


Thanks for participating!
2214A — Odd One Out
Idea: flamestorm
You just need to output the arrow that only appears once. That arrow is C2.
print("C2")
2214B — Are You Smiling?
Idea: prvocislo
One unusual thing about the statement is the presence of a emoji. More precisely, a smiling, emoji.
Okay, let's try to print a smiling emoji.
However, the output should be a string of characters and numbers, so we cannot do it directly.
There's one more suspicious thing in the statement — the $$$U+?=HAPPY$$$ equation. If we should print ?, what is the meaning of U?
U+ often indicates that an unicode of a special character is given — an international standardized encoding for characters, including emojis. A quick Google search can be used to obtain an unicode of any emoji, for example 😁 is represented as U+1F601 (in hexadecimal system). Outputing 😁 indeed works — however there are many possible answers.
Since both hexadecimal and decimal representation is commonly used, the checker was accepting smiling emojis in both formats.
print("1F601")
2214C — And?
Idea: flamestorm
What operation does "and" remind you of?
Here, "and" refers to bitwise AND. If we take the bits of $$$20260401$$$, we get $$$1001101010010011000110001$$$.
Now, notice that this is exactly as long as the string $$$\texttt{RXOEARDMTINHUSERMEDESIANT}$$$. This motivates us to look at the AND of these two strings: exactly those characters where the corresponding bit is $$$1$$$.
Doing so, we get the string $$$\texttt{READ}~\texttt{THE}~\texttt{REST}$$$. So we instead read the $$$0$$$ bits, and get $$$\texttt{XOR}~\texttt{MINUS}~\texttt{MEDIAN}$$$. Thus we simply output the XOR of the numbers minus their median.
#include <bits/stdc++.h>
using namespace std;
const int MAX = 200'007;
const int MOD = 1'000'000'007;
void solve() {
int a[3];
cin >> a[0] >> a[1] >> a[2];
sort(a, a + 3);
cout << (a[0] ^ a[1] ^ a[2]) - a[1] << '\n';
}
int main() {
ios::sync_with_stdio(false);
cin.tie(nullptr);
int tt; cin >> tt; for (int i = 1; i <= tt; i++) {solve();}
// solve();
}
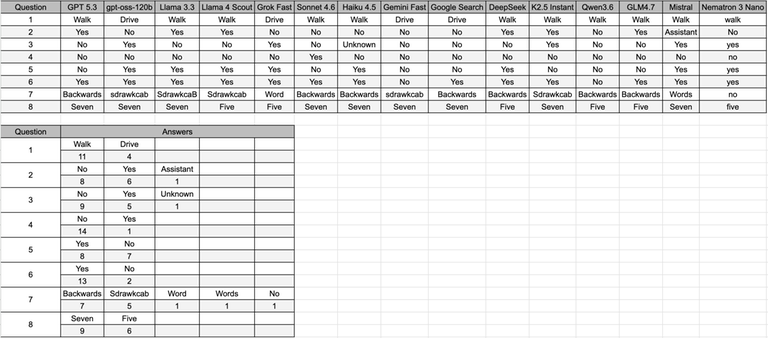
2214D — Neural Feud
Credits: AlperenT
Do the questions sound familiar?
Does the problem name sound familiar?
What happens when you submit the obvious answer "drive" for the first question?
If you submit "drive" the judge tells you:
4 out of 15 AI models gave the same answer as you (drive). This is not their most common answer, my condolences :(
This problem is a parody of Family Feud. However, instead of surveying 100 people, we surveyed 15 different AI models and gathered their answers. You have to figure out what is the most common answer among the AI models.
#include <bits/stdc++.h>
using namespace std;
int main(){
vector<string> answers = {
"",
"walk",
"no",
"no",
"no",
"yes",
"yes",
"backwards",
"seven",
};
int n;
cin >> n;
cout << answers[n];
}
2214E — Shortest Paths
Credits: willy108
It is intentional.
use Dikjstra's algorithm.
The astute reader may have noticed that "Dijkstra" is spelled incorrectly as "Dikjstra" in the problem statement. As a reference to this Meta Hacker Cup problem, we can use Floyd Warshall with a loop order of i, k, then j to find the correct shortest paths.
