial problems due to fundamental issues in how AI models work, back in 2022). However, I don't have any real knowledge about how AI works or what the current AI "scene" looks like so let's not focus too much on whether this is bound to happen.
Let's say it does happen in 5 years, what happens to CP then? Assuming that sites like CF don't go down to due to a lack of revenue (I don't actually know how CF generates revenue), we would realize that since there is no way to prevent misuse of AI, we might as well maximise enjoyment for actual humans (enjoyment for humans + cheating > no enjoyment for humans + cheating).
Now, you may ask: how is the future relevant to the present moment? Well, I think it's because most people are subconsciously thinking of the current decision to make anti-AI problems as going down a path which leads to AI never making cf ratings meaningless, at the cost of some eternal but minor decrease in problem quality (akin to making greedily optimal choices in an optimization problem; they aren't seeing far enough). If one does recognize that ratings will become meaningless in a significantly short amount of time (5 years being a good estimate) then one views the two choices in a different light:
Keep making anti-GPT problems, which become increasingly hard to create, and less pleasant for humans to solve, as AI keeps getting smarter, cheaper and faster. This also entails dealing with the countless blogs and comments by crying cyans about how a guy using o69 caused his rating delta to go from +2 to -10. Do this for 5 years until there is a pivotal moment when people realize the futility of this charade. If you were to look back upon the last few years from that point, giving up the prestige and meaning we attach to ratings in exchange for preserving the actual enjoyment we derive from this activity would seem like the right thing to have been done.
Stop caring about misuse of AI and how it affects ratings. Optimize for elegance and enjoyment when creating problems.
In other words, the destination is the same- we can either choose to be slowly dragged to it while throwing a hissy fit or accept reality and walk to it ourselves, enjoying every part of the journey.
Somehow, magically, AI hits a "wall" which it cannot meaningfully improve beyond. For us, this would mean that it's expected performance rating would asymptote to some value. Keep in mind that this value would still be quite high, since it currently seems to be able to perform at a performance rating of at least 2000 in most contests, which places it at the 95th percentile(https://mirror.codeforces.com/blog/entry/126802) of human competitors. Once again, I don't want to speculate about how much this score would be in the future, but it seems safe to say that it would at least be 2300, implying that the vast majority of human competitors would benefit in some measure by using AI during contests.
Until the "wall" is hit, the intervening period would be more-or-less identical to the period where AI gets better in the first situation. The meta would have to rapidly change, problem-setters would have to put effort into making sure that their problems weren't solvable by the SOTA, there would be a lot of volatility, people would constantly complain about AI cheaters and their effects on rating distributions, etc. This period would be as unpleasant as in the first scenario. There are two possible final destinations here:
We stop caring about misuse of AI and how it affects ratings. Optimize for elegance and enjoyment when creating problems. The same endpoint as the first scenario. We would realize that we should have stopped caring about AI cheating earlier in this timeline too.
The CF meta also asymptotes to a certain place, and is significantly based around the limitations of the then-SOTA AI. It is obviously unlikely that the kinds of problems AI would be bad at would be the ones that humans enjoy and find natural. It would, also not be perfect wrt cheating and there would still be a lot of it since AI would still be smarter than most humans at all kinds of problems (but worse at certain kinds of problems than a small percentage of humans). Maybe there will be a weird gap between the kinds of problems at offline events like olympiads and online contests, since the former would likely always optimize for human enjoyment (or at least not consider AI capability when creating problems). It could just be me, but I certainly wouldn't want this wonderful activity to end up in such a place and would much prefer having gone the other way earlier.
On a more positive note for people who care about ratings
If we do stop caring about how AI performs in contests, the following might happen:
People from certain countries who engage in this activity for jobs cheat en masse using AI initially.
Ratings lose value.
Organizations stop caring about ratings when hiring.
Aforementioned kind of people stop visiting this site.
Cheating significantly reduces and the only cases of it are the occasional 12 year old soothing his ego.
Ratings gain value again.
I shouldn't have started writing this at 6 AM, now the sun is out and I don't feel like sleeping.
I am unfortunately not very good at writing code and can barely function without an easy way to debug said code. I therefore need a debug template at ICPC and spent some time reducing the length of the debug template I use normally. I think it's pretty short already, but it seems like it can be shortened further. I don't know how to do so, hence this blog.
Some considerations:
Can only use features introduced in C++ 17 or earlier, as my region is weird.
Need to be able to debug all STL containers, and any nested versions thereof.
Now, if C++ 20 were allowed, one could simply use the following:
__print() works by repeatedly considering the elements that constitute x and calling __print() on them (whilst ensuring that the output of each __print() call is separated by ,) until << is defined for x by default.
Now, what's the problem with making this code compatible with C++17?