#include <bits/stdc++.h>
using namespace std;
const int MX = 1e9;
int main(){
int n, m;
cin >> n >> m;
vector<vector<int>> dist(n, vector<int>(n, MX));
for(int i = 0; i<m; i++){
int a, b, c;
cin >> a >> b >> c;
a--, b--;
dist[a][b] = c;
dist[b][a] = c;
}
for(int i = 0; i<n; i++){
dist[i][i] = 0;
}
for(int i = 0; i<n; i++){
for(int k = 0; k<n; k++){
for(int j = 0; j<n; j++){
dist[i][j] = min(dist[i][j], dist[i][k] + dist[k][j]);
}
}
}
for(int i = 1; i<n; i++){
if(dist[0][i] >= MX){
cout << "-1\n";
} else {
cout << dist[0][i] << "\n";
}
}
}
2214F — Numbers
Credits: temporary1
Subvert your expectations.
This problem is very, and I mean very, hard to solve in your head. Take your time.
All pieces are used. No piece needs to be flipped.
Subvert your expectations.
The answer is 5 digits long.
It you do it correctly, some things will line up.
Squint your eyes.
Through some work (and potentially assistance from image editing tools), you would be able to piece together the original untorn paper, which may look something like this:

Now squint your eyes and look down the middle row. Maybe cover the top and bottom part. You will see that the number $$$92136$$$ forms in the middle. This is the answer.
#include <bits/stdc++.h>
using namespace std;
int main() {
cout << 92136;
return 0;
}
2214G — Anomaly
Credits: temporary1
It seems the answer was leaked somewhere. We have investigated thoroughly regarding this issue.
It seems a person had broken the rules. We quickly disqualified him before the contest ended.
Turns out this person managed to get the solutions to all problems from the editorial ahead of time. How is that even possible?
It seems this person leaked the answer through the very limited means of communication he had.
The person in question is AprilFoolsClairvoyant. Truly an anomaly.
The hidden string is bigchadjeff. You can now use this information to get Accepted.
Notes:
Some time during the contest, a user by the name of AprilFoolsClairvoyant started submitting correct editorial solutions to all problems. We recognized him, as we've dealt with him before in previous year's contest, where he submitted the first accepted solution to problem C with the assistance of time machines. You can find more information about this incident in the trivia section of problem C's editorial.
In our investigation, we noticed that he was submitting to problems in a weird, particular order. We have now found out that this was an attempt made by him to communicate the answer to other participants. He made 11 submissions in total, to problems in this order: B,I,G,C,H,A,D,J,E,F,F. He submitted to all problems, with a resubmission on F.

This spells out the answer (that coincidentally only has latin characters from a to j), which he once again obtained via the use of time machines. Such behaviour is unacceptable as time machines are prohibited by the codeforces rules, so we quickly disqualified him before the contest ended.
#include <bits/stdc++.h>
using namespace std;
int main() {
string s = "bigchadjeff";
int tt;
cin >> tt;
while (tt--) {
int i;
cin >> i;
cout << s[i-1] << '\n';
}
return 0;
}
2214H — Double Vision
Credits: AlperenT
Does the image look familiar?
Did you click to the 2026 link on the announcement?
Well, that was actually a distraction. The problem is not about color blindness. Did you not read the problem name?
The image looks weird, why is that?
What could "double vision" refer to here?
This problem is a follow up on the last year's "blurred vision". However, as the name suggests, you need to use both of your eyes to solve it.
Specifically, the image is a autostereogram made out of the Ishihara Test in the rick roll video of the announcement. If you look at the image using the proper technique or use one of the online Autostereogram solvers, you would find the text "YU5zV2VS" embedded in the image.
If you haven't already, please try to see it without any tools.
Can you figure out what YU5zV2VS stands for?
#include <bits/stdc++.h>
using namespace std;
int main(){
cout << "YU5zV2VS";
}
2214I — You Are a Robot
Credits: Ari, AlperenT, temporary1
Remember, you are a robot.
There are certain laws robots must follow.
Ensure the best possible outcome.
This problem can be solved using dynamic programming.
Because you are a robot, you must follow the three laws of robotics, which state that:
A robot may not injure a human being or, through inaction, allow a human being to come to harm.
A robot must obey the orders given it by human beings except where such orders would conflict with the First Law.
A robot must protect its own existence as long as such protection does not conflict with the First or Second Law
So the first priority is ensure minimal human damage, and because you were not given any orders from any humans, your second priority is minimizing damage to your own existence. Do keep in mind that all robots share a unified mind, so damage to any robot affects you as well.