The problem is that there doesn't seem to be a short (in terms of code length) way in C++17 to differentiate between pairs and iterable containers.
I found two solutions, both of which aren't good at all:
This will work if we have pairs like std::pair<int, float> but not with something like std::pair<int, vector<int>>. This is a significant loss of functionality since we now cannot debug things like map<int, vector<int>> which are often used.
2) Just create a separate templated function for pairs
Notice that we now need to use a class/struct/namespace for the two __print() functions as they can call each other.
Can someone help me fix these issues and/or make the code shorter in general? Right now, I think the last one is the best. I can't believe I spent the last 3 hours shortening a piece of code by 5 lines.
For whatever reason, GPT and Claude seems to be unhelpful here. I ran out of access to 4o trying to get it to help me, despite purchasing GPT plus T_T
It has additional functionality as compared to std::bitset (you can answer many kinds of range queries on it, for example: "Find $$$k$$$-th set bit in range $$$[l, r]$$$).
Some poor documentation
General
It is used to store a 0-indexed boolean array.
Just like regular bitset, index 0 is the rightmost (sense of direction is important for >> and <<).
It uses $$$\lceil n/B \rceil$$$ blocks of size $$$B$$$ (which should be equal to bitwidth of $$$T$$$) to represent a boolean array of length $$$n$$$. Note that there may be some unused bits at the end of the last block. We will always have these unused bits set to 0.
Functions
For most functions, their use is obvious. For others:
helper functions
T prefix(int i): returns block of size $$$B$$$ with only first $$$i$$$ bits set.
T suffix(int i): returns block of size $$$B$$$ with only last $$$i$$$ bits set.
T range(int l, int r): returns block of size $$$B$$$ with only bits in range $$$[l, r]$$$ set (note that this function is 1-indexed but everything else is 0-indexed).
T submask(int l, int r): given that $$$l$$$ and $$$r$$$ belong to the same block $$$x$$$, returns $$$x$$$ with all bits outside $$$[l, r]$$$ turned off.
trim(): turns off extra bits in the last block, if any.
main functions
o= operator where o is some bitwise operator: if you do a o= b where a and b are bitsets of different sizes, the operation is done assuming that the smaller bitset is padded with 0s to make the sizes of the two equal.
Count(): returns total number of set bits.
FindFirst(): returns position of first set bit (returns -1 if no such bit).
FindLast(): returns position of last set bit (returns -1 if no such bit).
RangeProcess(int l, int r, auto block_brute, auto block_quick): can be used to process some range queries on the bitset. For example, "Finding $$$k$$$-th set bit in range $$$[l, r]$$$". See implementation of below functions to understand how it works.
RangeSet(int l, int r, bool val): set all bits in given range to given value.
Count(int l, int r): count number of set bits in given range.
FindFirst(int l, int r): find position of first set bit in given range (returns -1 if no such bit).
FindLast(int l, int r): find position of last set bit in given range (returns -1 if no such bit).
Warnings
Always keep in mind that there may be some unused 0s at the end of the last block.
Efficiency:
Firstly, always use the following pragmas with it:
They can reduce runtime by upto 50% (thanks to mr rewhile for enlightening me on this).
I am too lazy to run any proper benchmarks, but I solved a few problems with it and it was always faster than std::bitset and tr2::dynamic_bitset. Here are some sets of submissions on the same problem with all 3:
So it seems that my bitset is as good or slightly better in every manner. I have no idea why this is the case though, as there is nothing which seems particularly faster in my implementation.
Parting notes:
If you use it and find some bugs, let me know.
If you think it's missing some significant functionality, let me know.
Hello, in this blog I'll share a funny way to construct a suffix tree in $$$O(n \log^2{n})$$$ time, for a given string $$$S$$$ of length $$$n$$$. I am going to call the underlying idea the "Leader Split Trick". It can probably be used to solve other problems too.
Problem
A suffix tree of a string $$$S$$$ is a radix tree constructed from all the suffixes of $$$S$$$. It's easy to see that it has $$$O(n)$$$ nodes. It can be constructed in $$$O(n)$$$ using this.
I am going to share a simple and practically useless way of building it in a worse time complexity, $$$O(n\log^2{n})$$$.
Algorithm
Notation
When I refer to "suffix $$$i$$$" ahead, I mean the suffix $$$S[i, n]$$$.
$$$l_i$$$ is the leaf node corresponding to suffix $$$i$$$ in the final suffix tree.
Initially, we start with an empty tree (with a virtual root node), and a set $$$G$$$ of all suffixes from $$$1$$$ to $$$n$$$, these suffixes will be stored in the form of their starting index.
It's easy to see that the paths from the root node to $$$l_u \forall (u \in G)$$$ will share some common prefix till an internal node $$$s_G$$$, after which these paths will split apart along some downward edges of the internal node. Let's define $$$d_G$$$ to be the longest common prefix across the paths $$$(\text{root}, l_u) \forall u \in G$$$.
Our algorithm will essentially do the following:
Find $$$d_G$$$.
Split apart $$$G$$$ into disjoint subsets $$$G'$$$ (each subset $$$G'$$$ will have suffixes whose leaves lie in the subtree of a unique child node of $$$s_G$$$).
Solve the problem recursively for each subset, and add an edge in the suffix tree from $$$s_G$$$ to $$$s_{G'}$$$ for every $$$G'$$$.
Now, we define a recursive function $$$f(G, L, \text{dep}, \text{dis})$$$.
Definitions
$$$G$$$ : a set of suffixes (represented by starting indices)
$$$L$$$ : "leader" element (possibly undefined, in which case it will be "null")
$$$\text{dep}$$$ : depth of $$$s_{G_p}$$$ (the internal node of the parent call).
$$$\text{dis}$$$ : sorted list of integers (possibly undefined).
In each call, $$$f(G, L, \text{dep}, \text{dis})$$$, we do the following:
If the "Leader" element $$$L$$$ is undefined:
Set $$$L$$$ to a random element of $$$G$$$.
For every suffix $$$i \in G$$$, find $$$\text{dis[i]}$$$, the longest common prefix of the suffixes $$$i$$$ and $$$L$$$. This can be done in $$$O(\vert G \vert \cdot \log{n})$$$ using binary search + hashing. We store $$$\text{dis}$$$ in a sorted manner.
Let $$$m$$$ be the minimum value in $$$\text{dis[]}$$$. It's easy to see that the internal node created from splitting $$$G$$$ will occur at depth $$$\text{dep} + m$$$. We create $$$s_G$$$, and add an edge corresponding to the substring $$$S[L + dep + 1, L + \text{dep} + m]$$$ from $$$s_{G_p}$$$ to $$$s_G$$$.
Now, we delete all suffixes $$$i \in G : \text{dis[i]} = m$$$, from $$$G$$$ (and their corresponding elements from $$$\text{dis}$$$), and group them into disjoint subsets based on the character $$$S_{i + \text{dep} + m + 1}$$$ for suffix $$$i$$$ (basically the next character after the internal node).
We call $$$f(G', \text{null}, \text{dep} + m, \text{null})$$$ for every newly created subset $$$G'$$$, and also call $$$f(G, L, \text{dep + m}, \text{dis})$$$ for the modified subset $$$G$$$.
Note: There might be some off-by-one errors.
Complexity Analysis
Consider the following problem:
We have $$$n$$$ singleton sets, and are given some set merge operations. When merging sets $$$A$$$ and $$$B$$$, we merge $$$B$$$ to $$$A$$$ with probability $$$\frac{\vert A \vert}{\vert A \vert + \vert B \vert}$$$ and $$$A$$$ to $$$B$$$ with the probability $$$\frac{\vert B \vert}{\vert A \vert + \vert B \vert}$$$.
The above problem is computationally equivalent to Randomized Quicksort, which has an expected time complexity of $$$O(n \log{n})$$$.
It's not difficult to see that our split operations are simply the operations that will occur in the above problem in a reversed manner (Formally, we can define a bijective relationship between the two sets of operations, such that related sets of operations will occur with the same probability) . Therefore, the time taken by all the split operations is $$$O(n \log{n})$$$.
However, every time we perform a split operation (merge in reverse), we also compute $$$\text{dis}$$$ for the child set $$$C$$$ (which gets merged into the parent set), and that takes $$$O(\vert C \vert \log{n})$$$ time. Thus, our entire algorithm has an expected time complexity of $$$O(n \log^2{n})$$$.
This trick seems to have some "online capability", as we can efficiently split a group of nodes into multiple groups (given that the information for query for a group can be processed mostly through a randomly chosen leader element). For example, consider the following problem:
Problem 1
You are given a tree on $$$n$$$ nodes. You also have a set containing all nodes, $$${1, 2, \dots , n}$$$. You have to process the following queries online:
"$$$1\; m\; x\; v_1\; v_2\; \dots \; v_x$$$" : Remove the nodes $$$v_1, v_2 \dots, v_x$$$ from the set $$$S$$$ whose maximum element is $$$m$$$, and create a new set with these elements (it is guaranteed that there exists some set with maximum element $$$m$$$ and $$$v_i \in S \; \forall \; i$$$).
"$$$2 \; m$$$" : Let the set whose maximum element is $$$m$$$ be $$$S$$$. Find some node $$$x \in S \mid \max_{y \in S}{\text{dis}(x, y)} = \max_{u, v \in S}{\text{dis}(u,v)} $$$.