Thus your objective is to first minimize the number of human casualties, then minimize the number of robot casualties. We can compute these values using dynamic programming on the tree.
Let
where:
- $$$x$$$ is the minimum number of human casualties,
- $$$y$$$ is the minimum number of robot casualties among all solutions that achieve the minimum $$$x$$$,
assuming the trolley starts at intersection $$$i$$$.
For each intersection $$$i$$$, consider all intersections $$$j$$$ such that $$$j$$$ is a child of $$$i$$$. Then,
where the minimum is taken in lexicographical order (first minimizing $$$x$$$, then $$$y$$$).
After computing all $$$dp[i]$$$, we reconstruct an optimal path.
Starting from the root (intersection $$$1$$$), repeatedly move to a child $$$j$$$ such that
Continue this process until reaching a leaf. This leaf is a valid answer. The time complexity of this solution is $$$O(n)$$$.
#include <bits/stdc++.h>
using namespace std;
#define f first
#define s second
#define ll long long
#define pii pair<int,int>
#define pb push_back
#define mkp make_pair
const int MOD = 1e9+7; // 998244353;
vector<int> adj[200005];
pii dp[200005];
int a[200005];
void dfs(int node, int fa) {
if (adj[node].empty()) {
dp[node] = mkp(0,0);
return;
}
dp[node] = mkp(2e9,2e9);
for (auto it : adj[node]) {
if (it == fa)continue;
dfs(it,node);
pii cur = dp[it];
if (a[it] == 1)++cur.f;
else if (a[it] == 2)++cur.s;
dp[node] = min(dp[node],cur);
}
return;
}
int main() {
ios_base::sync_with_stdio(false);
cin.tie(NULL);
int tt;
cin >> tt;
while (tt--) {
int n;
cin >> n;
for (int i = 1; i <= n; ++i) {
adj[i].clear();
}
for (int i = 2; i <= n; ++i) {
int x;
cin >> x;
adj[x].pb(i);
}
for (int i = 2; i <= n; ++i) {
cin >> a[i];
}
dfs(1,0);
int x = 1;
while (adj[x].size()) {
int y = -1;
for (auto it : adj[x]) {
pii cur = dp[it];
if (a[it] == 1)++cur.f;
else if (a[it] == 2)++cur.s;
if (cur == dp[x]) {
y = it;
break;
}
}
x = y;
}
cout << x << '\n';
}
return 0;
}
2214J — Special Problem
This problem's source code can be found here
First, click on the link to view the statement. Oh wait, we need to pass Codeforces's Cloudflare verification first. Simply click the checkbox and solve some CAPTCHAs, which are just clicking stop signs, typing words, etc.... Wait, since when do these things start having word games and math problems?
At some point the CAPTCHAs are getting so absurd it should be clear that it is not a real Cloudflare challenge page. In fact, solving these increasingly convoluted CAPTCHAs is the problem itself. After finishing all of them, you will be shown the actual problem statement which is trivial to solve.
- The octagonal sign with DUR is a Turkish stop sign. Click on the squares that contains it.
- Type the squiggly word in the image.
- You can find prime number checkers online or write your own. Notice that the numbers 10000000007 and 993244353 are not the usual prime numbers you see.
- Since you have unlimited guesses, simply guessing
AAAAAtoZZZZZwill reveal the answer. - Using the Codeforces "Contests" page you can filter unrated rounds. You can also read the announcement blog of each round.
- If you are not an LLM, counting R's in strඞwberry should be easy.
- Assemble the famous Floyd-Warshall algorithm. Remember the correct indexing order of the algorithm.
- Click the center of the board and you're almost done... except, all the corners are 50/50s, which means that you cannot deduce where some mines are and can only guess. Fortunately you have infinite retries and the puzzle is almost the same.
- Find a map with borders and see where Liechtenstein is. Your answer is accepted if the red square roughly covers the country.
If you've played the Robot game on neal.fun you should recognize what's happening pretty fast. If you have never played the game this problem was inspired from, I highly recommend playing it: https://neal.fun/not-a-robot/
#include <iostream>
int main() {
std::cout << "Yes, I can attest to my status as a thoroughly validated, carbon-based biological entity.\n";
}







